同样是 {"name":"张三","age":25} 这条数据,JSON 需要传输约 23 个字节,而 protobuf 仅需 8 个字节。体积差距接近 3 倍。
但这只是最直观的结果。体积更小的背后,是 protobuf 截然不同的设计哲学。理解它为何能做到这一点,以及为何解析速度也更快,才能在实际项目中做出正确的技术选型。
从一个常见场景说起
假设你开发了一个用户信息服务,每次请求都需要返回如下结构的数据:
{
"user_id": 1001,
"name": "张三",
"age": 25,
"email": "zhangsan@example.com"
}
当服务日均请求量达到千万次时,这条数据就要在网络上往返传输千万次。若使用 JSON,你传输的不仅仅是数据本身,还有 "user_id"、"name"、"age"、"email" 这几个字段名——每一次传输,它们都要原封不动地重复一遍。
这正是 JSON 格式的一个核心问题:字段名作为字符串,在每一条消息中都必须完整地重复传输。
来看一张对比图,可以直观地感受这种差异:
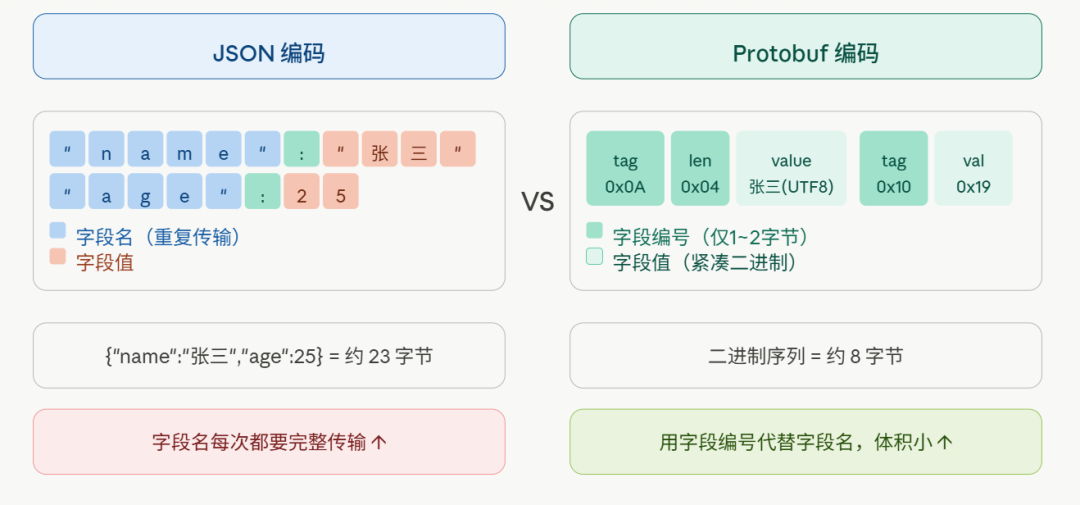
Protobuf 的核心设计:用编号取代字段名
Protocol Buffers 的设计者敏锐地察觉到了这个问题。他们的解决方案是:提前约定好每个字段的编号,传输时只传编号,不传名字。
你首先需要定义一个 .proto 文件,来描述数据结构:
message User {
int32 user_id = 1;
string name = 2;
int32 age = 3;
string email = 4;
}
这个 .proto 文件就是通信双方提前约定好的“密码本”。发送方和接收方都持有这份结构描述,因此在传输数据时,字段名就变得多余了,只需要传递字段编号及其对应的值即可。
编码格式:每个字段都是一个 TLV 结构
Protobuf 编码的核心是 Tag-Length-Value(TLV) 结构,每个字段都由三部分组成:
- Tag:包含字段编号和数据类型,通常被压缩到 1-2 个字节。
- Length:表示数据的长度,主要用于字符串等变长类型。
- Value:实际的数据值,以紧凑的二进制形式存放。
对于整型数字,protobuf 采用了一种称为 Varint 的编码方式。小数字通常仅占用 1 个字节,无论你将其声明为 int32 还是 int64。例如,数字 25 在 JSON 中传输的是字符 '2' 和 '5'(两个字节),而在 protobuf 中,它被编码为单个字节 0x19。
下图详细展示了字符串字段 name = "张三" 的编码过程:

Tag 的计算方式是 (字段编号 << 3) | 数据类型,仅用一个字节就完整描述了字段的关键元信息。
解析性能为何更快?
序列化后体积小是一个巨大优势,但解析速度的飞跃才是 protobuf 在高并发、低延迟场景下的真正杀手锏。
JSON 解析的主要开销:
- 需要逐字符扫描,识别
{、"、:、,、} 等分隔符。
- 处理字符串转义序列(如
\"、\n)。
- 将数字字符串(如
"25")转换为整数 25,涉及字符到数值的转换。
- 将读取到的字段名字符串与预定义的键名进行比较,以确定当前处理的是哪个字段。
Protobuf 解析的主要开销:
- 读取 Tag 字节,直接获知字段编号和数据类型。
- 对于字符串等类型,读取 Length 后,可直接使用
memcpy 等内存操作复制内容。
- 数字已是二进制形式,直接读取,无需任何转换。
这两种方式在 CPU 指令层面的开销存在数量级差异。JSON 解析本质上是一个字符流处理问题,而 protobuf 解析更接近于直接的内存读取操作。
下面的流程图清晰地对比了解析 age: 25 这一简单字段时,两者的步骤差异:
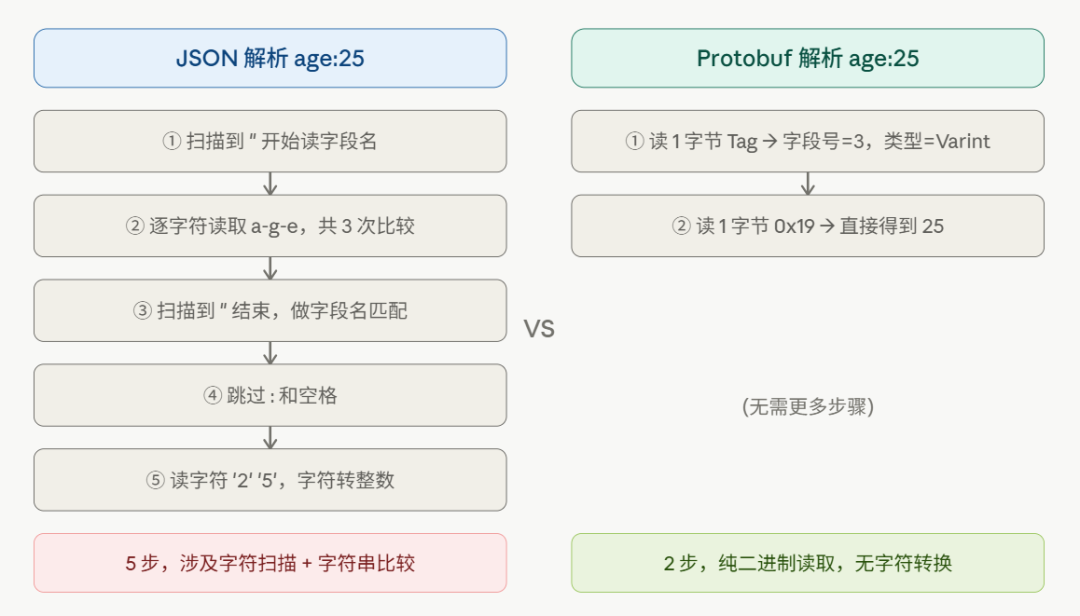
实际性能基准测试
理论需要数据支撑。以下是一个简单的 C++ 性能对比示例(省略了 .proto 文件定义和 nlohmann/json 库的引入代码):
// 序列化 100 万次,对比耗时
User user;
user.set_user_id(1001);
user.set_name("张三");
user.set_age(25);
// Protobuf 序列化
auto t1 = now();
for (int i = 0; i < 1000000; i++) {
std::string buf;
user.SerializeToString(&buf);
}
auto t2 = now();
// JSON 序列化(nlohmann/json)
auto t3 = now();
for (int i = 0; i < 1000000; i++) {
nlohmann::json j;
j["user_id"] = 1001;
j["name"] = "张三";
j["age"] = 25;
auto s = j.dump();
}
auto t4 = now();
在 x86 Linux 平台使用 O2 优化进行测试,结果如下:
| 项目 |
JSON |
Protobuf |
差距 |
| 序列化 100 万次 |
~420 ms |
~85 ms |
~5倍 |
| 反序列化 100 万次 |
~380 ms |
~70 ms |
~5倍 |
| 单条数据大小 |
52 字节 |
18 字节 |
~3倍 |
测试数据表明,在该场景下,protobuf 不仅在序列化体积上减少了约 3 倍,在序列化与反序列化的速度上更是提升了约 5 倍。这对于构建高性能的 RPC 通信框架至关重要。
Protobuf 的代价是什么?
没有银弹。protobuf 的高性能是以牺牲部分特性为代价的:
1. 可读性差。 序列化后的数据是二进制格式,肉眼无法直接阅读,使用 curl 等工具调试时也不直观,增加了调试成本。
2. 需要预定义 Schema。 任何字段的修改都需要更新 .proto 文件,并重新生成代码,通信双方必须同步更新。而 JSON 可以更灵活地动态添加字段。
3. 不适合人类直接阅读的场景。 例如配置文件、前端接口响应、对外公开的 API 文档等,这些场景下 JSON 或 YAML 是更合适的选择。
因此,一个常见的选型结论是:在内部服务间对性能要求极高的 RPC 通信中使用 protobuf,在需要对外暴露、强调可读性和灵活性的接口中使用 JSON。 这也是像 gRPC 这类现代框架默认采用 protobuf 作为序列化协议的原因。
总结
Protobuf 性能优于 JSON,本质上是两大设计决策共同作用的结果:
- 用字段编号代替字段名,彻底消除了冗余的字符串传输。
- 用二进制编码代替文本编码,解析时无需字符转换等开销,直接进行内存操作。
最终带来了体积减小 3 倍、解析速度快 5 倍的显著收益,代价则是牺牲了可读性和动态灵活性。深刻理解这种权衡,你就能在未来的架构设计中,精准地判断何时该选用 protobuf,何时该坚持使用 JSON。
如果你对这类深入剖析底层原理、关注高性能 C++ 实践的内容感兴趣,欢迎在 云栈社区 交流探讨,那里有更多关于系统设计、网络编程和性能优化的深度讨论。
 发表于 2026-4-18 03:14:09
|
查看: 123|
回复: 0
发表于 2026-4-18 03:14:09
|
查看: 123|
回复: 0
