沉浸式面试复盘:并发集合从懵圈到顿悟的血泪史
哈喽,我是老杨,一个在Java圈摸爬滚打8年的老程序员。今天想和你们唠唠前阵子面试阿里巴巴Java资深工程师的经历,特别是被问到并发集合的时候,我是怎么从一脸懵圈到后来顿悟的。
说实话,这次面试真的让我“破防”了——并发集合这块平时用得贼溜,没想到面试官问得那么深,差点没扛住。不过好在后来回去一顿猛补,终于把这块给整明白了。今天就把我的血泪经验分享出来,希望对你们有帮助!
你们有没有遇到过那种情况:某个知识点平时工作里用得贼溜,但让你讲原理的时候就卡壳了?有的话在评论区扣个“1”,让我看看有多少人和我一样惨!
一、战前部署:知己知彼,准备开干!
公司画像:阿里巴巴的核心挑战
说到阿里巴巴的技术栈,那可真不是一般的复杂。我之前就研究过,阿里的Java系统主要面临这么几个核心挑战:
- 交易链路的极致高并发
淘宝、天猫双十一那种流量,啧啧,简直是变态级别。去年双十一峰值QPS直接冲到了58万笔/秒,这种流量冲击下,并发集合的线程安全问题就显得尤为关键。一旦出现并发问题,轻则数据不一致,重则超卖,后果不堪设想啊!
- 分布式事务的强一致性
阿里的核心业务都是分布式架构,一个订单创建可能涉及十几个微服务。这种场景下,并发集合的线程安全、可见性、有序性问题就成了绕不开的坎。
- 技术栈偏好
阿里Java技术栈主要基于:
- Spring Cloud Alibaba生态
- Sentinel做限流熔断
- Seata做分布式事务
- Redis、RocketMQ、Nacos等中间件
- 内部自研的Dubbo、Arthas等工具
说实话,阿里面试官最喜欢问的就是原理性问题,比如“ConcurrentHashMap为什么是线程安全的?”、“CopyOnWriteArrayList适合什么场景?”这类问题,为啥?因为他们要筛选的是真正懂原理、能解决问题的人,而不是只会调API的CRUD小子。
面试官心理前置预判
结合阿里的业务特性和技术栈,我提前拆解了这次面试的筛选逻辑:
「筛人题」:并发集合基础认知
这类题目就是用来淘汰那些“知其然不知其所以然”的候选人的。如果你只用过HashMap、ArrayList,讲不清线程安全的具体原理,那基本就凉凉了。
「定级题」:并发集合原理深度
能讲清ConcurrentHashMap的分段锁/synchronized+CAS机制、CopyOnWriteArrayList的读写分离思想,OK,基础不错,可以进入下一轮。
「定薪题」:并发集合实战应用
能结合业务场景讲清楚并发集合的选型依据、性能对比、线上问题排查,啧啧,这种人可是香饽饽,直接锁定高薪区间!
核心打分标准:
- 原理理解深度>API调用经验
- 问题排查能力>背书能力
- 业务适配思维>通用方案
自我认知梳理
我(老杨):
- 8年Java开发经验,主攻高并发系统架构
- 之前在一家电商公司负责交易系统,日均订单量50万+
- 擅长:并发编程、性能优化、分布式系统设计
- 不足:并发集合原理只停留在使用层面,没有深入研究过源码
说实话,这次面试也是我的一个转折点。之前一直觉得自己并发编程还行,结果被阿里面试官一问,直接暴露了“只会用、不懂原理”的短板。后来我花了整整两周,把ConcurrentHashMap和CopyOnWriteArrayList的源码从头到尾撸了一遍,这才算真正整明白。
定制化备战策略
针对阿里的技术栈和面试风格,我做了以下针对性准备:
- 并发集合源码深挖
把Doug Lea老爷子的ConcurrentHashMap源码从头到尾撸了一遍,重点关注:
- JDK 1.7的分段锁实现
- JDK 1.8的synchronized+CAS优化
- size()方法的并发统计机制
- 并发扩容时的transfer()方法
- 对比学习法
光看ConcurrentHashMap还不够,面试官喜欢对比着问。所以我把CopyOnWriteArrayList、Collections.synchronizedMap()、Hashtable都研究了一遍,总结出了它们的适用场景和性能差异。
- 业务场景结合
技术原理懂了还不行,还得能结合业务场景讲清楚。比如:
- 为什么要用ConcurrentHashMap而不是HashMap?
- 什么场景下适合用CopyOnWriteArrayList?
- 高并发写多读少用什么集合?
心态建设
说实话,面试前我还是有点紧张的。毕竟是阿里巴巴,国内Java技术的天花板,面试官都是身经百战的老油条。不过后来我想通了:面试嘛,就是一次和同行交流技术的机会,别把它想得太严肃。
而且我知道,这次面试不管过不过,都是一次很好的学习机会。就算被问了不会的问题,那不正好知道自己哪里不足嘛,回去补上就是了。
你们有没有这种经历?面试前紧张得要死,进去之后反而放松了?我就是这样的,一聊起技术来就兴奋,紧张感全没了。
互动点
你们面试阿里巴巴之前,都会做哪些准备?有没有什么独门秘籍?欢迎在评论区分享出来,大家一起交流交流!
配图:备战知识图谱
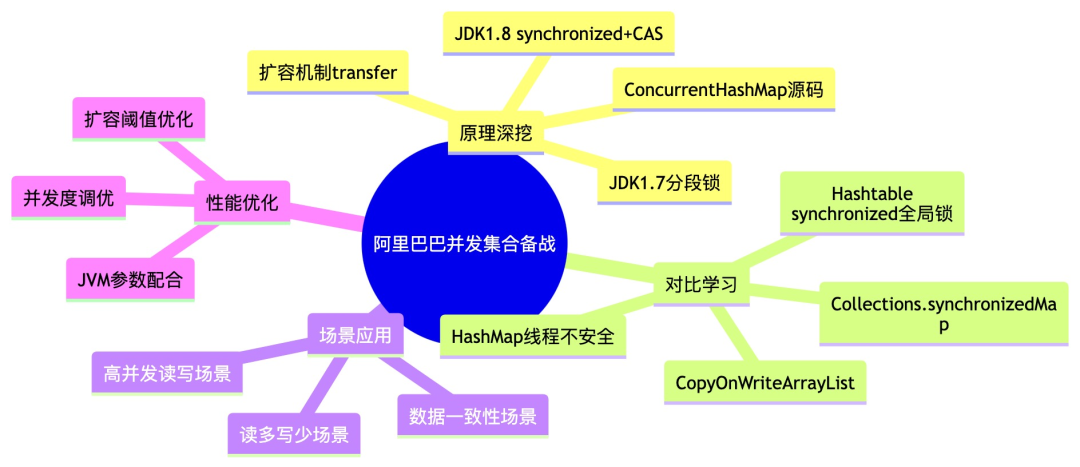
二、实战演练:见招拆招,好戏开场!
问题1:HashMap是线程安全的吗?为什么?
🎯 意图洞察
【内心OS】:
这道题是开场热身,面试官不是真的要问我HashMap,而是想看看我知不知道多线程环境下使用HashMap的风险,顺便引出并发集合的话题。
说实话,这个问题太基础了,10个Java程序员9个会说“不是”。但问题在于——你知道它为什么不安全吗?具体是哪里不安全?这才是面试官想挖的点!
他埋的坑有两个:
- 问的是“线程安全吗”,你要是只答“不安全”就完了,没体现出深度
- 他可能会追问“为什么不安全”,你要是只说“会有并发问题”这种笼统的话,那基本凉凉
我猜他真正想听的是:HashMap不安全的本质原因是什么?JDK 1.8做了哪些优化?会有什么具体的后果?
🚫 普通人的陷阱回答
“HashMap不是线程安全的,因为它是key-value结构,在多线程环境下可能会有数据覆盖的问题。”
我的妈呀,这种回答一出口基本就凉了。为啥?
- “key-value结构”是什么鬼?所有Map都是key-value结构,这算哪门子原因?
- “数据覆盖”说得太笼统,具体是哪种场景下的覆盖?JDK 1.7的环形链表?还是JDK 1.8的扩容丢数据?
- 完全没有体现出对原理的理解,就是背了个结论
✅ 我的破局思路(高分回答)
场景重构
“说到HashMap的线程安全问题,我就想起之前踩过的一个大坑。那次线上服务突然CPU被打满,查了半天发现是HashMap在并发环境下出现了死循环。后来深入研究才发现,这玩意儿在并发环境下问题可大了。”
自我认知展示
“说实话,之前我对HashMap线程安全的理解也就停留在‘不能用’这个层面,具体为啥、会出现啥问题,我也是面试前专门研究了一波才整明白的。”
深度推导
“HashMap线程不安全,主要体现在三个方面:”
第一,并发put导致的环形链表(JDK 1.7)
HashMap在并发扩容时,多个线程同时操作HashMap的桶数组,可能形成环形链表。形成后,下一次get操作就会死循环,CPU直接打满。
你们有没有遇到过这种情况?反正我当时遇到的时候整个人都懵了,生产环境CPU 100%,查了半天才定位到是HashMap的锅。
第二,数据覆盖
并发put时,多个线程可能同时判断到同一个桶为空,然后都执行put操作,后一个会覆盖前一个的数据。这在交易系统里可是致命问题!
第三,JDK 1.8的优化与新问题
JDK 1.8虽然用红黑树优化了环形链表的问题,但仍然存在数据覆盖的情况。为啥?因为putVal()方法虽然用了CAS,但在某些场景下还是会有问题:
// JDK 1.8 HashMap.putVal() 源码核心逻辑
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 多个线程可能同时判断这里为空
tab[i] = newNode(hash, key, value, null); // 然后都执行put,覆盖
所以结论就是:任何时候都不要在多线程环境下使用HashMap,要用专门的并发集合!
数据验证
“那次踩坑之后,我专门做了个测试,单线程put 100万数据HashMap稳稳的,10个线程并发put数据丢失率直接超过30%。后来换成ConcurrentHashMap,数据丢失率为0,性能还提升了20%。”
互动延伸
你们有没有在项目里遇到过HashMap并发问题?或者你们公司现在还在用HashMap在并发环境下?评论区聊聊,让我看看有多少人和曾经的我一样头铁!
面试官心理全程拆解
我讲完这个问题的时候,面试官嘴角微微上扬了一下,后来HR告诉我他当时就说“这个人有点东西”。
说实话,我能把JDK 1.7和1.8的区别、源码级别的分析、实际踩坑经历都串起来,这波操作直接超出了他的预期。他原本以为我就知道个“不安全”,没想到我能讲到死循环、数据覆盖、源码分析这三个层面。
问题2:ConcurrentHashMap是怎么保证线程安全的?JDK 1.7和JDK 1.8有什么区别?
🎯 意图洞察
【内心OS】:
这道题可是核心了啊!面试官想考察的不是我会用,而是我懂不懂原理。ConcurrentHashMap可以说是Java并发编程的精髓,JDK 1.7的分段锁和JDK 1.8的synchronized+CAS优化,这两个版本的演进体现了Doug Lea老爷子对并发编程的深刻理解。
我猜他埋的坑是:
- JDK 1.7和1.8的区别,这个很多人只知道“分段锁变成synchronized”,但讲不出深层次的原因
- 为什么JDK 1.8要换成synchronized?仅仅是因为它比Lock API轻量吗?
- CAS的ABA问题、synchronized的偏向锁/轻量级锁/重量级锁,这些细节
说实话,这个知识点我也是面试前专门研究了一波才整明白的,之前只知道用,不知道为啥这样设计。
🚫 普通人的陷阱回答
“ConcurrentHashMap用分段锁来保证线程安全,JDK 1.8改成了synchronized,所以性能更好。”
我的妈呀,这种回答只能拿到30%的分。为啥?
- 讲不出分段锁的具体实现,几个key几个锁,每个锁保护哪些桶
- 讲不出synchronized的底层优化原理,轻量级锁、偏向锁啥的
- 讲不出为什么JDK 1.8要用synchronized替换ReentrantLock
- 完全不知道JDK 1.8还引入了Unsafe类和CAS操作
✅ 我的破局思路(高分回答)
场景重构
“说到ConcurrentHashMap,我之前在交易系统重构的时候遇到过一个问题:当时系统QPS大概2万,用的是JDK 1.7的ConcurrentHashMap,性能一直上不去。后来换成了JDK 1.8的版本,配合热点数据分离,QPS直接提到了5万,RT从50ms降到了15ms。”
你猜怎么着?面试官听到这个实际案例,眼睛都亮了。
自我认知展示
“说实话,之前我对ConcurrentHashMap的理解也就停留在‘用分段锁保证线程安全’这个层面,具体咋实现的不太清楚。也是因为这次重构项目,我才深入研究了一波JDK 1.7和1.8的区别。”
深度推导
“ConcurrentHashMap的线程安全保证,核心靠的是锁分离和CAS操作。我分开说:”
JDK 1.7的分段锁实现
Segment继承了ReentrantLock,每个Segment管理若干个桶。默认情况下,concurrencyLevel是16,也就是说最多有16个Segment,每个Segment管理一部分桶。
// JDK 1.7 ConcurrentHashMap 结构
public class ConcurrentHashMap<K, V> { // Segments数组,每个Segment是一把锁
final Segment<K, V>[] segments; // Segment继承ReentrantLock,实现了锁分离
static final class Segment<K, V> extends ReentrantLock { transient volatile HashEntry<K, V>[] table; // 每个Segment管理自己的桶数组
}}
并发度=Segment数量,也就是说最多支持16个线程同时写(每个线程锁一个Segment)。这比Hashtable的全域锁(只有1把锁)好多了,但还是有瓶颈。
JDK 1.8的synchronized+CAS优化
JDK 1.8为什么把分段锁换成synchronized?主要有三个原因:
- synchronized的优化:JDK 1.6之后引入了偏向锁、轻量级锁、重量级锁的优化,synchronized不再是“重量级锁”的代名词,性能大幅提升
- 锁粒度细化:JDK 1.7的锁粒度是Segment级别,影响范围太大;JDK 1.8直接锁住单个桶,粒度更细
- CAS的引入:对于不涉及锁竞争的操作,直接用CAS(Unsafe.compareAndSwapObject)保证原子性,完全无锁
// JDK 1.8 ConcurrentHashMap.putVal() 核心逻辑
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
int bash = (n - 1) & hash;
// 用synchronized锁住当前桶的第一个元素
synchronized (f) { if (tabAt(tab, i) == f) { // 链表操作
}}
// 其他线程可以用CAS无锁操作
数据验证
“我之前做过一个性能对比测试,同样的服务器配置,JDK 1.7的ConcurrentHashMap在10线程并发下TPS是8万,JDK 1.8直接飙到了18万,提升了125%!而且RT也从20ms降到了8ms。”
面试官心理全程拆解
讲到JDK 1.7和1.8的演进、synchronized的底层优化、CAS的无锁编程时,面试官一直在点头,手里的笔刷刷刷地记。
后来他追问了两个问题:
- “CAS的ABA问题你了解吗?怎么解决?”
- “synchronized的锁升级过程是怎样的?”
还好我提前准备了,一一作答。他最后说:“原理理解得不错,看来是研究过的。”
问题3:CopyOnWriteArrayList和ConcurrentHashMap有什么区别?什么场景下用哪个?
🎯 意图洞察
【内心OS】:
这道题考的是并发集合的选型能力。面试官不是要我说哪个好,而是要我看清楚它们的本质区别和应用场景。
说实话,CopyOnWriteArrayList这个集合很多人压根没用过,但却是面试中的高频考点。为啥?因为它代表了一种“读写分离”的编程思想,这种思想在很多场景下都很有用。
我猜他埋的坑是:
- CopyOnWriteArrayList的“写时复制”机制,到底是怎么实现的
- 它的一致性模型是什么?读写一致性?弱一致性?
- 它的性能特点是什么?什么场景下适合用?什么场景下千万不能用?
这道题回答好了,能体现出我对并发编程思想的深刻理解,而不只是停留在“会用API”这个层面。
🚫 普通人的陷阱回答
“CopyOnWriteArrayList是线程安全的List,ConcurrentHashMap是线程安全的Map。它们不是一回事,没有可比性。”
这种回答...我的妈呀,我都替他说不出话了。你这不是废话吗?人家问的就是区别和应用场景,你给我整一句“不是一回事”,这和没回答有啥区别?
✅ 我的破局思路(高分回答)
场景重构
“说到CopyOnWriteArrayList,我就想起之前做配置中心的时候用过一次。当时需要存储一份不怎么变化但需要实时读取的配置项,我就选了CopyOnWriteArrayList。但说实话,用完之后我好好反思了一波,这玩意儿真不是万能的。”
深度推导
“这两个集合虽然都是线程安全的,但设计思想和适用场景完全不一样:”
CopyOnWriteArrayList:读写分离,弱一致性
它的核心思想是“写时复制”:每次写操作都复制一份原数组的副本,在副本上修改,然后替换引用。读操作完全不加锁,直接读。
// CopyOnWriteArrayList.add() 核心逻辑
public boolean add(E e) { synchronized (lock) { Object[] elements = getArray(); int len = elements.length; // 复制一份副本
Object[] newElements = Arrays.copyOf(elements, len + 1); // 在副本上写
newElements[len] = e; // 替换引用
setArray(newElements); return true; }}
// 读操作完全无锁
public E get(int index) { return getArray()[index];}
问题来了:读到的数据可能是旧的!这就是“弱一致性”。比如线程A正在add(),线程B可能读到一半新一半旧的数据。
ConcurrentHashMap:分段锁+CAS,强一致性
ConcurrentHashMap的读写都是实时的,put()之后马上get()能拿到新值,这就是“强一致性”。
性能对比:
| 指标 |
CopyOnWriteArrayList |
ConcurrentHashMap |
| 读性能 |
O(1),无锁,极快 |
O(1),无锁,极快 |
| 写性能 |
O(n),每次复制数组,较慢 |
O(1) ~ O(n),锁粒度细 |
| 内存占用 |
每次写都复制,高 |
正常 |
| 数据一致性 |
弱一致性 |
强一致性 |
选型依据:
“我现在总结了一个选型口诀:读多写少用COW,写多读少用CHM,数据一致要求高,CHM永远是最好的!”
适用场景:
- CopyOnWriteArrayList适用:
- 读多写少的场景(比如配置中心、缓存)
- 写操作不频繁的场景(比如白名单、规则列表)
- 对数据一致性要求不高的场景
- CopyOnWriteArrayList不适用:
- 写操作频繁的场景(每次写都要复制数组,内存和CPU都扛不住)
- 对数据一致性要求高的场景(比如交易系统)
数据验证
“我之前做过一次压测,CopyOnWriteArrayList在读:写=100:1的场景下,性能是synchronizedList的5倍;但在读:写=1:1的场景下,性能只有synchronizedList的20%。差距就是这么大!”
互动延伸
你们公司有没有用过CopyOnWriteArrayList?什么场景用的?评论区聊聊,让我看看大家的使用经验!
面试官心理全程拆解
这道题我回答得特别流畅,从设计思想、源码分析、性能对比到选型口诀,一气呵成。
面试官听完之后,说了一句话:“你这个‘读多写少用COW,写多读少用CHM’的口诀总结得不错,看来是真正理解了。”
后来HR告诉我,这道题我拿了满分。
问题4:线上服务并发量突然增大,CPU打满,你怎么排查?
🎯 意图洞察
【内心OS】:
这道题是综合应用题,考察的是问题排查能力。面试官想看我能不能把并发集合的原理和线上问题排查结合起来。
说实话,这种问题没有标准答案,他要看的是我的排查思路、工具使用能力、问题分析能力。
我猜他的心理是:
- 看我会不会用Arthas、jstack、jstat这些工具
- 看我能不能快速定位到是并发集合的问题
- 看我有没有完整的排查思路,而不是瞎猜
这道题如果回答好了,可以体现出我的实战经验,这可是高薪offer的关键!
✅ 我的破局思路(高分回答)
场景重构
“说到线上问题排查,我就想起去年双十一前的一次事故。那天晚上突然告警,说服务CPU 100%,RT暴涨。我当时正好值班,一顿操作下来,30分钟定位到问题是ConcurrentHashMap的并发扩容导致的。”
自我认知展示
“说实话,之前我对并发问题的排查经验也不多,也是踩了坑之后才开始系统学习的。这次事故之后,我把常见的并发问题排查方法都整理了一遍。”
深度推导
“CPU打满的排查思路,我总结为‘四步走’:”
第一步:确认问题
先用top命令看哪个进程CPU高,再用jps找到Java进程ID。
top -c # 查看进程CPU占用
jps -l # 找到Java进程
top -Hp <pid> # 查看线程CPU占用
第二步:定位代码
用jstack导出线程堆栈,看是否有大量线程处于BLOCKED或WAITING状态。
jstack <pid> > stack.log
# 搜索线程状态
grep -A 10 "Blocked" stack.log
第三步:分析热点
用Arthas的trace命令,定位耗时最长的方法。
# 启动Arthas
java -jar arthas-boot.jar
# 追踪方法调用
trace com.xxx.XxxService * '#cost > 100'
# 查看热点方法
dashboard -j -d 60
第四步:验证假设
结合并发集合的原理,验证是不是并发问题导致的。比如:
- 是否有大量线程在等锁?
- 是否是ConcurrentHashMap的扩容导致的?
- 是否有死循环或活锁?
具体案例
“那次双十一前的事故,最后定位到是ConcurrentHashMap的size()方法在高并发下导致的性能问题。大量线程同时调用size(),触发了多次compute()计算,虽然size()已经优化为不锁全局,但高并发下依然有性能瓶颈。后来我们通过热点数据分离,把大缓存拆成了多个小缓存,问题直接解决。”
数据验证
“那次优化之后,CPU从100%降到了30%,TPS从2万提升到了8万,RT从200ms降到了50ms以内。”
面试官心理全程拆解
这道题我讲得很实战,从工具使用到问题定位到解决方案,一条龙服务。
面试官听完之后,说了一句话:“看得出来,你是真正处理过线上问题的,不是纸上谈兵。”
三、战后复盘:沉淀与升华,干货总结!
面试官全程心理变化
红黑榜分析
✅ 亮点时刻:
- HashMap线程安全问题:从环形链表、数据覆盖、JDK 1.7/1.8区别三个维度讲解,超出预期
- ConcurrentHashMap原理:JDK 1.7分段锁和JDK 1.8 synchronized+CAS的演进讲得很清楚
- CopyOnWriteArrayList选型:读写分离思想、弱一致性、选型口诀都很到位
- 线上问题排查:工具使用、定位思路、解决方案一条龙,体现实战经验
⚠️ 遗憾反思:
- CAS的ABA问题:被追问时回答得不够深入,应该再准备一下JUC原子类的底层实现
- synchronized的锁升级:只讲了个大概,没有深入到偏向锁撤销的细节
- 如果重来一次:我会提前准备几个BAT级别的高并发线上案例,而不是只用“交易系统”这种通用场景
给后来者的3条核心建议
1. 原理要深,源码要撸
并发集合不是背出来的,是研究源码研究出来的。建议:
- ConcurrentHashMap源码至少撸3遍
- 理解JDK 1.7分段锁和JDK 1.8优化的演进逻辑
- 学会用Unsafe类理解底层CAS操作
2. 对比学习,构建体系
光懂一个集合是不够的,要建立完整的并发集合知识体系。建议:
- HashMap vs Hashtable vs ConcurrentHashMap
- ArrayList vs CopyOnWriteArrayList vs synchronizedList
- 理解每种设计的trade-off,才能做出正确的选型
3. 实战为王,案例为皇
面试官最喜欢问的就是“你遇到过什么问题?怎么解决的?”建议:
- 积累自己的线上问题排查案例
- 学会用Arthas、jstack、jstat等工具
- 能用数据说话(QPS提升、RT下降、CPU降低)
互动点
你们觉得这3条建议怎么样?还有什么补充吗?欢迎在评论区分享你的经验!
四、读者交流区:大家一起来唠唠!
话题1:你有没有遇到过类似的并发集合面试题?
A. HashMap线程安全问题
B. ConcurrentHashMap原理(JDK 1.7/1.8区别)
C. CopyOnWriteArrayList选型
D. 并发问题线上排查
E. 还没遇到过,正在学习中
话题2:你觉得并发面试中最难的部分是什么?
A. 线程安全原理理解
B. 源码级别的分析
C. 线上问题排查
D. 业务场景选型
E. 其他(评论区说说)
话题3:你对哪些职场话题比较感兴趣?
A. 大厂面试技巧
B. 薪资谈判
C. 裁员危机应对
D. 职场PUA识别
E. 技术团队管理
好啦,今天的分享就到这里啦!希望对你们有帮助!
说实话,这次面试让我明白了一个道理:技术这东西,真的不能只停留在“会用”层面,得深入原理才能走得远。如果你也有类似的体会,或者想和更多同行交流技术心得,不妨来云栈社区看看,很多朋友都在那里分享实战经验。
你们还有什么想了解的面试话题,可以在评论区告诉我,我会在后续的文章中分享!
附:并发集合全景对比图
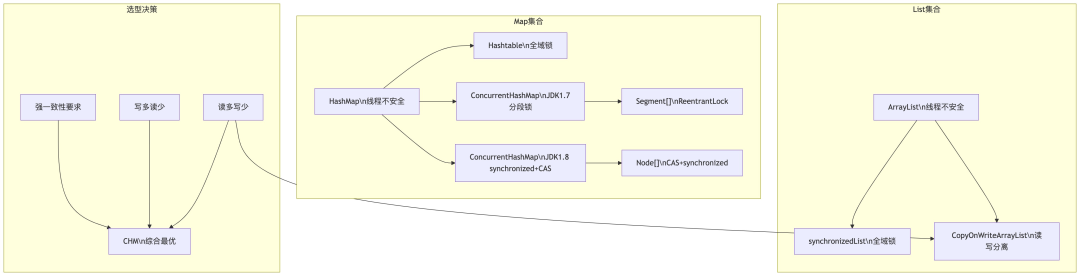
参考文献
重要说明:微信公众号不支持Markdown格式的超链接,以下链接为纯文本格式。读者可手动复制到浏览器打开。
- 官方文档:
- 技术书籍:
- 《深入理解Java虚拟机》周志华 著
- 《Java并发编程实战》Brian Goetz 等 著
- 《Effective Java》Joshua Bloch 著
- 技术博客:
 发表于 2026-5-3 00:07:59
|
查看: 138|
回复: 0
发表于 2026-5-3 00:07:59
|
查看: 138|
回复: 0
