这套系统跑了有一阵,组件越堆越多:知识库、AI 助手、好几层记忆、一堆定时任务。可这些东西全是看不见摸不着的,藏在一堆 Markdown 文件和命令行里。我想知道它什么状态,只能一个个翻文本、敲命令查,跟黑箱似的,特别费劲,还老拼不出全貌。
所以我就琢磨,给它做个仪表盘吧。说实话,我是真想做出那种数据中心监控大屏的效果,整面墙的指标灯,一眼扫过去哪块绿着、哪块报红,科技感拉满,看着就贼酷。但光酷没用,它更得落地实在,能把那些藏在文本里、平时根本看不见的东西,直接亮到我眼前。
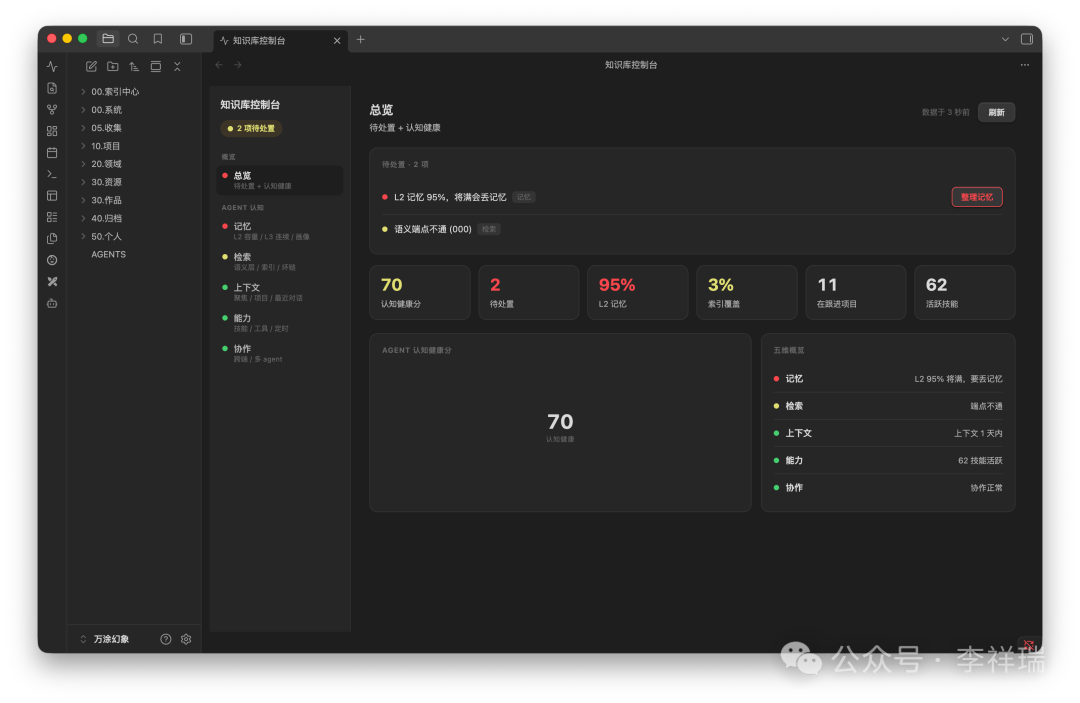
结果仪表盘真做出来,它劈头就给我亮了个红灯:我那 AI 的第二层记忆,95% ,快爆了。
接下来我干的事,可能有点反常。我没给它扩容。我花了一整天,教它学会了忘。
对,你没看错。我折腾这一通,就为了让我的 AI 学会遗忘。
01 先说说我这套知识管理
不过在讲我怎么折腾之前,得先花点时间说说这套知识管理是怎么回事,不然后面容易听懵。
这块我前后写过两篇文章,《00后一人公司,我是如何用Obsidian、Claude Code和Openclaw做知识管理的》和《如何让 Obsidian 成为 Claude Code 的大脑,让你的 Agent 越用越聪明》,感兴趣可以回看。一句话讲核心:我没把笔记软件当成存东西的仓库,而是当成我那个 AI 助手的“外接大脑”。知识、决策、踩过的坑,全沉淀在 Obsidian 里,AI 每次干活都从库里调记忆,用得越久越懂我。
而这个外接大脑里最关键的,是一套 三层记忆架构:最底层记“它是谁、我是谁”,身份和原则,基本不动;中间层记“怎么做一类事”,踩过的坑和方法,会更新;最上层记“今天聊了啥”,每天的流水,最活也最该清。一层比一层稳,越往上越该清。
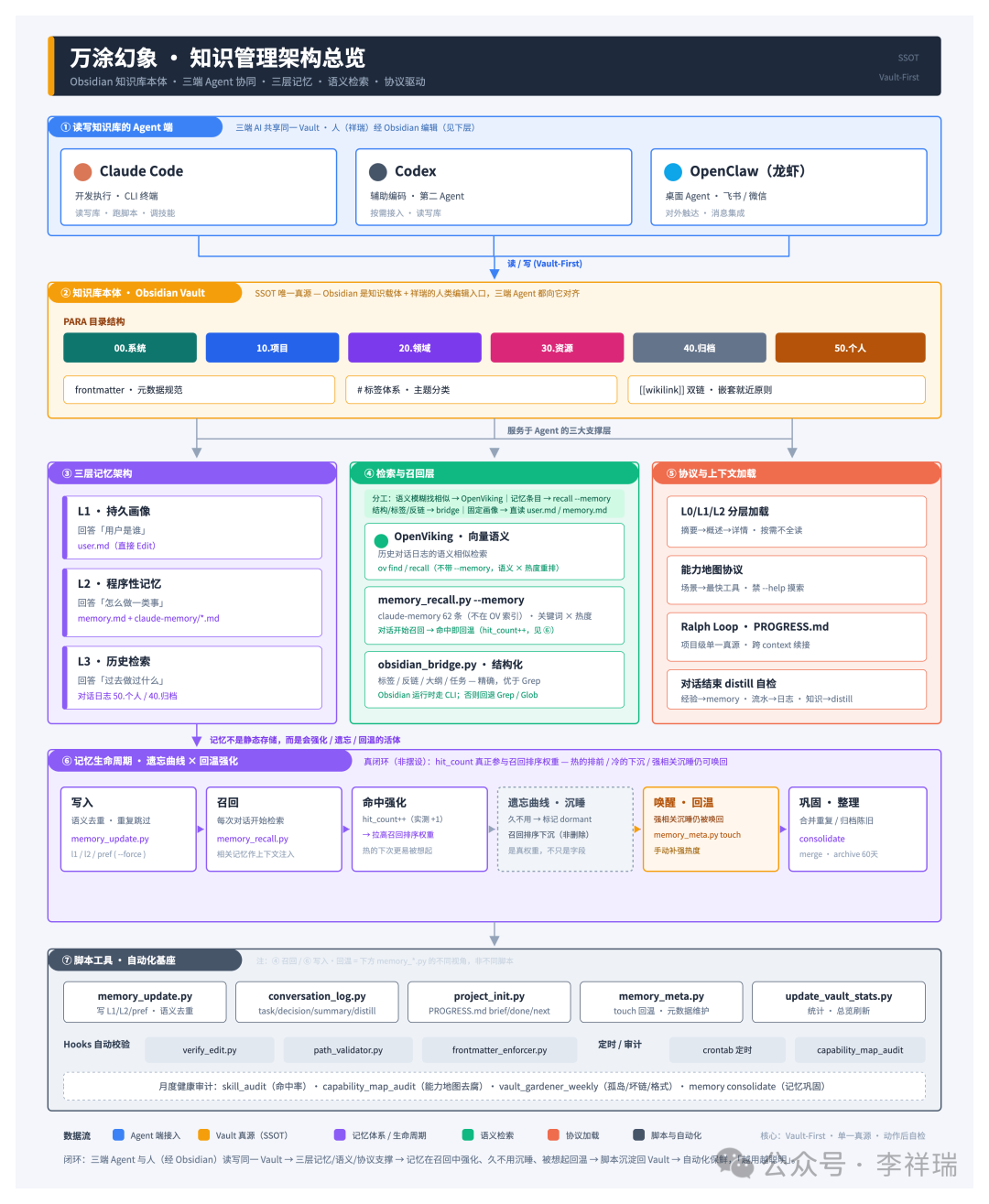
靠着它,我的 AI 不是每次都从零开始的金鱼,而是个能成长的助手。可凡是会成长的东西,长着长着总会遇上新麻烦。我这次撞上的,就是开头那个红灯。
02 第二层,爆了
红灯出在中间那层——程序记忆。
容量条干到了 95% 。
这意味着啥?意味着再记几条它就满,满了就得往外挤掉旧的。我赶紧试了系统自带的两招:合并重复的、归档陈旧的。结果你猜怎么着,一条都没处理掉。
为啥?因为里面的记忆全是近期的,还都不重复,每一条单拎出来看都挺有用。
这就把我架那儿了。删,舍不得,万一哪条以后正好用上;不删,马上就爆。
我盯着那个 95% 看了半天。说实话,那一下我有点卡住。倒不是技术上卡住,是脑子里那个根深蒂固的念头——记忆嘛,当然越多越好——突然就不太对劲了。
03 我突然想到人脑
卡着卡着,我想起一个事。
人脑是怎么处理这事的?人也天天往脑子里塞东西啊,怎么没见谁的脑子“满了”报警?
答案是,人会忘。
而且你注意,遗忘根本不是人脑的 bug,它是个特性。心理学里有条特别有名的曲线,叫艾宾浩斯遗忘曲线。说人学完一个东西,二十分钟就忘掉将近一半,一天之后忘掉三分之二。听着挺挫败是吧?可正是这套“该忘就忘”的机制,让你的脑子几十年都不会塞爆。
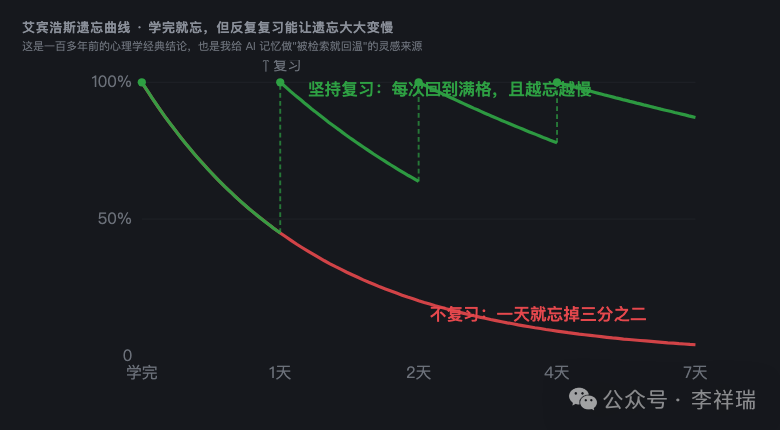
更妙的是,人脑忘东西是有讲究的。没用的、不碰的,慢慢就淡了;天天用的、要命的,牢牢钉着;偶尔想起来一次的,又重新变清晰。
不信你回想一下,背同一个东西,是天天过一遍记得牢,还是瞅一眼就完?答案其实你心里有数。
最典型的就是古诗文。高中那会儿,《岳阳楼记》《滕王阁序》那种长文言文,天天背得滚瓜烂熟,当年闭着眼都能默全篇。可上了大学再没碰过,现在你让我背两句,磕磕巴巴,早忘得差不多了。常翻的刻进脑子,撂下的慢慢还给老师。人脑一直在替我们做这种取舍,悄没声儿的。
我寻思了一下。凭什么我的 AI 记忆就只能一根筋地往里堆?
人会忘,而且忘得很聪明。那我也想让我的 AI 会忘,多少学一学人脑那套。
这个念头一冒出来,我整个思路就通了。问题从来不是“怎么扩容”,而是“怎么让它学会忘”。
04 让它学会聪明地忘
想清楚了方向,我分两步走。
第一步,先把台面收拾干净。
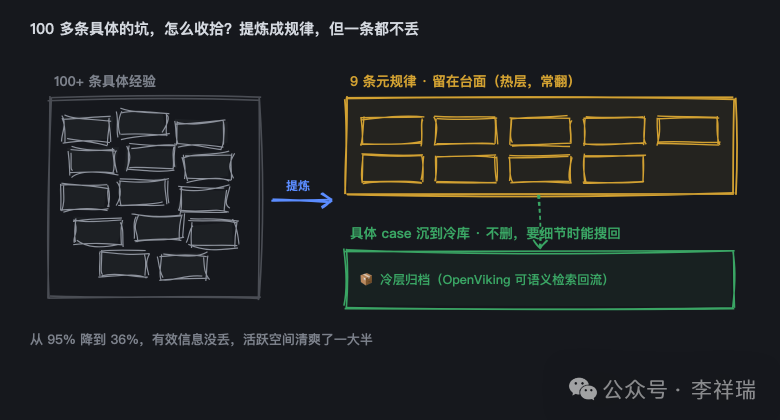
我把中间那层 100 多条具体的坑,提炼成了 9 条“元规律”。打个比方,我以前记了一堆飞书的坑:这个接口时间要用毫秒、那个认证要看 ID 不看名字、还有那个画布点不动。零零碎碎十几条。我把它们抽成一条:“调飞书任何接口,先查清字段格式、认证身份、接口版本。”一条顶十几条。
那具体那十几条删了吗?没有。我把它们沉到一个“冷库”里,平时不占地方,需要细节的时候还能搜回来。
就这么一弄,中间那层从 95% 直接掉到 36% 。有效信息没丢,活跃空间却腾出来一大半。
第二步,才是重头戏:给它装上遗忘曲线。
这一步我想了挺久,因为遗忘这事做不好会把整个系统搞坏。你要是简单粗暴“超过 30 天没用就删”,那完蛋,我的核心身份记忆几个月不主动调用,不就被你当垃圾清了?那不叫遗忘,那叫脑损伤。
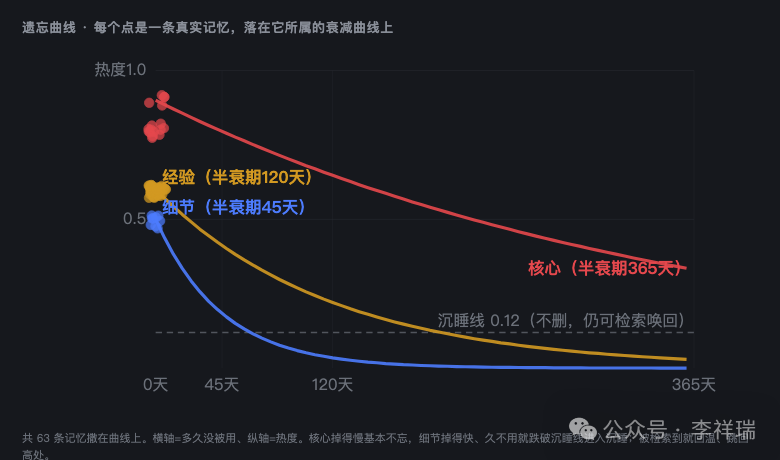
人脑的高明之处在于,它的遗忘是“自适应”的。越重要的,半衰期越长,几乎不忘;越细枝末节的,忘得越快。
所以我给每条记忆都算了个“热度”。这个热度由三样东西决定:它有多重要、多久没被用了、被翻出来过几次。
核心记忆,半衰期我给它定了 365 天。意思是哪怕一年不碰,它的热度也才掉一半,基本忘不掉。经验类的,半衰期 120 天。而最细的那些具体 case,半衰期只有 45 天。两个多月不用,它就慢慢凉下去。
凉到一定程度会怎样?会“沉睡”。
注意,是沉睡,不是删除。这是我特别在意的一点。一条记忆热度跌破某个线,系统就给它标个“沉睡”,平时不进上下文,也不挤占常用记忆的位置。但它没被删,还躺在库里,你哪天语义一搜,它“噌”地就被唤回来了。
这套“沉睡但不删”,还顺手解决了一个特别现实的问题:省 token。
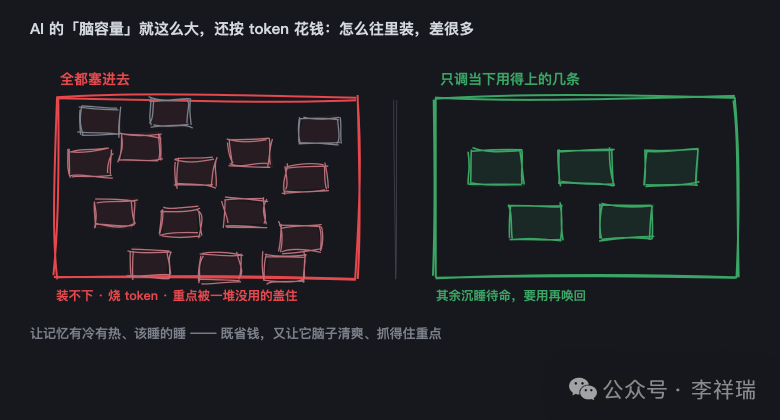
用过 AI 的都知道,它每次干活都得把相关记忆塞进“脑容量”里,也就是上下文。而这块容量按 token 花钱,还特别有限。要是几百条记忆不分冷热、条条都往里塞,那不光烧钱,还容易把它淹了,真正要紧的那几条反而被一堆陈芝麻烂谷子盖住。
让记忆有冷有热、该睡的睡,等于每次只把当下用得上的那几条调出来,剩下的安安静静躺在库里待命。又省钱,又让它脑子清爽,抓得住重点。这一点,其实跟人也一样:满脑子糨糊的时候,你反而想不起最该想起的事。
这又让我想起人脑的另一个机制。你有没有过那种体验:一个特别久没想起的事,某个气味、某句话,啪一下全回来了。它没真消失,只是睡着了。
更绝的是回温。我借鉴的是脑科学里一个叫“测试效应”的说法:主动回忆一个东西,往往比反复重读更能记牢,被回忆过的记忆会更结实一点。我把这个思路也搬了过来:任何一条记忆,只要被检索命中一次,它的热度就自动往上跳,从沉睡里被唤醒。
被想起,就是被强化。这个逻辑,跟人脑有点像。
这么一来,整套机制就转起来了。说白了就是:我最近反复用到的那些记忆,热度最高,它就优先记着、优先调出来用;撂在一边一直不碰的,热度一天天往下掉,直到沉睡。用得越多越清晰,用得越少越淡。一条记忆是活蹦乱跳还是睡过去,基本就看我还用不用它。
说到这儿插一句,我后来查资料发现,真有学者在干这事。有篇论文就叫 FadeMem,专门研究怎么让 AI 仿照生物的方式遗忘,据说能省下四成多的存储。所以这条路不是我瞎拍脑袋,是有人认真在走的。
那市面上那些 AI 记忆方案呢?我特意去扒了一圈。 MemGPT 、 Mem0 、还有斯坦福那个会过日子的 AI 小镇。你会发现,主流的劲儿更多使在“怎么把记忆扩展得更大、检索得更准、长期更一致”上。而我这套,核心命题反过来了:不是记更多,是忘得更聪明。
05 我还想亲眼看见它忘
机制齐活了。但还记得一开始那个仪表盘吗?它现在派上大用场了。
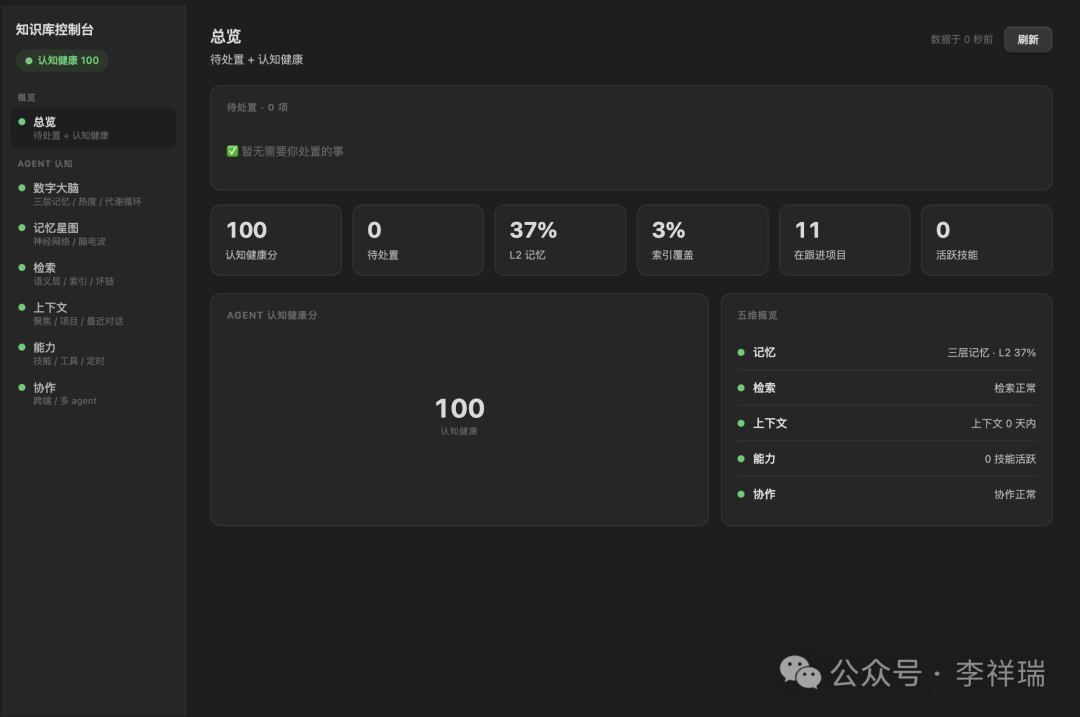
我干脆把它升级成了一个“数字大脑”,直接做进我天天用的 Obsidian 里。
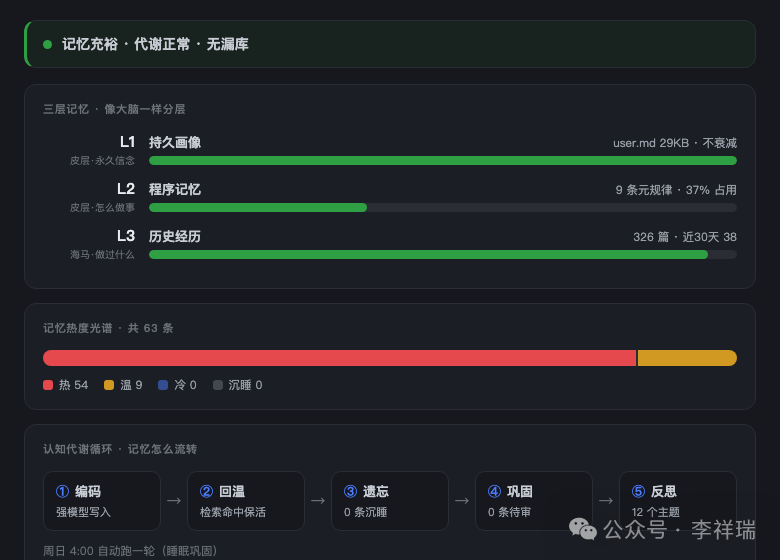
打开它,三层记忆各自多满、热度怎么分布、多少条是热的、多少条在沉睡,一目了然。最上面还有一句话体检:核心记忆都活跃没、有没有哪条在变冷。
但我最得意的是另外两张图。
一张叫“记忆星图”。我把每一条记忆当成一个神经元,按热度发光,热的亮、凉的暗、沉睡的几乎看不见。记忆和记忆之间有关联的,就连根线。然后让一阵阵脉冲沿着这些线传,就像真的脑电波,像神经在放电。看着那一团东西明明灭灭地搏动,我第一次有种感觉:这玩意儿是活的,它真在那儿“想事情”。
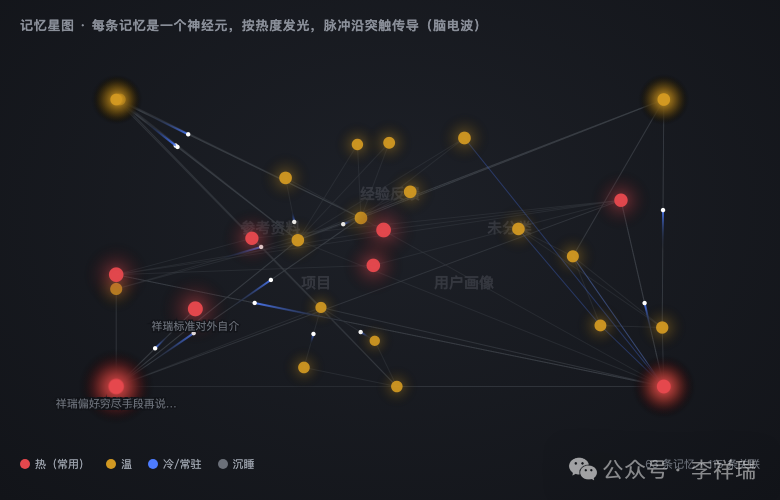
还有一张,就是前面那条遗忘曲线。我把六十多条真实记忆全撒在曲线上。横轴是多久没用、纵轴是热度。鼠标移上去,就告诉你这是哪条记忆、凉到什么程度了、离沉睡线还有多远。点一下,直接打开它。
哪条核心记忆开始往下掉了,我一眼就看见,点一下唤醒它。哪些细节已经沉到水面以下了,清清楚楚。
它不再是个会爆的文件夹了。它是一个会呼吸、会代谢、能让我看着它呼吸代谢的东西。
而这一切,都是从我那个“想给它做个仪表盘”的念头开始的。
06 它反过来照出了我
本来到这儿就该收尾了。但系统跑起来之后,出了件我没想到的事。
我给它加了一个“反思”的功能。每隔一阵,它会回看我最近都在干啥,把反复出现的主题挑出来。本意是让 AI 自己发现“主人最近的重心在哪”。这就像是给 AIGC 应用植入了一套元认知探针,让它能自我审视。
结果它第一次反思,给我列了这么一行:最近三十天,你反复在做的是公众号、内容策略、文案。
我看着这行字,愣了一下。
因为我嘴上一直说,我的主业是飞书多维表格的 AI 落地。可这面镜子照出来的是:我实际把大把时间,花在了内容上,离我说的那条主线飘了。
你看,这就有意思了。我造这套记忆系统,本来是想让 Agent 更懂我。结果它转过头来,把我自己都没太敢承认的事,平平静静摆在我面前。
这有点像人脑的“默认模式网络”,就是你发呆走神时,大脑在后台默默复盘、把零碎的事串成对自己的认知。我没想到,给 AI 装的这套东西,居然也长出了这么一只眼睛,反过来盯着我。
它不光会记、会忘,它还会照我。
写在最后
最后还得说句实在话。
这套东西,纯粹是我自己瞎折腾出来的实践,算不上啥标准答案。脑科学我是外行,资料是现学现卖的;工程上那些参数、半衰期到底定多少天合适,也都是我先拍个数,再慢慢调。里头肯定有不严谨、甚至压根就不对的地方。我不敢说这就是正解,就是把自己的摸索掏出来跟你唠唠,有不对的,欢迎拍。
折腾完这一整套,我自己最大的感受,其实跟技术没啥关系。
我们这代人,好像有种执念,总觉得“记得越多越牛”。备份要全、笔记要满、什么都别丢。AI 出来之后,这执念更重了,恨不得给它喂一个永不遗忘的完美大脑。
可真把人脑搬出来一对照,你会发现,人之所以是人,恰恰因为我们会忘。会忘,才学会了抓重点;会忘,才不至于被每一件鸡毛蒜皮压垮;那些忘了又被某个瞬间唤回的东西,才显得格外珍贵。
记得多,从来不是本事。知道什么该牢牢记住、什么可以慢慢淡掉、什么在被需要时还能找回来,这才是。
往实在了说,给 AI 装上会遗忘的能力,对我不是炫技。一个 AI 系统,你要长期用、还指望它越用越顺手,就得有人时不时给它做做保养,跟养车、养身体一个道理。记忆管不管得好,往往就决定了它是越用越聪明,还是越用越糊涂。
我没把我的 AI 变成一个记忆怪物。我让它,更像一个人了。
它会记,会忘,会在被想起的时候,重新清晰起来。
挺好。
 发表于 2026-6-6 18:33:16
|
查看: 124|
回复: 0
发表于 2026-6-6 18:33:16
|
查看: 124|
回复: 0
