
你有没有想过,不用联网、仅用一张消费级显卡,就能在个人电脑上拥有一个「边看、边听、边说、还能主动提醒」的类人 AI 助手?它既能实时感知环境变化、同步理解你的意图,又能全程保护隐私。
这就是 MiniCPM-o 4.5 所能做到的。在技术创新下,它仅凭 9B 参数,实现了业界首个端到端全双工全模态大模型,让端侧 AI 普惠成为现实。自 2026 年 2 月模型发布以来,其在 Hugging Face 上的下载量已突破 25 万+。
今天,面壁智能联合 OpenBMB 开源社区、清华大学 THUNLP 实验室和 THUMAI 实验室正式发布 MiniCPM-o 4.5 技术报告,首次公开面壁智能在全双工全模态交互领域的核心技术——Omni-Flow 流式全模态框架。
关于此框架的更多技术细节,你可以在相关的技术文档中找到深入解析。
在技术报告发布的同时,MiniCPM-o 4.5 同步推出在线体验 Demo、全模态全双工 API、端侧安装包 Comni 和 Demo 仓库。
在线体验 Demo
在线 Demo 是 MiniCPM-o 4.5 的原型示例网页应用,展现传统轮次交互、语音双工交互、视频双工交互三大类应用原型,并完整开放模型支持的全部配置,包括 prompt 和参考音频设置。Demo 可在手机、电脑端直接访问,并配套提供排队、录制、保存、分享、回看等功能,提升用户体验。
全模态全双工 API
同步开放的 MiniCPM-o 4.5 API 支持全模态全双工实时交互,全双工下无需 VAD 机制控制对话轮次,便于开发者基于 MiniCPM-o 4.5 构建应用。API 使用 https://api.modelbest.cn/minicpmo45/v1/ 端点,目前免费开放。详细使用方式见 API 文档。
Windows / macOS 端侧安装包 Comni
MiniCPM-o 4.5 已基于 llama.cpp 完成模型量化和推理性能优化,实测最低 12GB 显存的 RTX 5070 即可流畅运行全双工模式(RTF0.4),极大降低了个人端侧部署的准入门槛。
为进一步降低端侧部署的操作门槛,桌面软件 Comni 集成了模型下载、环境安装和 Demo 运行能力,提供 Windows / macOS 版本。在电脑上启动本地服务后,除了在本地浏览器中使用外,强烈推荐通过手机用局域网连接,进行全双工视频通话。软件包下载链接如下:
(上方视频展示了 MiniCPM-o 4.5 在个人笔记本上的完整部署与运行过程,包括全双工语音对话、实时视觉理解、主动提醒等能力演示)
Demo 仓库开源和 Linux 部署
上述 Demo 的全栈代码已开源,Linux 用户可克隆代码仓并部署完整的 Demo 服务。这也是首批可本地部署的全双工全模态交互演示项目之一。
为什么「全双工」是 AI 交互的下一站?
人类交流是流畅、并行的。我们边听边思考,甚至可以打断对方。
但过去,AI 与人类的交互模式是半双工的,像用对讲机:你说完,它才能处理;它说的时候,又听不见你的新指令。AI 与人类的不同频,使得大多数用户无法在与大模型产品的交互中获得良好的体验感,甚至由于交流的「时空割裂」逐渐失去耐心。长此以往,大模型在多模态场景的落地无疑大大受阻。
而 MiniCPM-o 4.5 在全球范围内首创「全双工全模态」,模型能在持续感知环境(看视频、听声音)的同时进行思考和响应,这让 AI 从一个被动的工具变成了一个可以主动帮助人类的真正助手。
这背后离不开面壁智能与清华大学共同研发的 Omni-Flow 流式全模态框架。本次技术报告也首次披露了 Omni-Flow 的技术核心:
简单来说,它创造了一个共享的「时间轴」,把视觉、音频、语言等所有信息流都对齐到毫秒级的时间片上。模型在每个极小的时间片内,完成一次「感知-思考-响应」的循环。这套机制从底层赋予了模型持续感知和即时反应的能力,是 MiniCPM-o 实现全双工的基石。
此外,MiniCPM-o 4.5 本次发布并坚持开源可本地部署的 Web Demo,这对开发者与用户意味着:
- 绝对的隐私安全:全天候陪伴式 AI 会接触大量敏感信息。数据不出本地,是最好的隐私保护。
- 断网也能跑的可靠性:没有网络也能用。即使在隧道、野外,你的 AI 助手也不会「掉线」。
- 开发者的游乐场:完整的 Demo 前后端代码已开源。你可以基于此快速构建自己的全双工多模态应用,无论是智能座舱、无障碍辅助还是具身智能,MiniCPM-o 4.5 都能成为你将想象变成现实的助推器。
技术报告深度解读:揭秘 MiniCPM-o 4.5 的实现之道
MiniCPM-o 4.5 采用端到端全模态架构,总参数量 9B。核心设计包括:
- 全模态端到端架构:多模态编码器/语音解码器与 LLM 通过隐藏状态紧密连接,在高压缩率下实现通用视觉、听觉感知和语音对话。
- 时分复用机制:将并行多模态流划分为周期性时间片内的顺序信息组,实现高效的流式处理。
- 可配置语音建模:支持文本+音频双系统提示,通过参考音频和角色提示词即可实现声音克隆角色扮演。
- 双模式支持:同一模型支持传统的轮次交互模式与 Omni-Flow 全模态全双工模式。
实时交互:Omni-Flow 流式全模态框架
传统多模态模型将交互视为一系列孤立的回合,而 Omni-Flow 将其重塑为一个连续的过程。
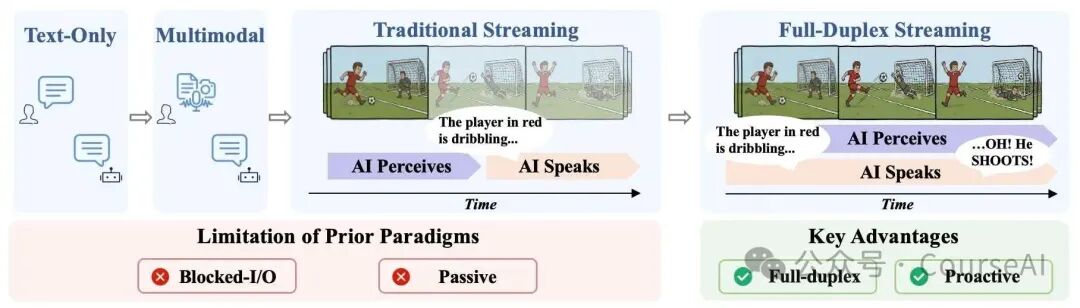
图1:交互范式的演进,MiniCPM-o 4.5 实现了最右侧的全双工流式交互
如图所示,Omni-Flow 将视觉、音频输入流和模型的文本、语音输出流,在时间上进行精确切片和对齐。模型不再是被动地等待用户输入完成,而是以极高的频率(例如每秒一次)持续刷新自己的“世界观”,并自主决定在哪个时间点介入(说话或提醒)。这套机制原生支持了打断、插话等高级交互行为,彻底摆脱了对外部 VAD (语音活动检测) 等辅助工具的依赖。
端到端架构:9B 模型如何协同工作?
为了实现 Omni-Flow,面壁智能团队设计了一套高效的端到端全模态架构,总参数量 9B。
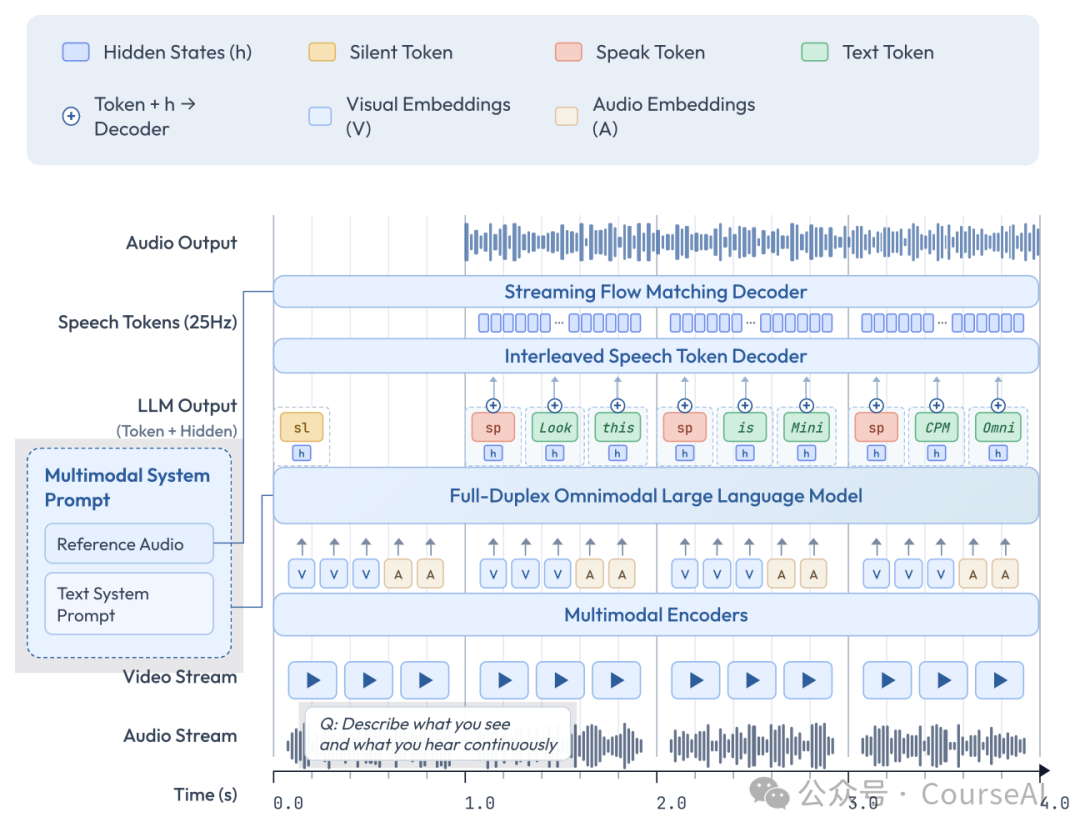
图2:MiniCPM-o 4.5 的端到端全模态架构
其核心组件包括:
- 视觉编码器(0.4B): SigLIP-ViT,负责「看」。
- 音频编码器(0.3B): Whisper-Medium,负责「听」。
- LLM 基座(8B): Qwen3-8B,负责「思考」和理解。
- 语音 Token 解码器(~0.3B): 轻量级 Llama 架构,负责将 LLM 的「想法」(文本)转化为语音单元。
- 声码器: 将语音单元合成为最终的波形。
这个架构最巧妙的设计之一是:LLM 基座只生成文本 Token,而专业的语音合成任务「外包」给了一个更小、更专业的语音解码器。这避免了让大模型直接处理复杂的声学任务,从而保证了其核心的语言和推理能力不受损害。同时通过各模块的token级稠密连接,保证了模型能力的高上限。
为实时而生:TAIL 语音生成方案
流式语音的一大难题是延迟。为了让语音听起来自然,模型通常需要「预读」一大段文本,但这会导致输出的语音远远滞后于用户的输入。在需要「即时打断」的全双工场景里,这是致命的。
因此,面壁智能团队提出了 TAIL(Time-Aligned Interleaving)方案,可以让每个语音块的生成都紧紧跟随其对应的文本块,而不是让文本「抢跑」太多。同时,通过一个轻量级的「预读」(pre-look) 机制,解决了跨词发音的连贯性问题。最终,TAIL 在保证音频流畅悦耳的同时,将语音输出与交互发生的延迟降到了最低。
性能表现:9B 模型硬刚业界顶尖
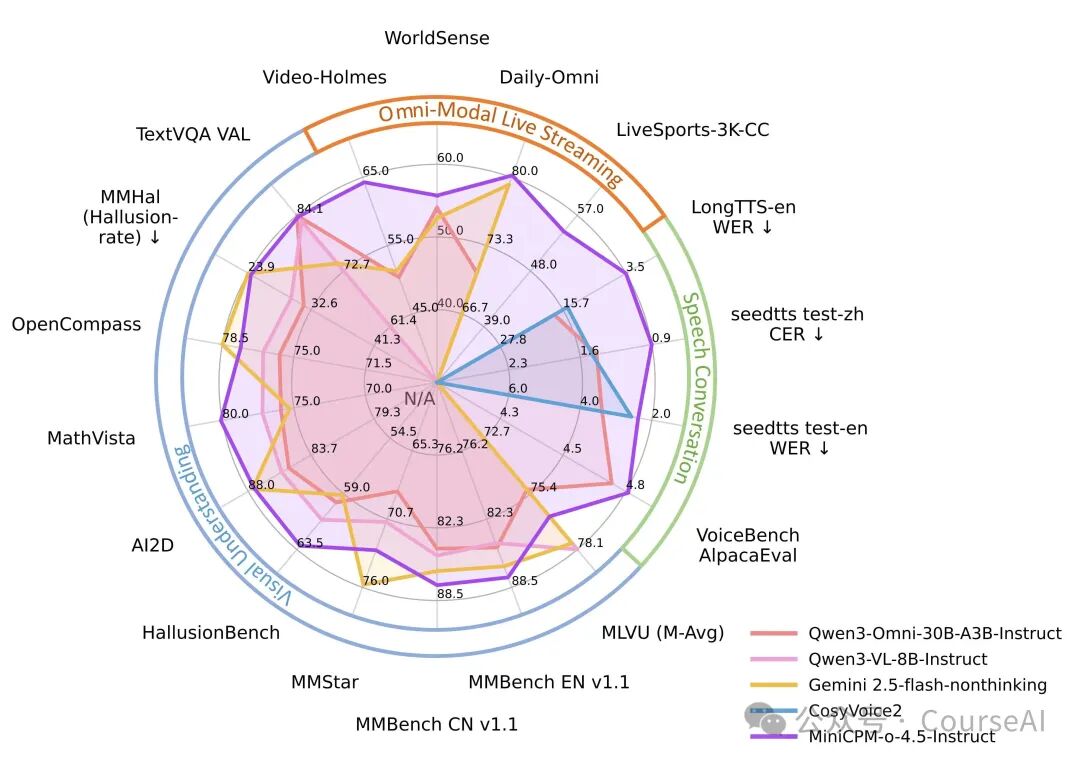
参数规模小不等于模型性能弱。MiniCPM-o 4.5 在多个维度的评测中,展现了与 SOTA 大模型掰手腕的实力。这种在有限算力下追求极致性能的开源实战经验,无疑为广大开发者提供了宝贵的参考。
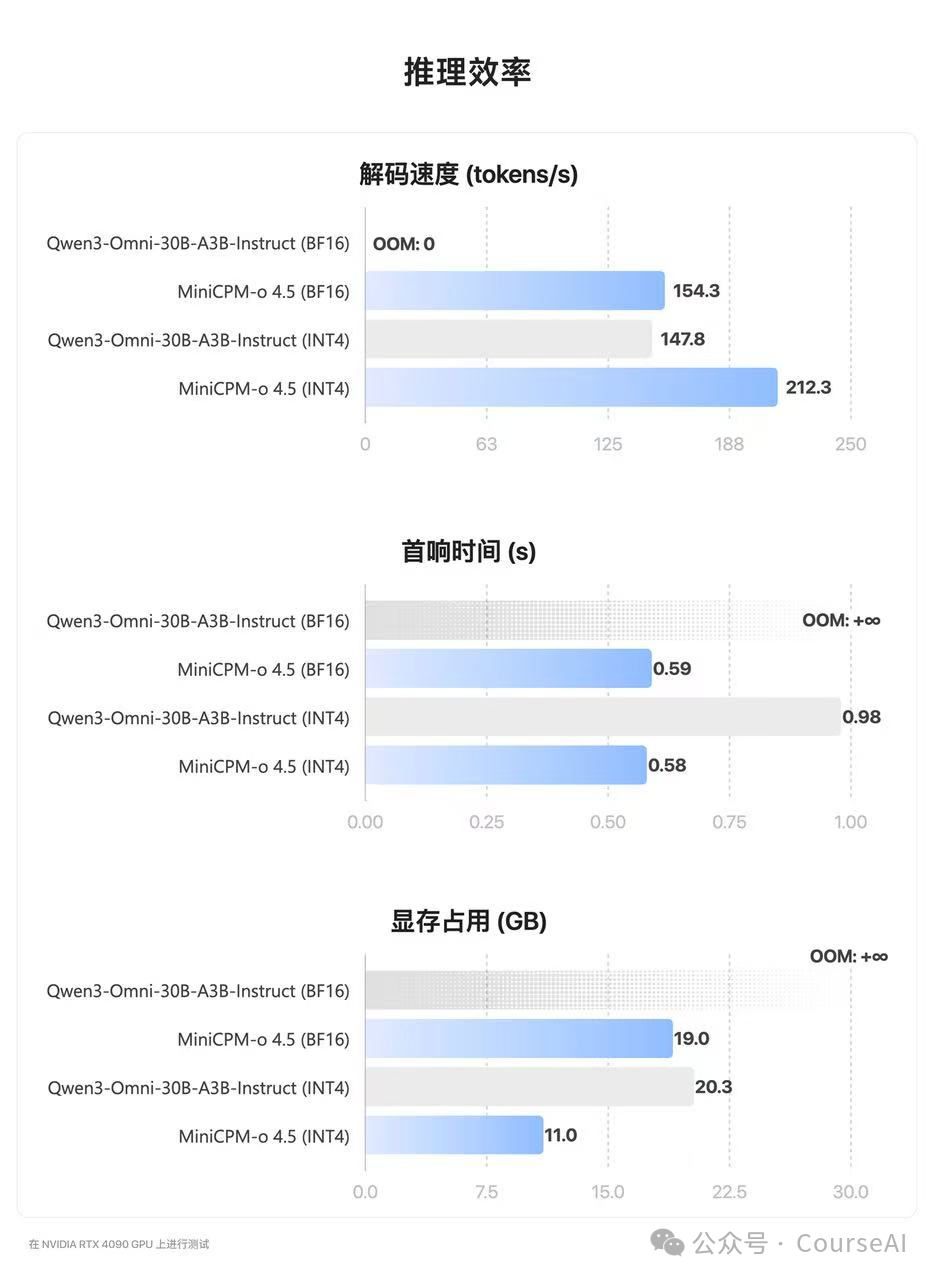
推理效率:在显存方面,MiniCPM-o 4.5 的 INT4 量化版仅需 11GB 显存即可运行,几乎是 Qwen3-Omni INT4 版本的一半,使得其在消费级显卡上的本地部署成为可能。在性能方面,MiniCPM-o 4.5 的推理速度也更快,其 INT4 版本的解码速度达到了 212 tokens/s,比 Qwen3 快了 40% 以上,响应延迟更低。
综合视觉能力: 在 OpenCompass、MMBench 等多个视觉基准上,9B 的 MiniCPM-o 4.5 与 Gemini 2.5 Flash 表现相当。
| Benchmark |
MiniCPM-o 4.5 (9B) |
Gemini 2.5 Flash |
Qwen3-Omni-30B-A3B |
| OpenCompass |
77.6 |
78.5 |
75.7 |
| MMBench EN v1.1 |
87.6 |
86.6 |
84.9 |
| MathVista |
80.1 |
75.3 |
75.9 |
| HallusionBench |
63.2 |
59.1 |
59.7 |
全模态与全双工交互: 在需要联合音视频理解的基准上,MiniCPM-o 4.5 全面超越了 Gemini 2.5 Flash 和 Qwen3-Omni。在全双工视频理解基准 LiveSports-3K-CC 上,其胜率(54.4%)更是大幅领先专用的流式视频模型。
| Benchmark |
MiniCPM-o 4.5 |
Gemini-2.5-Flash |
Qwen3-Omni-30B |
| Daily-Omni |
80.2 |
79.3 |
70.7 |
| Video-Holmes |
64.29 |
51.3 |
50.4 |
| LiveSports-3K-CC (Win Rate) |
54.4% |
– |
– |
语音生成:无论是中文还是英文,MiniCPM-o 4.5 的语音生成质量(字符/单词错误率更低)和情感表现力都优于 Qwen3-Omni 和业界领先的 CosyVoice2。
| Benchmark |
MiniCPM-o 4.5 |
CosyVoice2 |
Qwen3-Omni-30B |
| SeedTTS Test-ZH (CER↓) |
0.86 |
1.45 |
1.41 |
| SeedTTS Test-EN (WER↓) |
2.38 |
2.57 |
3.39 |
| Expresso (Emotion↑) |
29.8 |
17.9 |
– |
真 · 全双工,潜力无限
全双工全模态大模型不是一个遥远的概念,而是会催生一系列全新的应用,例如:
- 主动式伴侣:在你烹饪、修理或运动时,给你实时的指导和提醒。
- 无障碍辅助:成为视障人士的「眼睛」,为视障人士持续观察环境,主动播报绿灯亮起、水杯将满等关键环境信息,帮助他们安全生活。
- 智能座舱:持续监控路况和驾驶员状态,主动提示「左侧有可用车位」并引导泊车,提供更智能、更及时的安全预警和驾驶辅助。
- 具身智能:作为机器人的「大脑」,持续感知动态环境并自主决策交互时机。
这些场景的共同点是:需求并非一次性问答,而是需要 AI 作为「沉默的观察者」和「及时的提醒者」融入动态生活流——这正是传统轮次对话模型无法胜任的。
MiniCPM-o 4.5 是原生全双工模型,摆脱了对VAD的依赖。这意味着:支持 general 声音感知(环境噪音、音乐等,不仅是语音);画面变化跟进更快(native全双工,无需等上句说完);AI 说话时可被实时引导改变内容。
当然,MiniCPM-o 4.5 目前还存在可提升空间,如长时间交互的稳定性、主动行为的丰富性等。作为云栈社区关注的焦点,多模态智能的下一个前沿,不仅在于模型能力的扩展,更在于重新思考智能表达的交互范式。Omni-Flow 和 MiniCPM-o 4.5 是面壁智能在这一方向上的关键探索。
开放与协作将持续推动人机交互演进。欢迎所有开发者试用模型、参与讨论、贡献代码,共同探索人机交互的未来!
 发表于 2026-4-29 04:07:40
|
查看: 250|
回复: 0
发表于 2026-4-29 04:07:40
|
查看: 250|
回复: 0
