-
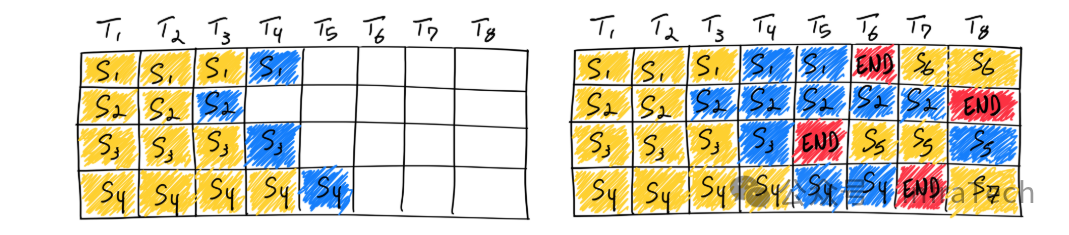
Continous-batching(持续批处理):与静态批处理不同,该技术持续向GPU送入请求数据。当一个请求推理结束后,系统会立刻下发新的请求进行填充,从而最大化GPU的利用率,避免计算资源空闲。参考[1]。
 静态vs持续批处理的对比
静态vs持续批处理的对比
 continuous batching示意图
continuous batching示意图
-
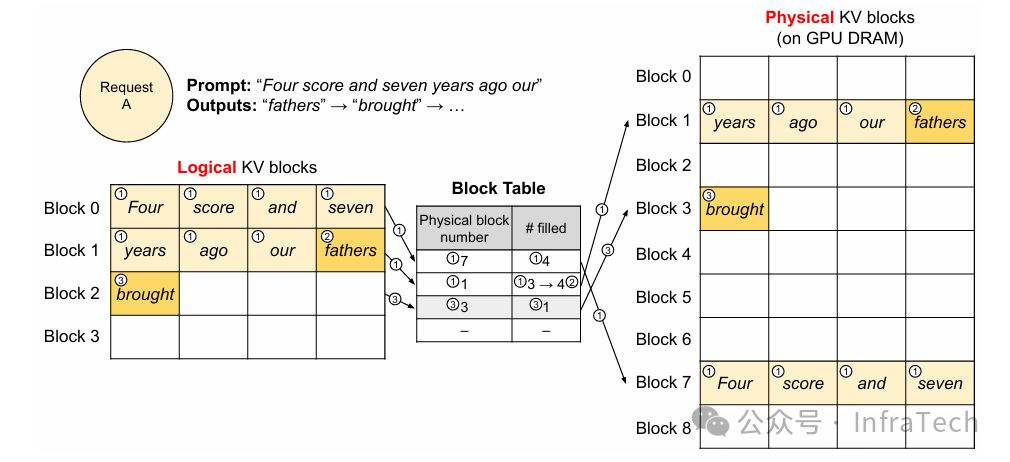
Paged Attention(分页注意力机制):一种高效管理Attention运算中KV Cache的机制。它借鉴虚拟内存思想,将KV Cache按“页”进行管理,能显著减少内存碎片,提升内存利用率。参考[2]。
-
Copy-on-write(写时复制):多个请求可以共享一个未使用完的物理内存块(Block)作为前缀。仅当某个请求需要写入与前缀不同的数据时,才会为该请求复制数据到新的Block中,以此节约内存。
-
Radix Attention:采用基数树(Radix Tree)数据结构来组织和管理Attention中的KV Cache。KV张量以非连续的分页布局存储,每页大小对应一个token,便于高效查找和更新。参考[3]。
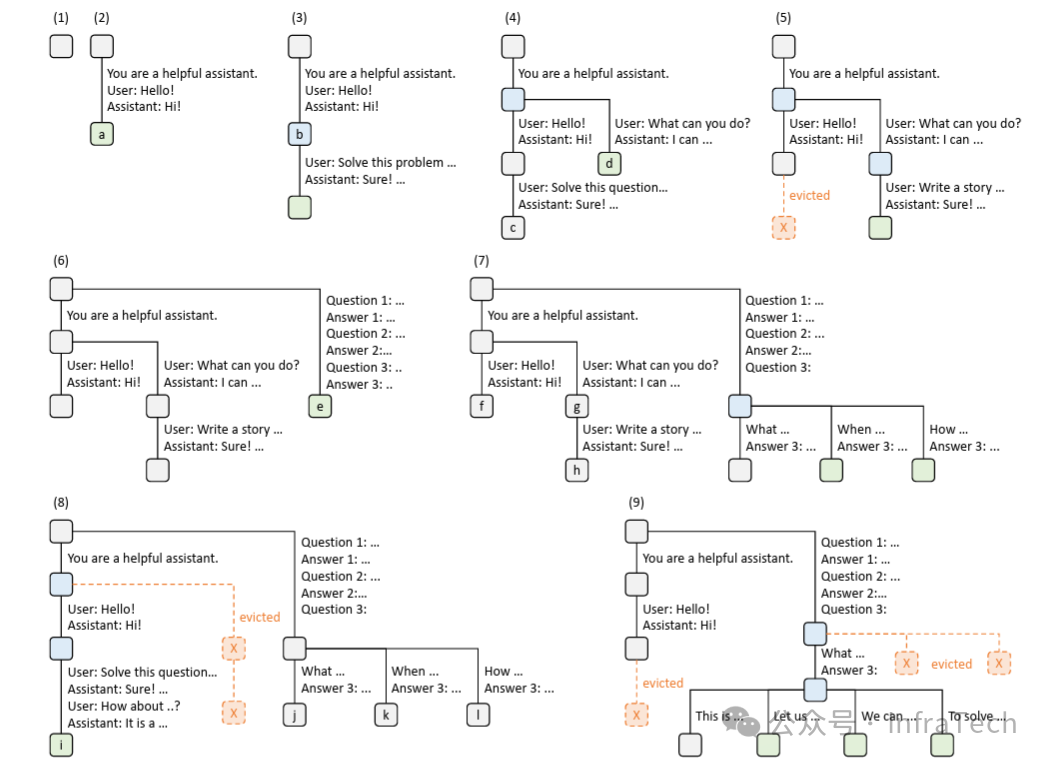 采用LRU策略的基数树示例
采用LRU策略的基数树示例
-
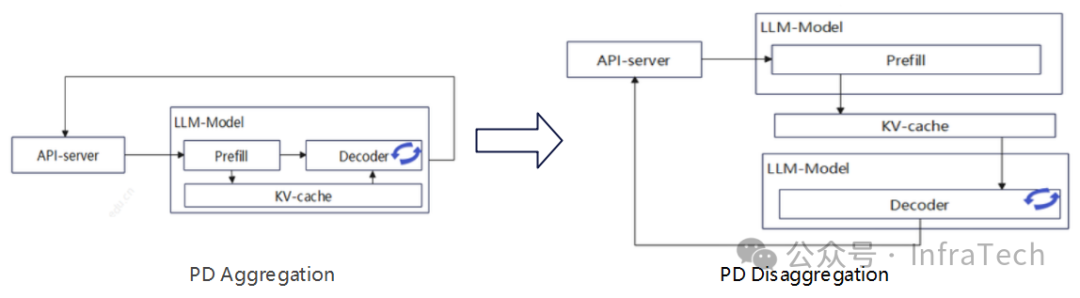
PD Disaggregation(预填充与解码分离部署):将模型推理过程拆分为计算密集的Prefill阶段和内存带宽密集的Decode阶段,并将这两个阶段部署到不同的硬件或计算单元上,以提升整体GPU利用率。参考[4]。
-
AFD (Attention-FFN Disaggregation):将Transformer层中的Attention子模块和FFN(前馈网络)子模块分别部署到不同的设备上。通过灵活调整A与F的配比,可以实现更高的推理性能。参考[5]。
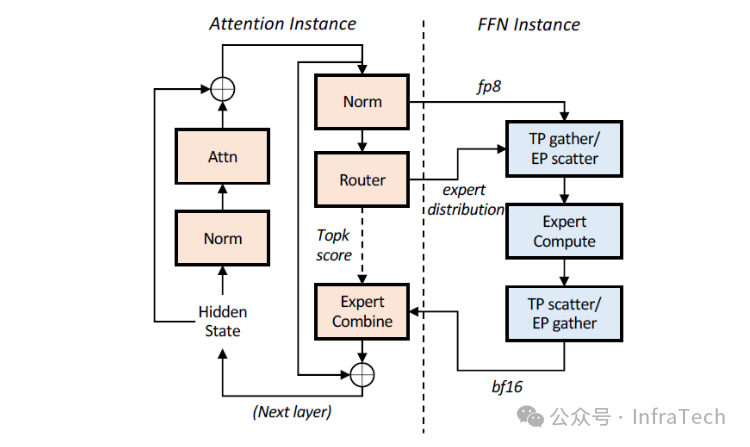
-
APC(Auto Prefix Cache,自动前缀缓存):自动复用历史请求中的KV Cache信息,从而减少新请求在Prefill阶段的计算量,有效提升首Token延迟(TTFT)性能。参考[6]。
-
Speculative Decoding(推测解码/投机推理):使用一个较小的“草稿模型”快速生成多个候选Token,然后由原始大模型并行地进行验证。仅保留验证通过的Token,以此加速生成过程。参考《搞懂投机推理难?这篇总结+框架实践帮你快速上手》。
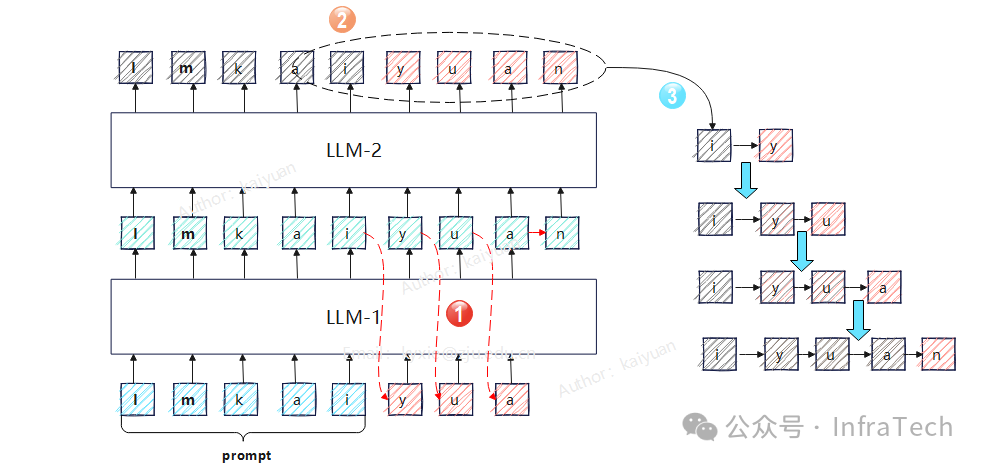 LLM-1负责输出、LLM-2负责校验
LLM-1负责输出、LLM-2负责校验
-
Chunked Prefill(分块预填充):允许将长的Prefill序列切分成更小的块,并将这些块与正在进行的解码请求一起进行批处理,从而平滑计算负载,减少排队延迟。参考[7], [8]。
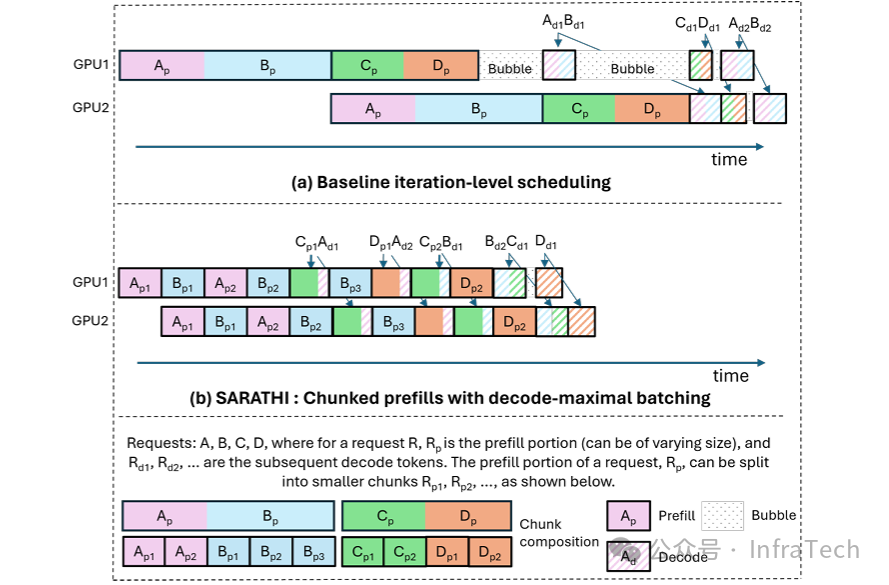 Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
-
W8A16:一种模型量化格式。W8表示权重(Weight)被量化为8位整数(INT8),A16表示激活值(Activation)保持16位浮点数(FP16)精度。类似的格式还有W8A8,W4A16等。参考[9],[10]。
-
Multi-LoRA(多LoRA适配器):在拥有一个基础预训练模型和多个针对不同任务微调的LoRA适配器时,该机制能根据传入请求动态加载对应的LoRA模块,实现在单个服务中高效支持多任务。参考LoRA[11],Multi-LoRA[12]。
-
Guided Decoding(引导解码):约束模型输出,使其严格遵循预定义的格式或语法规则(如JSON、SQL、正则表达式),从而生成结构化、可控的文本。
-
Function Call / Tool Call(函数/工具调用):利用LLM的引导解码能力,使其输出符合预设函数调用所需的参数格式,从而使LLM能够调用外部工具或API。参考[13], [14]。
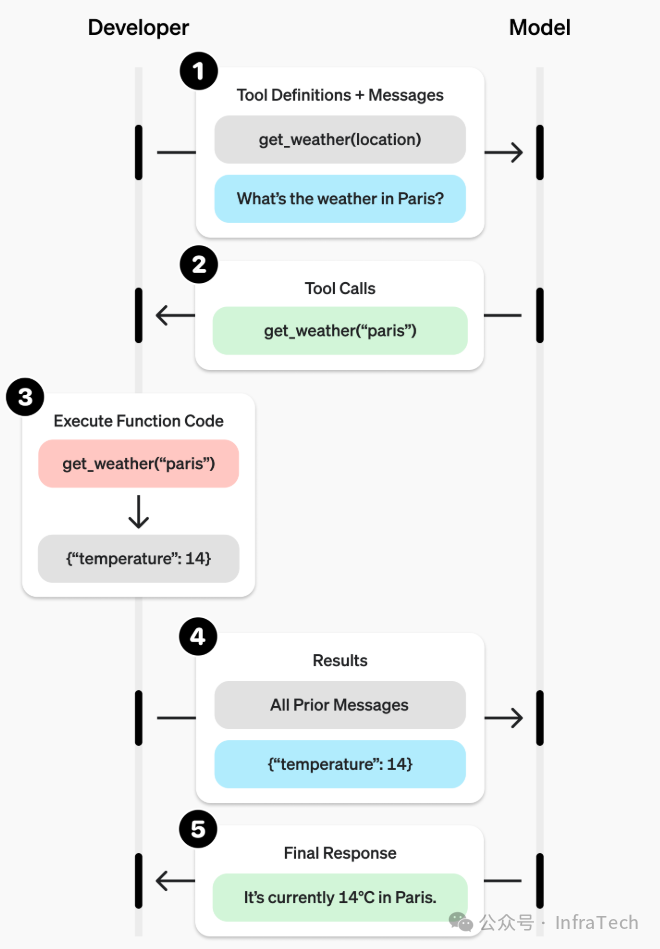 函数调用的示例
函数调用的示例
-
DP/SP/TP/PP:大模型推理中常见的并行策略,包括数据并行(DP)、序列并行(SP)、张量并行(TP)和流水线并行(PP)。参考[15]。
 一般切batch为DP、切序列为SP、切隐藏层尺寸为TP。
一般切batch为DP、切序列为SP、切隐藏层尺寸为TP。
-
TBO/DBO(双批次重叠):将请求拆分为微批次,使注意力计算与通信操作(分发/组合)交错进行,实现计算流和通信流的重叠,从而提升整体算力利用率。参考[16], [17]。
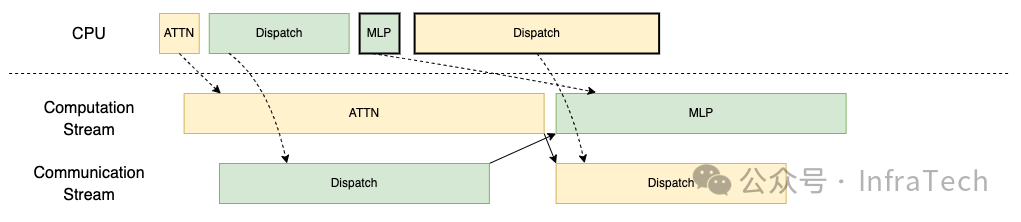 TBO下发示意图
TBO下发示意图
-
FlashAttention:一种加速Attention计算的算法。FA1[18]通过online softmax技巧融合计算步骤,减少HBM读写开销。FA2[19]进一步优化分块策略,缓解了非张量计算核心的性能瓶颈。Triton是一个常用于实现此类高性能算子的深度学习编译器和加速库。
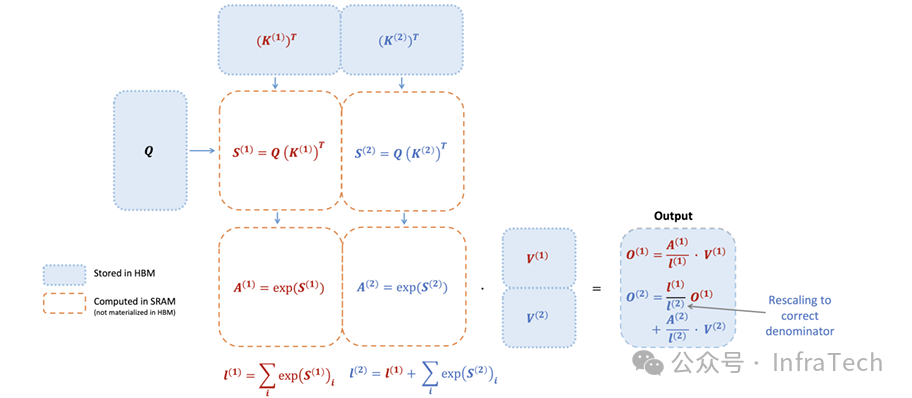 FA2
FA2
-
Flash-Decoding:针对长序列解码阶段Attention计算的优化方法,通过将Key/Value序列分块,来更高效地利用GPU计算资源。参考[20]。
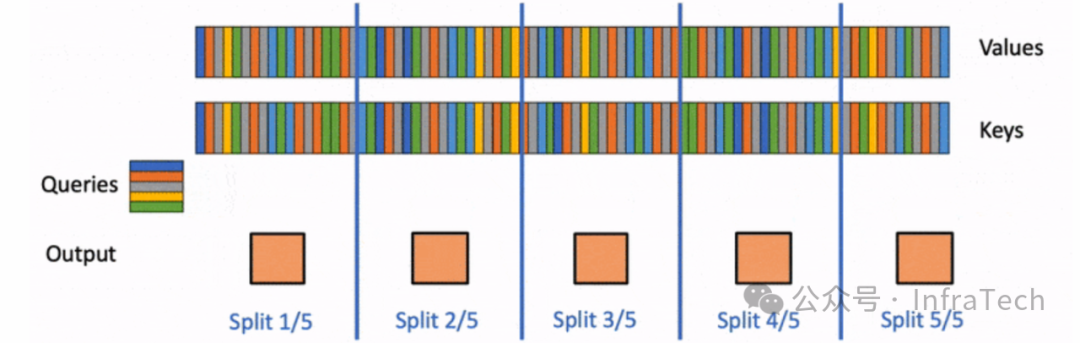 长序列分块运算
长序列分块运算
-
FIA (Flash Infer Attention):LLM推理框架中使用的高性能推理库,针对Prefill、Append、Decode等不同推理阶段实现了优化版本的FlashAttention算子。参考[21]。
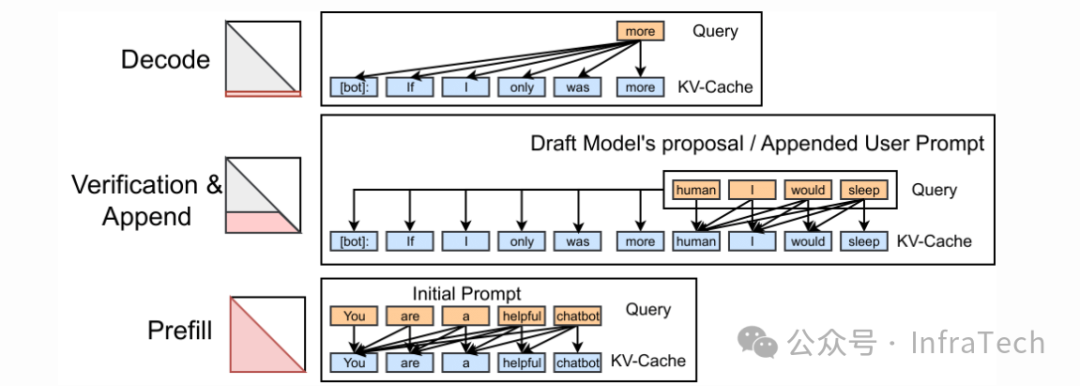 FIA
FIA
-
DPLB (Data Parallel Load Balancing,数据并行负载均衡):一种调度机制,确保将推理请求均衡地分发到多个数据并行实例上,以提升整个服务集群的吞吐量和效率。参考[22]。
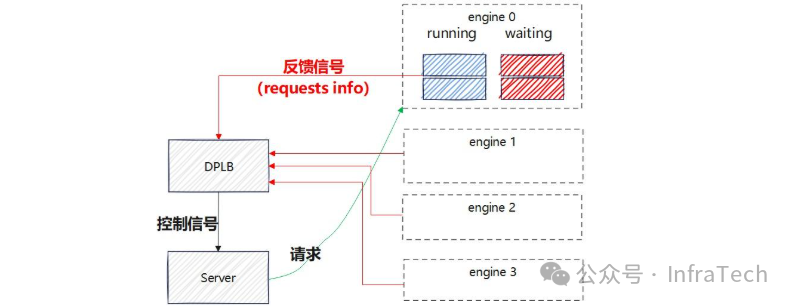
-
EPLB (Expert Parallelism Load Balancer,专家并行负载均衡器):在MoE(混合专家)模型中,用于平衡不同设备上专家计算负载的调度器。参考[23]。
-
CoT (Chain of Thought,思维链):在提示词中引导模型展示其逐步推理过程,通常能提升模型在复杂任务上的表现,可视为LLM的“深度思考”。参考[24]。
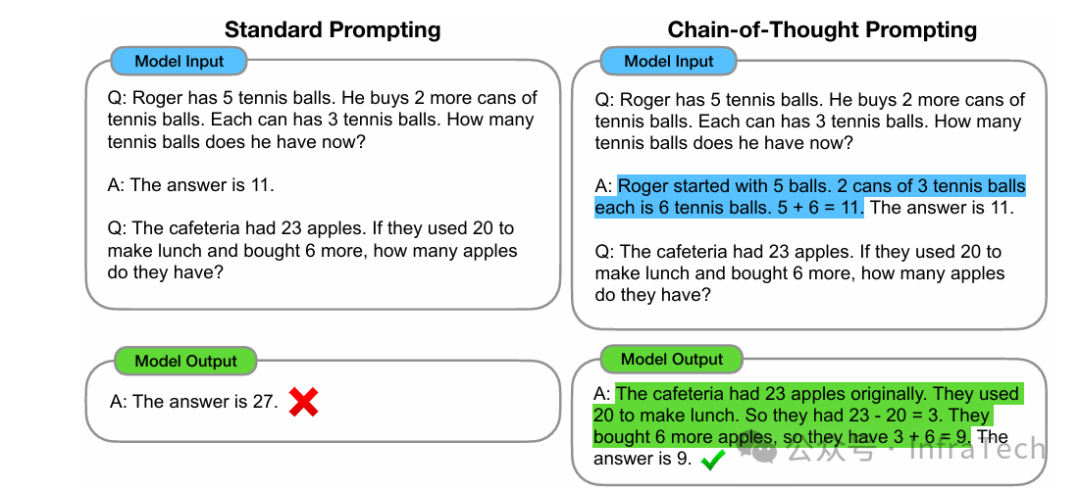 一般输出与CoT输出的差异
一般输出与CoT输出的差异
-
FCFS (First-Come, First-Served,先到先服务):一种基础的请求调度策略。
-
GPTQ:一种针对GPT系列模型的训练后权重量化方法,利用近似二阶信息进行量化。参考[25]。
-
AWQ (Activation-aware Weight Quantization):一种感知激活值分布的权重量化方法,采用通道级粒度进行量化。参考[26]。
-
Llama-2-7b-hf:指Hugging Face格式的Llama2模型,参数量为70亿。
-
Round Robin(轮询调度):一种公平的CPU时间片分配算法。
-
EOS:序列结束标记,生成过程中遇到此Token会停止输出。
-
logprobs:对数概率,计算方式为ln(p)。在计算长序列概率连乘时,使用对数可以避免数值下溢。
-
Reasoning Parser(推理过程解析器):用于从模型生成的结果中分离出推理过程和最终答案。
-
Stream Reasoning(流式推理):逐个生成并返回Token,与之相对的是非流式(一次性返回所有结果)。
-
Structured Output(结构化输出):约束模型输出为特定格式(如JSON)。参考[27]。
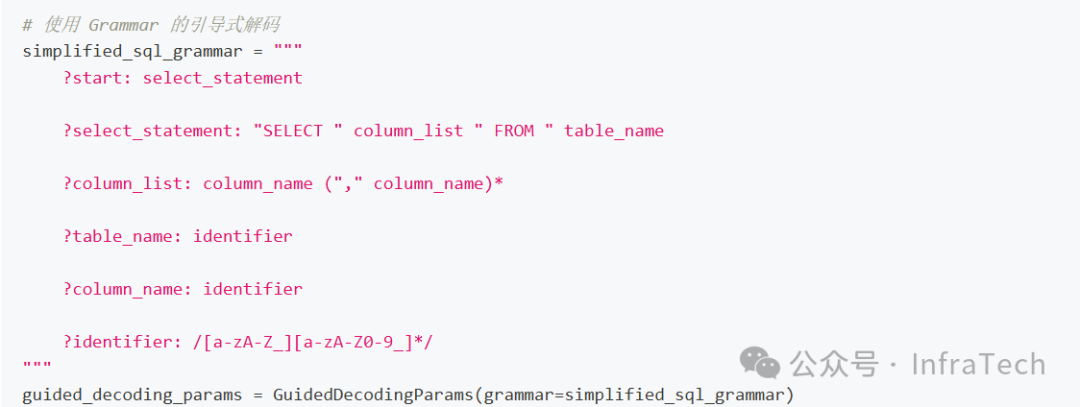
-
RPC (Remote Procedure Call,远程过程调用):一种网络通信协议。
-
Prometheus:一款开源的系统监控和告警工具包。
-
ORCA (Open Request Cost Aggregation):一种允许服务端点(如Envoy)向上游负载均衡器报告实时负载指标的协议,用于实现更智能的流量分发。参考[28]、[29]。
-
FlashMLA(Multi-Head Latent Attention):由DeepSeek推出的针对推理解码阶段优化的MLA(多头潜在注意力)加速版本。参考[30]。
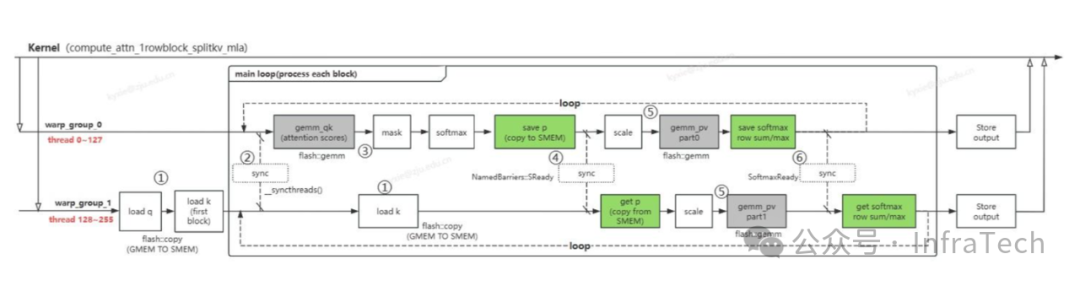
-
triton:一个开源的深度学习编译器和加速库,提供了许多高性能的GPU算子实现。参考[31]、[32]。
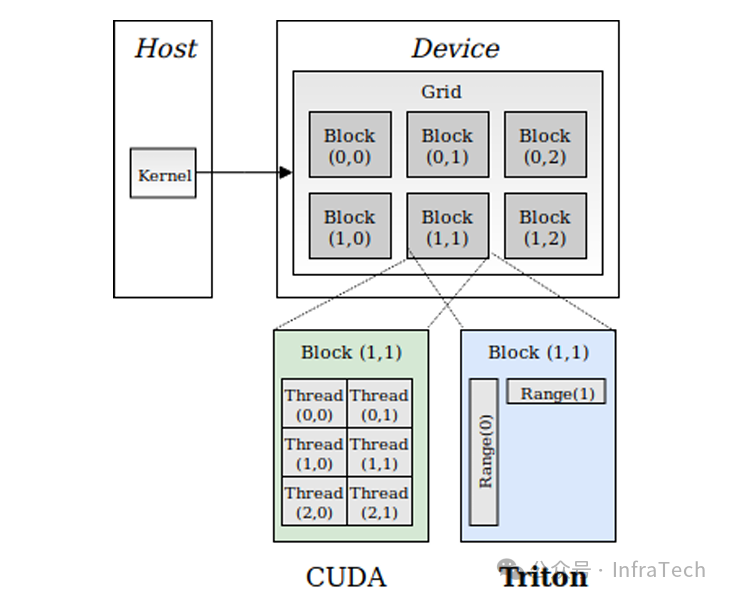
-
ray:一个用于构建分布式应用的框架,提供灵活的资源和任务调度。在推理中常用于支撑多机分布式并行计算。参考[33]。
-
lmcache:一个专注于KV Cache存储与传输的库,旨在降低首Token延迟(TTFT)。参考[34]。
-
nixl (NVIDIA Inference Xfer Library):NVIDIA推出的面向推理优化的传输库。参考[35]。
-
mooncake:一个KV Cache分布式存储/传输库,其中的TransferEngine常用于Cache传输。参考[36]。
-
pytorch:主流的深度学习框架,广泛应用于模型训练和推理。
-
punica:一个支持高效多LoRA服务的库,特点是提供了统一的服务接口。参考[37], [38]。
-
asyncio:Python内置的异步I/O框架,基于事件循环。在推理服务中常用于处理CPU端的异步操作,如请求预处理、结果后处理等。

-
uvloop:asyncio事件循环的一个高性能替代方案。
-
tqdm:一个用于快速创建进度条的Python库。
-
zmq (ZeroMQ):一个高性能的异步消息传递库,用于构建分布式和并发应用[39]。
-
fastapi:一个用于构建高性能API的现代Web框架。其中的APIRouter能帮助更好地组织路由。
 发表于 2025-12-13 09:10:59
|
查看: 378|
回复: 0
发表于 2025-12-13 09:10:59
|
查看: 378|
回复: 0


