项目卡片
- 项目:Supertonic [1]
- 状态:v3 / 11.1k Star / 1.1k Fork / 2025.11 开源至今半年迭代 3 个大版本
- 一句话判断:目前开源阵营里覆盖面最广的 TTS 引擎,仅凭 99M 参数就实现了 0.7B-2B 级模型才有的多语言覆盖与音质水平。
这是什么
Supertonic 是一款完全本地运行的文本转语音(TTS)引擎。输入一段文字,输出一段 44.1kHz 16-bit WAV 音频。没有云端 API 调用,没有数据上传,模型就在你的设备上跑。
背后的推理引擎是 ONNX Runtime,模型以 ONNX 格式发布。这意味着它天然跨平台:Python、Node.js、浏览器(WebGPU + WASM)、C++、C#、Go、Rust、Swift、Java、Flutter、iOS——同一个模型,12 种运行时。在 云栈社区 的开发者圈子里,这种“一次导出,到处部署”的思路一直是大家讨论的热点。
核心数字:99M 参数。
当前开源 TTS 的主流选手大多在 0.7B 到 2B 参数区间。Supertonic 的体量只占它们的十分之一到二十分之一,但在多语言朗读准确率和音质上保持在同一梯队。仓库的 benchmark 数据显示,在 MiniMax-MLS-Test 基准上,Supertonic 3 的词错率(WER)和多数大模型处于同一范围内,英语 2.06、德语 0.86、西班牙语 1.13,部分语言甚至优于更大的竞品。

值得关注的三个点
跨平台覆盖面。 开源 TTS 项目不少,但一个仓库同时给出 12 种运行时示例的非常罕见。ONNX 在这里起到了关键作用——模型只导出一份,各平台通过 ONNX Runtime 绑定来加载推理,不需要为每个平台单独训练或转换。
端侧推理是真能用的,不是 demo。 树莓派、电子书阅读器、Chrome 浏览器——仓库里有 Onyx Boox Go 6 电子书在飞行模式下跑 TTS 的演示,平均 RTF(实时率)0.3 倍,生成速度是播放速度的三倍。Chrome 扩展 TLDRL 能在一秒内把整个网页转成语音朗读,推理全在浏览器内完成,零网络请求。
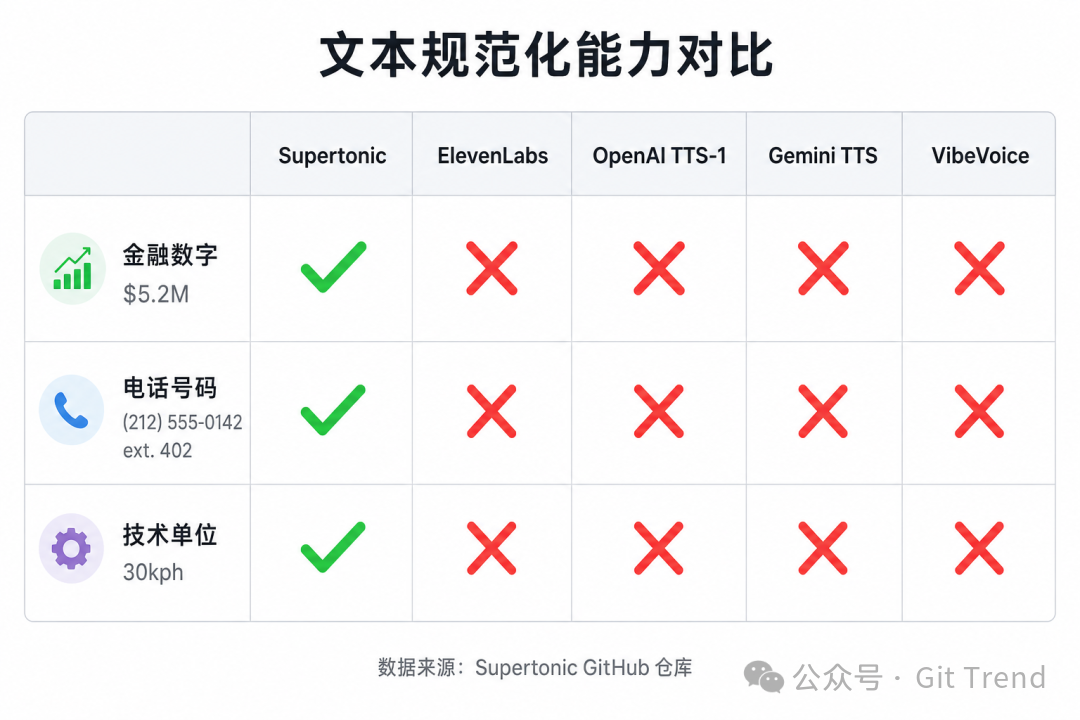
文本规范化能力是个意外的强项。 在处理金融数字($5.2M → “five point two million dollars”)、电话号码((212) 555-0142 ext. 402)、技术单位(30kph → “thirty kilometers per hour”)时,不需要任何预处理就能正确朗读。仓库的对比测试中,ElevenLabs Flash v2.5、OpenAI TTS-1、Gemini 2.5 Flash TTS 在这三类文本上全部失败,只有 Supertonic 全部通过。对需要朗读带数字、符号、缩写的实际文本(财报、技术文档、地址)的场景来说,这个能力很实用。
快速上手
最简单的路径是 Python:
pip install supertonic
三行代码出声:
from supertonic import TTS
tts = TTS(auto_download=True) # 首次运行自动从 Hugging Face 下载模型
style = tts.get_voice_style("M1") # 10 种预设音色(M1-M5 男声,F1-F5 女声)
wav, duration = tts.synthesize(
text="Hello, this is a quick demo.",
lang="en", # 31 种语言,不确定时传 lang="na"
voice_style=style,
total_steps=8, # 5(低)~12(高),默认 8
speed=1.05,
)
tts.save_audio(wav, "output.wav")
首次运行自动从 HuggingFace 下载模型,之后完全离线可用。模型文件不大,下载一次就能反复使用。
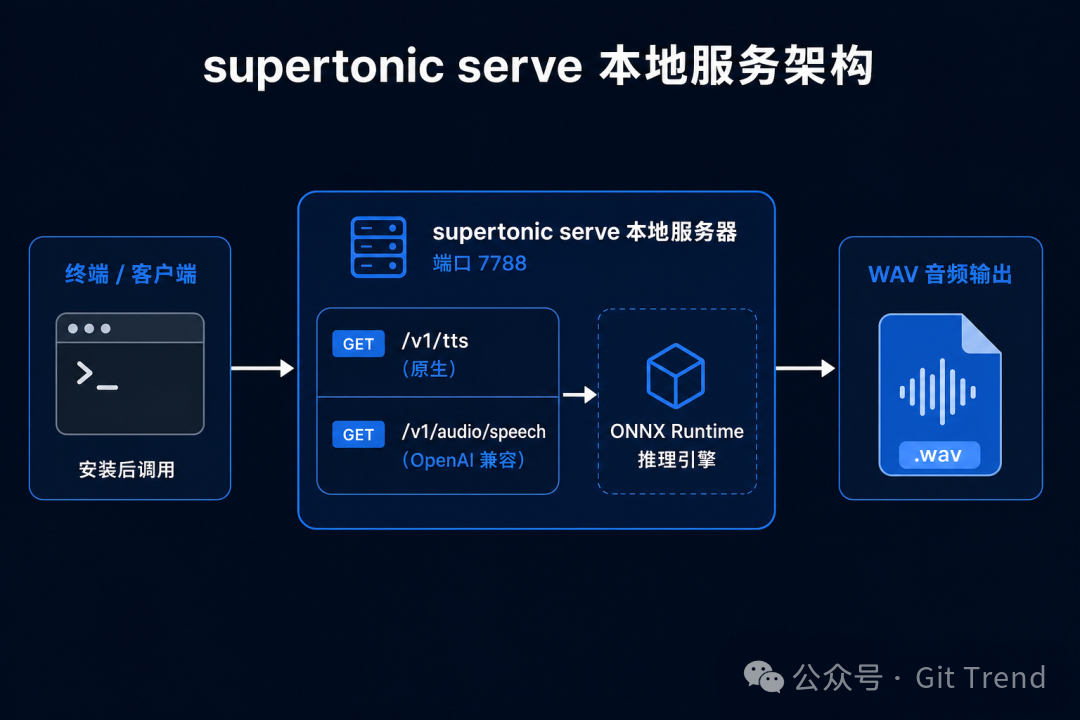
如果你的工具链已经走 HTTP 协议——比如本地 agent、Electron 应用、OpenAI 兼容的音频客户端——SDK 自带本地 HTTP 服务:
pip install 'supertonic[serve]'
supertonic serve --host 127.0.0.1 --port 7788
启动后暴露原生 /v1/tts 端点和 OpenAI 兼容的 /v1/audio/speech 端点,可以直接对接现有工具链。
谁该关注这个项目
需要离线或隐私优先 TTS 的开发者。 医疗、法律、教育场景下,语音合成涉及的文本可能包含敏感信息,不适合上传云端 API。Supertonic 全程本地运行,数据不出设备。
做浏览器或移动端产品的团队。 WebGPU + WASM 推理支持意味着 TTS 可以嵌入网页前端或 Electron 应用,不依赖后端服务。iOS 和 Flutter SDK 也直接可用。
想给工具加语音反馈的开发者。 仓库已列出不少实际案例:Claude Code / Cursor 的本地语音回复工具 Aftertone、开源浏览器朗读扩展 Read Aloud、ePub 阅读器 PageEcho、talking avatar 生成器 OmniAvatar。还有一个基于 MNN 的轻量化移植版 supertonic-mnn,支持 fp32/fp16/int8 量化,进一步降低部署门槛。

需要注意的边界
不支持中文。 31 种语言包含日语和韩语,但不包括中文普通话或粤语。中文场景需要另找方案。
音色固定,无内置声音克隆。 开源仓库提供 10 种预设音色,不包含声音克隆管线。自定义音色需要通过官方在线工具 Voice Builder [2] 上传参考录音生成配置文件,这是云端服务,不是本地操作。
模型许可和代码许可不同。 代码是 MIT,模型是 OpenRAIL-M。嵌入模型权重前需确认条款是否满足商用需求。
GPU 推理未就绪。 Python SDK 中 GPU 路径标注为 “not fully tested”,当前推荐 CPU 推理。好在 99M 参数体量下 CPU 推理已经足够快。
没有流式输出。 当前实现是生成完整音频后返回,不支持边生成边播放。长文本场景下,用户可能会有等待感。

总结
99M 参数、CPU 推理、31 种语言、12 种运行时、零网络依赖——这些标签堆在一起,Supertonic 基本上是目前开源 TTS 里端侧覆盖面最广的选择。pip install supertonic 加几行代码就能出声,上手门槛几乎为零。
前提是你接受它的边界:没有中文、没有内置声音克隆、没有流式输出。它适合嵌入工具和产品做功能性语音,但别指望它当专业配音引擎。
引用链接
[1] Supertonic: https://github.com/supertone-inc/supertonic
[2] Voice Builder: https://supertonic.supertone.ai/voice-builder
 发表于 2026-6-10 21:21:03
|
查看: 169|
回复: 0
发表于 2026-6-10 21:21:03
|
查看: 169|
回复: 0
