作为一个每天都要跟 Hacker News、GitHub Trending、arXiv、Product Hunt 打交道的技术人,信息焦虑几乎是常态。刷完这四个站点至少半小时,结果往往只是「看过即忘」。更别提工作群里的技术讨论、领导的突发消息、Xcode 编译报错——每次遇到都得手动分析、手动整理。
我用 Swift 写了一个 macOS 原生小工具 Tech Brain,把这两件事一并解决了:一是自动聚合四大社区,生成 AI 技术趋势雷达;二是关键时刻按个快捷键,截图识别,AI 直接输出一张结构化分析卡片。两个月下来,团队早上看推送、平时遇问题就截屏,效率提升不少。
它能干什么?
Tech Brain 有两条核心能力线。
能力一:AI 技术趋势雷达
同时拉取四大技术社区的实时内容:
| 数据源 |
获取方式 |
内容 |
| Hacker News |
Firebase REST API |
Top 30 热门文章 |
| GitHub Trending |
HTML 页面解析 |
每日趋势仓库 |
| arXiv |
Atom XML API |
AI/ML/NLP 最新论文 |
| Product Hunt |
GraphQL API + RSS 降级 |
最新产品 |
所有 Feed 汇总到一个统一列表,支持按来源筛选、全局搜索、已读/未读管理。基础上叠加三种 AI 分析模式:
- 每日趋势报告 —— 把当天所有 Feed 喂给大模型,生成热点解读、趋势分析、技术预测和开发者行动建议,SSE 流式输出。
- 单条深度解读 —— 对任意一条 Feed 右键,AI 给出「它是什么 → 为什么值得关注 → 对开发者的影响 → 要不要跟进」的四维分析。
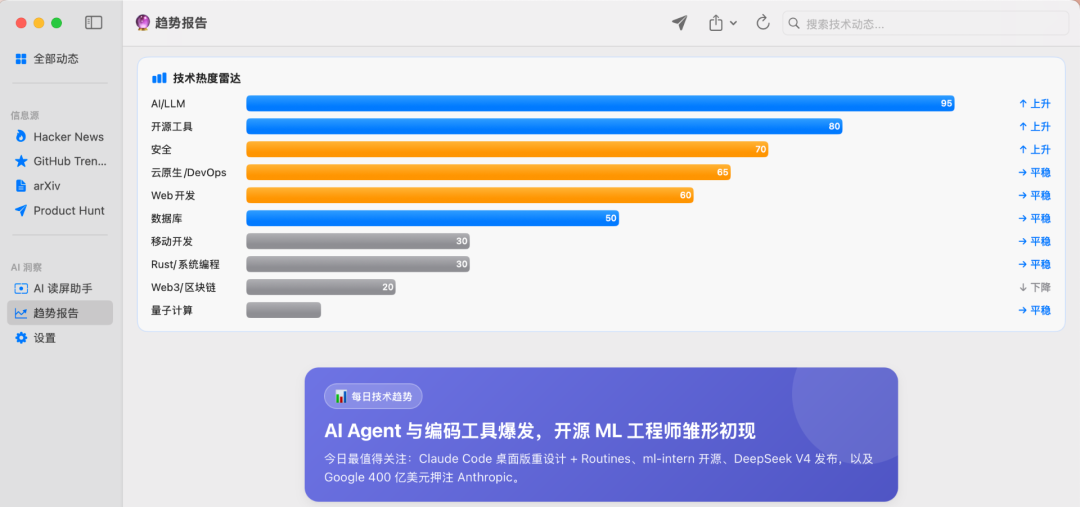
- 技术热度雷达 —— AI 对 10 个技术方向(AI/LLM、Web、移动端、云原生、Rust/系统、数据库、安全、开源工具、Web3、量子计算)打分 0-100,标注趋势,生成可视化雷达图。
你还可以配置定时任务,每天自动抓取 + 生成报告 + 推送到飞书群,团队早上打开群就能看到今天的技术趋势摘要。
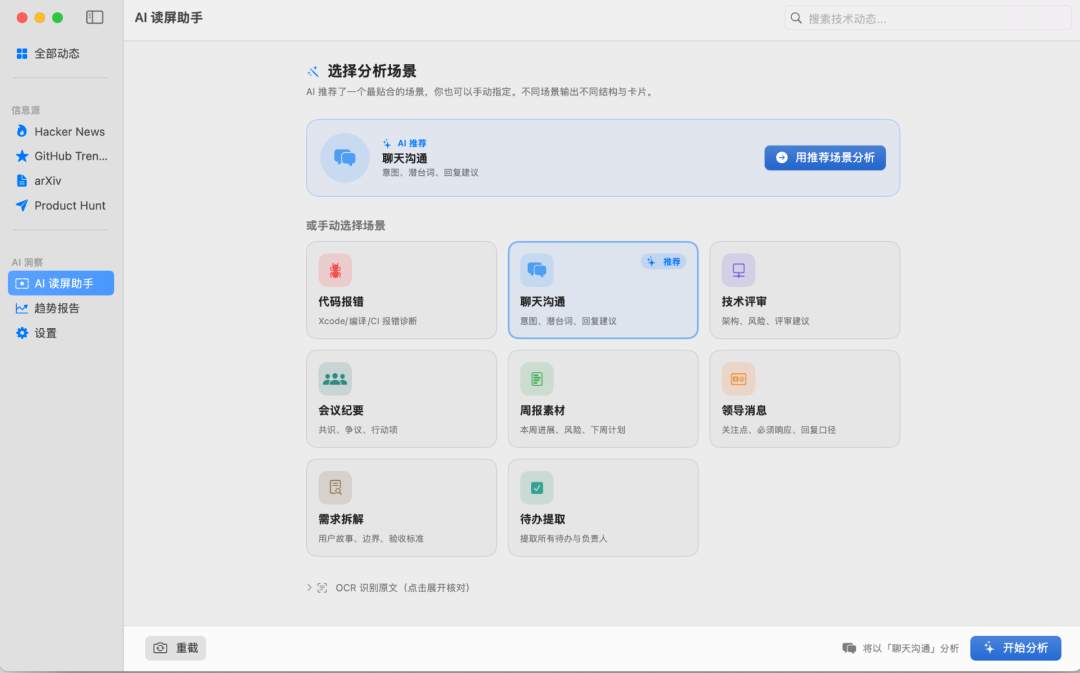
能力二:AI 读屏助手
按下快捷键 → 框选屏幕区域 → AI 自动识别内容 → 生成一张漂亮的结构化卡片。完整流程:
⌥ + Space 触发(可自定义快捷键)
→ 全屏半透明遮罩,鼠标拖拽选区
→ 本地 OCR 识别文字(Apple Vision,不上传图片)
→ AI 判断内容场景
→ 用户确认或切换场景
→ AI 按场景生成 HTML 卡片 + Markdown
→ 复制为图片 / 复制 Markdown / 保存文件
内置 8 个分析场景,每个有专属 Prompt 模板和卡片结构:
| 场景 |
识别内容 |
生成卡片 |
| 代码报错 |
IDE/终端/CI 报错 |
错误定位 + 原因分析 + 修复方案 |
| 聊天讨论 |
微信/飞书/钉钉对话 |
核心结论 + 待办 + 回复建议 |
| 技术评审 |
架构图/方案文档 |
方案要点 + 风险 + 评审建议 |
| 会议纪要 |
会议记录/讨论截图 |
议题 + 共识 + 争议 + 行动项 |
| 周报素材 |
看板/任务/进展 |
本周进展 + 风险 + 下周计划 |
| 领导消息 |
上级指示/问询 |
关注点 + 必须响应 + 交付物 + 回复建议 |
| 需求拆解 |
PRD/用户故事 |
用户故事 + 边界条件 + 验收标准 |
| 待办提取 |
任务清单/TODO |
结构化待办 + 优先级 + 责任人 |
卡片输出为精美的个性化卡片,支持 8 种场景主色、明暗主题切换,同时生成 Markdown 版本方便粘贴到飞书文档或笔记工具。
使用场景:解决哪些真实痛点?
场景一:早上 5 分钟了解技术圈
打开 Tech Brain,点一下「生成趋势报告」,AI 把四个社区的信息浓缩成一篇结构化分析。配合飞书推送,自动发到团队群,省掉「今天技术圈有什么新闻」的群聊问答。

场景二:群里一段讨论,秒变会议纪要
群聊截图 → ⌥ + Space → 框选 → AI 自动整理成「讨论主题 / 主要观点 / 已达成共识 / 争议点 / 行动项」,直接复制成图片发回群里。
场景三:领导发了一段话,拆解出行动项
截图领导消息,AI 分析:他真正关心什么、哪些要马上响应、应该产出什么材料、怎么回复稳妥。
场景四:一个报错截图,直接给修复方案
无论是 Xcode 编译失败还是 CI/CD 报错,截图扔给 AI,拿回来的是:错误类型 → 可能原因 → 定位步骤 → 建议命令 → 最小修复方案。
场景五:需求文档截图,自动拆成 SPEC
产品经理发来一段需求,截图后 AI 直接生成:用户故事 → 输入输出 → 边界条件 → 验收标准 → 前后端改动点 → 测试要点。
技术实现
零第三方依赖
整个项目没有引入任何第三方库——没有 Alamofire、SwiftyJSON、Kingfisher。纯 Apple 框架:
- 网络请求:
URLSession
- UI:SwiftUI
- 数据持久化:SwiftData
- 截屏:ScreenCaptureKit
- OCR:Apple Vision
- 密钥存储:Keychain
- 卡片渲染:WKWebView
- 并发:Swift Concurrency
安装包大小不到 3MB。在这个动辄几十 MB 的 Electron 应用时代,这才是纯原生 App 该有的样子。
全 Actor 并发模型
所有网络服务(喂料、OCR、分析等 9 个 Service)全部声明为 actor:
actor CardAnalysisService {
private let openAI = OpenAIService()
func suggestScene(ocrText: String, ...) async -> SceneType { ... }
func analyze(ocrText: String, scene: SceneType, ...) async throws -> CardDocument { ... }
}
不需要手动加锁,编译器保证线程安全。搭配 TaskGroup 实现四数据源并发拉取:
await withTaskGroup(of: [FeedItem].self) { group in
group.addTask { await self.hackerNewsService.fetch() }
group.addTask { await self.gitHubService.fetch() }
group.addTask { await self.arxivService.fetch() }
group.addTask { await self.productHuntService.fetch() }
// ...
}
状态机驱动的截屏流程
截屏 → OCR → AI 分析是一条复杂的异步链路,用一个显式状态机管理:
enum Stage: Equatable {
case landing // 待机
case capturing // 截图区域选择中
case recognizing // OCR 识别中
case scenePicking // 等用户选场景
case analyzing // AI 分析中
case showingResult // 展示结果
case failed // 失败
}
每个 Stage 对应一个视图面板,状态转换清晰可追踪。快捷键可以在任意非 capturing 阶段打断重来,无竞态问题。
HTML + Markdown 双段输出协议
让 LLM 直接输出结构化 JSON 的痛点大家都懂。我们换了个思路:让 LLM 输出 HTML + Markdown 双段文本,用分隔符切分。
<<<HTML>>>
<div class="container">
<div class="scene-banner">...</div>
<div class="card">...</div>
</div>
<<<MARKDOWN>>>
# 标题
## 摘要
...
HTML 天然宽松,没有 JSON 那种「少一个逗号全盘报废」的脆弱性。我们预定义了 CSS 组件类(.card、.scene-banner、.badge、.steps、.todo 等),LLM 只需要往里填内容,端侧保证渲染质量。解析器有 5 级容错策略,覆盖所有情况:
enum HTMLResponseParser {
static func parse(_ raw: String) -> Parsed {
// 1. 双分隔符都在 → 完美切两段
// 2. 只有 <<<HTML>>> → 剩余归 Markdown
// 3. 只有 <<<MARKDOWN>>> → 分隔符前归 HTML
// 4. 都没有但有 <div> → 整段当 HTML
// 5. 都没有也没 div → 当 Markdown,HTML 用 fallback 包裹
}
}
结果:解析失败率趋近于零,不再需要 JSON 重试 / sanitize / 校正循环。
18KB 手写 CSS 设计系统
卡片的视觉质量决定了用户愿不愿意分享。我们为 8 个场景手写了一套完整 CSS:
- Tailwind 风格的 utility class:间距、字号、颜色、圆角
- 语义化组件 class:
.card、.scene-banner、.badge、.kvp、.steps、.code-block
- 场景主色切换:
body[data-scene="codeError"] 切换 CSS 变量 --scene
- 明暗主题:
body[data-theme="dark"] 一键切换
- CSP 安全策略:
default-src 'none',禁止加载任何外部资源,杜绝 XSS
LLM 不需要关心配色,只需用对 CSS class,端侧保证视觉一致。
WKWebView 截图渲染管线
用户最终要的往往是一张图片。我们做了一条完整的截图渲染管线:
- 创建一个离屏
NSWindow,挂载 WKWebView
- 加载 HTML,通过 JavaScript
ResizeObserver 上报实际高度
- 动态调整 WebView 尺寸,等渲染稳定(防抖 + 8 秒超时守护)
- 调用
takeSnapshot,乘以 backingScaleFactor 实现 Retina 2x 输出
- 写入
NSPasteboard 或通过 NSSavePanel 保存
优雅降级策略
- Product Hunt 的 GraphQL API 需要 Token,拿不到自动降级为 RSS 解析
- SwiftData 数据库 schema 不兼容时自动降级为内存数据库,不 crash
- 场景推荐失败时返回
.auto,让用户自己选,永不抛错
- AI 返回格式异常时,5 级容错保证总能解析出可用内容
全局快捷键 + 窗口协调
通过 NSEvent.addGlobalMonitorForEvents 实现,需授权辅助功能。按下快捷键后的协调逻辑:
- 隐藏所有窗口 → 弹出全屏遮罩 → 用户拖拽选区
- 选区完成 → 恢复窗口,切换到截屏分析 Tab
- 按 Esc 取消则恢复窗口但不抢焦点
键盘布局使用 UCKeyTranslate + ANSI 键名 fallback,非拉丁键盘也能正确显示快捷键。
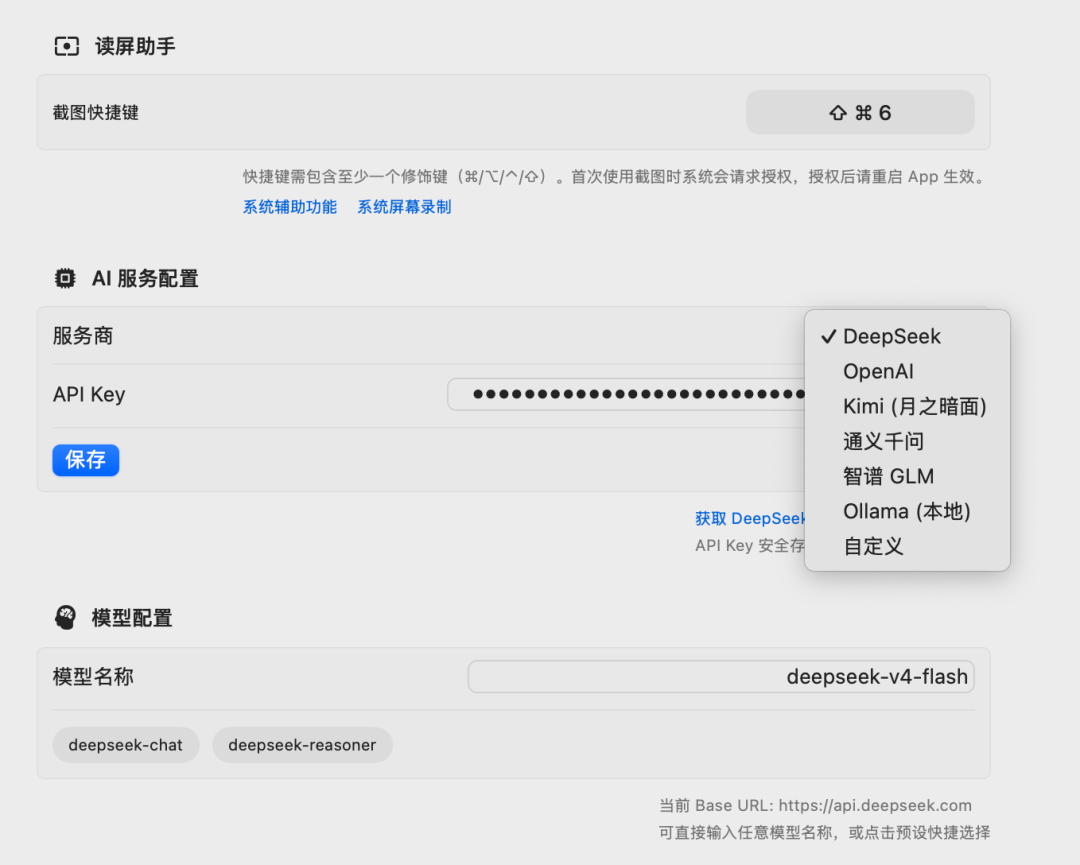
多模型兼容
通过 OpenAI-compatible API 协议,一套代码适配 7 种模型服务:DeepSeek、OpenAI、Kimi、通义千问、智谱 GLM、Ollama、自定义端点。API Key 存 Keychain,不写配置文件。
SSE 流式输出
使用 URLSession.bytes 的 AsyncSequence 逐行解析 SSE:
for try await line in urlSession.bytes(for: request).lines {
guard line.hasPrefix("data: ") else { continue }
// 解析 JSON,提取 delta content
// 同时通过 streamMarkdown() 实时提取可显示内容
}
用户看到的是打字机效果的实时输出,而不是等待 30 秒后一次性显示。
架构总览
┌─────────────────────────────────────────────┐
│ SwiftUI Views │
│ MainTabView / FeedListView / TrendReport │
│ ScreenshotCardView / WebCardView / Settings│
├─────────────────────────────────────────────┤
│ @Observable ViewModels │
│ FeedViewModel / AIViewModel / │
│ ScreenshotCardViewModel │
├─────────────────────────────────────────────┤
│ Actor Services │
│ HackerNews / GitHub / arXiv / ProductHunt │
│ OpenAI / ScreenCapture / VisionOCR / │
│ CardAnalysis / Scheduler / Feishu │
├─────────────────────────────────────────────┤
│ Apple Frameworks │
│ URLSession / ScreenCaptureKit / Vision │
│ SwiftData / Keychain / WKWebView │
└─────────────────────────────────────────────┘
每一层只依赖下一层,ViewModel 持有 Service 引用并协调业务逻辑。
设计决策的思考
为什么用 HTML 而不是 JSON 作为 LLM 输出格式?
最初也用 JSON Schema,但实际发现三点问题:不同模型对 JSON 的遵守程度参差不齐,需要大量后处理;卡片类型体系越做越复杂,新增场景要加 schema;视觉表现力有限。换 HTML 后,LLM 输出自由度大幅提升,容错更好。本质是 「约束在 CSS 层,自由在内容层」 的设计哲学。
为什么不用 Electron?
因为要频繁截屏、OCR、调系统 API。ScreenCaptureKit、Vision、Keychain、全局快捷键在 Electron 里要么不可用,要么需要 native 插件绕一圈。而且 Electron 包动辄 100MB+,一个工具类应用不该比用户的项目还大。
为什么选 Actor 而不是传统的 GCD?
Swift Concurrency 的 Actor 模型给编译期线程安全保证。9 个 Service 如果用 GCD,光是 DispatchQueue 创建、同步、回调嵌套就够折腾。actor 关键字一加,编译器替你干完所有事,代码更短,bug 更少。
隐私设计
- 截图图片不上传,只在本地处理
- OCR 由 Apple Vision 本地完成,不走网络
- 只有 OCR 识别出的文字发送给 AI 模型,原始图片不上传
- API Key 存 Keychain
- CSP 策略禁止卡片加载任何外部资源
写在最后
Tech Brain 目前是 v2.2.0,两条核心链路已跑通:技术趋势(四源聚合 → AI 报告 → 飞书推送)和 读屏助手(快捷键截屏 → 本地 OCR → 场景识别 → AI 卡片 → 复制分享)。整个项目零第三方依赖,纯 Swift + Apple 框架,安装包不到 3MB。
如果你也对信息过载感到头大,或者想体验「截图即分析」的工作流,欢迎试用。技术细节已在文中分享,开源地址:https://github.com/coder-brzhang/tect-brain-swift
你负责看到信息,它负责把信息变成判断、行动和结构化表达。
Tech Brain 需要 macOS 14 (Sonoma) 及以上版本。
 发表于 2026-4-27 17:03:05
|
查看: 196|
回复: 0
发表于 2026-4-27 17:03:05
|
查看: 196|
回复: 0
