引言: 网络世界的交通管制
想象一下现代城市的交通系统:成千上万的车辆每天穿梭于复杂的道路网络中,每个路口都有交通信号灯和路标指引它们前往目的地。如果没有这些指引,交通将陷入混乱。Linux的路由系统在网络世界中扮演着同样的角色——它是一个智能的交通管制系统,负责引导数据包穿越复杂的网络拓扑,从源端准确无误地到达目的地。本文将带你深入探索Linux路由处理的工作原理、实现机制和设计思想,全面解析这个核心网络子系统。
1 Linux路由处理的核心概念
1.1 路由到底是什么?
简单来说,路由就是决定数据包从源到目的地应该走哪条路径的过程。每当Linux系统需要发送一个数据包时,它都会面临一个基本问题:“这个数据包应该从哪个网络接口发送出去?下一站是哪里?”
路由决策基于一个关键的数据结构:路由表。这个表就像一张地图,告诉系统不同目的地的“最佳路径”是什么。
1.2 数据包的生命周期
要理解路由,我们首先需要了解数据包在Linux系统中的处理流程。IP模块的基本工作流程可以概括为下图:
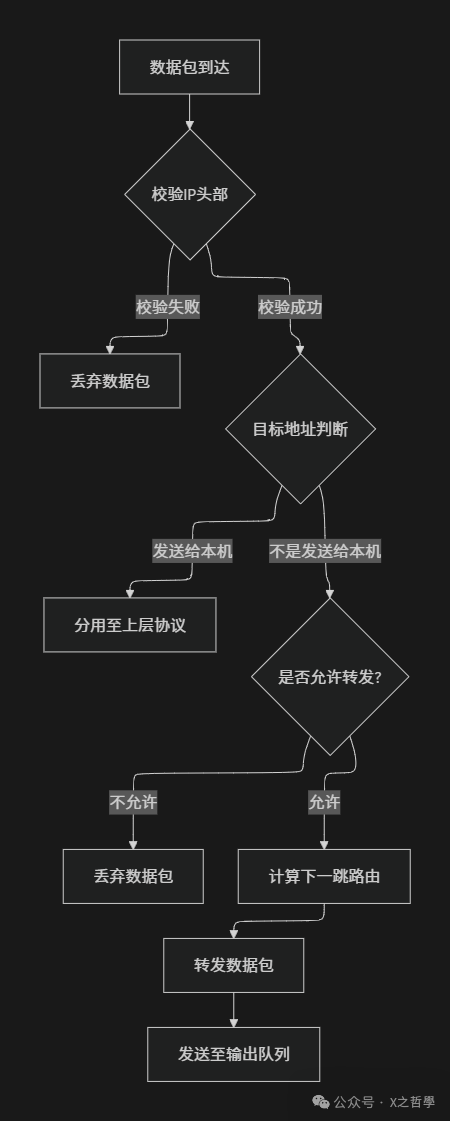
这个流程揭示了Linux路由处理的几个关键点:
- 本机与外发判断:系统首先判断数据包是否是发送给本机的。
- 转发权限检查:如果不是发送给本机的,检查是否允许转发。
- 路由决策:确定数据包的出口和下一跳地址。
- 输出处理:将数据包放入输出队列准备发送。
2 路由表与路由决策机制
2.1 路由表的结构与内容
路由表是路由系统的核心,它包含了到达各个网络目的地的路径信息。在Linux中,我们可以使用 route -n 或 ip route show 命令查看当前的路由表。
一个典型的Linux路由表包含多个字段,每个字段都有其特定含义:
| 字段 |
说明 |
示例 |
| Destination |
目标网络或主机 |
192.168.1.0 |
| Gateway |
网关地址 (下一跳) |
192.168.1.1 |
| Genmask |
网络掩码 |
255.255.255.0 |
| Flags |
路由标志 |
U (路由可用) G (使用网关) |
| Metric |
路由度量值 |
0 |
| Ref |
路由引用计数 |
0 |
| Use |
路由使用计数 |
0 |
| Iface |
出口接口 |
eth0 |
2.2 路由决策的三步法
当Linux需要为一个数据包选择路由时,它遵循一个三步匹配法:
- 精确主机匹配:首先查找与数据包目标IP地址完全匹配的主机路由。
- 网络匹配:如果没有找到主机路由,则查找与目标IP网络部分匹配的网络路由。
- 默认路由:如果以上都失败,则使用默认路由 (如果配置了)。
这个匹配过程体现了最长前缀匹配原则——更具体的路由 (掩码更长) 优先于更一般的路由。就像邮寄信件时,完整的街道地址比只写城市名更精确,因此会被优先使用。
2.3 实际路由表示例分析
让我们看一个具体的例子。假设我们有一个简单的家庭网络环境:
$ ip route show
default via 192.168.1.1 dev eth0 proto static
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100
10.0.0.0/8 via 192.168.1.254 dev eth0
这个路由表告诉我们:
- 默认情况下,所有流量都通过eth0接口发送到网关192.168.1.1。
- 发送到本地网络192.168.1.0/24的流量直接通过eth0接口送达,不需要网关。
- 发送到10.0.0.0/8网络的流量需要通过192.168.1.254这个特定网关。
当系统需要发送一个数据包到192.168.1.50时,它会匹配第二条路由;发送到8.8.8.8时,会匹配第一条默认路由;发送到10.1.2.3时,则会匹配第三条路由。
3 Linux内核中的路由实现
3.1 核心数据结构
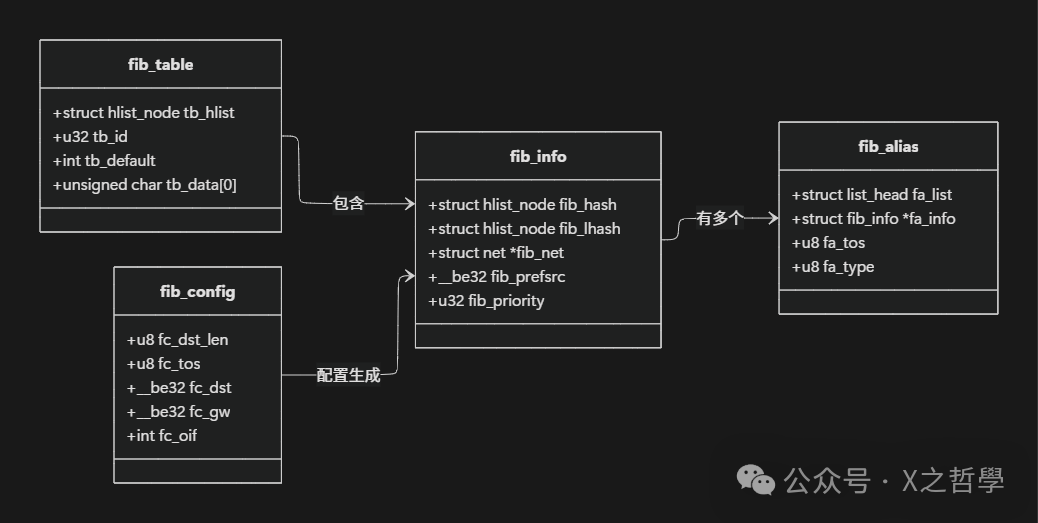
Linux内核中的路由实现基于一系列精心设计的数据结构。根据对内核代码的分析,最重要的数据结构包括:
1. fib_config结构体:用于将外部路由配置转换为内核内部格式。
struct fib_config {
u8 fc_dst_len; // 目的地址掩码长度
u8 fc_tos; // 服务类型
u8 fc_protocol; // 路由协议来源
u8 fc_scope; // 路由作用域
u8 fc_type; // 路由类型
u32 fc_table; // 路由表ID
__be32 fc_dst; // 目的地址
__be32 fc_gw; // 网关地址
int fc_oif; // 出口接口索引
u32 fc_flags; // 路由标志
// ... 其他字段
};
2. fib_info结构体:存储路由条目的共享参数。
struct fib_info {
struct hlist_node fib_hash; // 哈希表链接
struct hlist_node fib_lhash; // 上次使用链接
struct net *fib_net; // 所属网络命名空间
int fib_treeref; // 树引用计数
atomic_t fib_clntref; // 客户端引用计数
__be32 fib_prefsrc; // 首选源地址
u32 fib_priority; // 路由优先级
// ... 其他字段
};
3. fib_table结构体:表示一个路由表。
struct fib_table {
struct hlist_node tb_hlist; // 全局链表节点
u32 tb_id; // 路由表ID
int tb_default; // 是否默认表
unsigned char tb_data[0]; // 实际路由数据 (哈希或trie)
};
这些数据结构之间的关系可以用以下图表表示:
3.2 路由查询过程
内核中的路由查询过程主要发生在 fib_lookup() 函数中。这个过程有两个阶段:
- 本地表查询:首先查询本地路由表 (RT_TABLE_LOCAL),该表包含本机地址和多播地址等信息。
- 主表查询:如果本地表没有匹配项,则查询主路由表 (RT_TABLE_MAIN)。
这种设计确保了发送到本机的数据包能够被正确识别和处理,而不是被错误地转发出去。
3.3 路由表的存储与查找
Linux内核支持两种路由表的存储方式:哈希表和前缀树 (Trie)。早期版本默认使用哈希表,但新版本中前缀树已成为主流。
哈希表实现:
struct fn_hash {
struct fn_zone *fn_zones[33]; // 按掩码长度分区 (0-32)
struct fn_zone *fn_zone_list; // 非空分区链表
};
在哈希表实现中,路由条目按照目的地址的掩码长度被分配到33个不同的分区中。查找时,系统从最长的掩码长度开始尝试,逐步降低要求,直到找到匹配项。这种设计天然支持最长前缀匹配原则。
前缀树实现相比哈希表更为高效,特别是在处理大量路由条目时。它使用树形结构存储IP地址前缀,可以快速找到与目标地址最匹配的路由。
4 路由类型与应用场景
4.1 NAT路由
网络地址转换 (NAT) 路由是一种常见的路由方式,在负载均衡和网络地址转换场景中广泛应用。
在NAT路由中,LVS (Linux虚拟服务器) 路由器接收客户端请求,将其转发给后端的真实服务器。真实服务器处理请求后,将响应返回给LVS路由器,路由器再将源地址替换为自己的VIP地址后发送给客户端。
这个过程就像国际邮件的转运中心:你从国外寄信到中国某城市,国际邮递员不会直接送到收件人门口,而是先送到转运中心,转运中心再将信件交给国内邮递员派送。回信时也是先送到转运中心,再由转运中心寄往国外。
NAT路由的主要优点是:
- 后端服务器可以是任何操作系统的机器。
- 隐藏了后端服务器的真实IP地址。
- 网络配置相对简单。
但它的缺点也很明显:
- LVS路由器可能成为性能瓶颈。
- 所有流量都需要经过LVS路由器,增加了延迟。
- 需要处理地址转换,增加了复杂度。
4.2 直接路由
直接路由是另一种重要的路由方式,它在性能方面比NAT路由更有优势。在直接路由模式下,LVS路由器只处理进入的请求,将请求转发给后端服务器后,后端服务器直接响应客户端,不再经过LVS路由器。
这就像航空公司的转机服务:航空公司只负责把你从出发地带到中转枢纽,从中转枢纽到最终目的地的旅程由当地交通负责,不再需要航空公司参与。
直接路由的优势包括:
- 更高的性能,LVS路由器不会成为出向流量的瓶颈。
- 更好的可扩展性,可以轻松添加更多后端服务器。
- 减少了网络延迟。
但它也有挑战:
- ARP问题:由于LVS路由器和后端服务器共享同一个VIP地址,可能导致ARP混乱。
- 网络配置更复杂。
- 需要后端服务器支持特定配置。
4.3 解决直接路由的ARP问题
直接路由面临的主要技术挑战是ARP问题。当客户端发送请求到VIP时,它需要知道VIP对应的MAC地址。如果后端服务器也响应ARP请求,客户端可能会直接与后端服务器通信,绕过了LVS路由器。
解决这个问题有几种方法:
- arptables过滤:在后端服务器上使用arptables工具,防止它们响应VIP的ARP请求。
- iptables过滤:使用iptables进行IP数据包过滤,完全避免ARP问题。
- 内核参数调整:通过修改内核参数,如设置
arp_ignore 和 arp_announce,控制ARP行为。
这些解决方案各有优劣,选择哪种取决于具体的网络环境和性能要求。
5 简化路由模型
为了更好理解Linux路由的核心逻辑,我们可以参考一个简化的形式化模型。Isabelle/HOL定理证明器中有一个Linux路由器的简化模型,它抽象出了路由处理的核心步骤:
definition simple_linux_router :: " 'i routing_rule list ⇒ 'i simple_rule list ⇒ (('i::len) word ⇒ 48 word option) ⇒
interface list ⇒ 'i simple_packet_ext ⇒ 'i simple_packet_ext option" where
"simple_linux_router rt fw mlf ifl p ≡ do {
_ ← iface_packet_check ifl p;
let rd = routing_table_semantics rt (p_dst p);
let p = p⦇p_oiface := output_iface rd⦈;
let fd = simple_fw fw p;
_ ← (case fd of Decision FinalAllow ⇒ Some () | Decision FinalDeny ⇒ None);
let nh = fromMaybe (p_dst p) (next_hop rd);
ma ← mlf nh;
Some (p⦇p_l2dst := ma⦈)
}"
这个模型虽然简化,但抓住了Linux路由处理的关键步骤:
- 接口检查:验证数据包是否到达正确的接口。
- 路由查找:根据目的地址查询路由表,确定出口接口。
- 防火墙检查:通过iptables的FORWARD链检查。
- 下一跳确定:确定数据包的下一跳地址。
- MAC地址查找:查找下一跳的MAC地址 (通过ARP或静态表)。
- 数据包修改:更新数据包的L2目的地址。
这个模型的抽象程度让我们能够更清晰地看到路由处理的逻辑流程,而不被复杂的实现细节所困扰。
6 路由调试与故障排除
6.1 常用调试命令
Linux提供了丰富的网络调试命令,帮助我们诊断路由问题:
基础信息查看命令:
# 查看网络接口信息
ip addr show
# 查看路由表
ip route show
route -n
# 查看网络统计信息
netstat -rn
ss -tunap
连接测试命令:
# 测试主机可达性
ping 8.8.8.8
# 跟踪数据包路径
traceroute google.com
tracepath google.com
# 测试特定端口连通性
nc -zv 192.168.1.1 80
telnet 192.168.1.1 80
高级调试工具:
# 捕获和分析网络数据包
tcpdump -i eth0 -n host 192.168.1.1
tcpdump -i eth0 -n port 80
# 实时监控网络流量
iftop -i eth0
nload eth0
# 网络扫描
nmap -sn 192.168.1.0/24 # 发现活动主机
nmap -sT 192.168.1.1 # TCP端口扫描
6.2 常见路由问题与解决方案
1. 路由表混乱或缺失
# 症状: 无法访问特定网络或全部外部网络
# 诊断: 检查路由表
ip route show
# 解决: 添加缺失的路由
sudo ip route add 192.168.2.0/24 via 192.168.1.254 dev eth0
sudo ip route add default via 192.168.1.1 dev eth0
2. ARP问题 (特别是在直接路由环境中)
# 症状: VIP地址响应异常,负载均衡失效
# 诊断: 检查ARP表
ip neigh show
# 解决: 配置ARP过滤
# 在后端服务器上
echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce
3. 防火墙干扰路由
# 症状: 路由表正常但数据包无法转发
# 诊断: 检查iptables规则
sudo iptables -L -n -v
sudo iptables -t nat -L -n -v
# 解决: 调整防火墙规则
sudo iptables -P FORWARD ACCEPT
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
4. 多路径路由问题
# 症状: 网络流量没有按预期分布
# 诊断: 检查多路径路由
ip route show table all
# 解决: 配置路由策略
sudo ip rule add from 192.168.1.100 table 100
sudo ip route add default via 192.168.2.1 dev eth1 table 100
6.3 路由调试的最佳实践
- 从简单到复杂:先检查基本连接 (ping),再检查路由 (traceroute),最后深入分析 (tcpdump)。
- 记录基线数据:在系统正常时记录关键指标,便于对比分析。
- 分步隔离问题:通过逐段测试,确定问题发生的具体位置。
- 利用系统日志:查看dmesg、/var/log/syslog等日志文件,获取内核级信息。
- 模拟重现问题:在测试环境中重现问题,避免影响生产系统。
7 Linux路由处理的核心模型图解
现在,让我们将前面讨论的各个组件整合成一个完整的Linux路由处理模型。下图展示了从数据包到达开始,到最终转发出去的全过程:
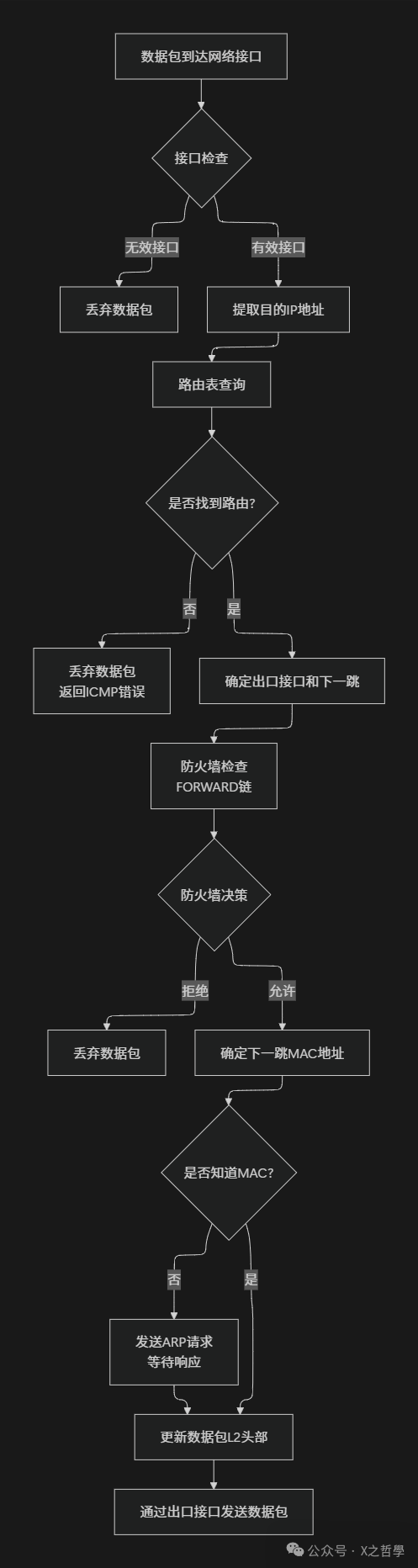 这个流程图展示了Linux路由处理的核心逻辑,它结合了路由决策、防火墙检查和二层寻址等多个步骤。
这个流程图展示了Linux路由处理的核心逻辑,它结合了路由决策、防火墙检查和二层寻址等多个步骤。
关键处理节点的详细说明:
路由表查询阶段:这是路由处理的核心,系统需要根据目的IP地址在路由表中找到最佳匹配。这个过程不仅包括查找,还包括路由优先级的比较和负载均衡策略的应用 (如果配置了多路径路由)。
防火墙检查阶段:在Linux中,路由和防火墙是紧密集成的。即使路由决策允许转发某个数据包,防火墙仍然可能拒绝它。这一阶段主要涉及iptables的FORWARD链,也可能包括连接跟踪 (conntrack) 等高级功能。
二层寻址阶段:路由决策确定了数据包的下一跳IP地址,但实际网络传输需要MAC地址。这一阶段可能涉及ARP协议 (IPv4) 或邻居发现协议 (IPv6),将IP地址解析为MAC地址。
8 实践案例: 构建一个简单的Linux路由器
理论知识需要结合实际操作才能深入理解。下面我们通过一个具体案例,展示如何将一台普通的Linux服务器配置成功能完整的路由器。
8.1 场景描述
假设我们有两个网络:
- 网络A: 192.168.1.0/24,连接在eth0接口。
- 网络B: 192.168.2.0/24,连接在eth1接口。
我们想让Linux服务器作为路由器,允许两个网络之间的通信,并且为两个网络提供互联网访问 (通过eth2连接互联网,网关为203.0.113.1)。
8.2 配置步骤
第一步:启用IP转发
# 临时启用
sudo sysctl -w net.ipv4.ip_forward=1
# 永久启用 (编辑/etc/sysctl.conf)
echo "net.ipv4.ip_forward = 1" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
第二步:配置网络接口
# 配置eth0 (网络A)
sudo ip addr add 192.168.1.1/24 dev eth0
sudo ip link set eth0 up
# 配置eth1 (网络B)
sudo ip addr add 192.168.2.1/24 dev eth1
sudo ip link set eth1 up
# 配置eth2 (互联网)
sudo ip addr add 203.0.113.100/24 dev eth2
sudo ip link set eth2 up
第三步:配置路由
# 为直接连接的网络添加路由 (通常自动添加)
# 查看当前路由
ip route show
# 添加默认路由 (互联网)
sudo ip route add default via 203.0.113.1 dev eth2
第四步:配置NAT (使内部网络能访问互联网)
# 启用NAT
sudo iptables -t nat -A POSTROUTING -o eth2 -j MASQUERADE
sudo iptables -A FORWARD -i eth2 -o eth0 -m state --state RELATED,ESTABLISHED -j ACCEPT
sudo iptables -A FORWARD -i eth2 -o eth1 -m state --state RELATED,ESTABLISHED -j ACCEPT
sudo iptables -A FORWARD -i eth0 -o eth2 -j ACCEPT
sudo iptables -A FORWARD -i eth1 -o eth2 -j ACCEPT
第五步:配置内部网络之间的路由
# 实际上,由于所有接口都在同一台路由器上,内部网络之间的路由会自动处理
# 但我们可以添加明确的路由规则以提高可读性
sudo ip route add 192.168.1.0/24 dev eth0
sudo ip route add 192.168.2.0/24 dev eth1
第六步:配置DHCP (可选,为客户端自动分配IP)
# 安装ISC DHCP服务器
sudo apt-get install isc-dhcp-server
# 编辑配置文件/etc/dhcp/dhcpd.conf
# 为网络A配置DHCP
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.100 192.168.1.200;
option routers 192.168.1.1;
option domain-name-servers 8.8.8.8, 8.8.4.4;
}
# 为网络B配置DHCP
subnet 192.168.2.0 netmask 255.255.255.0 {
range 192.168.2.100 192.168.2.200;
option routers 192.168.2.1;
option domain-name-servers 8.8.8.8, 8.8.4.4;
}
# 启动DHCP服务
sudo systemctl start isc-dhcp-server
sudo systemctl enable isc-dhcp-server
8.3 验证路由器功能
检查路由表:
$ ip route show
default via 203.0.113.1 dev eth2
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.1
192.168.2.0/24 dev eth1 proto kernel scope link src 192.168.2.1
203.0.113.0/24 dev eth2 proto kernel scope link src 203.0.113.100
测试连通性:
# 从网络A中的主机ping网络B中的主机
ping 192.168.2.50
# 从网络A中的主机ping互联网地址
ping 8.8.8.8
# 跟踪到互联网的路由
traceroute 8.8.8.8
监控路由性能:
# 查看网络接口统计
ip -s link show
# 实时监控网络流量
iftop -i eth2 # 监控互联网流量
这个简单的案例展示了Linux路由配置的基本步骤。实际生产环境中,可能还需要考虑冗余、负载均衡、流量控制、QoS等高级功能。
9 Linux路由系统的高级特性
9.1 策略路由
传统的路由决策仅基于目的地址,而策略路由允许基于源地址、服务类型、协议类型等多种条件进行路由决策。这在多宿主网络、流量工程等场景中非常有用。
# 创建自定义路由表
echo "200 custom_table" >> /etc/iproute2/rt_tables
# 添加路由规则
sudo ip rule add from 192.168.1.100 table custom_table
sudo ip rule add fwmark 1 table custom_table
# 在自定义表中添加路由
sudo ip route add default via 10.0.0.1 dev eth1 table custom_table
9.2 多路径路由
Linux支持多路径路由 (ECMP,等价多路径),允许将流量分配到多条等价路径上,提高带宽利用率和可靠性。
# 添加多路径路由
sudo ip route add default \
nexthop via 192.168.1.1 dev eth0 weight 1 \
nexthop via 192.168.2.1 dev eth1 weight 1
9.3 路由协议支持
虽然Linux内核本身不实现完整的路由协议,但可以通过用户空间守护进程实现各种路由协议:
- BIRD:支持BGP、OSPF、RIP等多种协议。
- Quagga/FRRouting:企业级路由套件。
- XORP:可扩展的开放路由平台。
这些守护进程通过netlink接口与内核交互,动态更新路由表。
9.4 网络命名空间中的路由
Linux网络命名空间为路由提供了隔离环境,每个命名空间都有自己独立的路由表、防火墙规则和网络设备。这是现代运维/DevOps实践中实现网络隔离和容器网络的关键技术。
# 创建网络命名空间
sudo ip netns add ns1
# 在命名空间中执行命令
sudo ip netns exec ns1 ip route show
# 将虚拟设备移动到命名空间
sudo ip link set veth1 netns ns1
总结: Linux路由处理的精髓
通过本文的详细分析,我们可以看到Linux路由处理是一个多层次、模块化的复杂系统。它的设计思想体现了几个核心原则:
- 分离关注点:路由决策、防火墙过滤、地址解析等不同功能被分解到独立的模块中。
- 可扩展性:通过模块化设计,可以轻松添加新的路由算法、存储方式和策略。
- 灵活性:支持多种路由方式 (NAT、直接路由等),适应不同的应用场景,是实现负载均衡等高级网络架构的基础。
- 性能优化:通过哈希表、前缀树等数据结构优化路由查找性能。
从简单的数据包转发到复杂的策略路由和负载均衡,Linux路由系统展现了其强大而灵活的设计,是构建现代网络基础设施不可或缺的基石。无论是单机网络配置还是大规模数据中心的路由策略,理解其内核原理与配置方法都至关重要。
 发表于 2025-12-13 03:56:59
|
查看: 244|
回复: 0
发表于 2025-12-13 03:56:59
|
查看: 244|
回复: 0
