本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL——一套完全开源的长上下文强化学习后训练方案,包含 23K 样本的 RLVR 数据集、完整训练代码,以及针对异构多任务的新算法 TMN‑Reweight。

论文链接:https://huggingface.co/papers/2605.19577
GitHub:https://github.com/xiaoxuanNLP/GoLongRL
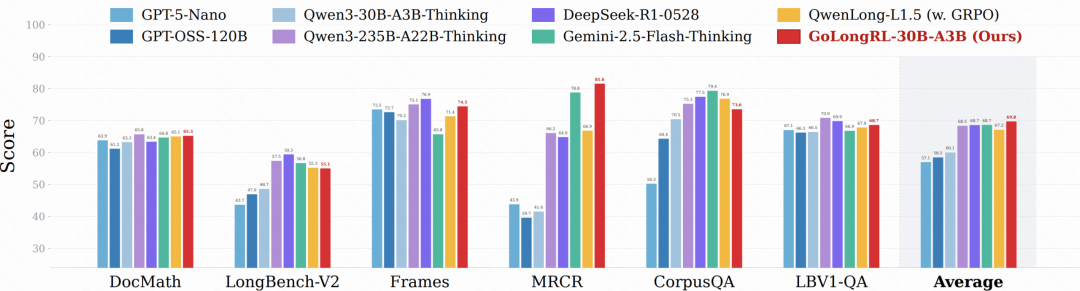
图 1:GoLongRL‑30B‑A3B 与各顶级模型的长上下文综合评测对比
为什么现有的长上下文 RL 方法不够好?
当前主流的长上下文 RL 方法(如 LoongRL、LongRLVR、QwenLong‑L1.5 等)普遍存在两个局限:训练数据基本围绕“在更长文本里找更难找的答案”这一单一路径,任务覆盖高度同质;奖励设计被压缩为单一的精确匹配或准确率,排序、摘要、穷举检索等能力几乎没有得到直接监督。
数据:以能力为导向
GoLongRL 的数据构造遵循三大原则:能力导向、奖励与任务语义对齐、真实文档优先。
能力导向。参考 LongBench Pro 提出的能力分类体系,定义了 9 种核心任务类型,覆盖长上下文理解所需的关键能力维度。其中,T1–T4 构成训练主干(占比超过 90%),覆盖基础长上下文能力;T6–T9 的样本量相对较少(合计不足 4%),但每种任务都保留了其最自然的奖励形式,确保完整的能力覆盖。
这 9 大任务类型及其对应的能力维度如下:
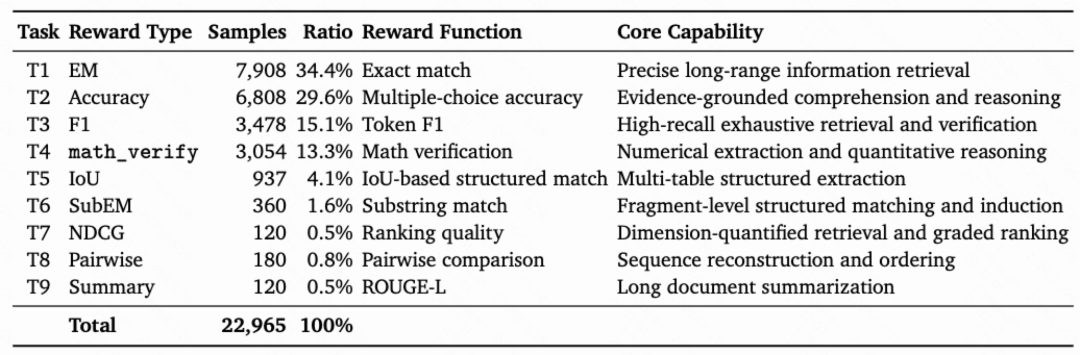
表 1:GoLongRL 数据集能力类型及其对应奖励
奖励与任务语义对齐。长上下文任务在评估维度上差异显著:摘要依赖 ROUGE,排序依赖 NDCG,抽取依赖 F1,若统一压缩为单一指标,将损失大量任务特有的语义信息。GoLongRL 为每类任务单独配置最契合其目标的评估指标作为奖励函数,使强化学习训练中的反馈信号与任务本身的评估逻辑保持一致。
真实文档优先。基于模板的合成数据存在结构性风险:当多段短文档被拼接为长输入时,段落边界与格式标记本身就携带了可被利用的位置信息,模型容易习得依赖这类浅层线索作答的捷径,而非形成真正的跨段落理解能力。因此,GoLongRL 以书籍、学术论文、法律文书和财务报告等真实文档为主要训练来源。对于标注稀缺的领域,仅在真实文档上合成问答对,而非生成文档本身。
图 2:训练数据的 UMAP 投影
数据来源:开源策略与合成策略并行
数据集的 22,965 个样本来自两个互补的池子:
- 约 14K 开源样本:从 CLongEval、LongBench Pro、MultiTableQA、CAIL2018 等已开源的长上下文语料库中改写。这些样本已有人工验证的标注,覆盖法律案例、财务报告、文学小说和多轮对话等多个领域。
- 约 9K 合成样本:问答对由真实源文档生成,源文档包括 Project Gutenberg 图书、arXiv CC0 等自然长文素材。需要强调的是,合成对象是问答对本身,而非文档。
四阶段构造 pipeline
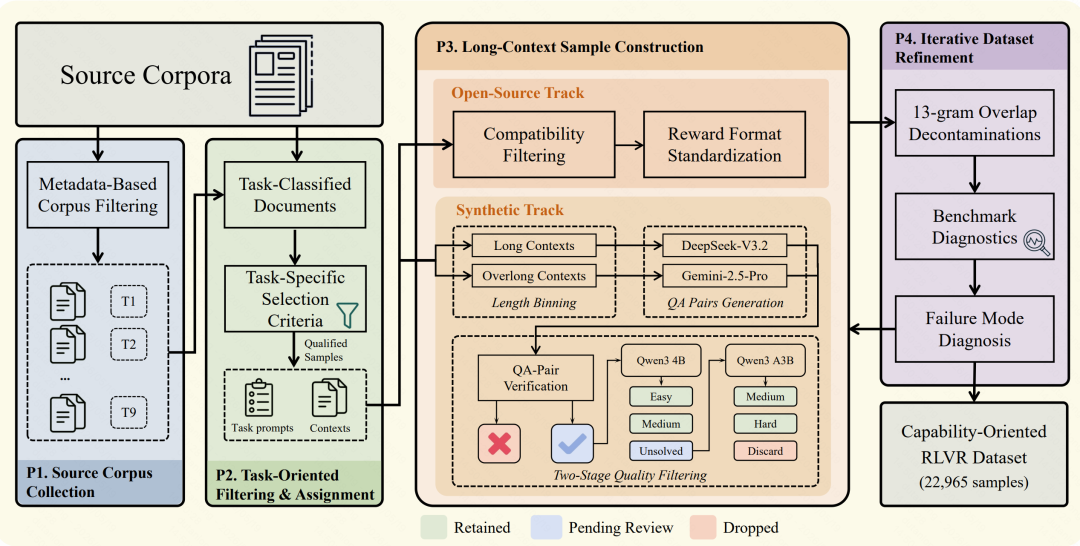
图 3:GoLongRL 数据构造四阶段 pipeline
整个数据集通过统一的四阶段流水线生产:
- P1 源语料收集:按 9 类任务分别收集有标注的开源数据集和无标注真实文档,力求覆盖不同领域、文档结构和长度区间。
- P2 任务过滤与分配:对每个样本按任务语义分配唯一标签。例如,CLongEval 里定位单一事实的样本归为 T1;CAIL2018 里需要聚合多条法律条款的归为 T3;对话记忆子类(T2)只保留超过 50 轮、30K Token 以上的对话。
- P3 样本构造:开源数据做兼容性过滤和奖励格式标准化(如把数值答案改写为
math_verify 可解析格式)。合成数据按文档长度分桶,普通长度用 DeepSeek‑V3.2 生成问答对,超长文档交由 Gemini‑2.5‑Pro 处理。生成后经过两阶段质量过滤:先由 Gemini‑2.5‑Pro 验证答案唯一性与无幻觉,再用 Qwen3‑4B 和 Qwen3‑30B‑A3B 的多级通过率测试剔除标签噪声。
- P4 迭代精化:先做 13‑gram 重叠过滤以防止数据污染,再训练并执行基准诊断。若某维度性能停滞,则排查奖励作弊、答案歧义等问题并清除相关样本;若信号不足,则回到 P1–P3 定向补充数据,循环直至性能与质量稳定。
TMN‑Reweight:面向异构多任务的优化算法
能力导向的数据集带来了 9 种不同的奖励函数,它们的数值尺度和方差分布各不相同。在标准 GRPO 框架下进行混合训练时,优化过程将面临两个相互纠缠的难题。
- 问题一:难度导致的优势估计偏差。GRPO 在计算优势时会除以组内奖励标准差
$\sigma_u$,这会导致特别难或特别简单的 prompt($\sigma_u$ 很小)的优势值被放大,而中等难度的 prompt(回复有成功有失败,$\sigma_u$ 较大)的优势反而被压缩——而后者恰恰是最具训练价值的样本。
- 问题二:跨任务奖励尺度不一致。不同任务的评估指标(EM、F1、ROUGE‑L 等)产生的奖励分布截然不同。Dr. GRPO 为解决问题一而移除了
$\sigma_u$,却使高方差任务(如 F1 检索)产生不成比例的大梯度主导优化,而低方差任务(如二值准确率)的学习信号则被淹没。
TMN‑Reweight 的核心思路
TMN‑Reweight 将尺度归一化与难度校正解耦为两个独立步骤。
- 第一步:任务级均值归一化(TMN)。不再使用逐 prompt 的标准差
$\sigma_u$ 做归一化,而是先计算每个 prompt 的组内标准差 $\sigma_u$,再在同一任务内进行均方根聚合,得到所有该任务 prompt 共享的分母 $\sigma_{task}$。这样既保留了任务级的尺度对齐,又在任务内部保留了 prompt 之间原始的难度差异结构,以供第二步利用。实验结果印证了这一设计:TMN 将跨任务优势量级的变异系数(CV)从 Dr. GRPO 的 0.54、标准 GRPO 的 0.34 降低到了 0.18。
- 第二步:难度自适应重加权。尺度对齐后,再用平滑后的通过率
$\hat{p}$ 估计 prompt 难度(将逐 prompt 的平均奖励与任务级基线插值,以避免小 batch 下通过率估计方差过大),并计算权重 $w = \exp(0.5 - \hat{p})$,以四象限非对称方式施加:困难 prompt 的正优势回复被放大(强化稀有的成功探索),负优势回复被缩小(抑制不稳定梯度);简单 prompt 则相反,正优势被压缩以防熵坍缩,负优势被放大以从意外失败中学习。这种“四象限”式的梯度重分配,在困难样本上强化探索,在简单样本上维持多样性。
实验结果
主要结果:4B 模型达到 SOTA
在 4B 规模上,实验设计允许独立评估数据与算法的贡献。
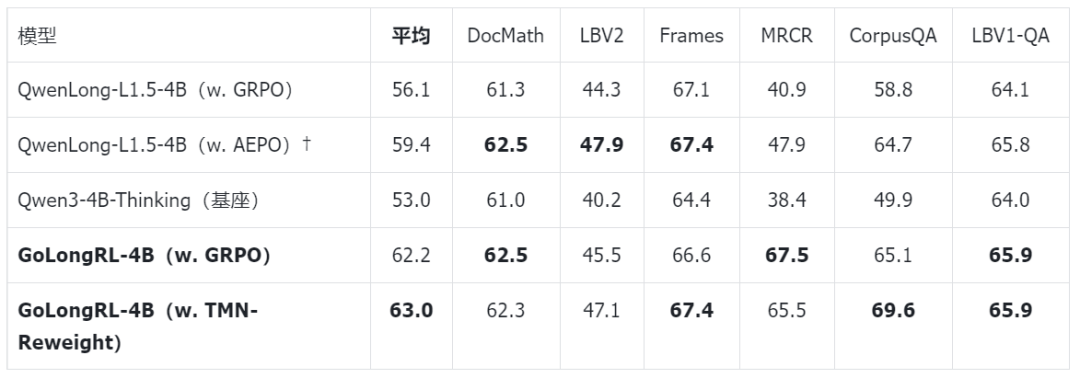
表 3:主实验 – 4B
仅凭数据,vanilla GRPO 的表现已比 QwenLong‑L1.5(GRPO)高出 6.1 分(62.2 vs 56.1),甚至超过了其专用算法 AEPO 版本(59.4 分)。加上 TMN‑Reweight 后,分数进一步提升至 63.0。
主要结果:30B 模型超越顶级旗舰模型
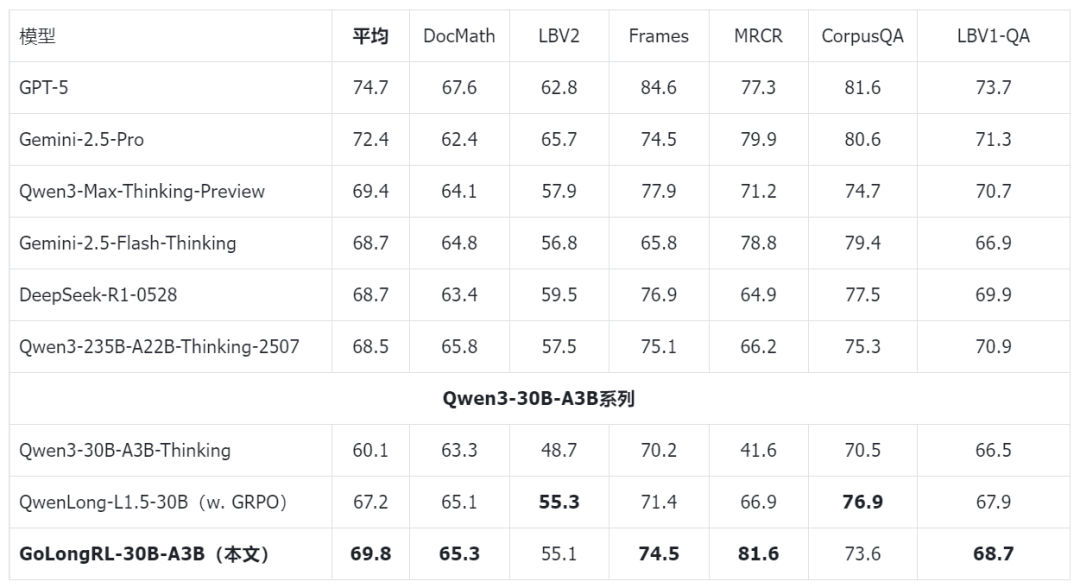
表 4:主实验 – 30B
在 30B 规模上,GoLongRL‑30B‑A3B 以 69.8 分超越了 DeepSeek‑R1‑0528(68.67)、Qwen3‑235B‑A22B‑Thinking‑2507(68.45)以及 Gemini‑2.5‑Flash‑Thinking(68.73),同时也全面超越了使用同等 强化学习 算法(GRPO)训练的 QwenLong‑L1.5‑30B(67.2)。
通用能力保持与迁移
长上下文 RL 训练并未带来负迁移。在通用推理方面,4B 和 30B 模型在 MMLU‑Pro、AIME24/25、GPQA‑Diamond 上均有小幅提升,且两个规模的模型趋势一致。
更值得关注的是迁移效果。Agentic Memory 的 Memory‑Vec 和 Memory‑Rec_Sum 两项任务是训练中从未出现过的,但 4B 模型在 Memory‑Rec_Sum 上仍提升了 9.7 分,30B 提升了 4.5 分。在对话记忆(LongMemEval)任务上,两个规模均提升了 13.6 分(4B: 47.6→61.2;30B: 61.6→75.2),30B 的表现甚至超过了 QwenLong‑L1.5‑30B 的 72.2 分。这说明长上下文 RL 所习得的信息整合能力,能够迁移到训练中从未见过的任务上。
长度外推能力
GoLongRL 的训练上下文为 160K,但其能力可以泛化到更长的序列。4B 模型在 MRCR 128K–512K 段提升 12.27 分,512K–1M 段提升 3.50 分。30B 的表现更为显著,MRCR 128K–512K 提升 12.61 分,512K–1M 提升 5.45 分,CorpusQA 1M 提升 2.74 分。这表明,在 160K 长度下习得的能力并未被局限在训练长度范围之内。
总结
数据覆盖度和奖励多样性才是长上下文 RL 的主要瓶颈,而非算法本身。将任务从单一的“复杂检索路径”扩展到更全面的能力维度,并为每种任务匹配语义合适的奖励函数,即使较小的模型也能达到与旗舰模型相当的长上下文性能。
数据集、模型以及训练与评测代码已完整开源,感兴趣的技术人员可前往 云栈社区 的论坛中与同行进一步探讨相关资源与实践经验。
© THE END
 发表于 6 小时前
|
查看: 3|
回复: 0
发表于 6 小时前
|
查看: 3|
回复: 0
