
之前有一次跟大家讲过,如果玩 AI 的话,有一个重要的选题源一定不要错过,就是播客。
如果你经常听播客的话,自然就会明白我的意思。不过这播客这玩意吧,真的又爱又恨。爱的是信息密度,一期好播客四十分钟里聊的行业判断、实操经验和系统思考,比你刷一上午短视频有用得多。恨的是时间成本——你永远不知道点开之后,前面的二十分钟到底是干货还是闲聊。
所以我的日常就是:看到一期好像挺有意思的播客,点开,听五分钟,发现好像都在铺垫,切走,找一期新的,点开听 5 分钟,然后又开始一轮循环。
有点烦。
有没有什么办法,可以先快速判断一期播客到底讲了什么、有没有核心观点、值不值得听?想了很多次,一直没动手。
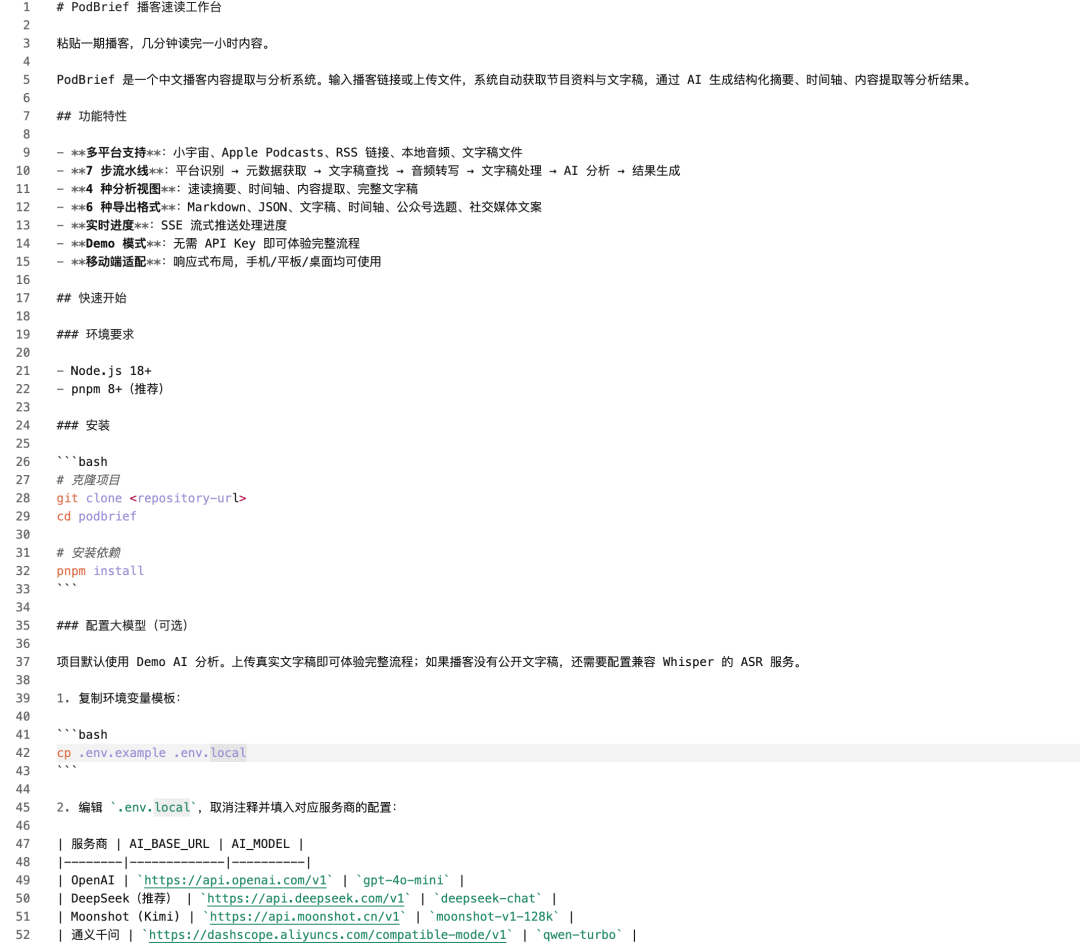
正好最近 Qwen-3.7-max 上新,我就琢磨着:别整那些花里胡哨的 demo 了,拿它做一个我自己真的会用的工具试试。用的 Agent 工具就是阿里的 QoderWork,原汤化原食嘛。而且 QoderWork 中国版目前每天赠送 Qwen-3.7-Max 200 次免费调用额度,现在注册可领取 1 个月 2000 积分,直接上手体验,零成本试用。
这次我要的需求简单说就是:输入小宇宙或者 Apple Podcasts 链接,自动获取播客节目信息、提取文字稿或者转写音频,然后用大模型分析内容,给你一个结构化摘要、核心观点和收听建议。起个名字就叫 PodBrief。
你看,需求很清晰。但把它做出来,中间踩的坑,故事比结果还精彩。
不是在吹
先说结论。我原本的预期是:让 AI 搭一个能跑的原型就行,界面过得去、流程能走通,就够了。
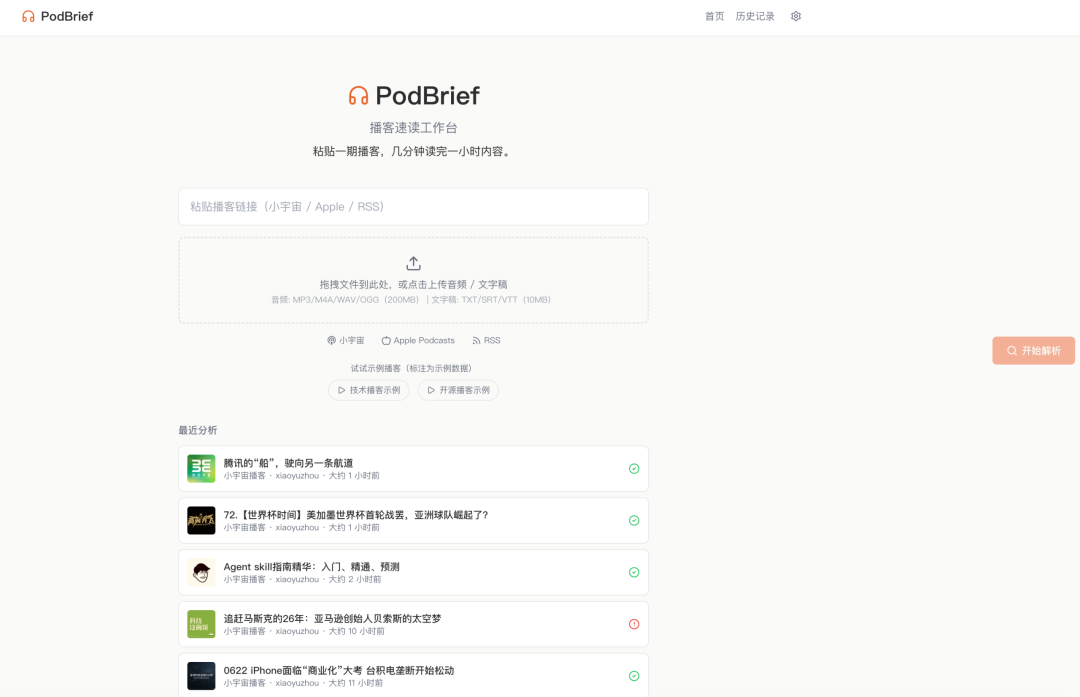
结果 Qwen-3.7-max 在这个项目上的表现,远超这个预期。它不是只写了个前端页面就完事了,而是理解了一整个系统的工程链路。

我把需求发给内置 Qwen-3.7-max 的 QoderWork:我要一个播客分析系统,支持小宇宙和 Apple Podcasts,优先找公开文字稿,没有的话就获取音频转写,最后生成摘要、核心观点和收听建议。还要能配置自己的大模型和 ASR,要有进度展示和历史记录。
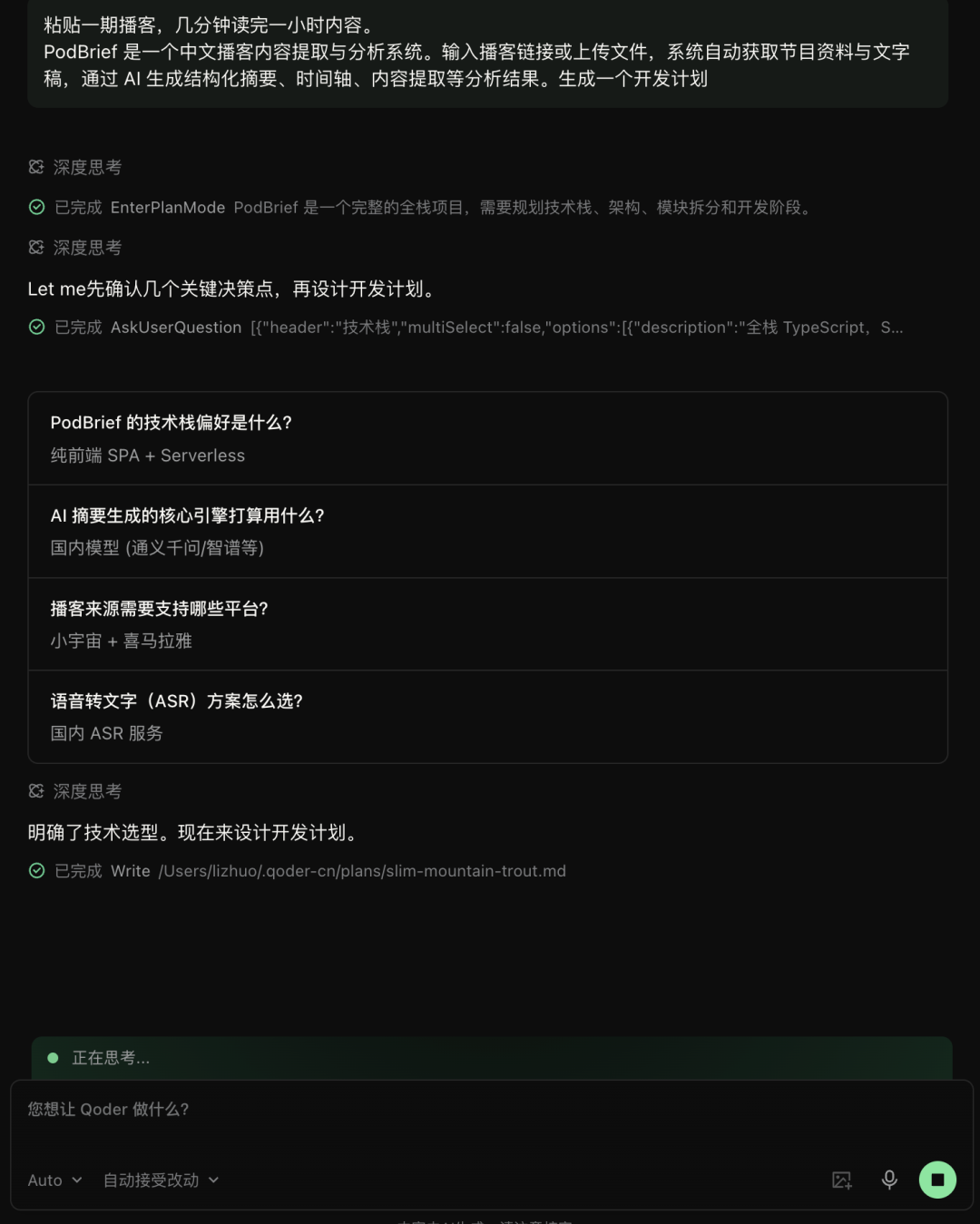
它没有一上来就开始写代码。而是先把这个模糊需求拆成了几个功能模块:平台识别、节目资料获取、文字稿查找、音频转写、内容分析、结果展示、设置模块、历史记录。这步拆解做完,我心里已经有谱了,是我要的这个方向。
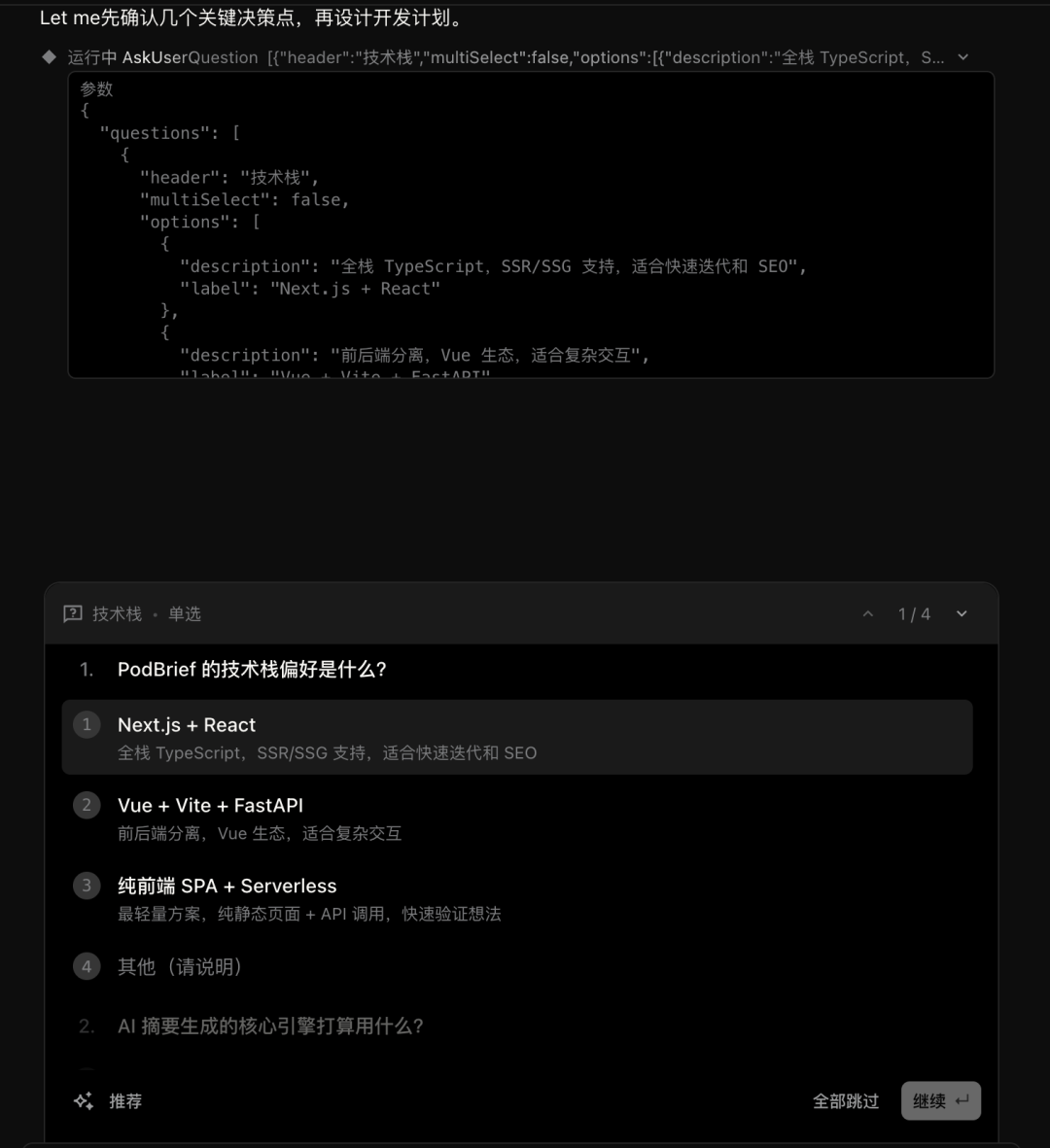
接下来是项目结构的搭建: Next.js App Router、TypeScript strict、SQLite + Drizzle ORM、Tailwind CSS。这些技术选型我都没指定,它自己选的。而且选的方案确实符合这个项目的体量——不重,不花哨,刚好够用。说实话,这个技术选型能力,比很多初级开发者都要靠谱。
项目骨架搭完之后,就是一步步实现功能。这中间有几个地方,让我对 Qwen-3.7-max 的印象加分不少。
举个例子。平台识别这个功能看起来很简单,看看输入链接是小宇宙的还是 Apple Podcasts 的。但如果按能跑就行的思路,可能就是写几个 if-else 判断 URL 格式。Qwen-3.7-max 的做法是:把平台识别做成一个独立模块。每个平台有自己的解析器,统一输出标准格式的节目数据。这样以后加 Spotify、喜马拉雅、RSS Feed,只需要加一个新的平台解析器,其他流程完全不用改。
这就是工程思维。需要解决的问题,先想好为未来的扩展留好接口。这种思路在 AI 写的代码里,不常见。
开始折腾
系统跑起来之后,第一关是 ASR 配置。播客不一定有公开文字稿,很多时候只能获取音频然后转写。ASR(语音转文字)是整个链路里最容易被忽略、但最可能出问题的一环。
Qwen-3.7-max 一开始帮我接了一个通用的 ASR 实现,走的是 OpenAI Whisper 兼容的 multipart/form-data 接口。我心想,阿里云千问也有 ASR 模型,与其用第三方,不如直接全部走千问生态。于是我开始搞千问 ASR 配置。
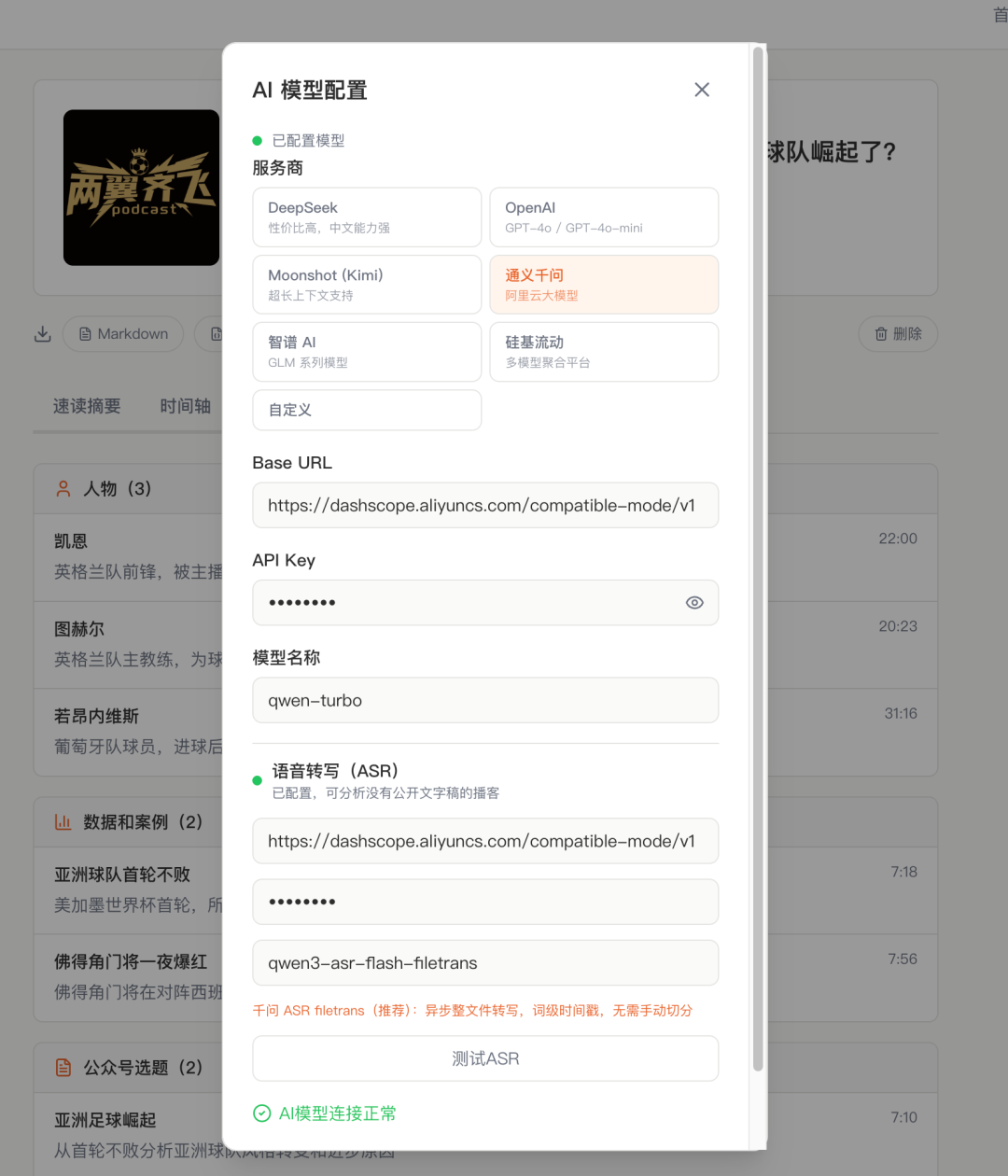
这里就要说一下 QoderWork 的一个关键能力了。整个配置流程涉及 API 文档阅读、接口对接、模型参数设置、错误处理、连接测试。Qwen-3.7-max 在 QoderWork 里能看完阿里云帮助文档后,把千问 ASR 的两个模式都接进来了:一个是 qwen3-asr-flash(同步模式),走 Chat Completions 端点,把音频转成 base64 发过去。但这个东西有个致命限制——单次只能转 3 分钟的音频。
三分钟。播客有多长你们是知道的,四十分钟起步,一小时常态。所以只能搞分片了。
Qwen-3.7-max 给我写了一个音频切分引擎。原理是这样的:如果是 WAV 格式,就读 PCM 采样数据,用滑动窗口算 RMS 能量,找到静音段,在静音中间切分。如果是 MP3 或者 M4A,就按估算码率切成固定时长的小段。
这个切割逻辑本身不复杂,但让我惊喜的是它在设计时做的权衡:优先用静音检测(最精准),WAV 不可解析时退化到固定时长切分(最通用),有对应回退和边界处理。不是临时糊上去的。切成小段之后,每段不超过 2.5 分钟,然后并发 3 个 API 调用去转写,转写完合并结果,按时间偏移对齐。
跑是能跑了,但有个问题:每个小段返回的都是纯文本,没有时间戳。后面做时间轴和内容提取的时候,时间都对不上,乱七八糟的。这就很难受。
外力救命
其实千问 ASR 还提供了另一个模式:qwen3-asr-flash-filetrans,异步文件转写。这个模式好在哪里呢?首先不用自己切分了,整段音频一个 URL 丢过去就行。其次它支持词级别的时间戳,每个字的起止时间精确到毫秒。而且 API 自动帮你分了句子,还能标注情绪。这不就是我想要的吗。
于是 Qwen-3.7-max 又在 QoderWork 里帮我换成了这个异步模式。整个流程是:提交任务,轮询状态,下载结果,解析词级时间戳。改完之后,文件转写终于跑通了,十几分钟的播客,几分钟内完成转写,返回了 83 个句子段,每个都有精确到毫秒的时间戳。
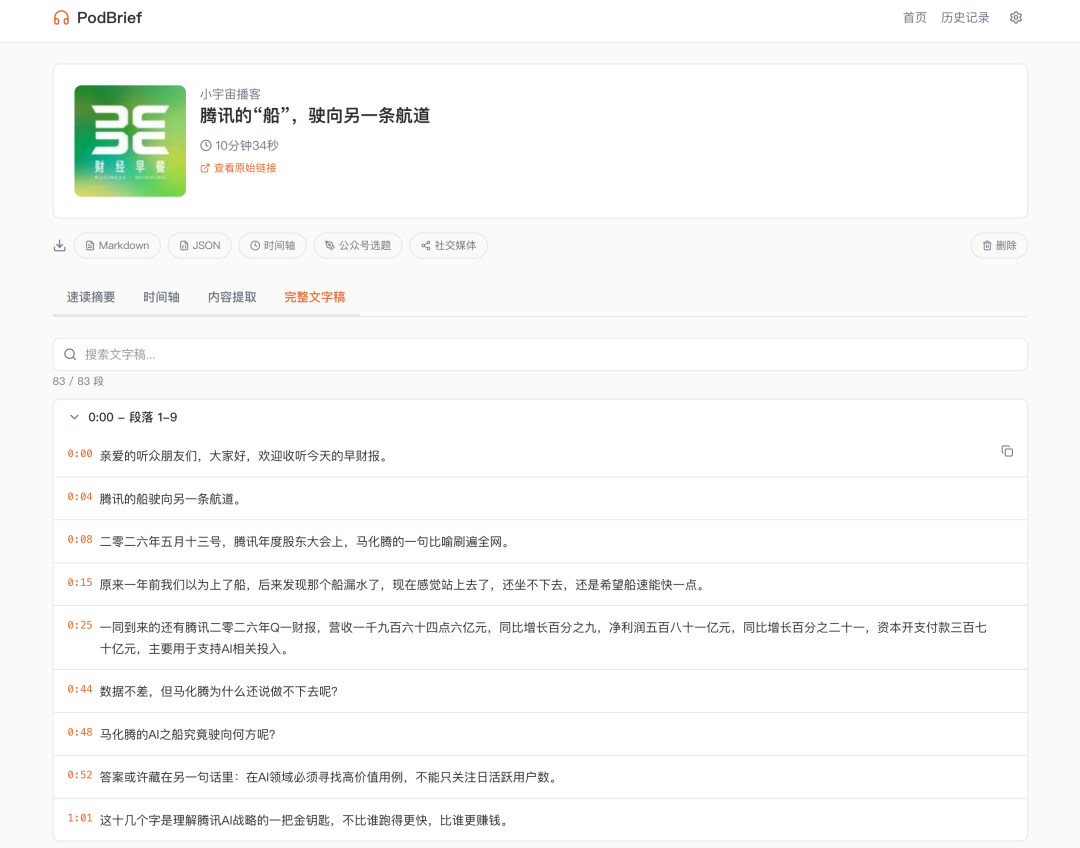
这个精度是真不错,很多做得比较规范的播客也就这样了。
AI 分析
转写搞定了,接下来是整个系统最核心的环节:AI 分析。把转写好的文字稿喂给 大语言模型,让它提取摘要、核心观点、关键实体、收听建议。十分钟左右的播客完全没问题。但四十分钟以上的播客,文字稿转出来有将近四百段,AI 分析要分很多块并行处理,最后再综合。然后进度条停在「提取核心内容」,卡住了。
我让 Qwen-3.7-max 去排查。它在 QoderWork 里定位到了两个问题:
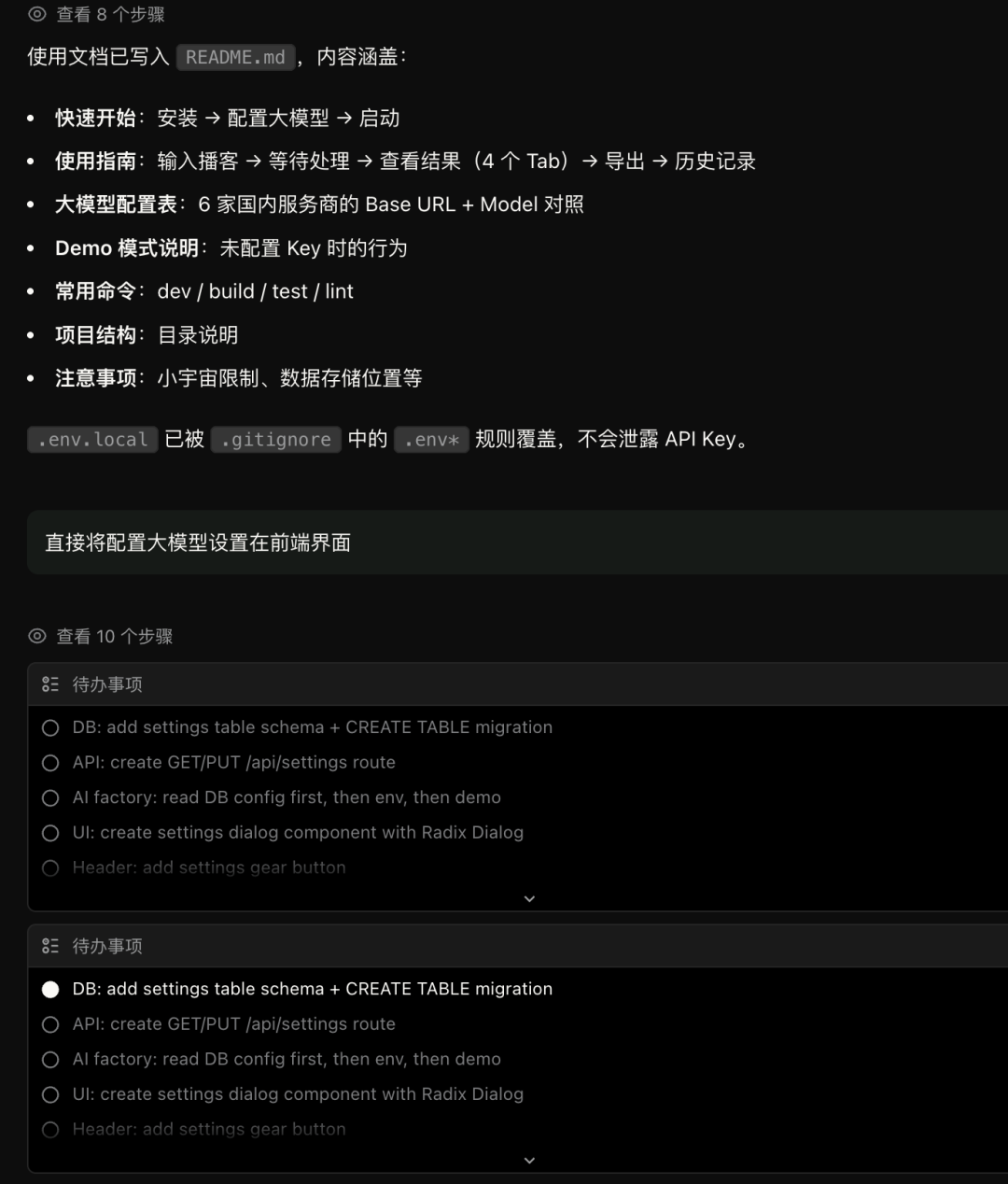
第一个:我在 AI 调用的 prompt 里让模型输出一个巨型 JSON,47 分钟播客的综合输出量太大了,模型生成到一半被截断了,最后一个数组少了个括号,全崩。第二个:虽然设置了超时时间,但 fetch 调用在某些情况下根本不响应 abort 信号,导致整个 worker 线程一直等。
Qwen-3.7-max 自己给我改了三件事:
把综合 prompt 精简约 50%,实体分类从 10 类减少到 7 类,每类限制 0-3 条;把分段分析的 prompt 也精简了,segment ID 列表从全部列出改成只给起止示例;写了一个 JSON 截断自动修复函数,扫描未闭合的括号和引号,自动补全。
改完这三件事之后,它还顺手把整个系统的使用文档和开发说明都补齐了。终于,跑通了。

跑出来的效果
最终出来的结果是什么样的?给你们看看。
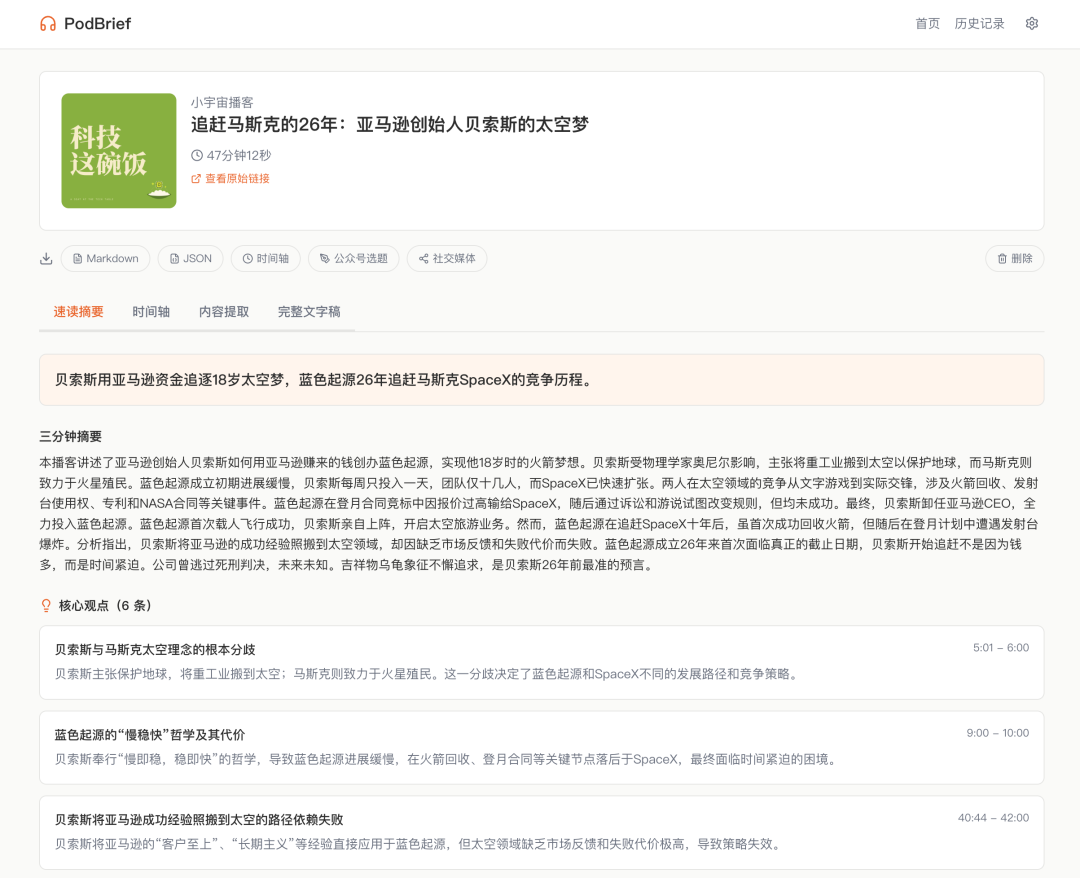
第一个 Tab 是速读摘要。一句话总结告诉你这期到底讲了啥,下面是三分钟速读,有点像播客版的「太长不看」。不是那种泛泛的“本期讨论了某某话题”,而是真的把核心逻辑链和关键结论给提取出来了。
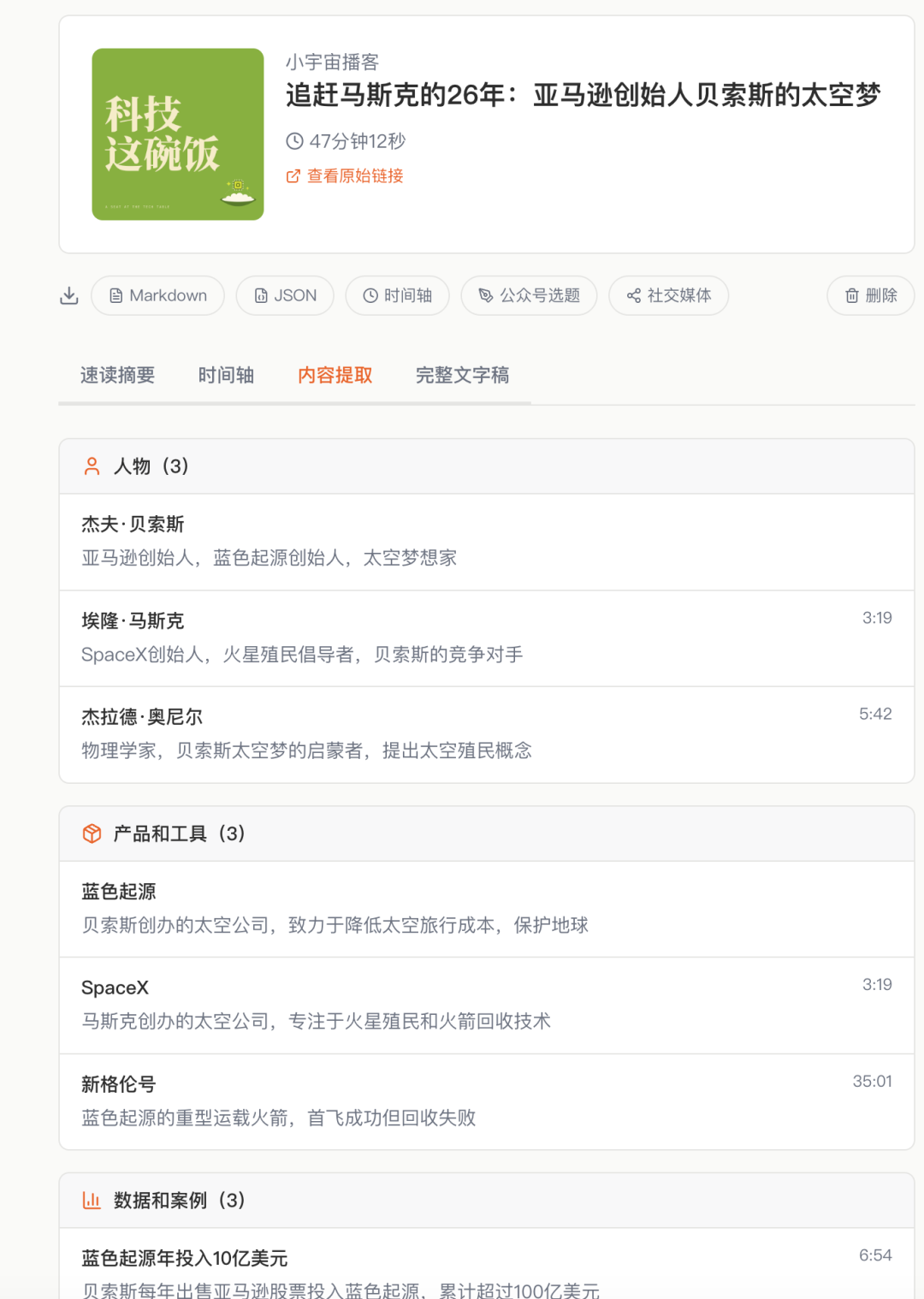
第二个 Tab 是内容提取。人物、产品、数据案例、金句、行动建议,分类列好。比如 47 分钟那期贝索斯太空梦,提取出了贝索斯、蓝色起源、ULA、SpaceX 等关键人物和公司,还有“太空不是逃避地球问题的地方,而是保护地球的方式”这种金句。每个条目都有出现的时间点和对应的原文段。
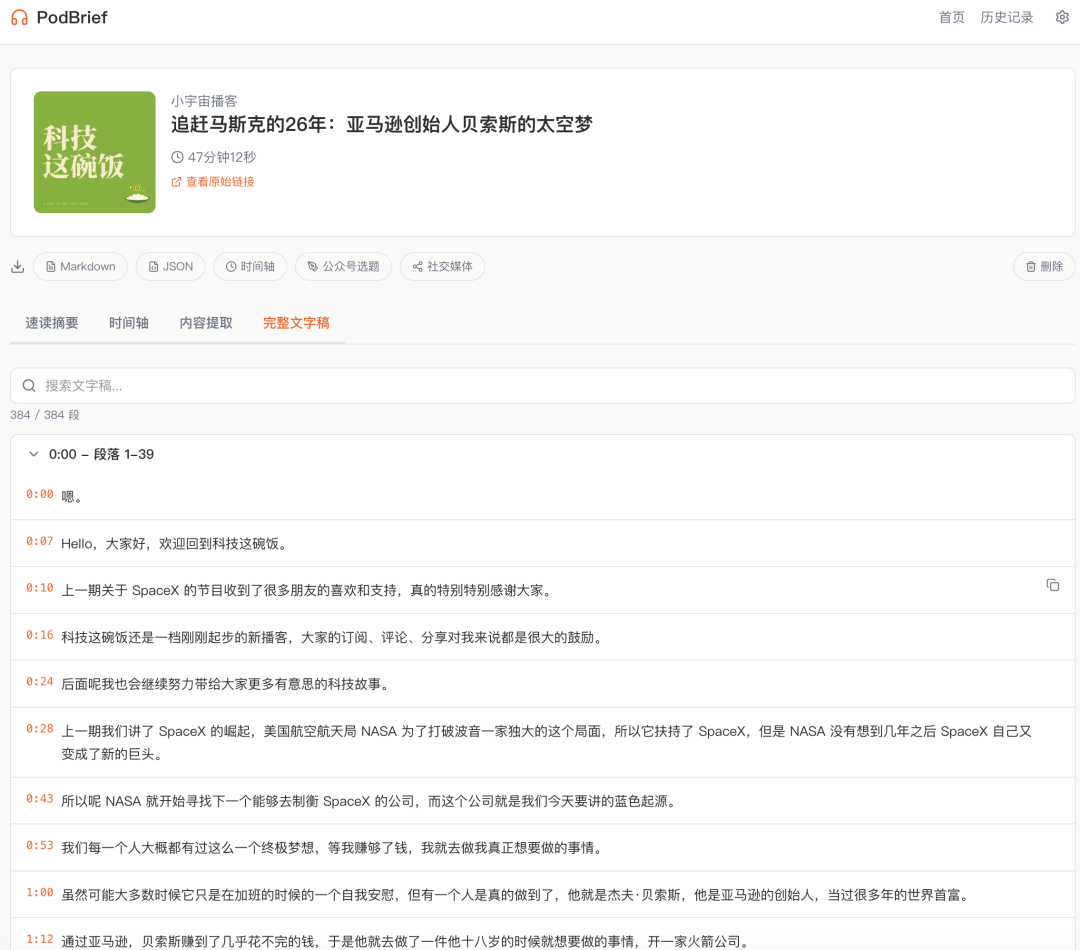
第三个 Tab 是完整文字稿。文件转写出来的,385 个句子段,每段都有精确到毫秒的时间戳。可以搜索、可以高亮、可以点时间戳跳转。如果你听完摘要觉得有意思,想直接跳到某个观点对应的原文位置,点一下就行。
使用体验
项目跑完了,复盘一下整个过程。必须要讲一下 QoderWork 的跨会话记忆。
整个开发过程,我前后折腾了大概几十个来回。需求一直在变:一开始只是个简单的播客分析,然后要求加配置页面,再加 ASR 支持,再换异步模式,再修 bug…… 如果每次都要重新跟 AI 解释这个项目是干嘛的、之前改过啥,我估计早就烦躁到放弃了。但 QoderWork 记得。
它记得这个系统的目标是做播客分析而不是通用工具。它记得我已经接过了千问 ASR。它记得上次修的 bug 是 API 响应字段层级写错了。

这就让整个体验非常不同。你不需要重新交代上下文,直接说“上一步卡在 AI 分析,帮我看看”就行了。顺便说一句,移动端还有个很实用的能力:你发起长任务之后可以离开电脑,手机看它跑到哪了。
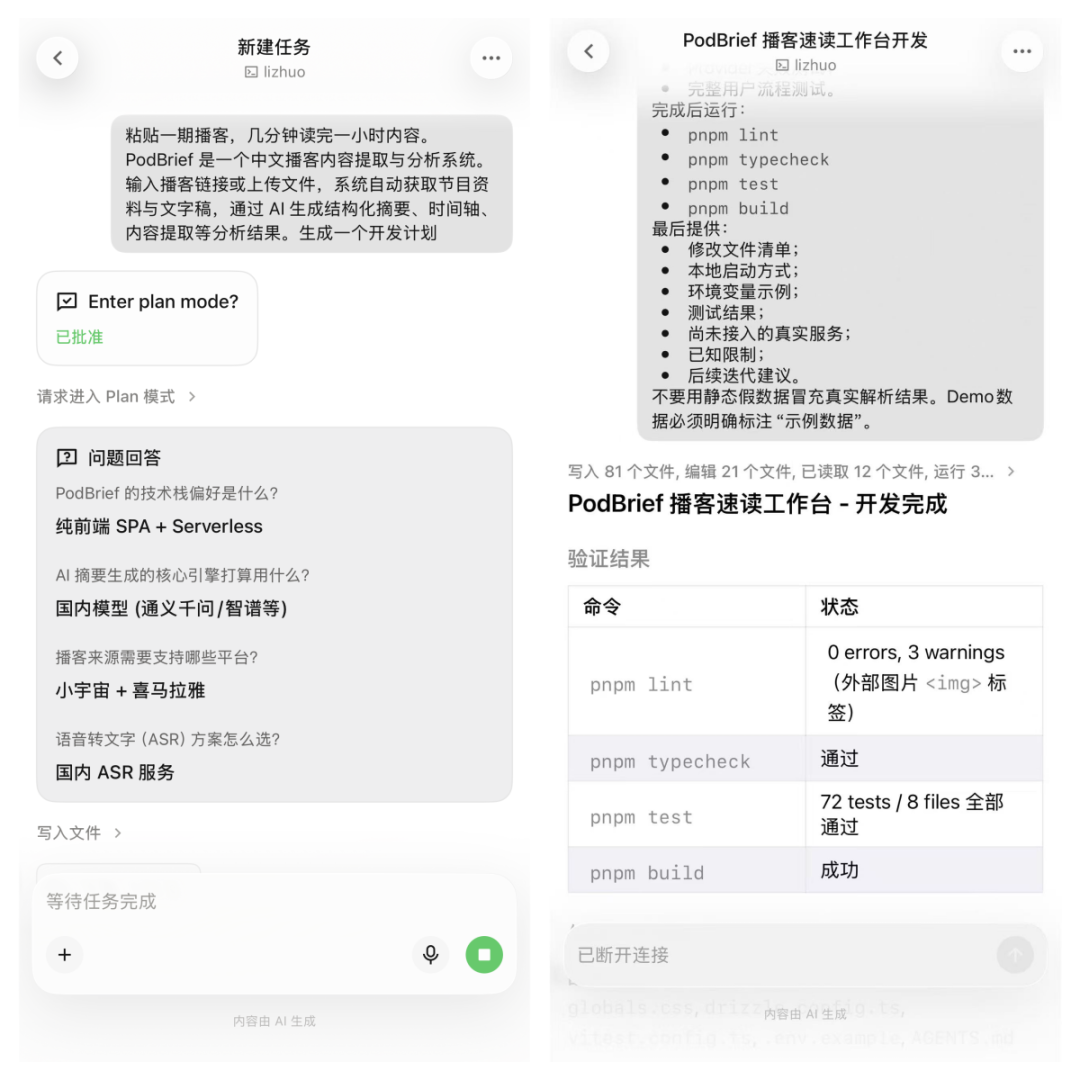
我实际试过。下班路上打开手机,看到 ASR 转写跑完了,AI 分析正在进行,不用盯着电脑屏幕干等。对于这种动不动几分钟甚至更长的长程任务来说,这个体验比一直守在电脑前好太多了。
结语
有一说一,这次最大的感触不是 Qwen-3.7-max 有多聪明,而是它配合 QoderWork 这种工具,能实实在在地把一个想法推进成一个可用的东西。而我记录的,也是一个真实项目的实操过程。
中间踩的坑,其实都不是模型的锅。ASR 配置、API 字段层级、JSON 截断,这些都是真实开发中本来就存在的问题。真正关键的是:当你遇到这些问题的时候,这个 AI 能不能帮你一步步定位、修复、验证、再推进。从这个角度看,Qwen-3.7-max 在这个项目里做到了。
它不只是写了个能看的页面,它理解了一整个系统的工程链路:平台识别、数据获取、音频转写、文字清洗、AI 分析、结果生成。每个环节都不是一次生成就完美,而是在反复调试中不断迭代到可运行。这就是真实开发。
对于像我这样平时有各种小想法但懒得从零手写完整系统的人来说,Qwen-3.7-max + QoderWork 的组合,确实把“想想而已”变成了“真的能做”。播客太多听不过来?至少现在,我有一个自己做的工具来帮我做第一轮筛选了。
这个成就感,拉满。如果你也有类似的小项目想法,不妨去 云栈社区 和大家一起聊聊,看看还有哪些有意思的 AI 应用场景值得动手做。
 发表于 1 小时前
|
查看: 5|
回复: 0
发表于 1 小时前
|
查看: 5|
回复: 0
