大模型已经能流畅对话、看图识物,但一个更底层的问题始终没被真正解决——它们是否「理解」了我们所处的三维世界?
距离有多远、谁更大、从A走到B该往哪转、多视角下的顺序对不对——这些对人类近乎本能的判断,恰恰是通向具身智能、自动驾驶、机器人导航与AR/VR的关键能力。
业界正逐渐达成共识:下一阶段的竞争,不只在语言与语义,更在空间智能。
为把这件事真正做出来,华为GTS AI算法部联合香港中文大学(深圳)、香港大学,刚刚发布最新工作SpaceMind:
在仅使用RGB输入、不依赖深度图与点云的前提下,把纯视觉语言模型的空间推理能力,推到了接近人类的水平。
在李飞飞团队建立的空间智能权威榜单VSI-Bench上,SpaceMind以70.6%的综合得分刷新纪录——而人类平均也才79%左右。
该工作已被CVPR 2026接收。

为什么「相机」不能只当备注
论文明确指出:现有VLM在处理空间任务时,往往把相机参数(内参、外参)视为普通元数据,与几何特征简单拼接,导致「视角」与「场景」混淆,难以建立一致的空间表征——模型「看见了」,却未必知道「从哪里看见」。
人类理解空间,从来不只是「看到了什么」,而是「从哪个位置看到的」。这种观察与视角的耦合,支撑人们估计距离、比较尺寸、推断连通关系、在陌生环境中规划路径。李飞飞教授所倡导的「空间智能驱动的AGI」,正建立在这一认知之上。
SpaceMind的核心洞察,正是把这一机制写进模型结构:让相机成为融合的「指挥棒」,而不是被动附录。
而要衡量模型是否具备这种能力,离不开权威、全面、贴近人类认知的评测体系。李飞飞建立的VSI-Bench迅速成为公认的空间智能试金石:人类平均准确率约79%,而此前的公开与闭源系统中,最强模型整体准确率长期徘徊在60%左右,与「真正看懂三维世界」仍有明显距离。
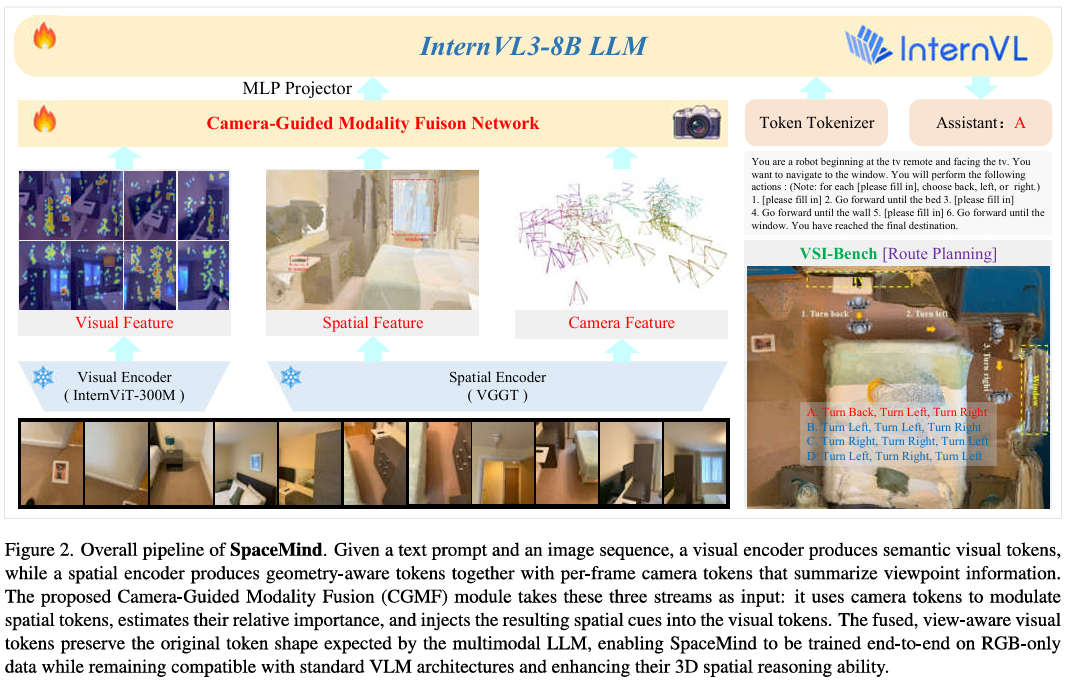
SpaceMind:相机引导的三模态融合范式
1、首次把相机表示定义为「引导模态」
不再把相机当作与场景同级的普通特征,而是作为主动调控信号,指导空间信息如何注入视觉语义流,更贴近人类以自我为中心的空间认知。
2、即插即用、不改动VLM主干
方案无需修改视觉编码器、语言模型或连接器的核心结构,仅在进入LLM前插入轻量的Camera-Guided Modality Fusion(CGMF)模块,可无缝集成到InternVL、Qwen-VL等主流架构,显著降低从零预训练与迁移成本。
3、纯RGB实现度量级空间推理
单张或短视频即可支撑绝对/相对距离、物体尺寸、房间尺度、路径规划、跨视角外观顺序等高难任务,摆脱对深度传感器、点云或多视角重建管线的依赖,更贴近真实部署场景。
架构上,SpaceMind采用双编码器架构:InternViT提供语义视觉token,VGGT提供几何感知的空间token与逐帧相机token;CGMF在融合阶段对空间token施加相机条件偏置、学习query-independent的几何重要性权重,并以相机嵌入对融合结果进行门控,使「视角—几何—语义」在统一框架内对齐,同时保持与标准VLM接口兼容,支持端到端RGB-only训练。
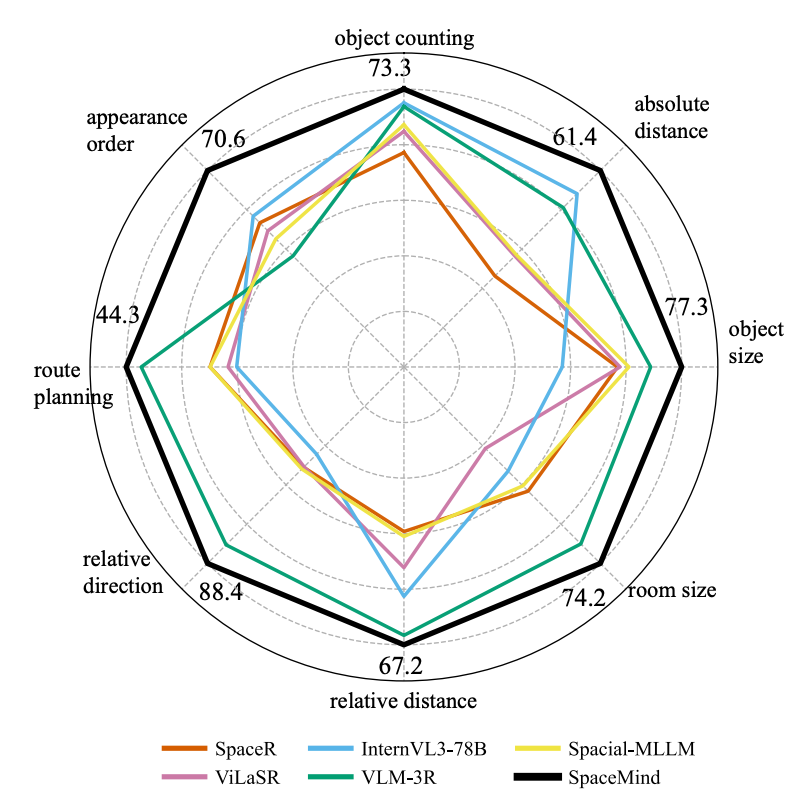
实验结果:全面刷新,优势不只在一个分数
在VSI-Bench上,SpaceMind以70.6%的整体准确率显著超越Spatial-MLLM、VLM-3R等几何增强基线,并在多项子任务上拉开差距。
例如在外观顺序这一极具挑战的跨视角一致性任务上,相较此前方法提升达30.5个百分点——说明显式以相机信号调制空间token,有助于整合跨视角证据、稳定多视角下的排序判断;路径规划同样保持极具竞争力的水平。
在SQA3D这一基于真实室内重建的「情境化3D问答」基准上,SpaceMind在多数问题类型上取得最佳表现,且仅使用视频RGB输入、不依赖深度/点云/网格等辅助模态,证明相机引导融合可从普通视频中恢复出强3D空间线索。
在SPBench的域外泛化评测中(训练数据未包含该基准),SpaceMind整体得分达67.3%,大幅领先GPT-4o、Gemini-2.0-Flash等通用闭源模型,以及Qwen2.5-VL、Spatial-MLLM等开源与专用空间模型;即便在仅单帧输入的子集上,仍能在「仅按32帧视频片段训练」的设置下展现强跨场景迁移——这对实际产品中的「单图问答」尤为重要。
消融实验进一步印证设计逻辑:在InternVL3-8B基线上,浅层cross-attention融合VGGT空间token即可带来+3.7分;叠加token-weight MLP与geometric MLP后,数值类与多选题子任务持续、稳定提升,完整SpaceMind架构达到最高平均准确率。
这不是「堆模块」,而是把3D视觉中长期强调的「相机与场景角色分离」,落实为可训练、可扩展的归纳偏置。
SpaceMind++:从单帧空间到视频级「认知地图」
面向动态真实世界,团队进一步受哺乳动物双通路视觉系统启发,提出SpaceMind++:一种能从RGB视频显式构建体素化认知地图的视频MLLM架构。
它通过坐标引导的深度融合机制,将碎片化视角重组为统一的3D度量表征,在动态场景中追求空间一致性与物体恒常性推理——让模型不只「答对一帧」,而是「记住这个房间、这件东西、这条路径」。
代码即将开源。
昇腾384卡节点Scaling Up:把空间智能推向更大规模
如果说论文与基准评测证明了SpaceMind方向正确、有效,那么工程侧的Scaling Up,正在把这一方向推向产业可用的量级。
目前,团队将SpaceMind系列空间智能模型放在华为昇腾NPU集群上开展大规模预训练与后训练——依托384卡昇腾910C算力池,在模型规模、长视频上下文与多任务数据上同步扩展,把相机引导融合能力从榜单验证推向可迭代、可部署的工程底座,持续放大SpaceMind的空间推理上限。
走向产业:赋能AIDC勘测设计
空间智能的价值,最终要落在真实场景里。SpaceMind系列技术将面向AIDC全生命周期中的勘测设计等关键阶段落地:
依托纯RGB输入下的距离估计、尺度比较与空间关系推理能力,模型可辅助解读园区航拍、现场巡检视频与机房实景图像,理解建筑布局、设备摆放与通道关系,为选址比选、平面规划、机柜列阵与走线设计提供可解释的空间判断依据。
在SpaceMind++的视频级认知地图能力加持下,还可将多视角、多时段的现场记录整合为一致的三维空间理解,减少反复踏勘与人工量测成本,提升勘测设计阶段的效率与决策质量。
云栈社区将持续跟踪空间智能领域最新进展。
 发表于 2026-6-14 01:34:57
|
查看: 176|
回复: 0
发表于 2026-6-14 01:34:57
|
查看: 176|
回复: 0
