大语言模型火了好一阵子,可很多朋友对显存的理解还停留在“模型多大,显存就得有多大”的初级阶段。实际情况呢,说复杂也复杂,说简单也简单。
复杂在于,这里头牵扯到量化、KV缓存、框架开销等一系列技术细节;简单在于,只要你掌握了一个核心公式,心里就能有个八九不离十的谱。
核心公式:搞定90%的显存估算问题
你只需要记住下面这个最基础的公式:
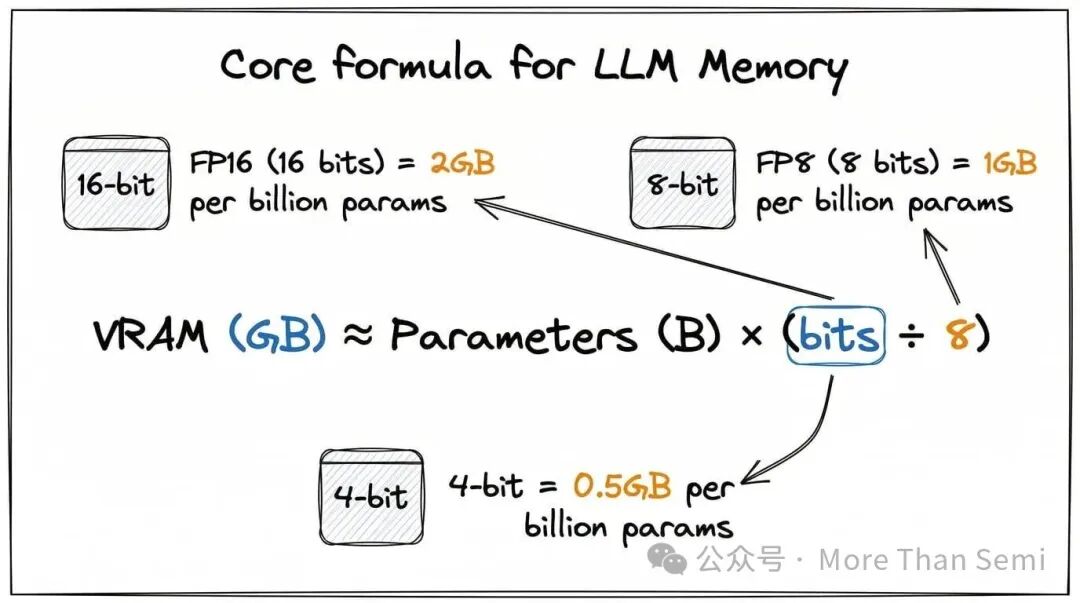
显存(GB)≈ 参数量(十亿)× (位数 ÷ 8)
简单解释一下:
- FP16或BF16精度:每个参数用16位(2字节)存储,一个10亿参数的模型大约需要2GB显存。
- FP8或INT8精度:每个参数用8位(1字节)存储,同样是10亿参数,就只需要1GB显存。
- 4-bit量化:每个参数用4位(0.5字节)存储,10亿参数仅需约0.5GB显存。
这个公式几乎适用于你遇到的所有主流格式,无论是FP16、BF16、FP8、INT8,还是GPTQ、AWQ、NF4,以及各种GGUF变体。关键在于搞清每个参数占多少位(bits),除以8得到字节数,再乘以总参数量,就是大致的模型权重显存占用了。
实战对比:从7B到405B,显存需求差多少?
理论讲完了,我们来看点实在的数字。
- 7B模型:FP16精度约需14GB,FP8需7GB,4-bit量化可压缩至3.5-4GB。这也是为什么许多玩家用RTX 4090(24GB显存)就能流畅运行Llama 2 7B。
- 70B模型:FP16直接飙到140GB,FP8也要70GB,即便是4-bit量化仍需35-40GB。这个量级单卡就很难驾驭了,通常需要多卡并行或采用更激进的量化策略。
- 405B巨无霸:FP16高达810GB,FP8为405GB,就算用4-bit也还要200多GB。这种规模的模型基本是云端算力的天下,个人硬件很难触及。
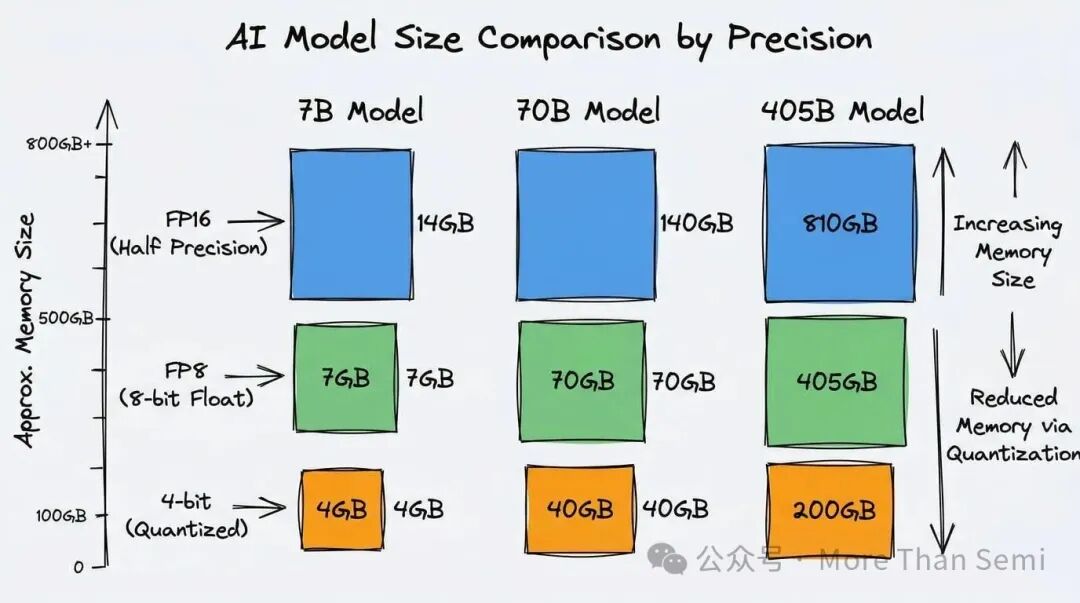
这张图清晰地展示了不同规模模型在各种精度下的显存需求。量化的威力显而易见——同一个模型,FP16和4-bit之间的显存占用可能相差4倍之多。
你的显卡能驾驭多大的模型?
最实际的问题来了:我手头的显卡到底能跑多大的模型?
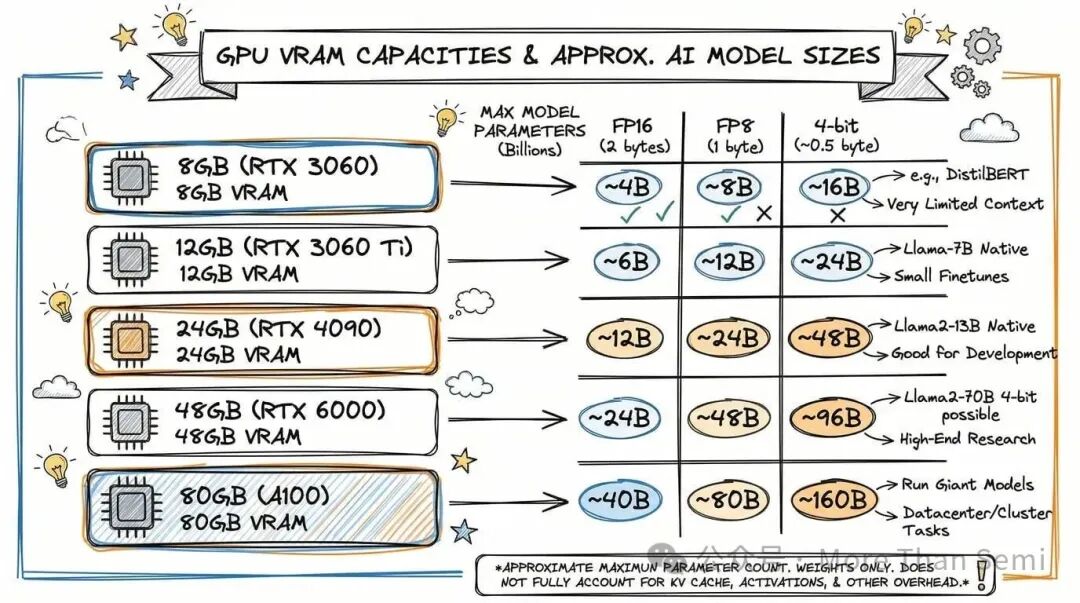
- 8GB显存 (如 RTX 3060):FP16下能跑约3-4B模型,FP8可达6-7B,4-bit量化则勉强能尝试12-13B的模型。
- 12GB显存 (如 RTX 3060 Ti):FP16下支持约5-6B,FP8约10-12B,4-bit可挑战18-20B的模型。
- 24GB显存 (RTX 4090):选择更多。FP16能跑10-12B,FP8约20-24B,4-bit量化则可以流畅运行35-40B级别的模型。这使它成为了本地AI部署爱好者的热门之选。
- 48GB显存 (如 RTX 6000 Ada):FP16能应对20-24B模型,FP8约40-48B,4-bit量化则能轻松驾驭70-80B的主流开源大模型。
- 80GB显存 (如 A100):FP16下可运行35-40B模型,FP8约70-80B,4-bit量化甚至能尝试140B级别的巨型模型。
模型权重只是冰山一角:小心那些“隐藏开销”
重点来了!前面讨论的所有数字,都仅仅只是模型权重的显存占用。模型实际运行时,会产生一系列额外的开销,稍不注意就可能引发OOM(内存溢出)。
- KV缓存:这是大头,其大小与上下文长度线性相关。短对话(如2K、4K)影响不大,但一旦处理32K、128K甚至更长的文本,KV缓存消耗的显存会急剧增加。
- 激活值:取决于具体的模型架构、框架和计算图优化程度,在某些计算路径下可能会突然飙升。
- 批处理与并发:如果需要同时处理多个请求(例如在Agent工作流中),显存占用会成倍增长。
- 框架开销:不同的推理框架,如 Transformers、vLLM、TensorRT-LLM、llama.cpp,其内存管理和调度策略不同,带来的额外开销也各异。
- CUDA Graphs等优化技术:为了换取更稳定的延迟和吞吐量,一些框架会预分配一部分显存。
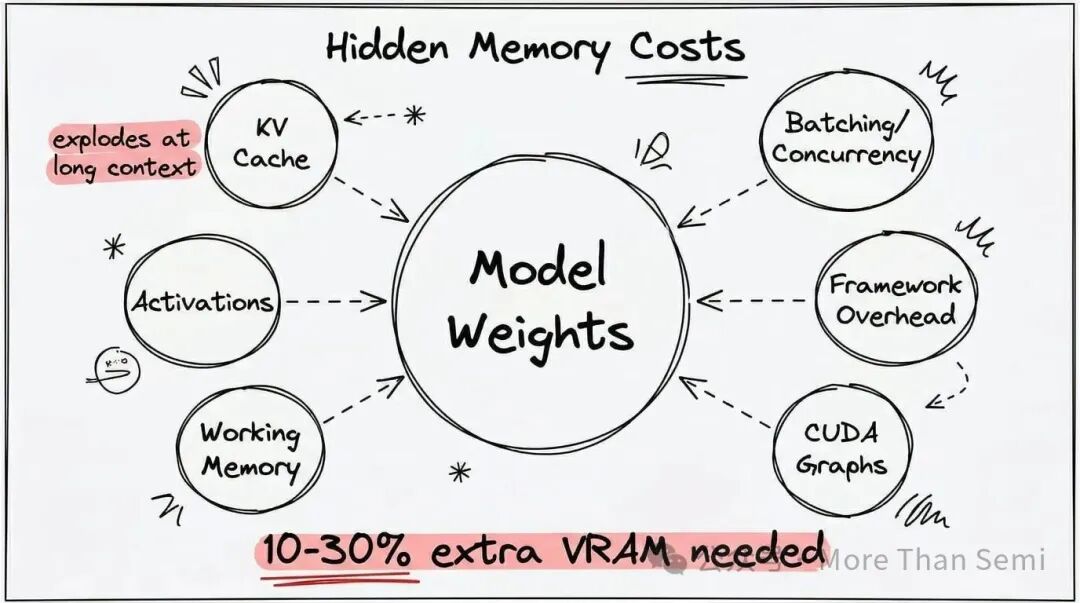
因此,一个实用的经验法则是:在模型权重估算值的基础上,至少预留10-30%的显存余量。如果你计划运行长上下文、高并发或复杂的任务链,则需要预留更多。这也就是为什么有时理论计算显存足够,实际运行时却报错的根本原因。
深入GGUF量化:如何选择“甜点”方案?
谈到降低显存占用,量化是关键手段,而GGUF格式(llama.cpp生态的核心)则是其中的“显存救星”。它提供了一系列量化选项,在压缩率和质量损失之间提供多种权衡。
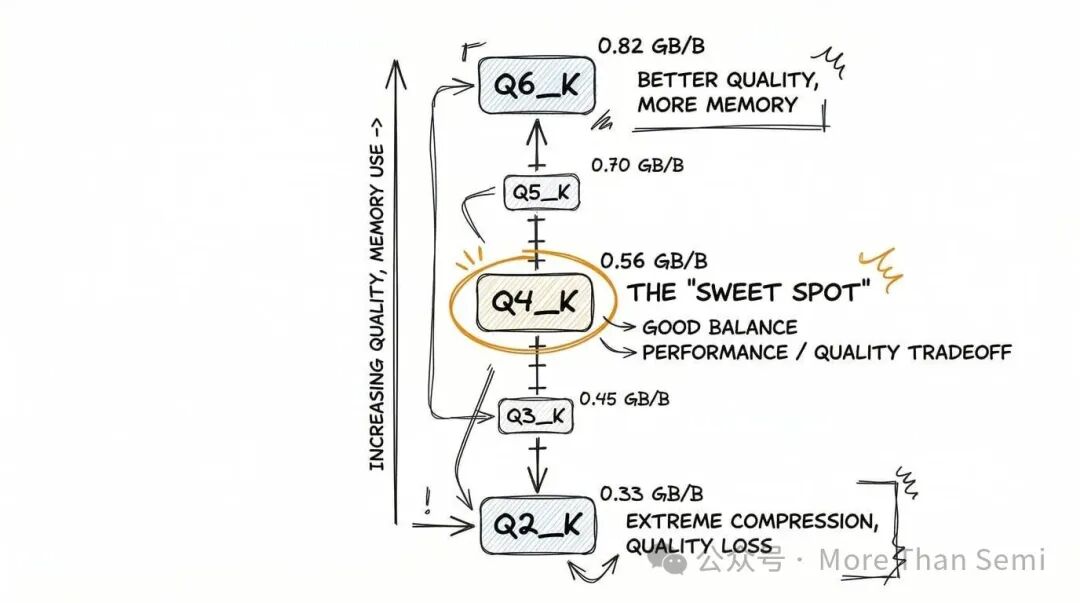
- Q6_K:最接近原始精度,每10亿参数约0.82GB,质量损失极微。
- Q5_K:约0.70GB/10亿参数。
- Q4_K:约0.56GB/10亿参数,被广泛认为是“甜点”方案,在质量和显存占用之间取得了良好平衡。
- Q3_K:约0.43GB/10亿参数。
- Q2_K:约0.33GB/10亿参数,压缩激进,质量损失较为明显。
一个重要提示:上述GGUF的显存数字,通常只在 llama.cpp 运行时成立。如果你将GGUF模型加载到其他框架(如Transformers),权重可能会被反量化回更高精度,导致显存占用大幅上升。所以,“这个GGUF模型只要6GB”是一个与运行时强相关的结论。
MoE模型的陷阱:别被总参数量误导
最后聊聊混合专家模型,比如Mixtral 8x7B。
很多人看到“8x7B”就以为是56B参数,并直接用56B去计算显存。这里有个关键区别:总参数量决定显存占用,而激活的参数量决定推理速度。
Mixtral 8x7B虽然有总计约56B的参数,但每次推理时只激活其中的一部分专家(通常2个),因此其推理速度接近一个7B的密集模型。然而,显存方面,你通常需要将全部专家的权重都加载进来(除非做了专家分片),因此其显存占用更接近56B的参数规模。这是评估MoE模型时需要特别注意的地方。
思维转变:从“能不能跑”到“怎么优化跑”
总结一下,我们的思路应该从简单地询问“我的显卡能不能跑这个模型”,转变为“基于我的硬件和目标,如何最优地运行这个模型”。
如果你有24GB显存想跑70B模型,4-bit量化几乎是必选项。如果追求更高精度,则需要考虑多卡或云端解决方案。如果只是进行简单的对话交互,一个7B模型的FP16版本或许就已足够。
这本质上是一个在精度、速度、显存占用和输出质量之间寻找最佳平衡点的过程。没有放之四海而皆准的“完美方案”,只有最适合你具体场景和需求的“最优解”。
当你真正理解了显存计算的核心公式及其背后的逻辑,你就不再是硬件的被动适应者,而能够主动地规划和设计你的本地大模型部署方案。这种掌控感,或许才是技术探索中最有意思的部分。
希望这篇指南能帮助你在云栈社区和更多的实践场景中,更从容地应对大模型部署的挑战。
 发表于 2026-4-5 03:19:35
|
查看: 152|
回复: 0
发表于 2026-4-5 03:19:35
|
查看: 152|
回复: 0
