1. torch.compile 与 Graph Break
PyTorch 2.x 引入的 torch.compile 通过将 Python 代码编译成静态计算图来加速模型执行。编译器会尝试将一系列操作融合为一个计算图,从而减少 Python 开销并启用算子融合。
然而,编译器并非万能。当代码中包含某些“动态”特性时,它无法继续构建完整的图,只能回退到 Python 解释器执行这部分代码,并在图中插入一个断点。这就是 Graph Break。
Graph Break 会损害性能,因为跨越断点的操作无法被融合和优化。控制流相关的操作(如依赖张量数值的 if 语句、动态循环次数)是导致 Graph Break 的最常见原因。
本文首先解释为什么控制流会打断 torch.compile,并用多个示例代码展示触发 Graph Break 的典型场景。然后简要介绍 ONNX 静态图框架如何处理控制流——它通过 If 和 Loop 算子将控制流显式纳入静态图,这一思路可以被 torch.compile 借鉴。最后讨论静态图框架的局限性。
2. 为什么控制流会打断 torch.compile?
要理解这个问题,需要区分编译时与运行时。
torch.compile 在第一次执行函数时,会“追踪”代码路径,试图构建一个静态的计算图。静态图要求所有算子的形状、数据类型以及控制流的方向在编译时都是已知的或可推导的。
当控制流依赖于张量的实际数值时,情况就变得棘手了。
- 张量的数值在编译时是未知的。例如,
x.sum().item() 的结果取决于输入数据,编译时无法知道它是正还是负。
- 如果编译器不知道走哪个分支,就无法生成单一的静态图。它必须保留两个分支的可能性,但这在传统的静态图中很难表达(除非引入特殊的控制流算子)。
- 因此,
torch.compile 选择了一种保守的策略:遇到无法静态决定的控制流,就插入 Graph Break,把决策权交还给 Python 解释器。
换句话说,Graph Break 的本质是静态图表达能力不足与动态语言灵活性之间的矛盾。编译器无法将所有 Python 动态特性都映射到静态图表示中。
此外,torch.compile 当前的中间表示并不原生支持带有动态条件的 if 或可变循环边界。虽然可以表示静态的 if(条件为常量),但无法表示数据依赖的分支。这也是 Graph Break 频繁发生的技术原因。
下图展示了 Graph Break 发生时的计算图结构:
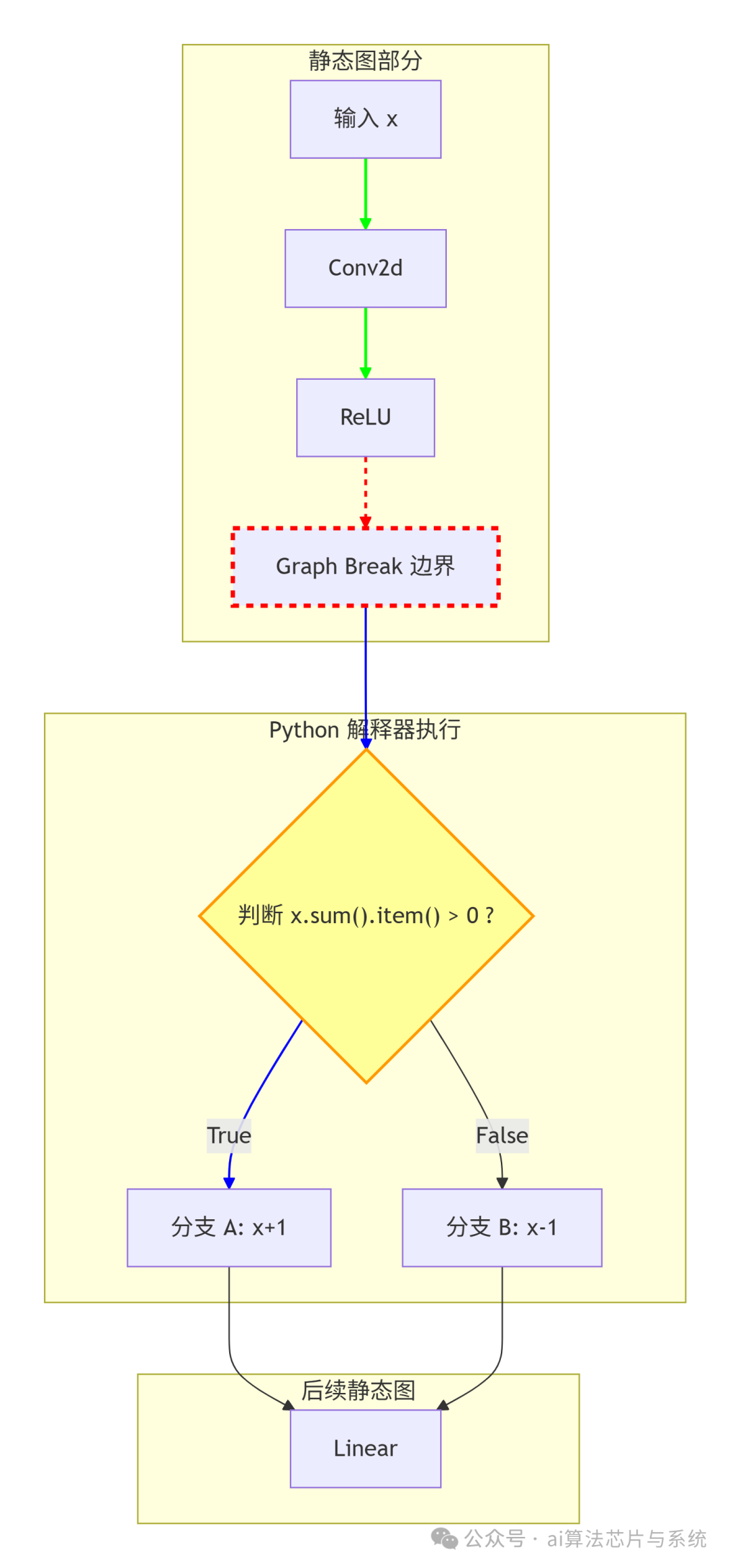
图中红色虚线框表示 Graph Break 的边界,橙色节点表示由 Python 解释器动态执行的条件判断,绿色箭头表示静态图中的正常数据流。
3. 典型示例:哪些代码会触发 Graph Break
下面通过多个示例展示触发 Graph Break 的常见模式。
3.1 使用 .item() 作为条件
import torch
@torch.compile
def func(x):
if x.sum().item() > 0:
return x + 1
else:
return x - 1
x = torch.randn(3, 3)
func(x) # 触发 Graph Break
原因:x.sum().item() 将张量转换为 Python 标量,该标量在编译时未知,编译器无法决定分支。
3.2 使用张量比较后直接作为条件(同样会 Break)
@torch.compile
def func(x):
if x.sum() > 0: # x.sum() 是张量,但 > 0 返回布尔张量
return x + 1
else:
return x - 1
x = torch.randn(3, 3)
func(x) # 仍然触发 Graph Break
原因:即使没有 .item(),x.sum() > 0 返回的是一个布尔张量(可能包含多个值),Python 的 if 无法处理多元素布尔张量。编译器需要将其规约为标量,但规约本身也是数据依赖的。
3.3 动态循环次数
@torch.compile
def func(x):
n = int(x.sum().item()) # 转换为 Python int
for i in range(n):
x = x + i
return x
x = torch.randn(3, 3)
func(x) # 触发 Graph Break
原因:循环次数 n 在编译时未知,编译器无法展开循环。
3.4 在循环内部使用 break 或 continue
@torch.compile
def func(x):
for i in range(10):
if x[i].item() < 0:
break
x = x + i
return x
x = torch.randn(10)
func(x) # 触发 Graph Break
原因:break 条件依赖于张量的运行时值,编译器无法静态确定何时退出循环。
3.5 动态创建 Python 容器
@torch.compile
def func(x):
lst = []
for i in range(3):
lst.append(x + i)
return torch.stack(lst)
x = torch.randn(2, 2)
func(x) # 触发 Graph Break
原因:动态列表 lst 及其 append 操作是 Python 对象层面的操作,编译器无法追踪其内部状态变化。
4. ONNX 静态图的启示:控制流也可纳入静态图
ONNX(Open Neural Network Exchange)是一种静态图格式,其核心理念是:模型必须是一张完整的、无环的计算图。与传统认知不同,ONNX 并没有回避控制流,而是通过专门的算子将其显式结构化:
If 算子:接受一个布尔张量作为条件,并包含两个子图 then_branch 和 else_branch。运行时根据条件选择执行其中一个子图。Loop 算子:接受最大迭代次数(可以是动态张量)和初始条件,循环体子图内部更新状态并输出是否继续的布尔值。
这意味着,原本在 torch.compile 中因数据依赖控制流而产生的 Graph Break,在 ONNX 中可以被表达为静态图内的 If/Loop 节点。
示例对比:
# PyTorch 动态代码(触发 Graph Break)
if x.sum().item() > 0:
y = x + 1
else:
y = x - 1
# ONNX 静态图等价形式(无 Break)
cond = x.sum() > 0 # 产生布尔张量
y = If(cond, lambda: x+1, lambda: x-1) # 伪代码
决策信息始终保留在张量域内,无需逃逸到 Python 解释器。
下图展示了 ONNX If 算子的静态图结构:
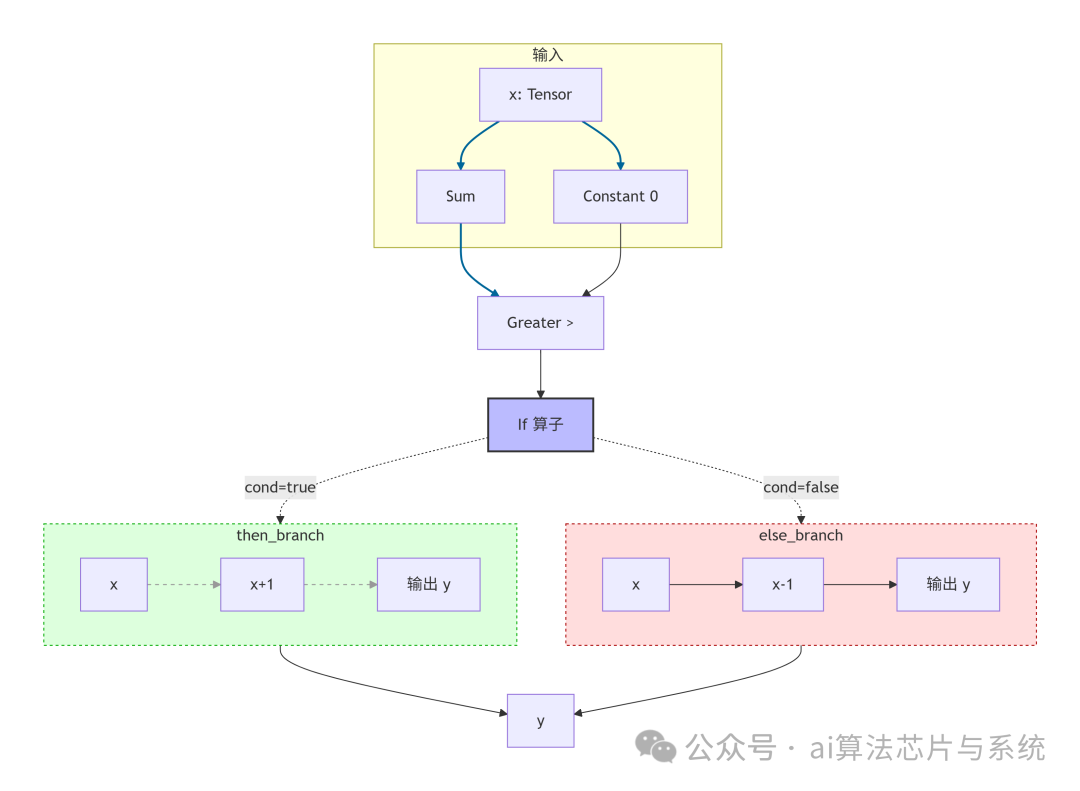
图中 If 节点用蓝色方框表示,两个分支子图分别用绿色(then)和红色(else)虚线框包围。
对 torch.compile 的借鉴意义:虽然 torch.compile 当前的中间表示尚未完全采用这种结构化的控制流算子,但 ONNX 的设计表明,数据依赖的控制流并不必然导致 Graph Break。通过引入类似 If/Loop 的 IR 节点,编译器可以在静态图中保留动态分支,从而减少断点数量,提升优化效果。事实上,PyTorch 的 torch.export 和 TorchScript 已经在一定程度上采用了这种思路。想了解更多关于人工智能模型优化的前沿思路,可以关注相关社区讨论。
此外,ONNX 还支持 Loop 算子,用于表达动态循环:
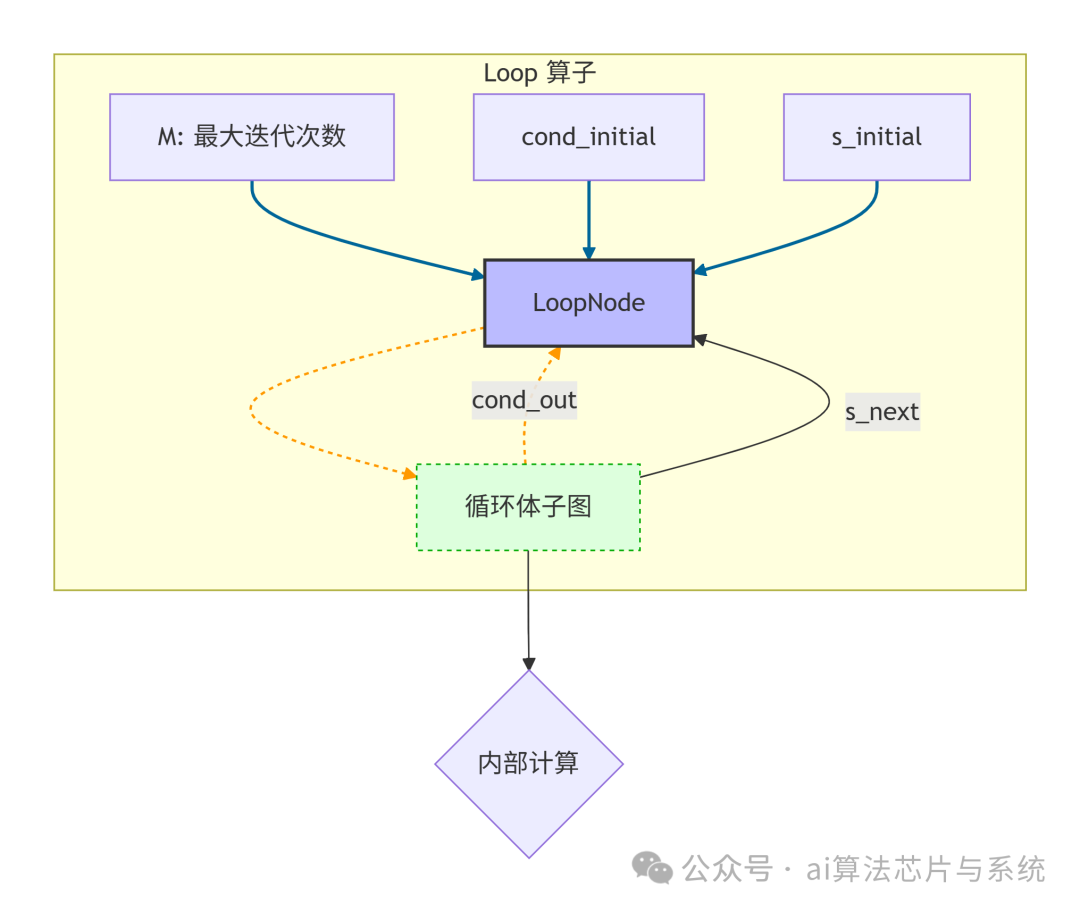
图中 Loop 节点同样用蓝色方框表示,循环体子图用绿色虚线框表示,橙色的反馈箭头表示状态回传以形成循环。
5. 静态图框架的局限性
尽管 ONNX 的结构化控制流能够避免由数据依赖分支引起的“图断裂”,但这并不意味着所有动态特性都能被静态化。以下情况仍然可能造成问题:
- 动态 Python 容器:如
list.append、dict 操作。ONNX 没有可变长度的容器类型,需要手动重构为张量操作(如 torch.stack)或使用固定长度的 Sequence 类型。
- 外部库调用:调用非 PyTorch 的 Python 库(例如 NumPy、SciPy)且无法被追踪或转换为 ONNX 算子。
- 复杂的内省或元编程:例如动态修改函数签名、使用
eval 或 exec。
- 某些高级张量操作:部分索引或形状操作在特定条件下可能无法被静态化。
因此,静态图框架主要解决的是“控制流依赖张量数值”这一特定类别的 Graph Break,而非所有动态特性。用户仍需遵循最佳实践:避免将 .item() 用于控制流决策,避免动态容器,将副作用操作移出图外。
6. 总结
torch.compile 的 Graph Break 主要源于数据依赖控制流、张量转 Python 对象和副作用操作三类原因。其中控制流打断编译的本质是:编译时无法预知张量数值,导致静态图无法确定分支或循环边界。- ONNX 静态图通过
If 和 Loop 算子显式建模数据依赖的控制流,从而在静态图内保留了动态分支能力。这一设计思路可以被 torch.compile 借鉴,以缓解由控制流引起的 Graph Break。
- 静态图并非万能,其他类型的 Break(如动态容器、外部库)仍需开发者手动处理。
理解这些动态特性的本质以及静态图框架的应对策略,有助于编写更适配 torch.compile 的代码,并在必要时借鉴 ONNX 的结构化控制流思想,进一步提升模型执行效率。对于更多计算机基础层面的编译优化知识,也值得深入探索。
 发表于 2026-4-8 06:40:52
|
查看: 216|
回复: 0
发表于 2026-4-8 06:40:52
|
查看: 216|
回复: 0
