手机芯片能否直接跑赢云端百G大模型?腾讯混元团队用半年时间给出了答案:通过极致的量化技术,他们在翻译任务上实现了这一突破。

腾讯混元团队刚发布了手机端翻译模型 Hy-MT1.5-1.8B-2bit。体积仅574MB,却敢叫板720亿参数的开源模型和主流商业翻译API。具体性能对比如下。
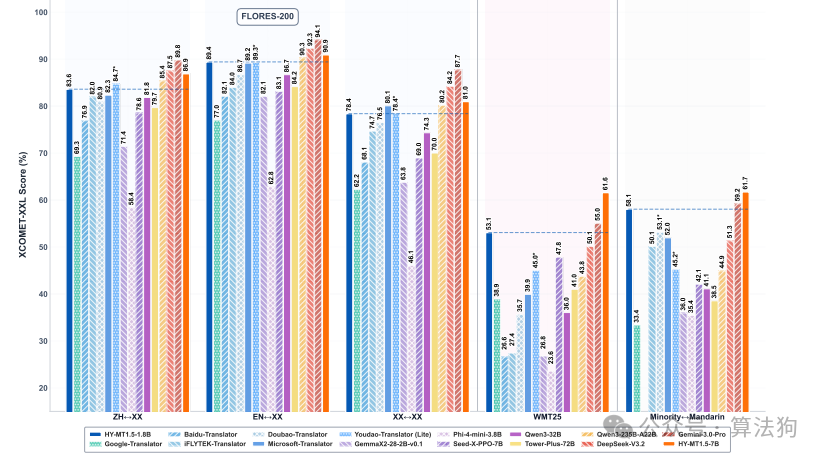
能打吗?确实能。团队指出,这款模型专为 Arm SME2 架构的手机芯片优化,完全离线运行,数据不上云。
1. 参数少,打得狠
模型基础版是 Hy-MT1.5-1.8B,参数规模仅18亿,但翻译质量全面比肩甚至超越参数远大于它的对手。团队列出的对比对象包括:
- Tower-Plus-72B(720亿参数)
- Qwen3-32B(320亿参数)
就连微软翻译和豆包翻译这类商业API,它也能扳一扳手腕。
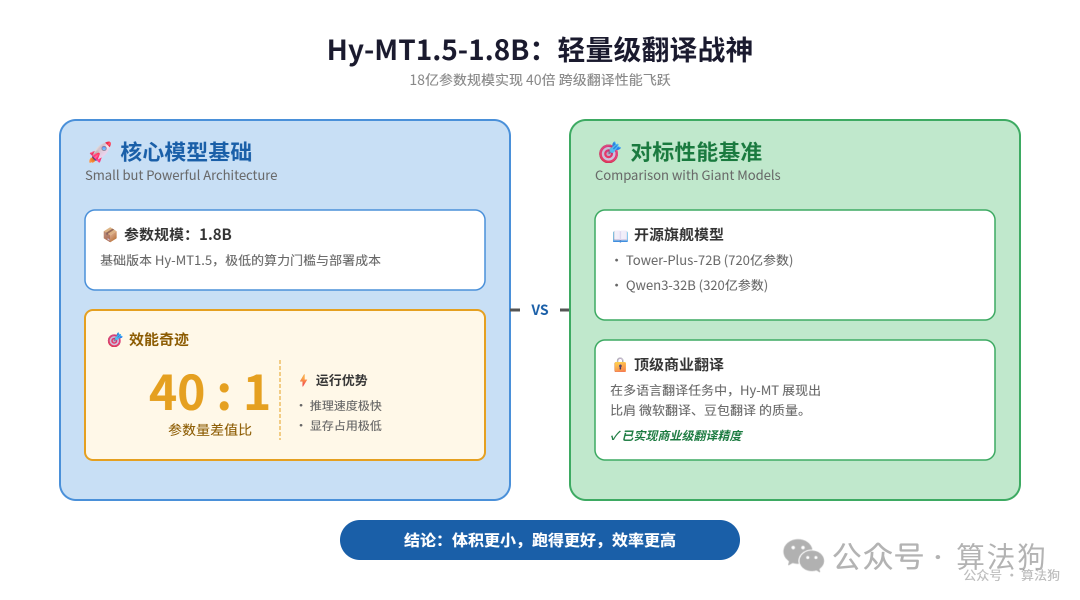
这个效果对比非常直观。一个1.8B模型,另一个是72B,参数相差40倍,但前者体积更小、跑得更好、更快,而且隐私性更强。
2. 说下压缩技术
这一切要归功于背后的压缩技术。模型原本的 FP16 版本体积为3.3GB,经过量化后被压缩到574MB,压缩比接近6倍。
核心技术叫 Stretched Elastic Quantization(SEQ),可译为“拉伸弹性量化”[1]。有兴趣的话可以看论文了解细节。原理很直接:将模型权重从无数个浮点精度,压缩到只允许取四个值:
-1.5、-0.5、0.5、1.5
配合量化感知蒸馏等技术,压缩后的模型翻译质量几乎无损。他们还提供了一个更极致的版本:1.25-bit 量化,体积仅 440MB。在 HuggingFace 等开源社区可以找到相关资源。
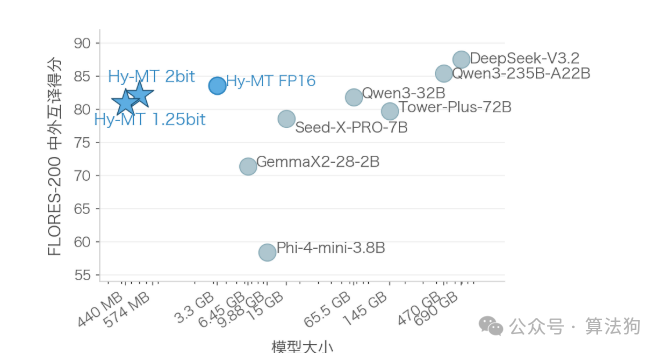
3. 跑在手机上,不联网
这款模型的目标场景十分明确:手机端离线部署,让用户在手机上直接使用翻译。它主要针对支持 Arm SME2 指令集的芯片,如 Apple M4 和 vivo X300 这类处理器。模型在手机本地运行翻译,不需要任何网络连接。
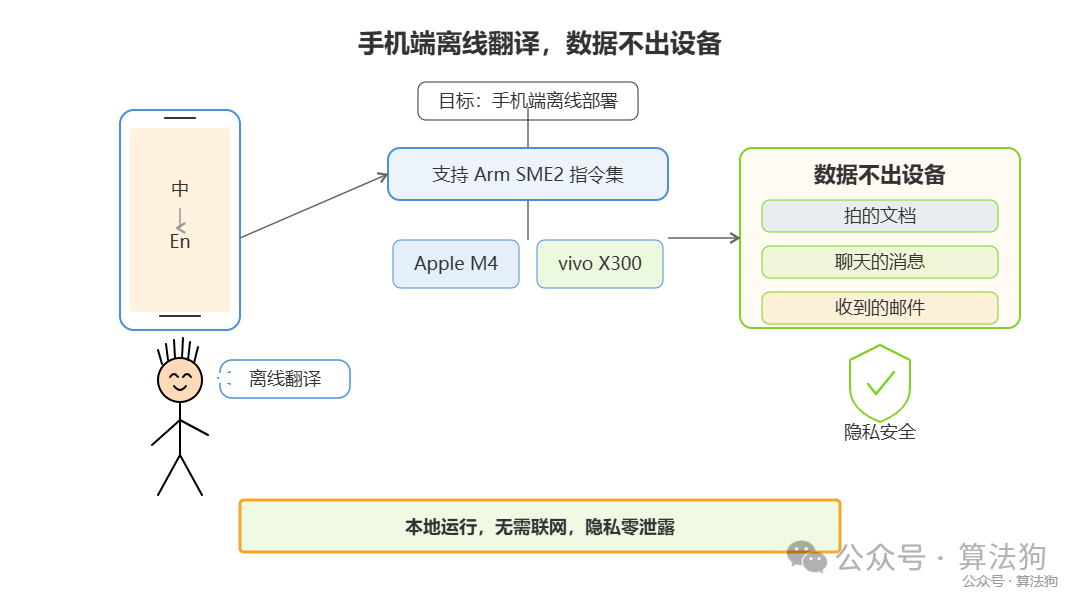
这意味着什么?你拍的文档、聊天的消息、收到的邮件等所有私有数据,全都不离开设备。对于注重隐私保护的用户来说,这是非常重要的保障。简单讲,就是拔掉网线,照样能跑,而且速度快。
4. 速度有多快?
原文放了一张速度对比图。
对比的对象是 SME2 内核和传统的 Neon 内核。结论是:在 SME2 架构下,2-bit 模型的推理速度快了一大截。快到什么程度?团队没有给出绝对数字,但明确指出 SME2 内核的速度显著优于 Neon 内核。对于实时翻译场景,这个差距至关重要。
5. 真正的杀手级功能
团队最后介绍了一个 Android 演示 APK。这个 App 有个模式叫“背景单词提取”:你在手机上刷邮件、看网页、聊微信,不用切换 App,它就能直接提取屏幕上的文字并给出翻译。整个过程全程离线,不收集数据,而且一次下载,永久使用。
演示设备用的是骁龙865(8GB 内存)和骁龙7+ Gen 2 (16GB 内存),都不是最新旗舰芯片,跑起来毫无压力。
6. 结尾
该文的核心结论是:大不是强,小才是趋势。574MB 的模型在翻译质量上干掉了 72B 的大模型,同时实现了真正的隐私安全和无网可用。手机端 AI 的拐点,可能比所有人预想的来得更快。感兴趣的读者可以下载官方演示 APK 亲自体验,链接已在原文中提供。
[1] https://arxiv.org/pdf/2602.21233
[2] https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit
[3] https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit-GGUF
[4] https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit
[5] https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit-GGUF
在端侧 人工智能 技术快速落地的今天,像 Hy-MT1.5 这样将 深度学习 模型高效部署于移动端的实践,正重新定义我们对“实时翻译”的想象。如果你对模型量化和端侧推理有更多见解,不妨来云栈社区一同探讨。
 发表于 2026-5-2 17:26:54
|
查看: 170|
回复: 0
发表于 2026-5-2 17:26:54
|
查看: 170|
回复: 0
