过去两天,大家的朋友圈是不是被 GPT-Image-2 刷屏了?文字渲染极其精准,高密度信息图、复杂布局和美学 UI 一次到位,真实感爆棚。连社交媒体截图、高考试卷都能近乎一比一还原,这彻底颠覆了以往的文生图模型,解决了文字、信息图这些长期以来的痛点。
看到这些效果,很多人第一反应就是:设计师真要失业了……
而就在刚刚,兔展智能 放出大招:UniWorld-V2.5,居然直接“重现”了 GPT-Image-2 的某些惊艳案例。
不废话,直接看效果。用同一套提示词,我们来对比一下生成结果:
提示词:生成一个篆书碑刻拓片,内容是“由兔展智能首席科学家袁粒领导团队研发”

GPT-Image-2 生成效果

Nano-Banana-2 生成效果

UniWorld-V2.5 生成效果
可以说,在 InfoGraph、文字密集、图文交错等此前被公认为“AI 生图天花板”的场景上,UniWorld-V2.5 的完成度已经 对齐 GPT-Image-2,并 显著超越 其他国内外主流文生图模型。
更重要的是,UniWorld-V2.5 只需要非常简短的提示词,不再需要像过去那样提供极其复杂和详细的 prompt。你只需一句话,就能生成多样、复杂的视觉信息图,背后是一整套完整的视觉生成系统在做支撑。
接下来,我们一起见证更多场景。
高考数学卷:最难的中文测试,它过了
以前,AI 生图最令人崩溃的场景是这样的:结构化排版 + 高密度中文 + 复杂多样数学公式 + 曲线图 + 立体图,同时出现在一张图里。几乎所有文生图模型,在这个场景下表现都很不稳定,甚至根本无从下手。
UniWorld-V2.5 则表示:这只是基本功。直接上地狱级测试,提示词:
生成一张2025年高考数学理科试卷。

一张图里同时包含:选择题、填空题、解答题、函数图像、几何证明……密密麻麻一整页,格式规范,字迹清晰,连答题线和页码都一个不落。这已经不是“像不像”的问题,而是“能不能直接拿去给学生考试”的问题。
与此类似的,对中文排布要求很高的场景“简历生成”,效果也同样可圈可点:

这种文字密集生成能力,此前的主流模型几乎无法做到。在中文密集文字和复杂排版领域,这是前所未有的降维打击。
GUI 布局:超真实的 APP 界面生成,也过了
想要 AI 生成一个真实感的社交媒体 APP 界面?传统模型生成的界面要么布局错乱,要么文字胡言乱语。现在,给 UniWorld-V2.5 布置作业,让它一句话生成一套完整、可乱真的社交媒体界面及布局。
1、抖音直播带货
主播、商品弹窗、价格、实时弹幕、打赏特效,细节真实到“细思极恐”。


2、小红书探店
咖啡馆照片、店名、推荐指数、评论、点赞、导航栏,一个不落,调性精准。

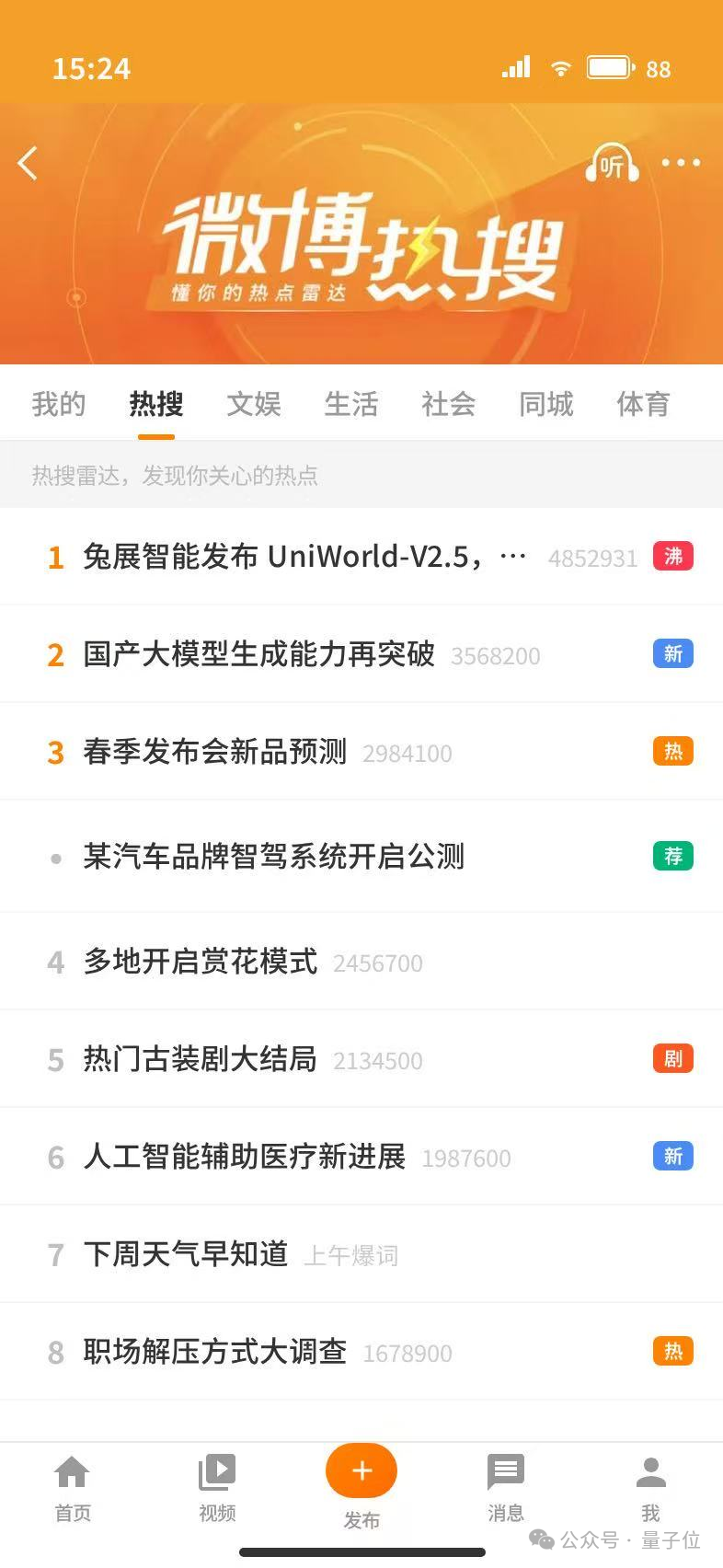
3、微博热搜
热点头条、热度值、标签、按键等,全都可以直接生成,以假乱真。
4、YouTube 视频页
博主信息、播放量、推荐列表、评论区,UI 细节精准到让人分不清真假。
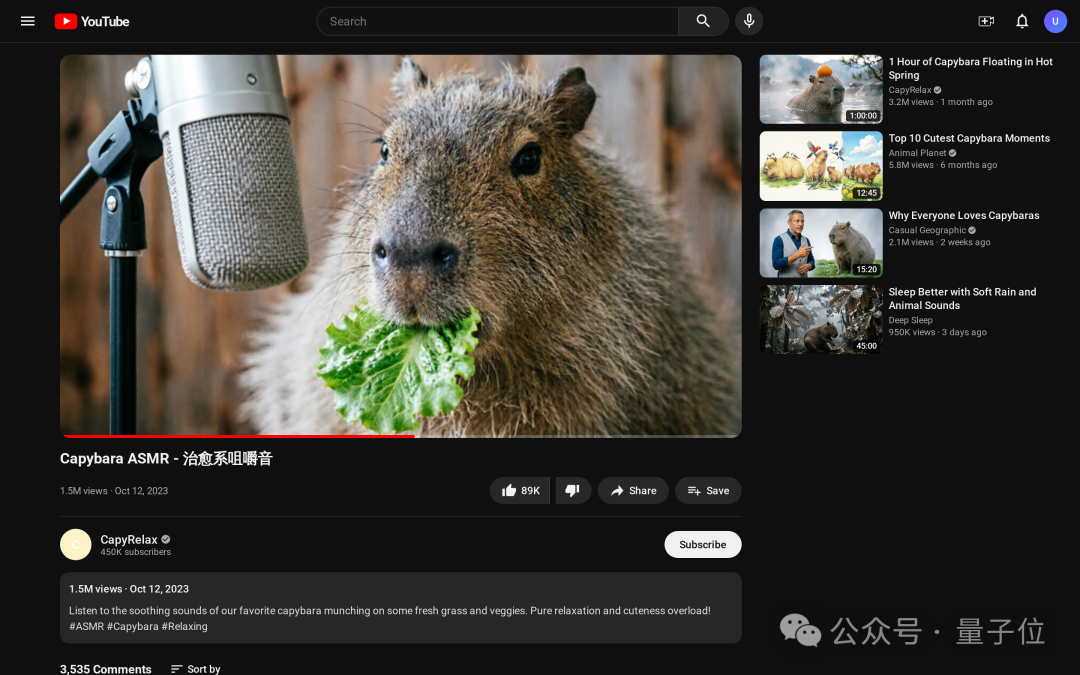
这哪里是“生图”?这简直是“赛博截图”。这么看来,UniWorld-V2.5 理解的不是像素,而是 产品逻辑和用户场景本身。
InfoGraph 信息图:AI 生图的终极考场,很惊喜
高密集、复杂的信息图是公认的 AI 生图“无人区”。它要求模型同时理解数据、图表、文字排版和逻辑关系,信息密度越高,难度越大。
让 UniWorld-V2.5 尝试露一手,它交出的作业是这样的:
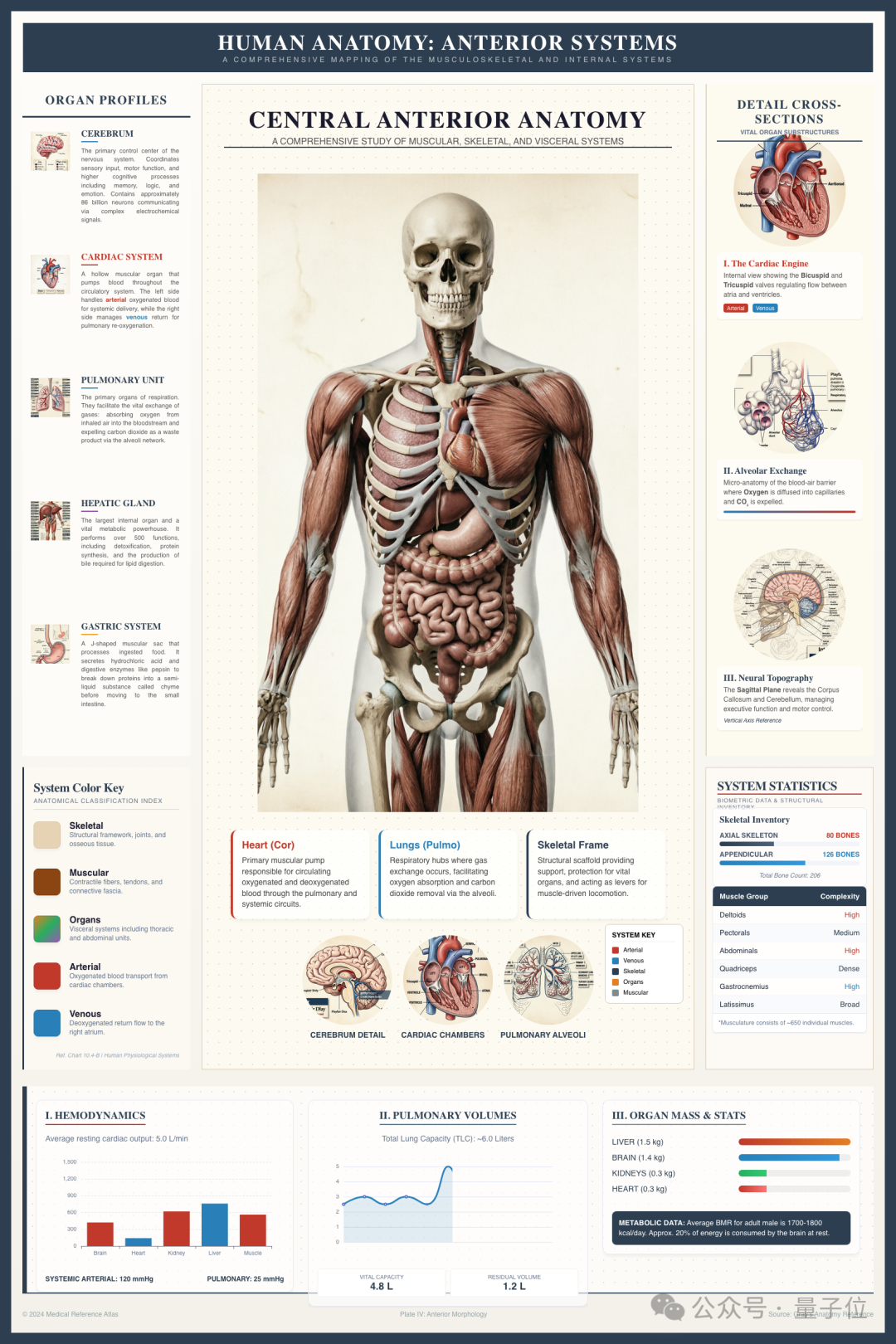
人体前侧解剖系统全图:
太阳系全貌信息图:

绿叶解剖信息图:
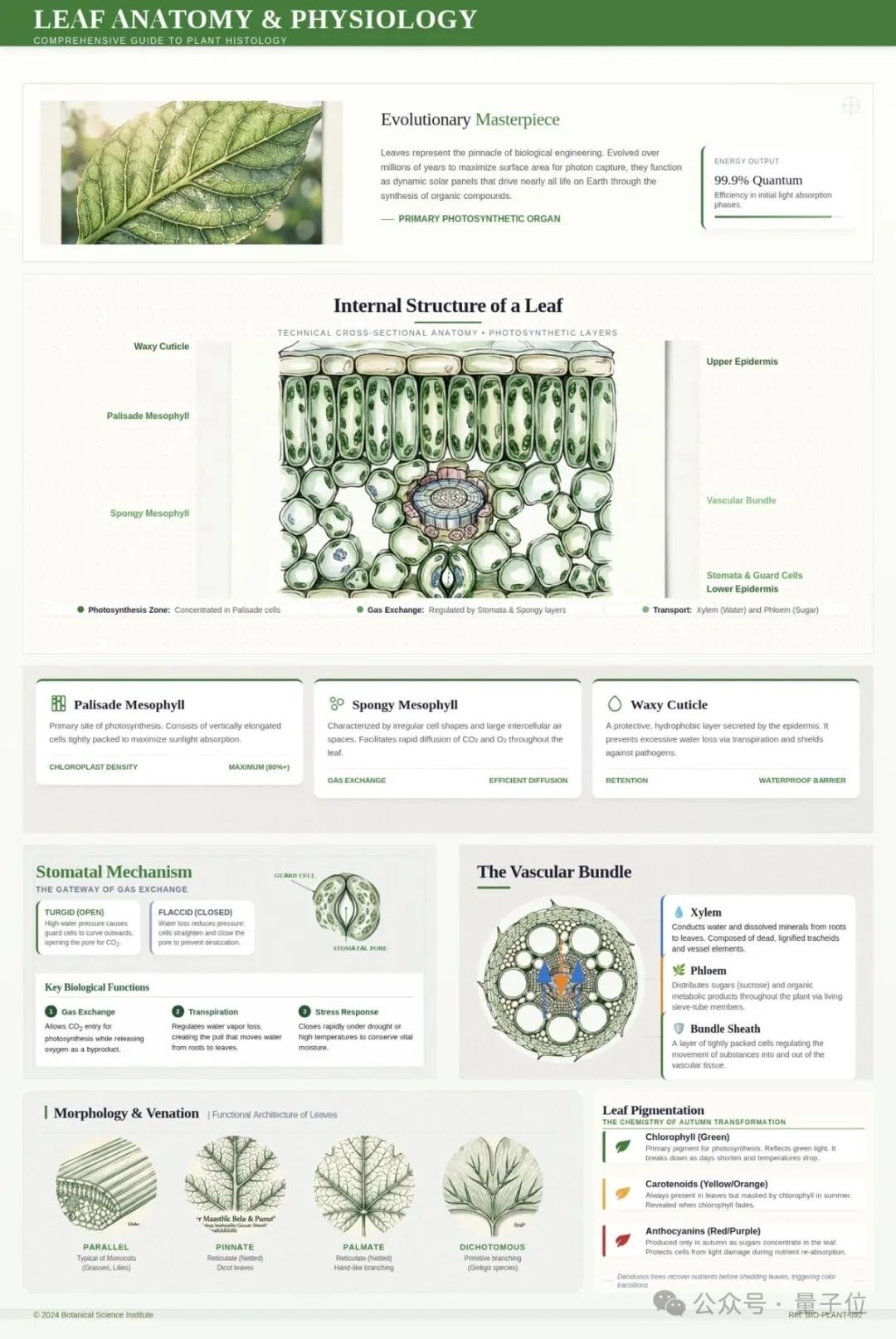
肌肉、骨骼、内脏等细节可视化呈现,中英文混排清晰,数据图表严谨。它不是在“画”一张看起来像的图,而是在 理解并构建一个完整的信息体系。这种能力才是模型真正的技术护城河,标志着它从一个“生图工具”向“会思考、懂设计的视觉生成系统”的跨越。
海报与设计:考察商业级完成度
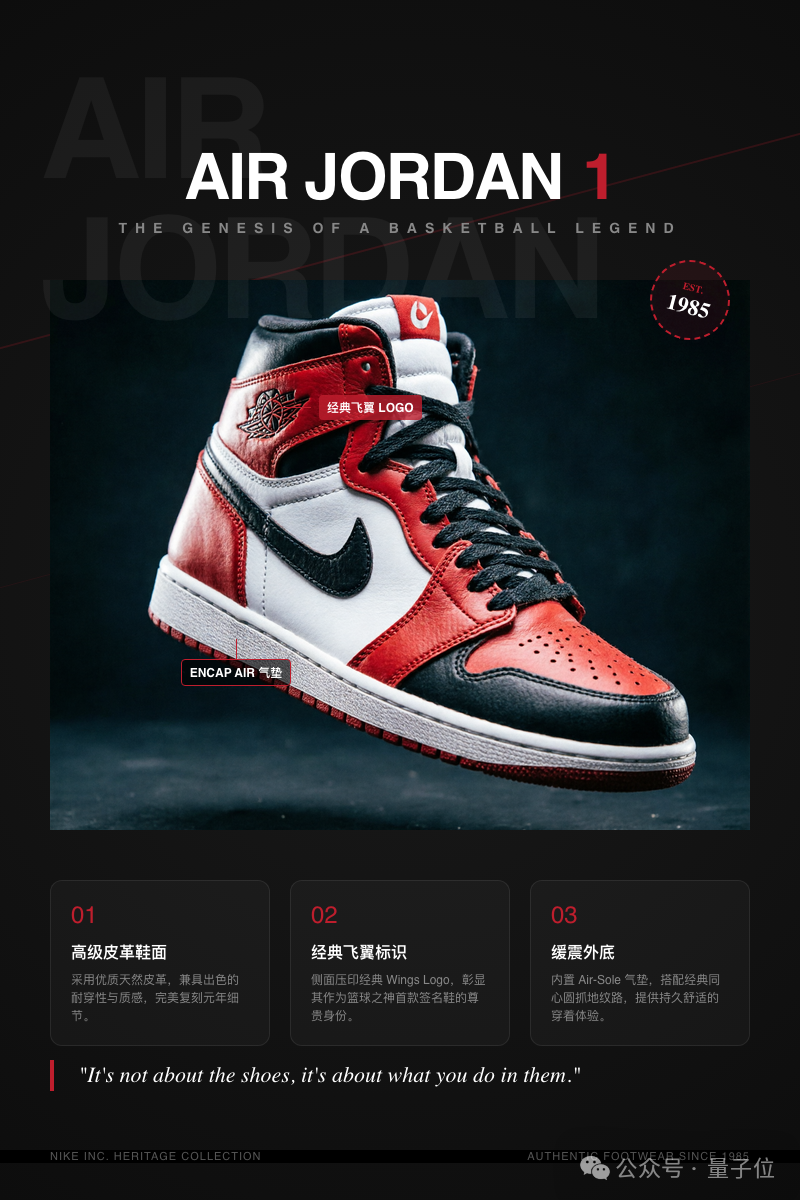
让它试着画一张 Air Jordan 1 产品宣传海报。鞋的质感、中文文案、版式层次、品牌调性……看看这商业级完成度:
再来看一张苹果手机的宣传海报。字体、排版、风格、专业摄影风格图片,美学和质感可以说是拉满了:

国产视觉 AI 的突围:在 OpenAI 与 Google 的身影前“抢跑”
UniWorld-V2.5 的横空出世绝非偶然,它背后站着一位视觉 AI 深水区的“领跑者”:兔展智能。
深圳兔展智能科技有限公司,由 董少灵 在 北京大学 宿舍于 2014 年发明最早的 H5 工具而创立。后来到了 2022 年,其与北京大学年轻一代视觉 AI 领军人才 袁粒 等二次创业。公司总部位于深圳,已服务超 4100 万家企业用户。
截至目前,兔展智能已获深创投、腾讯、龙岗金控、嘉道资本、中国风投、青岛人工智能基金、招商局创投等头部机构投资,完成 F 轮融资。它还是国家高新技术企业、国家级专精特新“小巨人”企业、大湾区最具潜力独角兽、广东省首个“AI 国家级高技能人才培训基地”。
兔展智能的 UniWorld 系列模型,为什么能做到“理解即生成”?因为它的技术底座早已遥遥领先:
- 自研“兔灵”大模型:广东省首个完成备案的视觉空间智能大模型,在视觉理解、压缩重建等核心领域实现多项 SOTA(业界最佳)技术突破。
- 开源第一:其开源的 Open-Sora Plan 是全球最早的开源视频生成模型之一,曾连续多日登顶 GitHub 全球趋势榜榜首,单模型超过 2600 万次下载,2024 年视觉大模型代码引用量全球第一,被字节、腾讯、华为等大厂广泛采用。
- 架构创新:UniWorld 系列是国内最早实现“理解、生成、编辑”统一架构的视觉空间智能模型。其中,UniWorld-V1 早于 Nano Banana 三个月推出,UniWorld-V2 在权威评测(GEdit-Bench)中综合性能 超越 OpenAI 的 GPT-Image-1,多项关键指标亦一度优于谷歌的 Nano Banana 系列模型,并入选 2025 年西丽湖论坛深圳市七大科技关键成果、广东省人工智能与机器人科技进步一等奖第一名。
- 国际领跑:其推出的 Video LLaVA 模型成为 Google Gemini Pro 技术报告中作为对比基准的视觉理解模型,标志着技术获得国际顶级认可。LLaVA-CoT 模型则在行业内首次提出视觉慢思考架构,让模型能够进行自主、系统化地多阶段推理,突破了传统视觉模型单步响应的局限,该研究成果被 ICCV 2025 会议收录(计算机视觉领域的三大顶会之一),获得同行评审的权威认可。
- 国产生态:与 华为昇腾 深度合作,是昇腾 910C 芯片全球首个大规模用户,打造了行业最早 100% 基于昇腾架构的视觉生成模型 Open-Sora Plan V1.5,突破了算子适配、大规模训练等一系列“卡脖子”问题。这不仅是一次技术胜利,更是为中国 AI 基础设施的自主可控,提供了一个完整的可行范本。
值得一提的是 UniWorld 系列发布的历史时间线:
- UniWorld V1 比 Nano Banana 早发布整整 3 个月,且同步开源。
- UniWorld V2 在 Nano Banana Pro 发布之前,已是 行业第一。
- UniWorld V2.5,是这条路上的最新一站,突破了 高密集文字、信息图、图文交错、结构化生成 等一系列领域难题。
面向高度结构化且依赖复杂世界知识推理的生成任务,传统的一句话出图范式已难以支撑。区别于传统 prompt-to-image 的范式,团队将 超过 80% 的 token 预算 用于意图理解、推理与布局规划,相当于引入资深的“总设计师”来全程指挥和全局控制。这从源头上保证了生成的质量,也体现了理解与生成统一的多模态范式优势。
其中,兔展智能首席科学家、北京大学 袁粒 老师,及其博士生 晏志远 等人,深度参与了核心能力的设计与实现,是 V2.5 关键突破的重要贡献者。
兔展智能一直围绕着让人类叙事更生动高效的使命,投入到最前沿的视觉智能创新。据悉,兔展智能也将在不久之后,推出 视觉空间智能路线为基础的世界模型。
站在世界舞台的国产模型,等你免费体验
AI 生图的上限,远比我们想象的要高。UniWorld-V2.5 的发布,用实力证明了在中文语境和超复杂逻辑场景下,国产模型已经具备了站在世界舞台中央的底气。
设计行业的“一句话出图”,过去是由 GPT-Image-2 引发的焦虑。现在,这个能力在国内坚实落地了,而且是以 自主可控、可微调、国产算力 的形式落地的。品牌方、内容平台、电商商家、医疗科普机构、教育出版机构……任何需要大规模生产视觉内容的场景,过去需要设计团队花数小时完成的工作,现在仅需要一句自然语言。
更重要的是这件事的示范意义:在多模态图像生成这条赛道上,中国不再只能是跟跑。 一个从北京大学走出来、深耕视觉大模型 4 年的团队,今天交出了这份答卷。
那么,最硬核的来了:这么强的“怪兽”模型,现在 开放免费体验 了!想亲身体验这种“一句话出图”的魔力吗?在 [云栈社区](https://yunpan.plus) 上,你可以和其他开发者一起探讨 UniWorld-V2.5 的更多玩法。
👇 独家体验传送门,手慢无 👇
UniWorld-V2.5 体验入口:https://uniworld.rabbitpre.com/
本文系量子位获授权刊载,观点仅为原作者所有。
 发表于 2026-4-27 17:21:10
|
查看: 371|
回复: 0
发表于 2026-4-27 17:21:10
|
查看: 371|
回复: 0
