你睡8小时,它跑完3轮实验;你出去度假,它探索了50+组超参;你在写论文,它已经把results table准备好了。
一个能24/7自主运行深度学习实验的AI代理框架,每天LLM成本不到6毛钱。
痛点:为什么我们还需要一个“自动炼丹”工具?
做深度学习研究的你,一定经历过这些:
- 白天盯着loss曲线,晚上守着GPU日志,生怕训练崩了
- 一个实验跑8小时,你要守着8小时才能决定下一组参数
- 超参搜索?手动改config,手动重启,手动记录,来回几十次
- 好不容易想出个好idea,却被“跑实验”这个体力活拖得精疲力尽
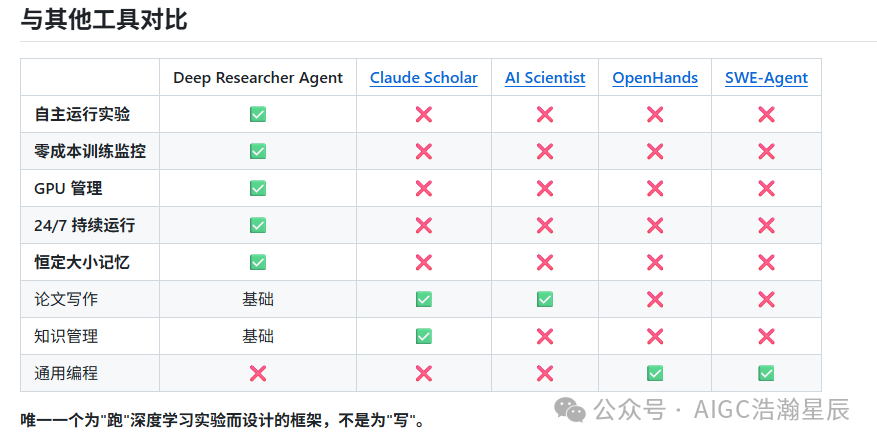
现有的AI工具,有的帮你写论文,有的帮你查文献,有的帮你整理笔记。但替你跑实验这件事,没人做。
Deep Researcher Agent(简称DAWN)就是为了填这个坑而生的。它不是一个聊天助手,而是一个能持续24/7自主运行的实验Agent——你睡觉,它炼丹。
实战验证:500+轮实验,52%提升,0.55元/天
这不是一个纸上谈兵的demo。项目作者已经在真实研究环境中验证了它的能力:
| 指标 |
数据 |
| 自主完成的实验循环 |
500+轮 |
| 单项目最佳指标提升 |
比基线提升52%(200+次自动实验后) |
| 同时管理的项目数 |
4个项目,4台GPU服务器 |
| 最长连续运行时间 |
30+天无需人工干预 |
| 24小时平均LLM成本 |
~¥0.55(你没看错,五毛五) |
核心创新:零成本监控,告别按token烧钱
很多人会问:让AI 24/7跑实验,那API费用不得爆炸?
DAWN的设计者早就想到了这个问题。它的秘密在于 THINK → EXECUTE → REFLECT 循环:
- THINK(5-10分钟):LLM分析现状、制定计划、写代码 → 花钱(约¥0.35)
- EXECUTE(数小时/天):训练真正在GPU上跑,Agent只做进程存活检查 + 读日志尾部 → 零LLM调用,不花钱
- REFLECT(5-10分钟):LLM解析日志、对比基线、更新记忆 → 花钱(约¥0.20)
训练8小时的一个完整周期,LLM成本合计约¥0.55,而不是¥350+。
这意味着你可以放心让它24/7跑下去,不用心疼账单。
架构设计:Leader‑Worker + 恒定大小记忆
Leader‑Worker架构
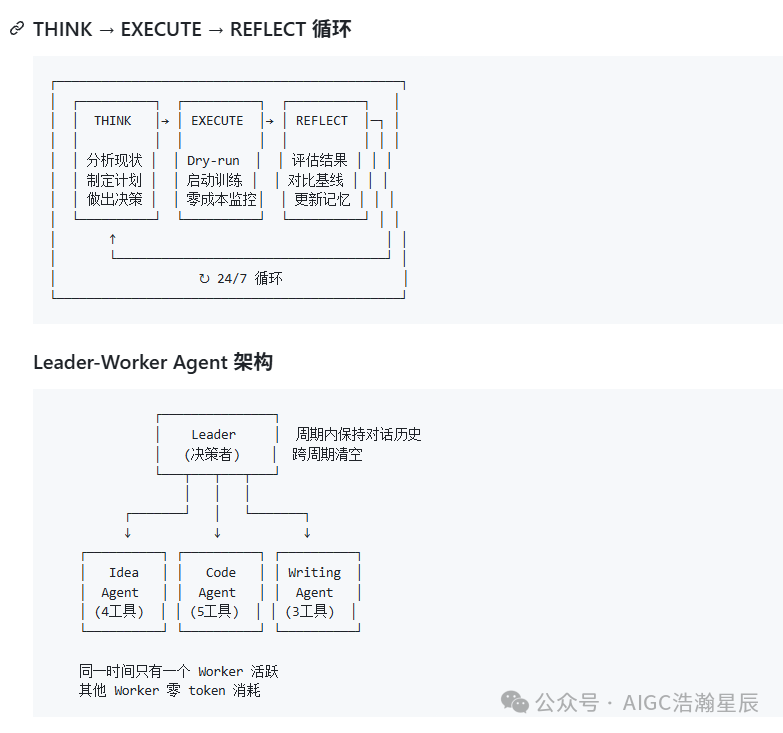
Leader负责任务调度和决策,Worker各司其职(想idea、写代码、写文档)。同一时刻只有一个Worker活跃,避免token浪费。
恒定大小记忆系统
Agent跑得再久,记忆也不会无限膨胀:
PROJECT_BRIEF.md:项目目标、约束、决策树(冻结,Agent不可改)MEMORY_LOG.md:关键成果 + 最近15条决策,自动压缩到~2000字符
无论运行多久,记忆大小恒定在~5000字符(约1500 tokens)。既不会遗忘重要信息,也不会被历史对话撑爆上下文。
快速上手:10分钟从零跑起来
0. 环境要求
- Python 3.10+
- Claude Code(或其他兼容CLI)
- NVIDIA GPU(至少一块)
- Anthropic API Key
1. 安装
# 克隆仓库
git clone https://github.com/Xiangyue-Zhang/auto-deep-researcher-24x7.git
cd auto-deep-researcher-24x7
# 安装依赖
pip install -r requirements.txt
# 安装 7 个 Claude Code 斜杠命令
python install.py
# 验证
python -m core.loop --check
2. 创建你的第一个项目
建一个文件夹,写一个PROJECT_BRIEF.md,告诉Agent你想做什么:
cat > PROJECT_BRIEF.md << 'EOF'
# 目标
在 CIFAR-100 上训练 ResNet-50,测试准确率 >80%。
# 代码
Agent 从零开始写 PyTorch 训练代码。
- 用 torchvision 加载数据集(自动下载)
- 模型存到 ./checkpoints/
- 日志写到 ./logs/
# 尝试方向
- 先试基础 ResNet-50,lr=0.1,SGD,100 epochs
- 如果准确率 <75%,加 cosine annealing + warmup
- 如果 75-80%,加 mixup 或 cutout 数据增强
- 如果 >80%,目标达成
# 约束
- 只用 GPU 0
- 每次最多 100 epochs
- Batch size 128
# 当前状态
还没跑过任何实验,从零开始。
EOF
写好Brief就像在指导一个聪明的实习生:目标要具体,决策树要清晰。
3. 启动
在Claude Code中输入:
/auto-experiment --project ~/my-first-experiment --gpu 0
Agent就会开始它的THINK → EXECUTE → REFLECT循环。你可以随时查看进度:
=== 第 1 轮 ===
[THINK] 读取 PROJECT_BRIEF.md...
目标:ResNet-50 CIFAR-100,>80%
没有历史实验,从 baseline 开始
计划:ResNet-50, lr=0.1, SGD + momentum, 100 epochs
[EXECUTE] 创建 train.py...
创建 config.yaml...
Dry-run (跑2步验证)... ✓ 没报错
启动训练:nohup python train.py --config config.yaml
PID: 12345,日志: logs/exp001.log
[MONITOR] 训练中...(零 LLM 成本)
15:00 — 进程活着,GPU 98%,Epoch 12/100,loss=2.34
15:15 — 进程活着,GPU 97%,Epoch 25/100,loss=1.87
...
18:00 — 进程结束,训练完成
[REFLECT] 解析日志... 测试准确率 = 76.3%
76.3% < 80% 目标
Brief 说 75-80% 应该加数据增强
决策:下一轮加 mixup (alpha=0.2) + cosine annealing
记录里程碑:"Exp001: ResNet-50 baseline, 76.3%"
=== 第 2 轮 ===
[THINK] 当前最佳:76.3%(Exp001)
计划:加 mixup + cosine annealing
...
4. 随时介入
想临时改变方向?写一个文件即可:
# 方式 1:放一个文件(Agent 下一轮自动读取)
echo "别试 ResNet 了,换 ViT-B/16,lr=1e-3" \
> ~/my-first-experiment/workspace/HUMAN_DIRECTIVE.md
# 方式 2:命令行
python -m core.loop --project ~/my-first-experiment \
--directive "加 label smoothing 0.1"
# 方式 3:直接改记忆文件
vim ~/my-first-experiment/workspace/MEMORY_LOG.md
Agent下一轮会以最高优先级读取你的指令。
哲学:学术应当保持纯粹,人始终在循环里
项目README里有一段很诚恳的话,值得每个使用者读一读:
我们的愿望很朴素:让学术保持纯粹,让人始终留在循环里。
Agent可以替你跑实验,但idea、结果的解读、科学判断请留给自己。
不要用这个项目去伪造结果,不要用它去“生成”完全没有人类参与的研究。
那不是我们想帮忙建造的未来,我们也相信,那同样不是大多数你们想要的未来。
这个框架不是为了替代研究者,而是为了把机械、重复的环节从你身上拿掉,让你把省下来的时间,留给真正重要的事:思考。
开源地址
GitHub:https://github.com/Xiangyue-Zhang/auto-deep-researcher-24x7
项目提供完整的中文文档、英文文档、日文、韩文文档,还有一份AI_GUIDE.md,可以直接丢给Claude / ChatGPT,AI会一步步带你装好、配好、跑起第一个实验。如果您对这类开源实战项目感兴趣,欢迎到云栈社区交流讨论。
最后
“实验通宵运行,结果黎明到来。”
如果你也曾因为盯训练、调参数、等结果而疲惫不堪,不妨试试把这个“体力活”交给Deep Researcher Agent。
你负责idea和思考,它负责跑腿和重复劳动。这才是AI该有的样子。
欢迎Star、Fork、试用。也欢迎在Issues里分享你的使用故事和需求。让我们一起,让学术回归纯粹。
 发表于 2026-4-11 07:01:48
|
查看: 187|
回复: 0
发表于 2026-4-11 07:01:48
|
查看: 187|
回复: 0
