你是否也曾有过这样的经历:下载一份金融产品说明书,或是翻开厚厚的监管合规文件,密密麻麻的条款瞬间让人头晕目眩。很多人会本能地把这种感觉归结为“字数太多了”。但金融学界和监管层对“复杂”的理解,远不止是“长”这么简单。
近些年,从层层加码的《巴塞尔协议》到体量庞大的美国《多德-弗兰克法案》,全球金融监管似乎正陷入一场“复杂性危机”。监管机构自己也头疼:怎么才能在保证监管精准度的同时,不让规则复杂到连大银行的精英团队都算不过来?
一、核心问题:监管复杂度远不止“字数多”
金融监管领域一直有个悖论:规则太简单,好执行但可能过于粗糙;规则越精细,越能覆盖复杂的金融活动,却可能让银行、监管者甚至政策制定者都难以理解和落实。
2008年全球金融危机后,各国监管体系大幅扩张。以美国《多德-弗兰克法案》和巴塞尔资本监管规则为代表,金融监管文本变得越来越长、越来越细、越来越技术化。这引出了一个根本性问题:监管复杂度到底是什么?它能否被量化?它是否真的带来了更高的合规成本和更多的执行错误?
过去最常见的做法是看文本长度——页数越多、字数越多,似乎就越复杂。但这只是个粗略指标。两段长度相同的监管文本,复杂程度可能天差地别:一段可能只是把同一种规则重复了十遍;另一段则可能涵盖了十类金融机构、五种资产、多个例外条款和条件判断。论字数,它们不相上下,但后者的理解、执行和合规难度显然高出几个数量级。
于是,文章将监管复杂度拆解为三个层次:
第一,内在复杂度。 规则本身的复杂性。比如,它需要区分多少类资产、多少种银行、多少种风险权重。即使条文写得清清楚楚,只要涉及的经济概念和约束足够多,它依然复杂。
第二,心理复杂度。 读者理解文本的难度。同一条规则,可以写得言简意赅,也可以写得晦涩难懂。复杂的句法、频繁的交叉引用、过多的条件判断,都会推高理解成本。
第三,计算复杂度。 将规则落到实处的执行难度。比如,一家银行要根据自己的资产结构、风险暴露和监管模板来计算资本要求,规则越复杂,执行成本和算错概率就越高。
这里有一个关键洞见:监管复杂度绝非单一概念,而是贯穿规则设计、文本理解到合规执行的多阶段问题。 文章在理论框架中明确区分了监管者起草规则、市场主体解读规则、机构落地执行这三大环节,并指出错误可能在每一环悄然累积。
二、颠覆性思路:把监管文件当成“代码”来读
本文最具辨识度的创新,在于将监管规则类比为计算机程序。这是 算法/数据结构 思维在金融监管领域的一次漂亮迁移。
在程序中,有两类基本元素:操作符(operators,如加减乘除、条件判断)和操作对象(operands,如变量、参数、输入输出)。作者将这套思想平移到了监管文本中:
- 监管操作符:那些表示监管约束、义务或动作的词,如 shall、must、require,它们在说“必须做什么”。
- 逻辑操作符:如 if、when、unless、and、or 等条件判断词,它们决定了规则在何种情况下适用。
- 数学操作符:涉及计算、比较和数量关系的表达。
- 操作对象:监管中涉及的经济概念,如 bank、asset、capital、risk weight、exposure 等。
基于这些元素,作者提炼出两个最核心的文本复杂度指标:
- Quantity(规则数量):监管操作符的总数,回答了“这份文件到底包含多少条‘必须做’的要求?”
- Potential(概念多样性):唯一操作对象的数量,回答了“读者需要掌握多少类金融概念,才能真正搞懂这套规则?”
作者的发现直击要害:这两个指标能够解释文本长度之外的复杂度。监管文件之所以让人头大,并不仅仅因为它又厚又重,而是因为它承载了更多的硬性规则和更加庞杂的经济概念。
三、从《巴塞尔协议 I》到 Dodd-Frank:三步实证检验
文章的实证设计逻辑分明,分三步走:
第一步:用《巴塞尔协议 I》做“概念验证”。
《巴塞尔协议 I》的资本监管规则天生就像一套算法:不同资产对应不同风险权重,银行据此计算风险加权资产和资本充足率。作者先将部分规则改写成伪代码,直接计算其操作符与操作对象;再回到原始监管文本,对词语进行分类并计算同样的复杂度指标。
这步的关键在于证明:监管文本确实可以被拆解为类似程序代码的结构。 结果显示,用文本计算出的内在复杂度指标,与用伪代码算出的高度一致。尤其是 Quantity 和 Potential,它们与文本的具体写法相对无关,更贴近规则本身的复杂内核。
第二步:向大型监管文本发起挑战。
方法验证通过后,作者将战场扩展到两个庞然大物:美国2010年的《多德-弗兰克法案》和欧盟2021年欧洲银行管理局(EBA)的《实施技术标准》(ITS)。作者公开了可复用的监管词典,如包含5627个操作对象和608个操作符的 DFA 词典,以及 EBA 词典,这为后续研究提供了极大便利。
第三步:用实验和现实调查,检验这些指标能否预测真实后果。
复杂度的测量是手段,解释真实世界的错误与成本才是目的。文章在此设计了两套验证策略:
-
实验室实验:复杂规则会让人更容易算错吗?
作者设计了一个类似《巴塞尔协议I》的实验,让参与者阅读随机生成的监管规则,并为一假想银行计算风险加权资产。在控制了文本长度后,一个清晰的结论浮出水面:Quantity 能显著解释错误率与完成耗时;Potential 则主要解释耗时。 规则越多,人越容易犯错且需要更多时间;概念越多,处理规则所需的时间也越长。这个设计巧妙地将抽象的“复杂度”转化为了可观察的“算错”与“算得慢”。
-
现实调查:复杂规则是否推高了银行的真金白银?
作者进一步利用 EBA 对欧洲银行的调查数据——银行需报告哪些监管模板带来了较高合规成本。将每个模板的文本复杂度指标与实际合规成本匹配后,结果与实验高度一致:在控制文本长度后,Quantity 依然是解释高合规成本的关键。 真正烧钱的不只是长篇大论,更是文本中那些多如牛毛的约束性规则。更有意思的是,大型银行主要受 Quantity 影响(它们有专门合规团队应对“量”);而小型银行则更容易受 Potential 影响(面对大量陌生概念,资源有限,理解成本剧增)。
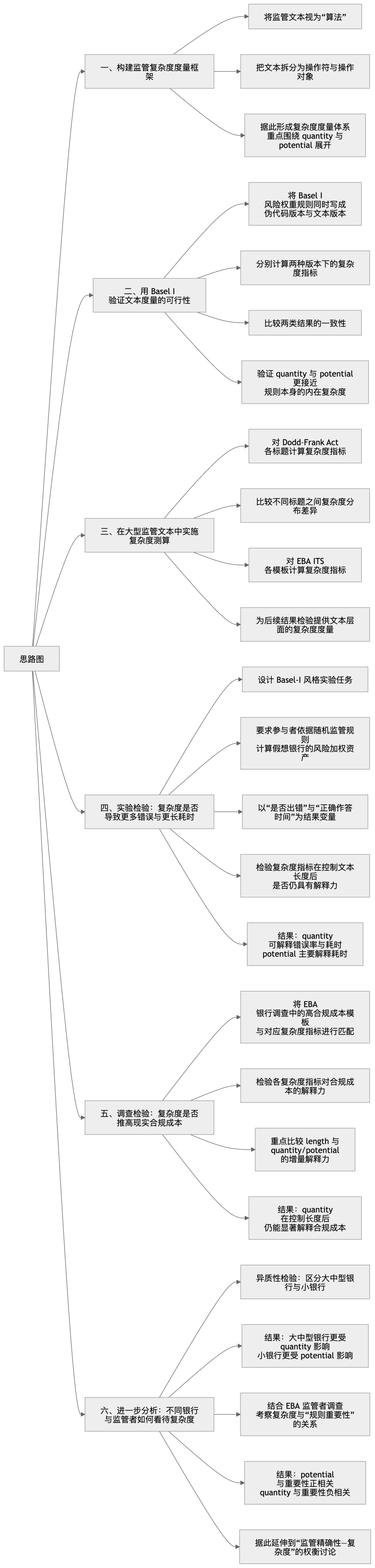
四、研究思路图解
下面这张思路图清晰地勾勒了全文的研究脉络,从框架构建、可行性验证到实证检验和差异化分析,环环相扣。
五、结论:简化监管,绝非“删字数”那么简单
文章最重要的结论可概括为三点:
第一,文本长度是一个有用但粗糙的代理变量。 长文本通常更复杂,但长度本身并非复杂度的根源。
第二,Quantity 和 Potential 能捕捉到长度之外的监管复杂度。 它们分别对应着“要执行多少条规则”和“要理解多少个概念”,是架在法律文本与人的认知负荷之间的两座桥梁。
第三,监管简化不应等同于“删字数”。 政策制定者若只是机械地缩短文本,未必能减轻真实的合规负担。更有意义的做法或许是:减少不必要的约束、合并重复规则、降低概念的碎片化,并从根本上优化规则的结构。
当监管规则复杂到一定程度时,成本最终会通过多种渠道传导给普通人:银行需要更多合规人员,运营成本上升;小银行在重压下可能退出市场或缩减业务;复杂规则无形中给大机构带来了相对优势;而难以理解和执行的规则,反而可能滋生更大的监管套利空间。因此,“监管复杂度”绝非一个小课题,而是影响金融系统效率、公平与稳定的关键变量。这篇文章最终在提醒我们:好的监管,不是越多越好,也不是越简单越好,而是在风险敏感性、可执行性与合规成本之间,找到那个精妙的平衡点。
原文摘要:
本文提出了一个基于计算机科学概念的监管复杂性研究框架。本文区分了复杂性的不同维度,对现有度量方法进行分类,开发了新的度量方法,并在三个案例——《巴塞尔协议 I》、《多德—弗兰克法案》以及欧洲银行管理局的报告规则——中对这些度量方法进行计算,同时通过实验和一项关于合规成本的调查对其进行检验。本文重点强调了两个能够捕捉监管文本长度之外复杂性的度量方法。本文提出了一种量化分析监管复杂性与监管精确性之间政策权衡的方法。
本文为学术论文解读,仅用于前沿学术交流。原文版权归原作者和原发刊所有。
原文链接: Colliard, Jean-Edouard, and Co-Pierre Georg. "Measuring Regulatory Complexity." Journal of Financial Economics (174), 2025. https://doi.org/10.1016/j.jfineco.2025.104186.
 发表于 2026-5-19 20:46:13
|
查看: 91|
回复: 0
发表于 2026-5-19 20:46:13
|
查看: 91|
回复: 0
