在Linux操作系统的宏大架构中,内核线程扮演着“系统后台服务人员”的角色。想象一下,你走进一家高效运转的现代化工厂:前台有接待员(用户进程)直接为你服务,而工厂内部则有许多“隐形”的工作人员(内核线程)在维持着整个系统的运转——清理垃圾、维护设备、调度资源。这些工作人员虽然不直接与客户交互,但却是工厂正常运转的基石。
Linux内核线程正是这样的“后台工作者”。它们由内核创建、调度和管理,执行系统级别的关键任务,如内存回收、磁盘缓存同步、硬件中断处理等。与用户态线程不同,内核线程没有用户地址空间,完全生活在内核的“特权世界”里,可以执行任何内核代码,访问所有内核数据结构。
第一部分: 内核线程 vs 用户线程——本质区别探析
1.1 概念对比: 两种不同的“生存空间”
让我们用一个简单的比喻来理解这个核心区别:
用户线程像是住在普通公寓楼里的居民。每个居民有自己的私人空间(用户地址空间),可以装修自己的房子(加载用户程序),但不能随意进入大楼的管理中心(内核空间)。他们需要通过物业前台(系统调用)来请求大楼服务。
内核线程则是物业公司的内部员工。他们没有自己的私人公寓,办公地点就在大楼管理中心(内核空间)。他们可以自由访问整个大楼的所有设施(所有内核数据结构),执行维护任务,但从不与居民直接打交道。
1.2 技术特性对比表
| 特性维度 |
用户态线程 |
内核线程 |
| 地址空间 |
拥有独立的用户地址空间 |
无用户地址空间, 只在内核空间运行 |
| 创建者 |
用户程序(通过pthread库等) |
内核自身(内核启动或模块加载时) |
| 调度实体 |
可以是进程内的轻量级单元 |
独立的调度实体, 在进程列表中可见 |
| 权限级别 |
用户态(Ring 3) |
内核态(Ring 0) |
| 上下文切换 |
相对较快(通常无需TLB刷新) |
较慢(可能涉及更多状态保存) |
| 直接可见性 |
对用户透明,ps命令不可见 |
ps -ef中可见(用[]括起) |
| 示例 |
浏览器渲染线程、数据库工作线程 |
kswapd(内存回收)、kworker(工作队列) |
1.3 设计哲学: 为什么要引入内核线程?
早期的Unix系统中, 内核完全是“事件驱动”的——中断来了就处理, 没有真正的并发执行实体。但这种设计存在明显局限:
- 阻塞操作问题: 如果内核任务需要等待I/O, 整个CPU可能被挂起。
- 异步任务处理: 某些后台任务(如定期内存回收)需要定时执行。
- 多核利用: 现代多核CPU需要真正的并行执行实体。
内核线程的引入解决了这些问题, 让内核能够:
- 真正并发执行多个系统任务。
- 异步处理耗时操作而不阻塞其他服务。
- 更好地利用多处理器架构。
第二部分: 内核线程的核心数据结构剖析
2.1 灵魂结构体: task_struct
内核线程虽然是特殊的执行实体, 但在Linux的设计哲学中, 一切皆任务。内核线程与用户进程共享同一个核心数据结构——task_struct。这是Linux调度器的基本调度单元。
// 简化版task_struct关键字段(基于Linux 5.x内核)
struct task_struct {
/* 状态和调度信息 */
volatile long state; // 线程状态
int prio; // 动态优先级
int static_prio; // 静态优先级
struct list_head tasks; // 所有任务链表节点
/* 内存管理 */
struct mm_struct *mm; // 内存描述符(对内核线程为NULL!)
struct mm_struct *active_mm; // 活动内存描述符
/* 线程相关 */
pid_t pid; // 线程ID
pid_t tgid; // 线程组ID(对内核线程等于pid)
struct task_struct *group_leader; // 线程组领导
/* 内核栈和线程信息 */
void *stack; // 指向内核栈
struct thread_info *thread_info; // 线程相关信息
/* 调度类 */
const struct sched_class *sched_class;
/* 信号处理 */
struct signal_struct *signal;
struct sighand_struct *sighand;
/* 文件系统 */
struct fs_struct *fs;
struct files_struct *files;
/* 命名空间 */
struct nsproxy *nsproxy;
/* 性能分析 */
u64 utime, stime; // 用户/内核态CPU时间
};
关键洞察: 注意mm字段!对内核线程来说,mm总是NULL, 因为它们没有用户地址空间。但它们会借用上一个运行的用户进程的active_mm, 以减少TLB刷新开销。
2.2 紧凑的伴生结构: thread_info
为了快速访问当前任务信息, 内核使用了精巧的thread_info结构, 它通常与内核栈放在同一内存区域:
struct thread_info {
struct task_struct *task; // 指向对应的task_struct
unsigned long flags; // 低级标志位
int preempt_count; // 抢占计数器
mm_segment_t addr_limit; // 地址空间限制
// ... 架构相关字段
};
2.3 数据结构关系图
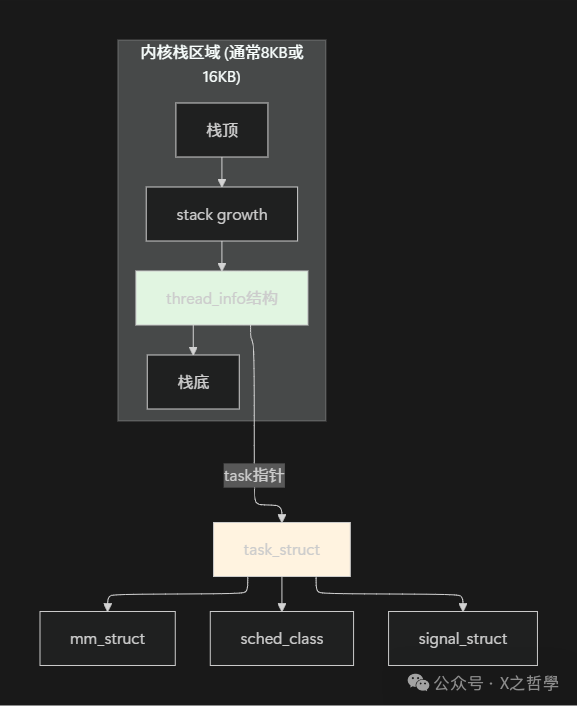
设计精妙之处: 通过将thread_info放在栈底, 内核可以用简单的位掩码操作从栈指针快速获取当前任务信息:
current_thread_info()->task // 快速获取当前task_struct
第三部分: 内核线程生命周期全解析
3.1 诞生: 内核线程的创建过程
内核线程的创建就像“无性繁殖”——它们不是通过传统的fork()系统调用诞生, 而是通过内核内部API直接生成。
// 创建内核线程的核心函数
struct task_struct *kthread_create(int (*threadfn)(void *data),
void *data,
const char namefmt[], ...);
// 创建并立即运行
struct task_struct *kthread_run(int (*threadfn)(void *data),
void *data,
const char namefmt[], ...);
创建流程分解:
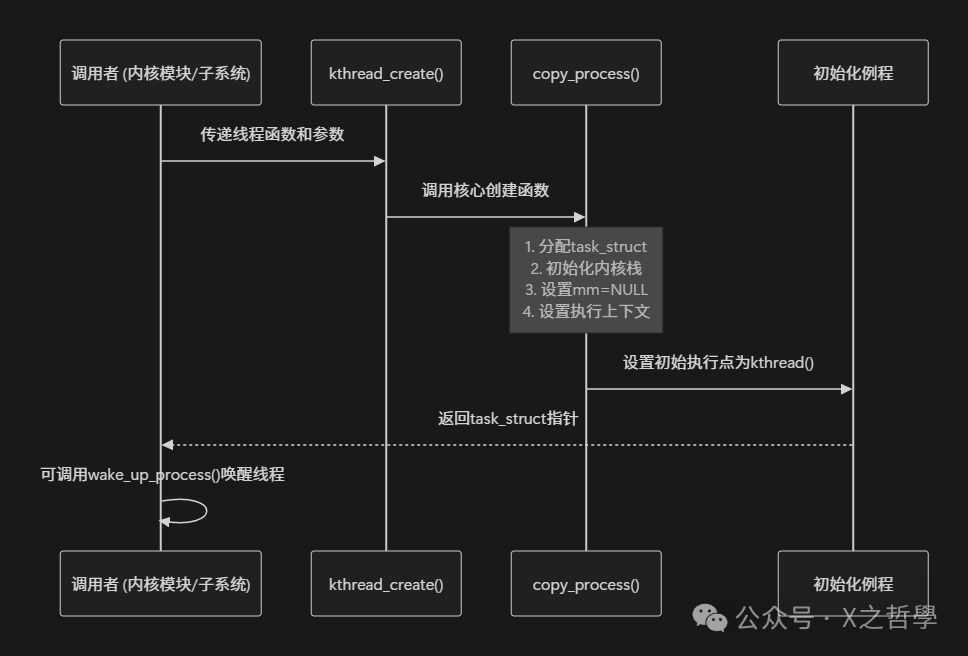
3.2 核心创建代码深度解析
让我们看看kthread_create的内部实现关键点:
// 简化的创建逻辑
struct task_struct *kthread_create_on_cpu(...){
struct task_struct *p;
// 关键: 使用内核特有的标志
p = copy_process(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND |
CLONE_THREAD | CLONE_SYSVSEM | CLONE_UNTRACED,
0, node);
if (!IS_ERR(p)) {
// 设置内核线程特有属性
p->flags |= PF_KTHREAD; // 标记为内核线程
p->vfork_done = NULL; // 没有vfork语义
// 设置执行入口
p->thread.sp = ...; // 栈指针
p->thread.ip = ...; // 指令指针指向kthread()
// 设置线程函数和参数
to_kthread(p)->threadfn = threadfn;
to_kthread(p)->data = data;
// 设置名称
snprintf(p->comm, sizeof(p->comm), namefmt, ...);
}
return p;
}
关键标志位说明:
- CLONE_VM: 共享地址空间(内核线程共享内核地址空间)。
- PF_KTHREAD: 这是区分内核线程的关键标志位。
- mm = NULL: 这是内核线程的“身份证”。
3.3 执行: 内核线程的运行机制
内核线程启动后, 并不直接执行用户提供的threadfn, 而是先进入一个通用入口点:
// 内核线程的通用启动函数
static int kthread(void *_create){
// 设置完成标志, 通知创建者
complete(done);
// 调度点: 让创建者继续执行
schedule();
// 设置退出处理
set_current_state(TASK_INTERRUPTIBLE);
// 执行实际的线程函数
ret = threadfn(data);
// 线程退出
kthread_complete_and_exit(&result, ret);
}
有趣的现象: 内核线程创建后默认处于TASK_INTERRUPTIBLE状态, 需要显式调用wake_up_process()才会开始执行。这给了创建者一个机会来设置线程参数。
3.4 状态变迁: 内核线程的一生
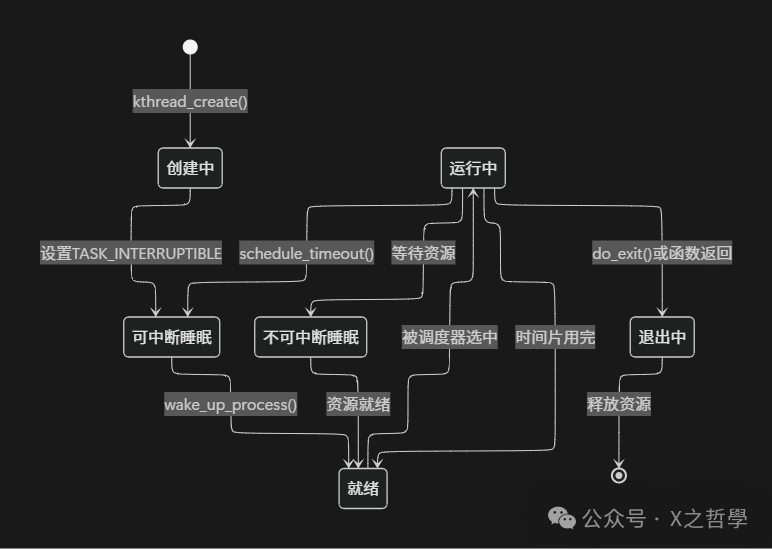
3.5 死亡: 内核线程的优雅退出
内核线程退出有几种方式:
- 自然死亡: 线程函数执行return语句。
- 自杀: 调用
kthread_stop()或do_exit()。
- 他杀: 其他线程调用
kthread_stop()。
// 停止内核线程的标准方式
int kthread_stop(struct task_struct *k){
// 设置停止标志
set_kthread_stop_info(k);
// 唤醒线程(如果它在睡眠)
wake_up_process(k);
// 等待线程真正退出
wait_for_completion(&kthread_done);
return kthread_result;
}
// 内核线程中的配合代码
int my_kthread_func(void *data){
while (!kthread_should_stop()) {
// 执行工作任务...
schedule_timeout(HZ); // 休眠1秒
}
return 0;
}
第四部分: 内核线程的调度与优先级
4.1 调度策略: 内核线程的“工作制度”
| Linux内核为不同任务设计了多种调度策略: |
调度策略 |
缩写 |
适用场景 |
内核线程示例 |
| 完全公平调度 |
SCHED_NORMAL |
普通任务 |
大多数内核线程 |
| 先进先出 |
SCHED_FIFO |
实时任务, 不可抢占 |
高优先级硬件处理 |
| 轮转调度 |
SCHED_RR |
实时任务, 可轮转 |
实时数据处理 |
| 截止时间 |
SCHED_DEADLINE |
有严格时间限制 |
多媒体处理 |
内核线程默认使用SCHED_NORMAL策略, 但可以通过sched_setscheduler()更改。
4.2 优先级体系: 内核线程的“紧急程度”
内核线程的优先级体系比较复杂, 涉及多个优先级数值:
// 优先级相关定义
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40) // 默认140
// 内核线程的nice值通常为0
#define KTHREAD_NICE_LEVEL 0
实时优先级 vs 普通优先级:
- 实时优先级: 0-99, 数值越高优先级越高。
- 普通优先级: 100-139, 数值越低优先级越高(对应nice值-20到19)。
第五部分: 实战示例: 创建自定义内核线程
5.1 完整示例: 系统监控线程
让我们创建一个简单的内核模块, 它会产生一个监控线程, 定期打印系统信息:
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/kthread.h>
#include <linux/delay.h>
static struct task_struct *monitor_task;
static int monitor_running = 1;
// 监控线程函数
static int system_monitor(void *data){
unsigned long jiffies_last = jiffies;
int interval = *((int *)data);
pr_info("System monitor thread started, interval=%d seconds\n", interval);
while (monitor_running && !kthread_should_stop()) {
unsigned long current = jiffies;
unsigned long elapsed = (current - jiffies_last) / HZ;
// 获取系统负载
struct sysinfo info;
si_meminfo(&info);
pr_info("[Monitor] Uptime: %lu seconds, "
"Free RAM: %lu KB, "
"Load avg: %lu.%02lu\n",
elapsed,
info.freeram * (info.mem_unit >> 10),
avenrun[0] >> 11, (avenrun[0] & 0x7FF) * 100 / 2048);
// 休眠指定间隔
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(interval * HZ);
}
pr_info("System monitor thread exiting\n");
return 0;
}
// 模块初始化
static int __init monitor_init(void){
int interval = 5; // 5秒间隔
pr_info("Initializing system monitor module\n");
// 创建内核线程
monitor_task = kthread_create(system_monitor, &interval, "sys_monitor");
if (IS_ERR(monitor_task)) {
pr_err("Failed to create monitor thread\n");
return PTR_ERR(monitor_task);
}
// 启动线程
wake_up_process(monitor_task);
return 0;
}
// 模块清理
static void __exit monitor_exit(void){
pr_info("Cleaning up monitor module\n");
// 停止线程
monitor_running = 0;
if (monitor_task) {
kthread_stop(monitor_task);
}
}
module_init(monitor_init);
module_exit(monitor_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Kernel Developer");
MODULE_DESCRIPTION("System monitoring kernel thread example");
5.2 编译和测试
创建Makefile:
obj-m := monitor.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
$(MAKE) -C $(KDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KDIR) M=$(PWD) clean
编译和加载:
# 编译模块
make
# 加载模块
sudo insmod monitor.ko
# 查看内核日志
dmesg | tail -20
# 查看线程是否存在
ps -ef | grep sys_monitor
# 卸载模块
sudo rmmod monitor
第六部分: 重要内核线程实例解析
6.1 内存管理: kswapd
kswapd是内核的内存回收线程, 当系统内存压力大时被唤醒:
// kswapd的主循环(简化版)
static int kswapd(void *p){
while (!kthread_should_stop()) {
bool ret;
// 进入休眠, 等待唤醒
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
// 计算需要回收的内存页数
pages = calculate_pressure();
if (pages > 0) {
// 执行内存回收
ret = balance_pgdat(pgdat, order);
}
// 回到休眠
schedule();
finish_wait(&pgdat->kswapd_wait, &wait);
}
return 0;
}
6.2 工作队列: kworker
kworker线程是工作队列机制的一部分, 用于异步执行延迟任务:

6.3 其他重要内核线程
| 线程名称 |
所属子系统 |
主要功能 |
唤醒条件 |
| ksoftirqd |
中断处理 |
处理软中断 |
软中断过多时 |
| migration |
CPU热插拔 |
任务迁移 |
CPU状态变化 |
| watchdog |
系统监控 |
检测系统挂起 |
定时器超时 |
| writeback |
文件系统 |
脏页回写 |
脏页过多或超时 |
| khugepaged |
内存管理 |
透明大页合并 |
扫描周期到达 |
第七部分: 调试与监控工具大全
7.1 基础监控命令
# 查看所有内核线程(通常用[]括起)
ps -ef | grep '\['
# 更清晰的查看方式
ps -eo pid,ppid,cmd,cls,pri,ni | grep -E "PID|\["
# 查看内核线程的调度策略
chrt -p <pid>
# 查看内核线程的栈使用
cat /proc/<pid>/stack
# 查看内核线程的状态
cat /proc/<pid>/status | grep -E "State|voluntary|nonvoluntary"
7.2 高级调试技术
7.2.1 ftrace跟踪内核线程
# 跟踪特定内核线程的函数调用
echo function > /sys/kernel/debug/tracing/current_tracer
echo kswapd0 > /sys/kernel/debug/tracing/set_ftrace_pid
echo 1 > /sys/kernel/debug/tracing/tracing_on
sleep 2
echo 0 > /sys/kernel/debug/tracing/tracing_on
cat /sys/kernel/debug/tracing/trace
7.2.2 perf性能分析
# 采样特定内核线程的CPU使用
perf record -g -p <pid> sleep 10
perf report
# 查看内核线程的调度延迟
perf sched record -- sleep 10
perf sched latency
7.3 可视化监控工具
| 工具名称 |
主要功能 |
适用场景 |
| htop |
交互式进程查看 |
实时查看内核线程CPU使用 |
| atop |
高级性能监控 |
历史性能数据分析 |
| trace-cmd |
ftrace前端 |
内核函数调用跟踪 |
| bpftrace |
eBPF动态追踪 |
高级内核调试 |
第八部分: 最佳实践与性能考量
8.1 内核线程设计原则
- 最小权限原则: 内核线程应只拥有必要的权限。
- 优雅退出机制: 必须响应
kthread_should_stop()。
- 避免忙等待: 使用适当的休眠机制。
- 资源清理: 确保退出时释放所有资源。
8.2 常见陷阱与解决方案
| 问题现象 |
可能原因 |
解决方案 |
| 内核线程无法创建 |
内存不足或达到进程上限 |
检查ulimit -u和内存使用 |
| 线程占用100% CPU |
忙等待或死循环 |
添加cond_resched()或休眠 |
| 线程无法停止 |
未检查kthread_should_stop() |
在循环中添加检查点 |
| 内存泄漏 |
退出时未释放资源 |
实现完整的清理函数 |
8.3 性能优化技巧
// 优化示例: 合理设置CPU亲和性
static int my_kthread_func(void *data){
// 绑定到特定CPU核心
cpumask_t mask;
cpumask_clear(&mask);
cpumask_set_cpu(2, &mask); // 绑定到CPU 2
set_cpus_allowed_ptr(current, &mask);
// 设置实时优先级(如果需要)
struct sched_param param = { .sched_priority = 50 };
sched_setscheduler(current, SCHED_FIFO, ¶m);
// 主循环
while (!kthread_should_stop()) {
// 工作任务...
// 优化点: 使用自适应休眠
if (work_pending()) {
schedule_timeout(HZ/10); // 100ms
} else {
schedule_timeout(HZ); // 1秒
}
}
return 0;
}
第九部分: 总结与核心要点
| 概念维度 |
关键要点 |
技术实现 |
| 本质区别 |
无用户地址空间, 完全在内核态运行 |
mm = NULL,PF_KTHREAD标志 |
| 创建方式 |
专用API, 非传统fork |
kthread_create(),kthread_run() |
| 调度特性 |
共享内核调度器, 多种策略可用 |
CFS调度类, 优先级0-139 |
| 生命周期 |
显式创建和停止 |
kthread_should_stop()机制 |
| 资源管理 |
共享内核资源, 无用户资源 |
借用前进程的active_mm |
| 调试手段 |
专用工具链 |
ftrace, perf等运维工具 |
理解内核线程不仅有助于编写更好的内核代码,更能深化对整个操作系统架构的认识。从kswapd的内存回收到kworker的异步任务,从migration的CPU热插拔支持到watchdog的系统健康监控,内核线程共同构建了支撑现代计算基础设施的核心后台服务体系。
 发表于 2025-12-13 04:01:22
|
查看: 247|
回复: 0
发表于 2025-12-13 04:01:22
|
查看: 247|
回复: 0
