摘要
很多同学第一次做量化评估都会遇到同一种崩溃感:
张量对比看起来还行,但 mAP 掉了;或者 mAP 还行,某些层的数值指标却很难看。
这并不代表你“做错了”,而是量化评估本来就不是单指标问题。
这篇文章用工程视角把 Day7 的核心内容重构成一条可复用的方法链:
先看什么、后看什么、什么指标该信、什么情况该重做量化、什么时候该从 PTQ 升级到 QAT。
你读完后应该能做到两件事:
- 独立跑完 ONNX vs OMC 的评估闭环;
- 看到异常结果时,能快速定位问题而不是盲目调参。
关键词:量化评估、余弦相似度、平均绝对偏差、mAP、ONNX、OMC、PTQ、QAT
目录
- 为什么量化评估一定要分层做
- 张量级指标:余弦相似度与绝对偏差
- 任务级指标:mAP 才是最后裁判
- 两个核心脚本怎么跑、怎么读
- 指标“打架”时怎么判断谁对
- 为什么检测头最容易出事
- 一套可落地的评估流程(含决策树)
- 精度优化策略:从低成本到高成本
- PTQ vs QAT:什么时候该升级
- 高频问题与实战建议
1)为什么量化评估一定要分层做
先说结论:只看一个指标,几乎一定会误判。
量化评估至少要分三层:
- 张量级:看每层输出数值差异(方向、幅度)。
- 特征级:看关键特征图是否失真(尤其是检测头前后)。
- 任务级:看最终业务指标(mAP/Recall/Precision)。
你可以把它理解成“体检”:
- 张量级像抽血化验,快、细,但不能代表全部症状。
- 任务级像临床诊断,慢一点,但最后要听这个。
所以工程里正确顺序是:
张量级先筛查 -> 任务级做裁决 -> 回到关键层定位原因。
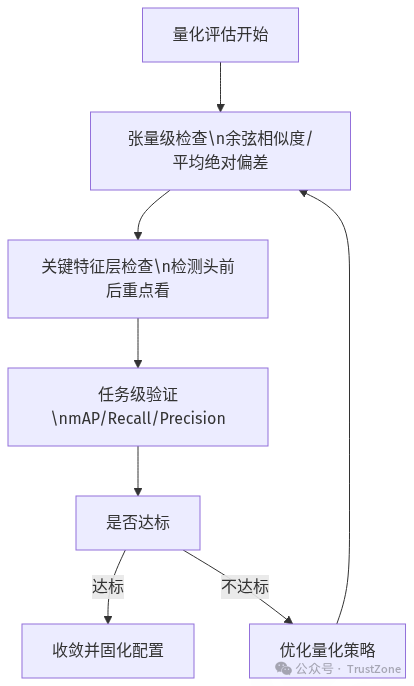
量化评估分层闭环流程图
实践要点:不要只看任务指标,也不要只看张量指标。两者结合,才能避免误判和漏判。
2)张量级指标:余弦相似度与绝对偏差
这一部分是最快给你反馈的,所以一定要会看。
2.1 余弦相似度(Cosine Similarity)
它看的是方向像不像,不是数值是否完全一致。
cos = (A · B) / (||A|| * ||B||)
在你的脚本里通常会显示为百分比。实战经验可用这套粗分:
| 余弦相似度 |
工程判断 |
| > 99.9% |
极好,通常很稳 |
| 99.0% - 99.9% |
良好,可接受 |
| 95.0% - 99.0% |
需关注关键层 |
| < 95.0% |
高风险,建议排查 |
注意:余弦高,不代表 mAP 一定高;余弦低,也不代表 mAP 一定崩。
2.2 平均绝对偏差百分比(MAD%)
它看的是数值差了多少:
MAD% = Σ|A_i - B_i| / Σ|A_i| * 100%
实战里通常这样读:
| 平均绝对偏差 |
工程判断 |
| < 1% |
极好 |
| 1% - 5% |
良好 |
| 5% - 10% |
有风险 |
| > 10% |
需要重查 |
2.3 阈值占比:你最容易忽略但很好用的指标
你脚本里常见 [0.1, 0.01, 0.001] 三个阈值占比。
这个指标特别适合看“是不是有一批点偏得很厉害”:
>0.1 占比:大误差点比例,越接近 0 越好。 >0.01 占比:中误差密度。 >0.001 占比:小误差噪声面。
实践要点:平均偏差正常并不代表没有局部异常。阈值占比指标用于识别“少量但高风险”的离群误差点。
3)任务级指标:mAP 才是最后裁判
张量级再漂亮,最后还是要回到任务结果。
3.1 mAP 为什么是黄金指标
目标检测最终关心的是:
该检出的目标有没有检出(Recall),以及检出的是否靠谱(Precision)。
mAP 本质是各类别 AP 的平均值,AP 来自 PR 曲线面积。
常见两种口径:
mAP@0.5:IoU=0.5 的精度,偏“好检出”。 mAP@0.5:0.95:更严格,综合质量更真实。
3.2 一个你会经常遇到的现实
有些模型量化后:
mAP@0.5 只掉一点; - 但
mAP@0.5:0.95 掉得明显。
这通常意味着:检测还在,但框定位质量变差了。
这时别急着怀疑全网,优先查检测头和后处理阈值。
4)两个核心脚本怎么跑、怎么读
量化评估中最核心的两类脚本是:
compare_onnx_and_omc.py:张量级快筛 calibrate_onnx_and_omc.py:任务级终判
4.1 compare_onnx_and_omc.py(张量级)
它做的事情本质上是:
- 同一输入跑 ONNX(FP32)和 OMC(INT8)
- 对齐输出层(或中间层)
- 计算每层相似度、偏差、阈值占比、最大偏差
你该重点看什么
- 检测头前后层是否异常(优先级最高)
- 是否出现“某几层突然断崖式变差”
>0.1 占比是否在关键层飙升
什么情况需要立即停下来排查
- 关键输出层余弦低于 99% 且 mAP 同时明显下降
- 平均偏差不高,但阈值大偏差占比异常高
- 最后一层最大偏差远高于其他层
4.2 calibrate_onnx_and_omc.py(任务级)
它做的是完整任务闭环:
- 统一数据与预处理
- 分别推理 ONNX 与 OMC
- 统一后处理、统一评估器
- 输出 mAP/Precision/Recall 差异
你该重点看什么
mAP@0.5 与 mAP@0.5:0.95 的差异形态 - Recall 是否明显掉(常指向阈值/检测头)
- Precision 是否明显掉(常指向误检增多)
一句经验话:
如果两个脚本给出的结论冲突,不要急着“二选一”,先确认数据、预处理、后处理是否完全一致。
5)指标“打架”时怎么判断谁对
这是实战里最常见的困惑。
情况 A:张量指标不错,但 mAP 掉得多
高概率原因:
- 误差集中在高敏感层(检测头/最后输出层)
- 置信度在阈值附近漂移,触发漏检
- NMS 排序被细微扰动放大
情况 B:张量指标一般,但 mAP 几乎不掉
可能原因:
- 误差主要在不敏感层
- 关键语义仍被保留
- 后处理阈值对该误差不敏感
快速判断原则
- 业务上线看任务级:mAP/Recall/Precision。
- 定位根因看张量级:找到哪一层、哪一类误差。
- 两者不是替代关系,而是“裁判 + 法医”的关系。
6)为什么检测头最容易出事
这一节聚焦检测头在量化中的高敏感性,并给出可直接用于排查的工程解释。
6.1 它是最后一道关
检测头误差没有“后续层兜底”,直接体现在最终框、置信度、类别上。
6.2 它的数值范围小,绝对误差更致命
同样是 0.01 误差:
- 对数值 100 的层:几乎可忽略
- 对数值 0.1 的置信度:就是 10% 相对波动
6.3 它对非线性和阈值非常敏感
- Sigmoid 在部分区间对输入扰动敏感
- NMS 按分数排序,微小变化可能改写保留结果

检测头量化敏感性误差传导图
结论:前序层的小误差通常还有被后续网络缓冲的空间,而检测头的小误差会更直接地放大为漏检或误检风险。
7)一套可落地的评估流程(含决策树)
下面这套流程可以直接拿去用。
Step 1:先固定评估环境
- 同一验证集
- 同一预处理(letterbox/normalize)
- 同一后处理(conf、iou、NMS)
- 同一评估器口径
Step 2:先跑张量级快筛
- 全层统计一次
- 锁定关键异常层
- 建立“问题层候选名单”
Step 3:跑任务级终判
- 对比 ONNX vs OMC 的 mAP/Recall/Precision
- 看整体是否达业务阈值
Step 4:按异常类型回溯优化
- 关键层异常 -> 量化参数/标定数据
- 任务级掉 Recall -> 阈值与检测头优先
- 任务级掉 Precision -> NMS/后处理优先
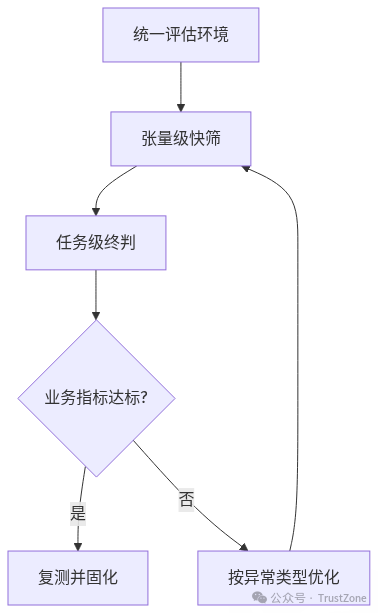
量化评估决策树流程图
8)精度优化策略:从低成本到高成本
建议按成本递增,不要一上来就 QAT。
第一层(低成本,优先做)
- 标定数据更有代表性
- 保证标定/推理预处理一致
- 调整校准方法(MinMax vs KL)
- 检查关键层量化粒度(如权重 per-channel)
第二层(中成本)
- 针对关键层做更细粒度分析
- 调整后处理阈值做鲁棒性验证
- 对困难样本做定向评估
第三层(高成本)
- 进入 QAT 微调
- 针对敏感头部做专项训练策略
- 完整回归测试与部署链路重验
一句经验话:
70% 的问题通常在第一层就能解决,别把简单问题训练化。
9)PTQ vs QAT:什么时候该升级
9.1 你可以先用这张表做决策
| 维度 |
PTQ |
QAT |
| 上手速度 |
快 |
慢 |
| 工程复杂度 |
低 |
高 |
| 训练资源要求 |
低 |
高 |
| 精度上限 |
中高 |
更高 |
| 推荐顺序 |
先做 |
PTQ 不达标再做 |
9.2 什么时候坚持 PTQ
- 项目时间紧
- 当前精度已接近或达到业务要求
- 团队暂时不具备稳定重训条件
9.3 什么时候必须上 QAT
- PTQ 多轮优化后仍明显不达标
- 业务精度红线非常严格
- 你能保证训练闭环可复现
一句实战建议:
先把 PTQ 做到你能力范围内最好,再决定要不要付出 QAT 成本。
10)高频问题与实战建议
Q1:我需要看所有层吗?
第一轮建议全层扫,后续重点盯关键层(检测头、最后输出层、异常断点层)。
Q2:验证集要多大才够?
没有绝对值。关键是覆盖真实场景分布。
建议先用中等规模做趋势判断,再补难例做稳定性确认。
Q3:数值指标好,mAP 还是掉怎么办?
优先查:
- 后处理阈值是否与 FP32 完全一致
- 检测头输出是否在阈值附近漂移
- NMS 相关参数是否一致
Q4:什么时候该“停止优化、接受结果”?
当你满足这三点时可以收敛:
- 业务核心指标达标
- 回归波动在可控范围
- 优化成本已明显高于收益
结语:把评估当作“定位系统”,而不是“打分系统”
很多人把量化评估理解成“打个分看看行不行”。
更成熟的做法是把它当成定位系统:它不是只告诉你“坏了”,还应该告诉你“坏在哪、先修哪”。
你如果把这篇文章里的三件事用起来:
- 分层评估思维
- 双脚本闭环
- 成本递增优化策略
基本就能避开量化评估里最耗时间的盲目试错。
最后送你一句项目里很好用的话:
没有不能解释的结果,只有还没分层看清的问题。
在云栈社区,我们相信精准的定位比盲目调参更重要。
 发表于 2026-5-30 04:10:11
|
查看: 142|
回复: 0
发表于 2026-5-30 04:10:11
|
查看: 142|
回复: 0
