
最近,博通发布了 Q2 新财报。一向沉稳的 CEO 陈福阳当天却有点不在状态——发言稿一开始竟然读成了 2025 年第二季度的内容。
同场财报会议上,陈福阳进一步坦承:「考虑到 AI 算力 消耗的速度,像谷歌这样的客户拥有多元化供应来源,是完全可以预见的。」这是博通首次在公开场合明确证实,谷歌正在积极推行供应商多元化的策略。
话一落地,博通股价当天暴跌 15%,市值一夕之间缩水 2800 亿美元。
博通被抢单了?ASIC 市场真要变天了?
01 博通:甜蜜时光结束了
早在 2006 年,谷歌就开始考虑为人工智能构建专用芯片 (ASIC) 的可能性。但直到 2013 年,公司才猛然意识到,未来 AI 计算所需的算力可能远超现有基础设施的上限。
当时,谷歌正在规划全球语音识别服务。首席科学家杰夫·迪恩粗略一算:如果数亿用户每天只用 3 分钟语音识别,所需的算力将是谷歌全部数据中心总算力的两倍。
评估了各种现有方案后,团队意识到,连当时的基础机器学习需求都难以满足,更别提支撑未来增长了。于是,2013 年谷歌创始人谢尔盖·布林在内部启动了一个秘密项目。
这个项目后来有了一个公开的名字——TPU。
谷歌有算法设计能力,但没有芯片量产经验。它需要一个懂芯片设计、又能协调台积电流片的合作伙伴。博通由此进入了谷歌的视野。2016 年,第一代 TPU 正式发布。尽管 TPU v1 在部分应用中的利用率并不高,但其平均速度比同时代的英特尔 Haswell CPU 和英伟达 K80 GPU 快了 15 至 30 倍,能效比更是高出 30 至 80 倍。
随后,TPU v1 被广泛用于搜索排序、地图街景、智能回复等谷歌核心业务。2016 年的谷歌开发者大会上,谷歌首次对外介绍 TPU,并透露 AlphaGo 在对弈李世石时,也借助了 TPU 来加速思考。
这一阶段,博通与谷歌的合作模式日渐清晰:谷歌负责 TPU 的架构设计与算法优化,博通则把设计转化为可量产的物理布局,并提供从芯片到网络的一整套解决方案。博通还利用其在台积电等代工厂的关系,帮谷歌锁定先进的制造产能。
这场合作让双方都赚得盆满钵满。摩根大通报告显示,从 TPU v1 开始,谷歌就与博通深度绑定,共同设计了所有已经公开的 TPU 型号。而博通从这笔生意中获得的收入,从 2015 年的 5000 万美元,涨到了 2020 年的 7.5 亿美元,五年翻了 15 倍。
随着 AI 浪潮袭来,博通的相关收入也从 2022 年的不到 50 亿美元,暴涨至 2024 年的 122 亿美元,同比增长 220%。这当中,TPU 贡献了最大的一块。
博通的股价也跟着一路飞升。2024 年 12 月,博通市值突破万亿美元,成为全球第 12 家万亿美元俱乐部成员。第二天又大涨 24%,单日市值增加 2000 亿美元。陈福阳在那次财报会上的一句话让分析师集体兴奋:「到 2027 年,大客户将在 AI 芯片上花费 600 亿到 900 亿美元。」
彼时,博通手握多个定制 XPU 客户:谷歌 TPU、Meta MTIA、Anthropic、OpenAI,以及两家尚未公开的客户。2026 年 Q2 单季度 AI 芯片收入已达 108 亿美元,同比增长 143%,并与谷歌签订了延续至 2031 年的长期协议,继续为其供应 TPU 和网络组件。
原本在 ASIC 赛道上顺风顺水的博通,突然迎来了新的挑战。
02 联发科 ASIC,效果初显
在今年的 Google Cloud Next 大会上,谷歌发布了两款最新 AI ASIC 服务器芯片:TPU v8t(训练用,代号 Sunfish)和 TPU v8i(推理用,代号 Zebrafish)。其中,面向训练的 TPU v8t 由博通设计,而面向推理的 TPU v8i,则由联发科设计。
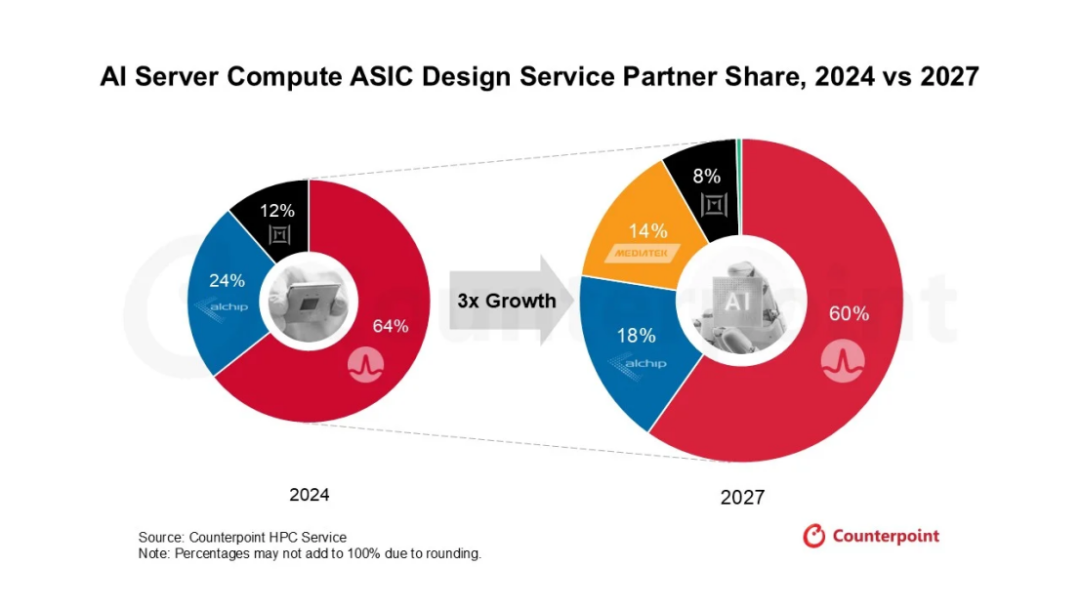
如果博通是 ASIC 市场的老牌玩家,那联发科绝对是这条赛道上增速最快的新人。Counterpoint Research 预测,到 2028 年,联发科可望占据全球 AI 服务器运算 ASIC 出货量约 26% 的份额。
此前,大家对联发科的印象还停留在手机芯片巨头,但它切入 ASIC 市场的关键并非什么 Transformer 优化,而是一项听起来很老派的技术——SerDes。
SerDes 是 AI 芯片中负责芯片间高速数据传输的核心 IP,直接决定芯片互联带宽的上限。在 AI 训练场景,芯片间的通信效率几乎直接影响整个集群的扩展能力。
联发科在 SerDes 领域的积累远比外界想象的深。这家公司在手机基带芯片上多年深耕,对高速信号传输有一种近乎偏执的追求。224G SerDes 是全球最先进的高速接口标准之一,联发科是国内极少数掌握该技术的企业。
TPU v8i 是联发科与谷歌合作的第一款 AI 推理芯片,代号 Zebrafish(斑马鱼),定位高性价比推理场景。合作分工上,谷歌自研主处理芯片(核心计算 Die),联发科负责 I/O Die,封装设计双方共同完成。
业内人士解释,在博通的交钥匙方案里,博通不光做芯片设计,还包揽了 HBM 内存采购、供应链协调、后段封装整合等全流程。这种一站式服务确实省心,代价是博通会在 HBM 采购上加收 15%~20% 的溢价。
Counterpoint Research 副总监 Brady Wang 分析指出,随着 HBM 在 AI 芯片总成本中的占比不断攀升,这部分溢价在大规模部署时会显著推高成本。尤其在谷歌加速 TPU 部署的态势下,采购量越大,被薅的羊毛就越多。于是,谷歌新策略浮出水面:自己掌控 HBM 采购和计算核心设计,将 I/O 模块与制造协调外包给联发科。
联发科对 AI ASIC 市场的前景非常乐观。目前,它不但拿到了谷歌 TPU v8 的合同,还顺势斩获了下一代 TPU v9 的订单,并将继续与博通共享项目。首席执行官蔡力行表示,基于现有产能,展望至 2027 年,这些项目将扩展到数十亿美元规模,他对此充满信心。
还有个有意思的细节。股东会上,有人直接问联发科创始人蔡明介:像 Google 这样的客户会不会把芯片设计能力全部内部化,直接找台积电合作,最终甩开联发科?蔡明介的回答直白得可爱:「大型云端企业希望掌握更多技术能力,直接与晶圆代工厂合作,某种程度上是很自然的趋势。」但他接着点出了根本:一颗先进的 AI 芯片,从设计到量产,牵涉的不止电路设计,还包括系统架构、供应链协调、先进制程导入、封装整合及量产品质管理等,这堆事情短时间内可不是谁都能取代的。
03 Marvell:不当 ASIC 公司了
ASIC 赛道眼下正出现明显的分化。
Marvell 的 ASIC 业务数据很好看:2020 年起步,2024 下半年开始有量产收入。在 2027 财年第一季度(截至 2026 年 5 月初),Marvell 总营收创纪录达到 24.18 亿美元,同比增长 28%。Marvell 还大幅上调了业绩展望,预计今年成长超 20%,明年更将倍增,到 2029 财年 ASIC 累计营收可望突破 100 亿美元。
但总裁暨营运长库普曼斯却主动撕掉了「ASIC 公司」这个标签。
他最近明确表示:「我们不把自己看成一家 ASIC 公司,我们把自己定位在高速 I/O 业务。客户来找我们,不是因为我们比他们更会造处理器。大型云端企业完全可以自己设计符合特定负载的处理器核心,他们真正需要的是高速、高可靠度、长距离的 I/O,而且要能在先进节点上尽快拿到手。这块,才是 Marvell 的专业所在。」
Marvell 真正押注的是互连技术。在它的定位里,ASIC 不过是承载高速 I/O IP 的一种形态,远不是公司身份的核心。
这个选择背后,是对行业趋势的清晰判断:进入 AI 推理阶段后,基础设施不再等于单纯堆算力,而是「存储 + XPU + 连接」的组合。当芯片数量从几千张扩张到上万张,芯片之间的连接效率就成了真正的瓶颈。Marvell 的 PAM4 DSP 在可插拔光模块中占据领先身位,同时还在铜缆、LPO/OBO、CPO 和全光互连等新技术上全面布局。
从实际业绩看,互连产品确实贡献了最主要的增量。当季互连产品收入约 9 亿美元,占到数据中心收入的一半左右。更关键的是,公司将 2027 财年互连业务增长预期从 50% 以上上调至超 70%,并预计 2028 财年继续快跑。
为了构建完整的互连能力,Marvell 近年接连出手:收购了 XConn(PCIe/CXL 交换)、Celestial AI(光子互连)、Polariton(硅光子)。加上更早的 Cavium、Innovium 等,Marvell 搭建起了覆盖三大 AI 网络层的能力:Scale‑Out(跨服务器扩展)、Scale‑up(服务器内部扩展)、Scale‑Across(跨数据中心扩展)。
在内存层面,Marvell 的产品线也分为三类:Structera A(近存储加速器)、Structera X(内存扩展控制器)、Structera S(内存池化与交换)。透过这些,Marvell 正在从「卖芯片」转向「卖解决方案」。客户要的不再是单独的 SerDes 或交换芯片,而是一套能让上万块 GPU 高效连接成一片的基础设施。
值得一提的是,黄仁勋最近与 Marvell CEO Matthew Murphy 同台时,称 Marvell 可能成为「下一家万亿美元公司」,随后 Marvell 股价一度飙升 32.52%。黄仁勋看重的,并非简单为 Marvell 站台,而是点出了 AI 集群的新瓶颈。他在 Computex 期间说,当计算问题被拆分并分布到整个数据中心后,连接就成了必要条件。
Marvell 的主动转身,也有非常现实的考量。尽管当前业绩指引包含了微软的下一代 Maia 芯片、CXL 和 NIC 等多款 XPU 产品,但供应链调查显示 Alchip 即将加入 AWS 供应链,这意味着 Marvell 在 AWS Trainium 未来发展路线方面可能面临日益激烈的竞争。预计到 2027 年,随着竞争升温,Marvell 在该领域的市场份额或将下滑至 8%。
当云服务商的自研能力越来越强,替他们设计处理器这门生意的利润空间正在收窄。但帮他们解决「连接」问题的需求却在井喷式爆发——AI 集群的规模越大,互联的瓶颈就越刺眼。
04 结语
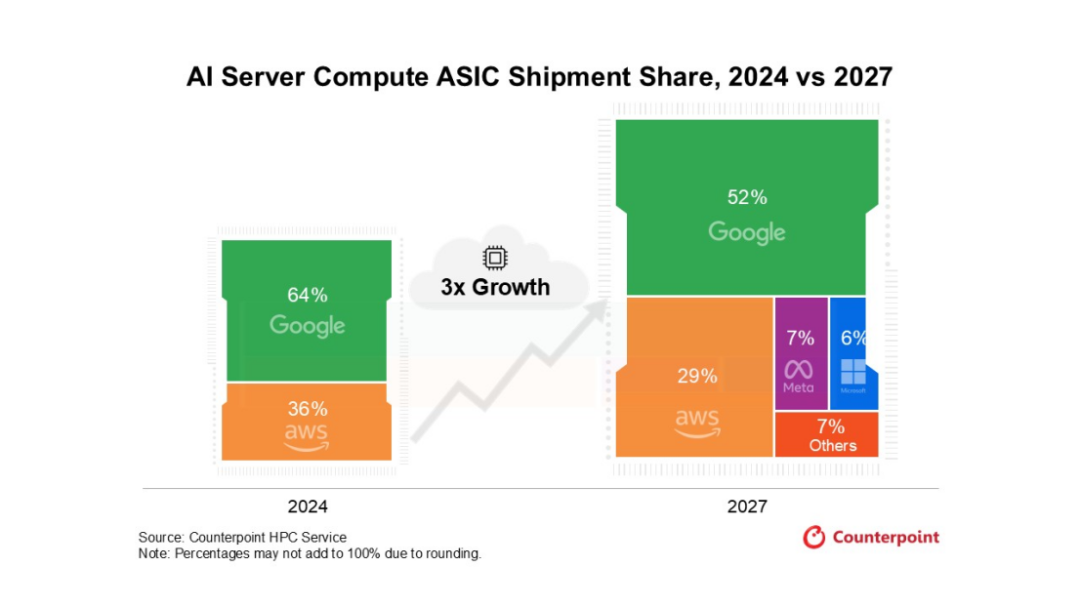
预计到 2027 年,全球服务器专用 AI 计算 ASIC 出货量将比 2024 年增长三倍。这一爆炸性增长的背后,是谷歌 TPU 基础设施的强劲需求、AWS Trainium 集群的持续扩展,以及 Meta (MTIA) 和微软 (Maia) 内部芯片产品组合扩大带来的产能提升。
随着市场的扩张,巨头们正在走向分化。一方面,客户开始自研芯片。谷歌并不只是引入联发科,它同时在推进供应商多元化与内部设计能力提升。毕竟,当客户变得足够庞大又有钱,自然会想把更多能力收归己有。另一方面,芯片设计公司开始分层。 博通偏重网络加 ASIC,Marvell 直说自己是高速 I/O 公司,联发科从手机杀进 ASIC 市场,三家公司之间的定位差异越来越鲜明。市场开始重新审视 ASIC 阵营的内部分工:有人专注计算核心,有人卡位 I/O 模块,有人做系统集成,大家各自在产业链上占据不同的生态位。
ASIC 市场正在从一家独大走向多元竞争,只有提供不可替代的价值,才能笑到最后。更多关于 AI 算力与云计算的前沿讨论,欢迎访问云栈社区。
 发表于 2026-6-12 00:02:27
|
查看: 136|
回复: 0
发表于 2026-6-12 00:02:27
|
查看: 136|
回复: 0
