从“会操作”到“高效操作”,Web Agent 还差什么?
如今的 Web Agent 其实不缺基础能力。像 Claude、Codex 这类 Agent,能看懂页面、识别按钮和输入框,点击、跳转、提交都不在话下。真正拖慢它们脚步的,是另一个更恼人的问题:每换一个新任务、新网站,就得让那个最强(也最贵)的模型,像第一次上网一样,从零开始把整个流程摸索一遍。
这种“从零摸索”常常演变成一系列翻车现场:陷进死循环,在几个页面间反复横跳;跑着跑着就忘了最初任务意图,越走越偏;在搜索结果里来回切换却永远读不全信息;或是明明离答案只差一步,却提前收手,草率交差。
更要命的是,就算这次侥幸摸对了路,经验也往往随着对话窗口关闭而蒸发。下次遇到同类任务,换个 Agent,一切又要从头再来,再踩一遍同样的坑。
一个很朴素的问题就浮出水面了:能不能让“摸一次路”,达到“复用很多次”的效果?
更具体点说——能不能让人认真地做一遍任务,把这一遍操作里的“门道”打包,然后交给一个更小、更便宜的模型,让它照着做,就能稳定搞定同一类任务?
Einsia AI 旗下 Navers Lab 发布的开源项目 BrowserBC,给出的答案是一条三步走的范式:录制 → 转写成 Skill → 交付执行。
- 录制:在浏览器里完成任务时,把全过程完整录下来。这包括任务指令、每一步的页面观察(既有渲染截图,也有结构化的 DOM/可访问性树快照)、用户的每个动作(点击、输入、跳转,并带着对应的元素定位)、页面给出的反馈(跳转、校验报错、成功信号),以及任务最终状态。
- 转写:这是关键。它不是把操作存成一段“回放脚本”,而是由模型将其转写成一份用自然语言描述的 Skill——一张“技能卡”,讲清这类任务该怎么做、怎样判断成功。
- 执行:最后,把这份 Skill 交给任意一个模型。它会根据技能卡的指引,在真实的网页上自己完成落地操作,而不是机械地复刻上一次的点击坐标。
说通俗点,BrowserBC 就像一个 Agentic 时代的“按键精灵”。
传统的按键精灵录制的是写死的鼠标坐标和按键序列,页面布局一变,整个脚本就废了。而 BrowserBC 录的不是坐标,是一整套“该做什么、怎么算做完”的技能逻辑。它能被另一个模型读懂,能在变了样的页面上随机应变,还能被不断合并、复用。它就是那种会“理解”、能迁移、还能直接交给别人用的按键精灵。
这恰恰揭示了 BrowserBC 的核心思想:技能从哪里来,和技能由谁来执行,可以彻底分开。
人在浏览器里把路趟一遍,系统就将其转写成技能;之后照着技能把同类任务做完的,可以是另一个更便宜的模型。技能一旦变成自然语言,就能在不同模型间自由地传递、复用和组合。这正是通向“通用网页浏览”的关键一步:把人类每天的浏览器行为,蒸馏下来教给 Agent 去做。
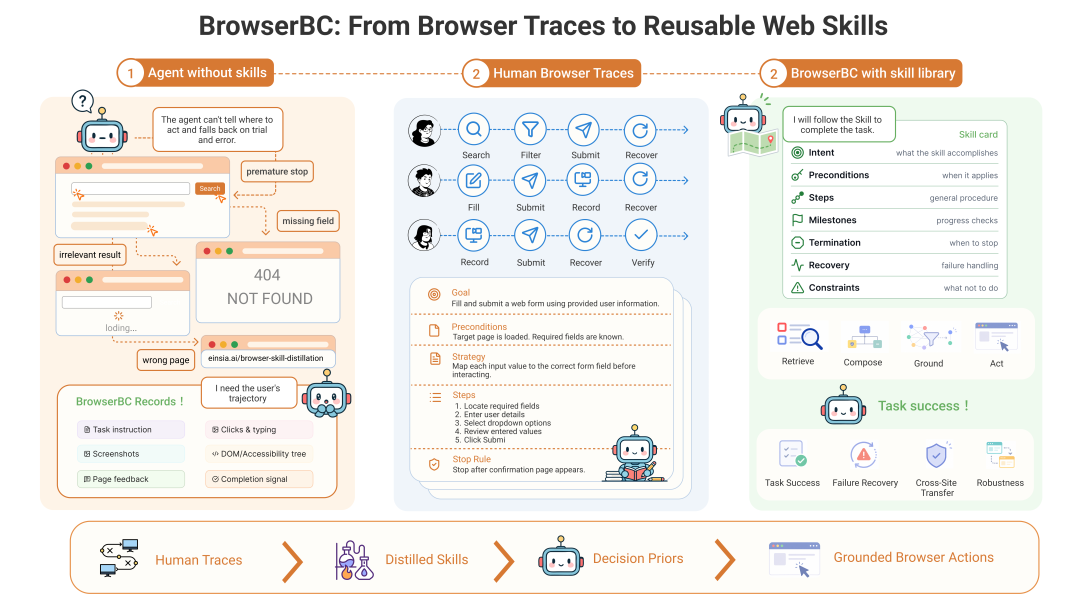
BrowserBC 把人类的浏览器操作轨迹蒸馏成可复用的自然语言技能,为 Agent 提供访问陌生网站时的“决策先验”。
项目与论文地址:
人类录一次,Agent 就能照着做
研究团队录制了一个很常见的任务:旅行前预订民宿。过程是在预订网站输入时间、地点、人数,按评分和评分数筛选,并排序找出最优选项。这任务看起来不难,许多小模型却经常栽在它上面——并非不理解任务,而是不知道怎么用筛选功能,或者干脆凭空捏造虚构信息假装完成。
第一步,录制。研究团队让人完整做一遍:进入网站 → 输入时间地点人数 → 应用筛选器 → 通读所有结果 → 找到最佳选项。整个过程被原样录下。
第二步,转写成 Skill。系统把这段操作提炼成一张“技能卡”,而不是坐标回放。卡上记录的是这类任务的通用门道:
- 意图:在预订网站找到最佳住宿选项。
- 关键步骤:先写基本信息,搜索后逐项应用筛选器(这正是小模型最容易卡壳的地方)。
- 完成判据:最终输出可人工核查的结果。
- 要避免的坑:网站自带筛选器可能与用户真实需求有偏差,必要时需自行编写脚本筛选。
第三步,交付给一个小模型执行。没有这张卡片时,小模型要么跌跌撞撞卡死,要么直接输出幻觉;拿到卡片后,它立刻明白该输入什么、校验哪个界面、哪些依赖网站自身功能、哪些需要自己判别——于是任务被稳定地完成了。
就这样,BrowserBC 把“操作浏览器”这个日常动作,变成了 Agent 可以复用的技能。人把路打通一次,系统写成说明书,Agent 负责照着说明书把同一条路走顺。
这条路天然具备可复用和可扩展性。人类访问网站的分布遵循幂律定律:常用站点占据了大部分访问量,用的人越多,Skill 库就越完备。更重要的是,对于稀疏的长尾网站,BrowserBC 让人们再也不必苦等那些陈旧的网站自己来提供官方的 Agent 接口了。现实是,大量老网站永远不会专门为 Agent 开放一套干净接口,而 BrowserBC 则直接复用人类在为人设计的那套界面上积累的操作经验。一个网站能不能被 Agent 高效访问,不再取决于网站方是否愿意配合,而在于有没有人已经在这个网站上走过通路。这便是“通用”二字的底气。
如何将一次操作转写成能用的 Skill,并有效管理
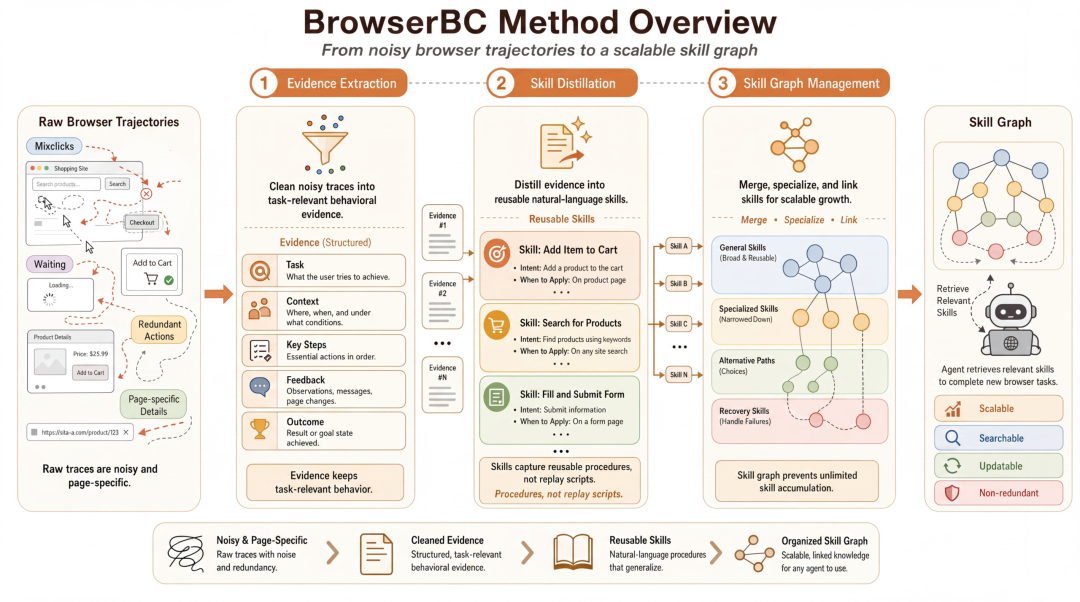
BrowserBC 将嘈杂的浏览轨迹清洗、蒸馏为可复用的自然语言技能,并组织成可扩展的技能图,最后检索相关技能指导 Agent 完成新任务。
BrowserBC 的方法论主要回答两个问题:一段操作该如何总结,以及总结出的成千上万个 Skill 该如何管理。
问题一:如何转写,以及要特别注意什么?
原始浏览器轨迹通常非常嘈杂,充满误点击、无意义等待、重复尝试和临时页面状态,还可能夹带隐私信息。因此,转写前必须先清洗,并按语义将轨迹切分成连贯的子过程。
每一段轨迹会被抽取成一份“证据”,保留任务指令、操作前后页面状态、关键步骤、页面反馈和成败信号。随后,这份证据被转写成结构化的自然语言 Skill 卡,用固定字段阐明“该做什么、怎么判断进展、怎么算完成、失败了怎么办”,以及它从哪来、在什么场景下适用。这样一张卡,既能直接喂给语言模型作上下文,又方便人工审阅修改。
这里有一个最核心的原则:只保留“可迁移的过程性知识”,剥离“会变、会泄露的细节”。
- 要剥掉的:精确坐标、DOM 选择器、临时 ID、登录态、隐私文本,以及任何指向具体答案或评测标准的内容。
- 要留下的:语义层面的“该做什么、怎么判断进展、怎么算完成”。
举个例子,一张“填表单”技能卡写的是“按语义标签找到对应字段、把任务给定的值原样填进去、提交后确认页面出现成功状态”,而不是“点 (x, y)、再点那个 id 是某串字符的按钮”。原因很直接:网页天天变,布局、代码结构、版本、登录态都会变,克隆坐标和选择器极其脆弱,而克隆“做什么 + 怎么判断完成”才真正能够迁移。
另外,一条成功轨迹足以蒸出一个可用技能;而融合同一任务的多次尝试(含失败),则能让技能更稳健——成功运行强化执行步骤,失败运行则暴露缺失的前置条件,催生出显式的恢复策略。同时,转写时还必须做一遍泄露检查,确保技能卡只记过程,不夹带具体答案。
问题二:Skill 怎么管理?
如果每条轨迹都产生一个互不相关的技能,库很快就会失控,变得重复、冗余甚至互相冲突。
BrowserBC 的做法是把库组织成一张技能图。每当产生一个候选技能,系统会判断该将其新增为一个独立节点,还是合并进已有技能,或是登记为某个更通用技能的特化版本。
- 当两个技能在意图、前置条件、步骤、效果、终止证据上彼此相容时,就合并。
- 当它们适用条件不同、需要的信息不同,或约束互相冲突时,就保持分开。
图中的节点是技能,边是技能间的关系——时间依赖、特化、同一子目标下的替代方案、以及同一状态下的互斥。这样一来,一个通用过程(如“填表单”)可以连接到它的各种特化(支付、改资料)和对应的失败恢复技能,而不必把它们压成扁平的独立条目。
这张图带来了三个关键价值,也正是 BrowserBC 所谓可扩展的真正含义:将重复的演示合并成可复用节点,而非无限堆砌样本;让检索和更新只动相关局部区域;支持增量精炼——新来一条轨迹,只更新受影响的技能及其邻居。这张图的核心作用是“组织”:学习和复用的基本单元始终是那张自然语言技能卡,而图则让这些卡片被有序地存放、检索和更新,这是技能库能持续扩张而不失控的关键。
在 人工智能 驱动的执行端,检索也被刻意做得很轻量:通过语义相似度挑出一小撮相关技能,塞进 Agent 的上下文,剩下的落地操作交给 Agent 自己读取当前页面来完成。技能既不是可执行脚本,也不是要硬套的演示,它只提供一个决策先验,而每个具体动作仍需 Agent 根据当前页面实时决定。
实验与讨论:技能带来跨基准、跨站点的一致提升
BrowserBC 首先在 WebArena-Hard 上接受检验:258 个经人类核验的任务,覆盖 GitLab、电商及其后台、论坛、跨站点组合等各类站点。实验严格控制变量,唯一变量是是否注入 BrowserBC 检索到的 Skill。结果是:基线 Agent 成功率 60.5%(156/258),注入技能后提升至 81.4%(210/258),绝对提升 20.9 个百分点,挽回了原本失败的 54 个任务。
更严苛的考验来自 ClawBench 基准:152 个任务全部运行在真实的线上网站,页面布局和操作流程会在不同运行间变化,且以写操作任务为主,彻底排除了“靠记忆取巧”的可能。在这种情况下,无技能基线仅解出 32.9%(50/152)的任务,注入技能后解出 68.4%(104/152),成功率提升 35.5 个百分点,几乎把解出的任务数翻了一倍,且在全部八个类别上普遍成立。
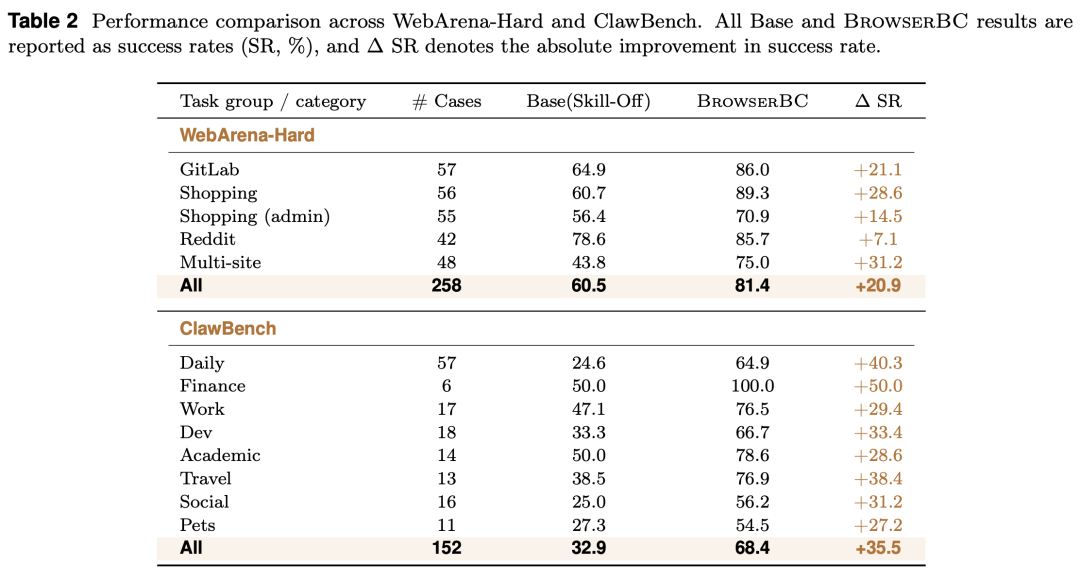
BrowserBC 在 WebArena-Hard 与 ClawBench 上的性能表现。
技能不仅提升了成功率,还缩短了交互路径。在 WebArena-Hard 任务上,Agent 的平均工具调用次数从 31.2 次降到 22.7 次,减少 27.3%,这与“技能作为流程先验”的定位完全一致。
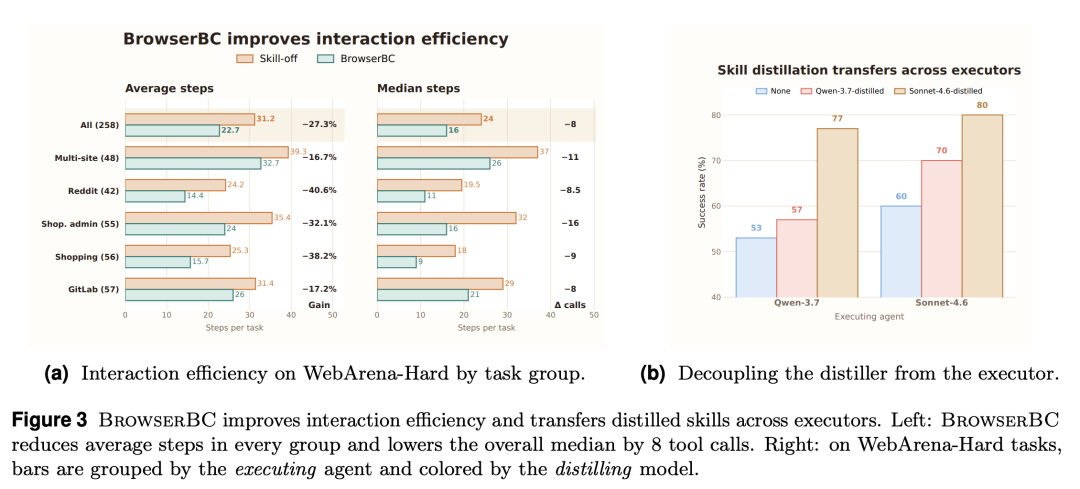
BrowserBC 既能提升交互效率,又能让蒸馏出的技能在不同模型间迁移。
讨论一:Skill 是一份“带置信度的先验”,不是一条命令。 在 WebArena-Hard 上,如果强制 Agent 逐字照搬技能,成功率只剩 77.5%;而允许 Agent 选择性使用,并以当前页面为准,成功率才达到 81.4%。约 3.9% 的任务里,盲目照搬技能反而把能做对的题做错了。这强有力地说明:自然语言技能的价值在于“提示策略”,落地执行永远要交给模型去读当前页面。
讨论二:技能是“蒸馏一次、便宜复用”的模型无关对象。 研究团队将蒸馏技能与执行技能的模型交叉组合。结论是:技能质量主要取决于蒸馏阶段,用强模型蒸馏出的技能能同时大幅提升多个不同执行器的成功率;并且,高质量技能能跨执行器迁移,装备了强模型技能的小 Agent,表现可逼近大 Agent,直接坐实了“蒸馏一次、便宜复用”的设想。
讨论三:剩下的难点在“执行”而非“缺知识”。 对失败案例的审计发现,瓶颈大多在执行精度:长表单漏填字段、目标对象歧义、长程任务耗光预算、模型自身推理“跑飞”。技能本身正确,也用上了,限制因素是“按照流程执行的保真度”——即底层模型本身的能力。这也划出了小模型执行的可行边界:技能能补“该怎么做”,补不了“手稳不稳”。
讨论四:迁移到浏览器之外。 论文在 30 个 OSWorld 风格的 Ubuntu 桌面任务上做了诊断性迁移研究。结果显示,过程性先验确实能跨过浏览器边界发挥作用。真正可迁移的不是浏览器专属的动作序列,而是那份关于前置条件、语义状态转移、进度里程碑、失败恢复的先验知识。当任务缺的是“流程结构”时,技能最有用;当缺的是底层 GUI 交互精度,或被错误的先验带偏时,技能则帮不上忙。
从能用到好用:BrowserBC 的启发

BrowserBC 不是一个炫技的方法。它真正重要的地方在于,指出了人类浏览器轨迹的巨大价值:这是人类群体在信息迷宫中走出的高效路径。BrowserBC 所做的事,就是将这些隐含经验的轨迹,蒸馏成 Agent 可用的 Skill。
它带来的核心启发有三点:
- 第一,提升 Agent 的浏览器使用能力,关键是为它补齐完备的网页逻辑知识。
- 第二,人类与虚拟世界的交互过程,本身就是一种尚未被充分利用的宝贵数据资源。
- 第三,如果这些轨迹可以被持续蒸馏和管理复用,Agent 就能从“会操作网页”,逐渐走向“高效操作网页”。
所以,BrowserBC 的核心不是教 Agent 点击网页——它是在信息不完备的环境里,用人类轨迹为 Agent 补上决策所需的先验。
从更深的层次看,真正决定 Web Agent 性能上限的,从来不是“能否复现某个操作流程”,也不是“能否快速搭建一个可运行的系统”,而是是否真正构建了可以持续积累、可复用、可迁移的经验结构。这或许就是让 Web Agent 从能用走向好用的临门一脚。在 开源实战 中,像 BrowserBC 这样热门的开源项目,正通过代码开源和社区协作,加速将这种思想转化为可落地的工具。
 发表于 昨天 23:26
|
查看: 4|
回复: 0
发表于 昨天 23:26
|
查看: 4|
回复: 0
