在多年基于SparkStreaming的大数据流处理开发实践中,除了Kafka,Redis是使用最为频繁的组件。目前生产环境中维护着多个Redis集群,其中最大的一个32节点集群,其Key数量已达40亿,峰值QPS更是高达2000万。
在流处理架构中,Redis主要扮演两种角色:
- 作为离线更新的维表数据存储,用于丰富流数据的维度信息。
- 作为应用实时状态数据的存储。
无论哪种场景,最终在SparkStreaming中都需要与Redis进行频繁的get、set交互。假设RDD的批处理间隔为1分钟,那么该窗口内的数据必须在1分钟内完成计算才算“无延迟”。当出现计算延迟时,如果问题不在与Redis的交互上,通常增加计算核心、内存或提高并行度即可解决。
然而,在开发一个数据量达1亿/分钟的SparkStreaming应用时,我们发现计算延迟的根源很可能在于与Redis的交互耗费了过多时间。此时,单纯增加计算资源收效甚微,必须从应用层与Redis的交互方式上进行深度优化。
应用层性能优化策略
很多时候,我们对已部署的Redis服务本身进行参数调优的空间有限,重启集群更是可能影响生产。因此,优化重点自然落在了应用侧代码上。
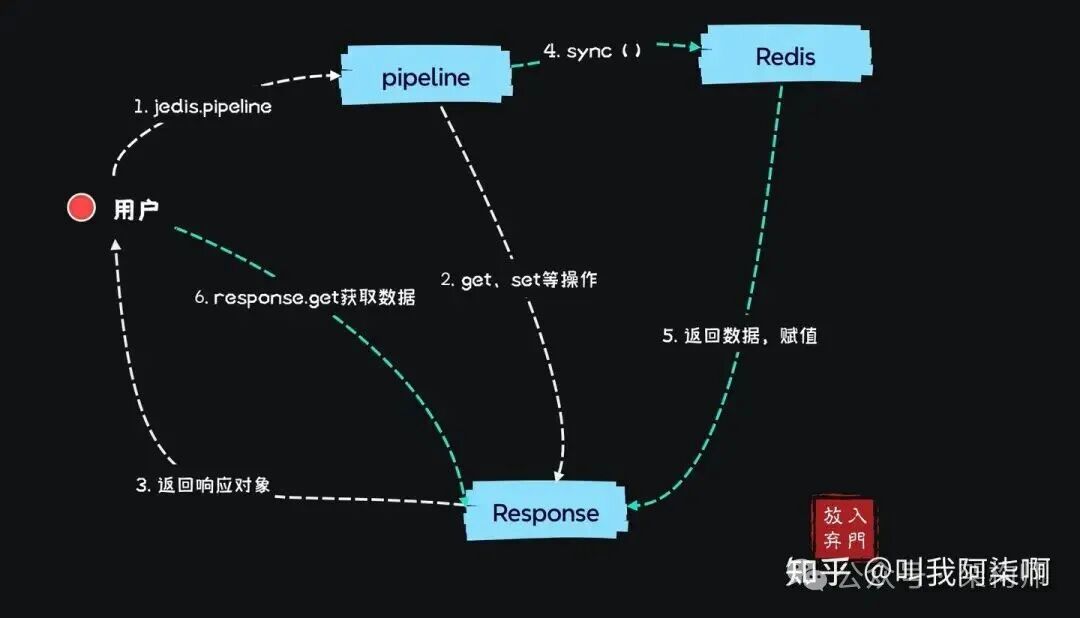
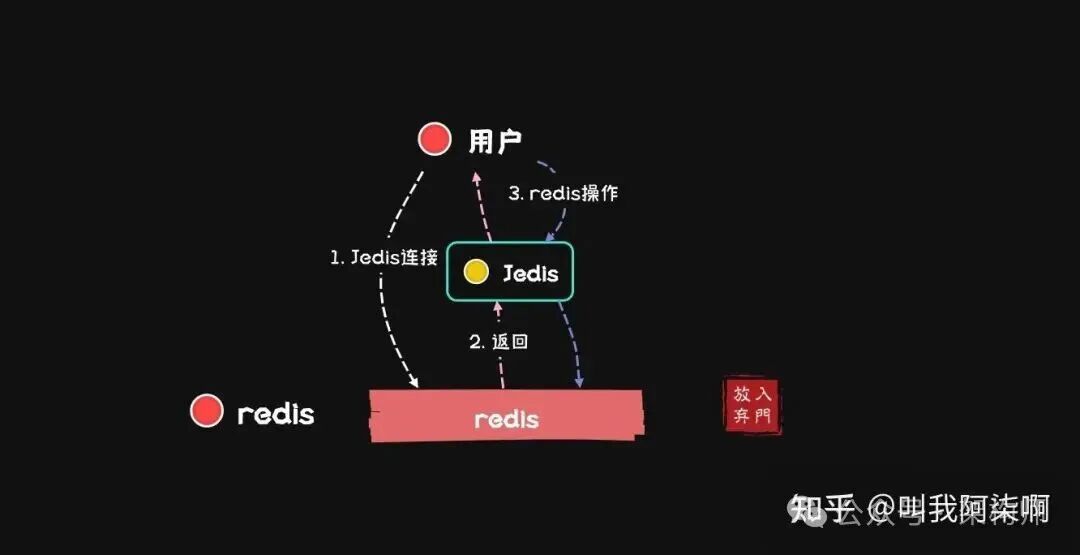
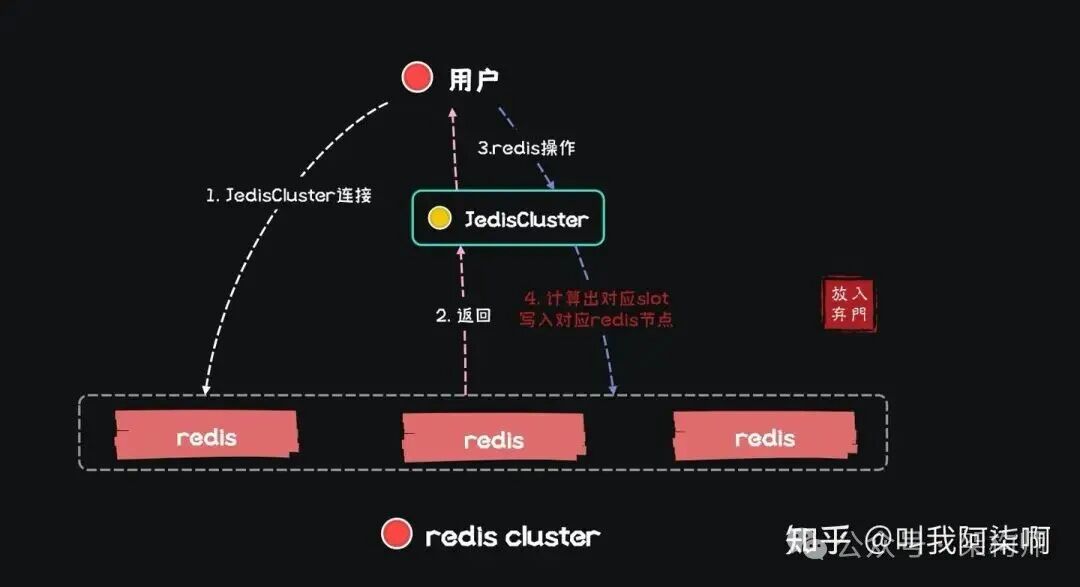
应用与Redis服务的数据交互过程大致如下图所示:
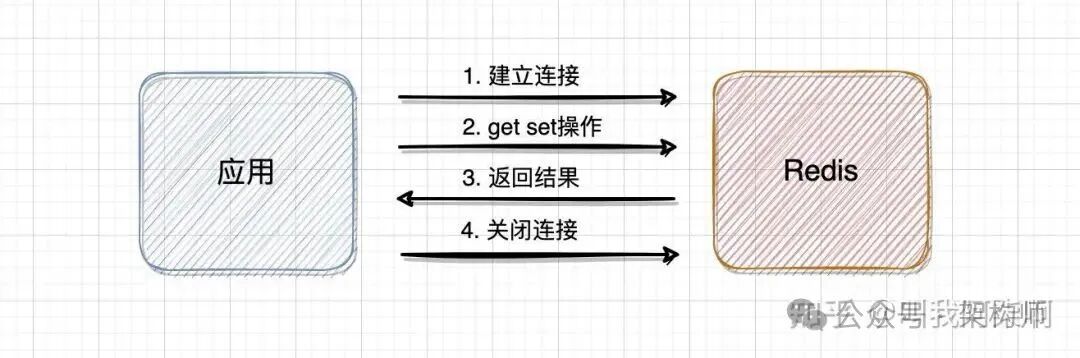
1. 使用连接池
在Java生态中,Jedis是与Redis交互的常用客户端。如果每次操作都新建一个Jedis连接,意味着每次都要经历TCP三次握手建立连接,关闭时又要四次挥手,内网环境下虽快,但在海量数据请求面前,这种开销不可忽视。因此,保持长连接是必要的。
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(10);
poolConfig.setMinIdle(5);
poolConfig.setMaxIdle(8);
JedisPool jedisPool = new JedisPool(poolConfig, "localhost", 6379);
Jedis jedis = jedisPool.getResource();
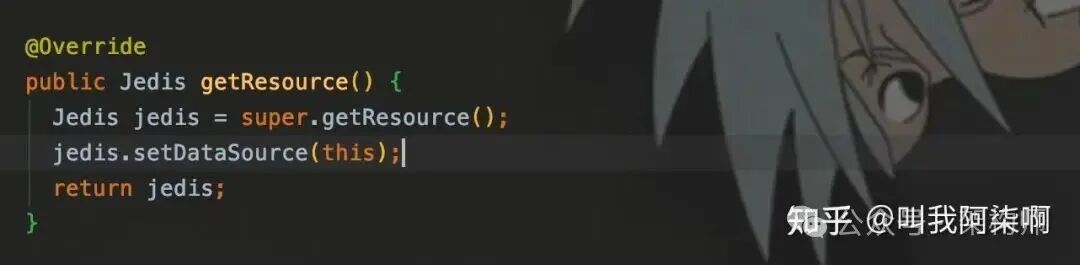 调用
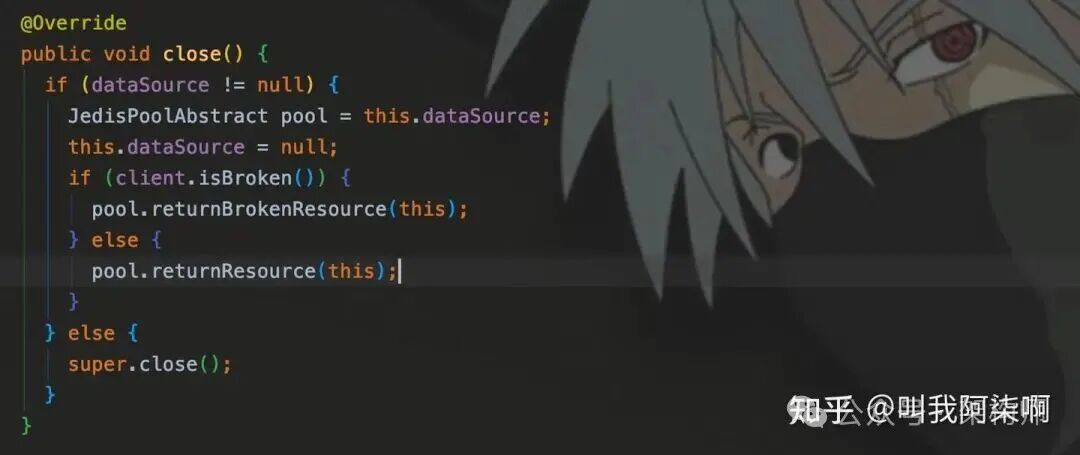
调用close()方法时,会判断dataSource。如果为null则直接断开连接;若连接来自连接池,则会将Jedis实例归还给JedisPool。
2. 批处理 (Batch)
批处理是大数据领域的通用优化思路,其核心是通过减少通信次数来提升效率。
- Kafka Producer:通过
batch.size参数控制一次发送的消息条数,并结合linger.ms参数保证在数据量不足时的发送实时性。
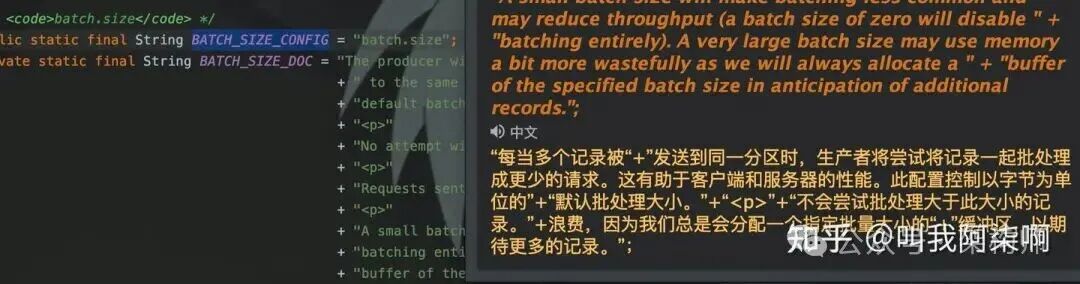

- Flume:配置文件中的
batchSize参数同样用于控制source到channel或sink从channel取数据的批次大小。

那么,我们能否将多个Redis的set、get操作打包成一个批次提交呢?
3. Pipeline 管道技术
Jedis提供了Pipeline模式,允许一次性提交多个操作命令,然后通过手动执行sync()统一发送到Redis并获取结果。结合连接池,使用示例如下:
Jedis jedis = jedisPool.getResource();
Pipeline pipeline = jedis.pipelined();
Response<String> res1 = pipeline.get("aa");
Response<String> res2 = pipeline.get("bb");
// 此处也可以执行set、hmget等其他命令
pipeline.sync();
String s1 = res1.get();
String s2 = res2.get();
从jedis.pipelined()创建管道到执行sync()发送命令期间,可以堆积多个不同的Redis命令。与直接使用Jedis返回String不同,Pipeline执行命令返回的是泛型为String的Response对象。
Response数据回填机制:
这与NIO中的Future概念相似。执行pipeline.get(key)后,命令并未立即发送,因此只能返回一个Response对象作为占位符。当执行sync()将请求真正发送到Redis后,返回的结果才会被回填到对应的Response对象中。
 只有
只有sync()之后,Response中才会有数据,可以通过调试直观看到这一过程。
调试验证:
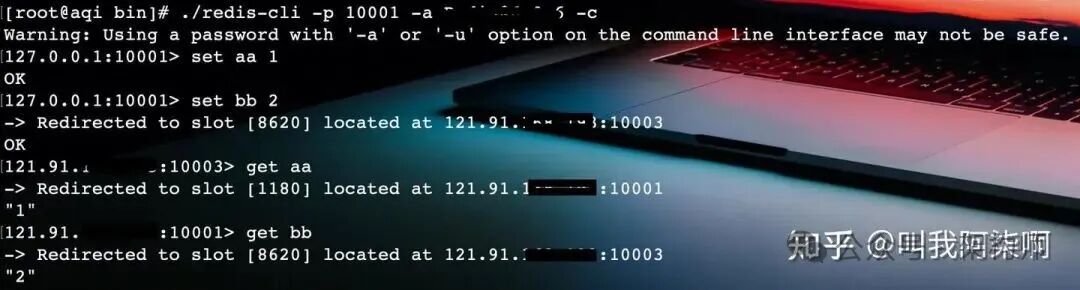
使用Docker启动一个四主四从的Redis Cluster(端口10001-10008)。
 通过
通过redis-cli(注意集群模式需加-c参数)设置两个Key。
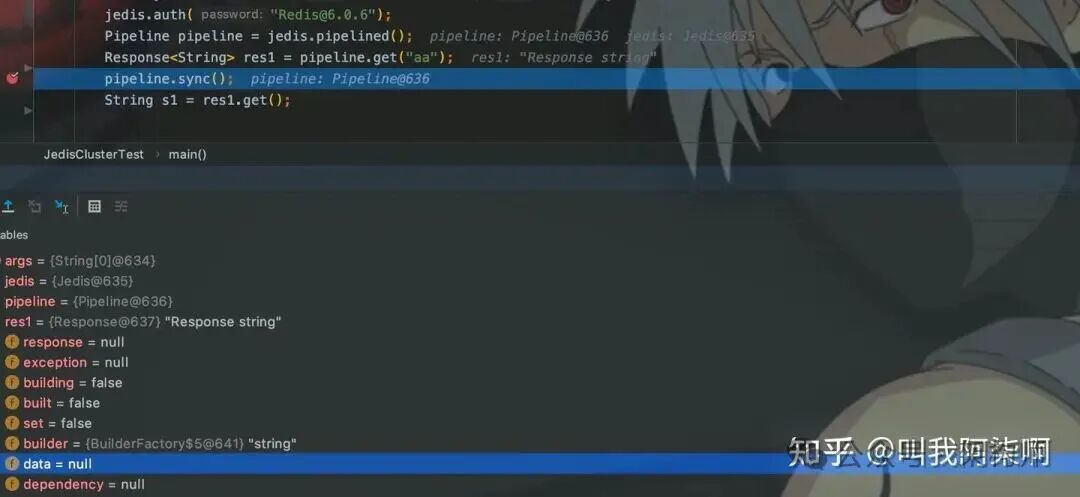
 使用Jedis连接10001节点,并通过Pipeline获取Key。
使用Jedis连接10001节点,并通过Pipeline获取Key。
Jedis jedis = new Jedis("121.91.xxx.xx", 10001);
jedis.auth("1qaz@WSX");
Pipeline pipeline = jedis.pipelined();
Response<String> res1 = pipeline.get("aa");
pipeline.sync();
String s1 = res1.get();
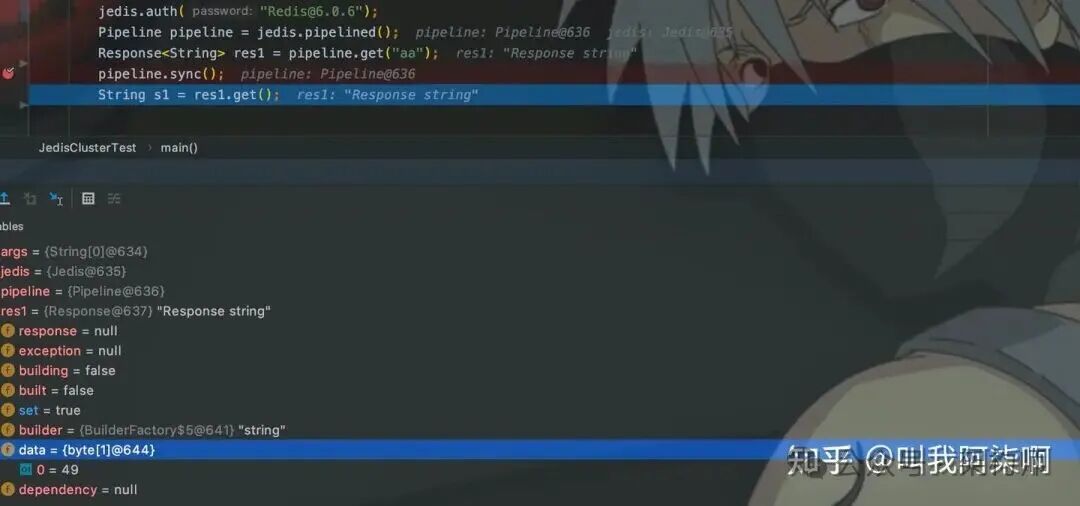
在sync()处设置断点进行调试,可以看到执行前response.data为null,执行后其值被回填(‘1’的ASCII码为49)。
在SparkStreaming开发中,通常将批次大小设置为256或512,即一次通过Pipeline提交256或512条命令。
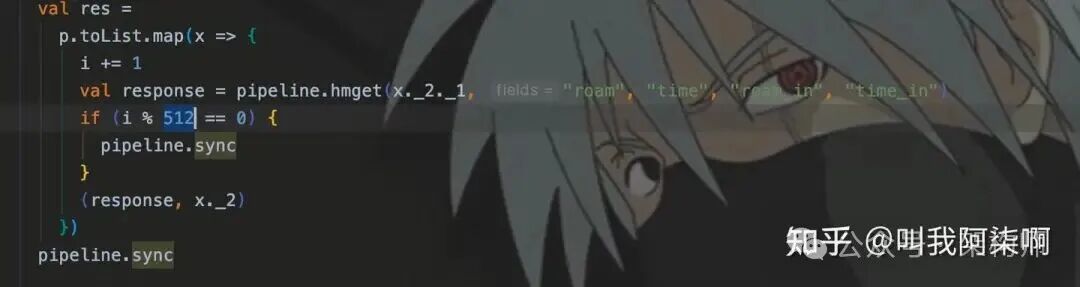 具体数值可根据返回Value的大小或请求类型进行评估。
具体数值可根据返回Value的大小或请求类型进行评估。
然而,Pipeline的本质是与单个Redis实例建立一个通道进行批量通信,因此它仅适用于Jedis客户端。 要理解这一点,需要从Redis的常见架构说起。
Redis架构与Pipeline的适配挑战
Redis有单点、主从哨兵、集群等多种部署模式。在生产环境,尤其在大数据场景下,集群模式最为常见。通常所说的集群默认指Redis官方的Cluster模式,但在多年实践中,豌豆荚开源的Codis曾因其易用性备受青睐,可惜已停止维护。
为什么强调Pipeline仅针对Jedis?这需要从Redis的数据分布架构说起。Redis将所有数据划分为16384个槽位(slot),每个Key通过计算都会落在其中一个slot上。
单点模式
在单点模式下,所有16384个slot都在同一个节点上。使用Jedis直连该节点即可,Pipeline可以正常工作。
Jedis jedis = new Jedis("ip", 10001);
Pipeline pipeline = jedis.pipelined();
Response<String> res1 = pipeline.get("aa");
Response<String> res2 = pipeline.get("bb");
pipeline.sync();
记住关键点:Jedis客户端设计用于连接单个Redis服务实例。
而在Cluster模式下,集群中的多个节点会均匀分摊这16384个slot。这就带来了问题:一个Key应该放在哪个slot?这个slot又在哪个节点上?这是集群模式使用Pipeline必须面对的问题。
Codis 架构
Codis架构分为Codis Proxy代理层和Server存储层。
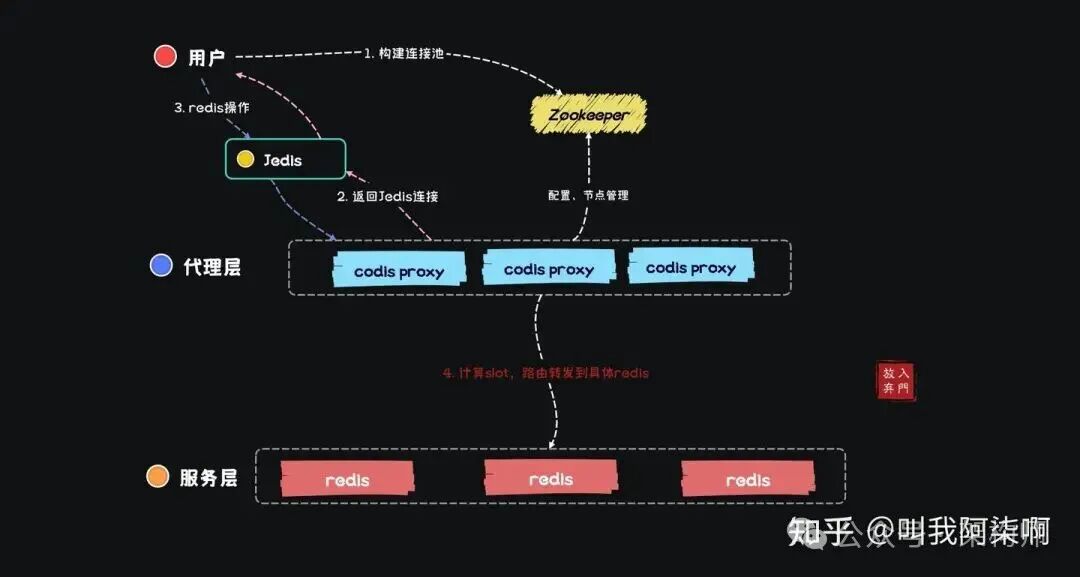 Proxy层让整个Codis集群对外表现得像一个“大的单点Redis”,并实现了Redis协议,因此用户可以直接使用Jedis连接Proxy。底层的多个Redis实例(Server层)对用户透明,slot均匀分布在这些实例上,由Proxy负责计算Key的slot并路由到正确的Redis节点。用户无需关心细节,可以像使用单点Redis一样使用Jedis和Pipeline。
Proxy层让整个Codis集群对外表现得像一个“大的单点Redis”,并实现了Redis协议,因此用户可以直接使用Jedis连接Proxy。底层的多个Redis实例(Server层)对用户透明,slot均匀分布在这些实例上,由Proxy负责计算Key的slot并路由到正确的Redis节点。用户无需关心细节,可以像使用单点Redis一样使用Jedis和Pipeline。
val poolConfig = new JedisPoolConfig
val poolx: JedisResourcePool = RoundRobinJedisPool.create()
.curatorClient(redisHost, 30000)
.zkProxyDir("/jodis/" + database)
.poolConfig(poolConfig)
.timeoutMs(60000)
.build()
val jedis: Jedis = poolx.getResource
Redis Cluster 架构
与Codis类似,Redis Cluster也由多个实例组成,slot均匀分布。不同之处在于,Redis Cluster没有独立的Proxy层,存储层直接暴露给用户。如上所述,Jedis只能连接单个节点。
如果使用Jedis连接到Cluster中的某一个节点,那么它只能操作该节点所负责的slot上的Key。例如,Key aa可能位于10001节点,Key bb位于10003节点。用Jedis连接10001节点去获取bb,将会直接报错。
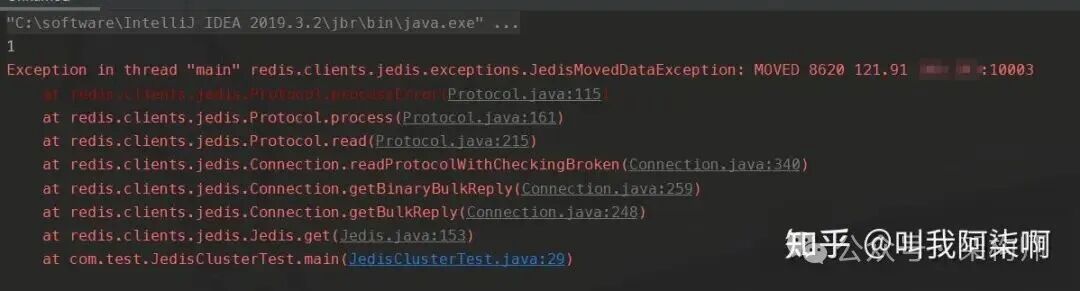 因此,官方提供了
因此,官方提供了JedisCluster客户端来操作整个集群。
HashSet<HostAndPort> jedisClusterNodes = new HashSet<>();
jedisClusterNodes.add(new HostAndPort("121.91.xx.xxx", 10001));
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(-1);
config.setMaxIdle(-1);
config.setMaxWaitMillis(1000);
JedisCluster cluster = new JedisCluster(jedisClusterNodes, 1000, 1000, 10, "1qaz@WSX", config);
cluster.get("aa");
cluster.get("bb");
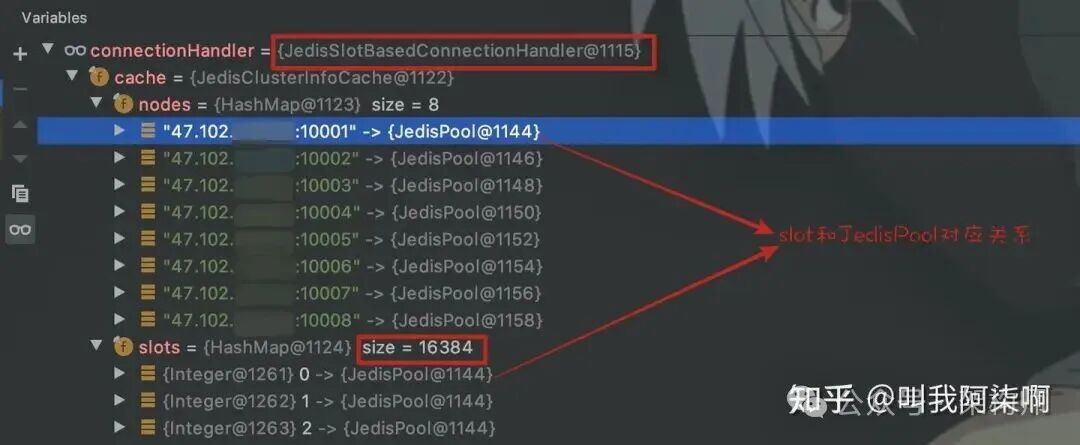
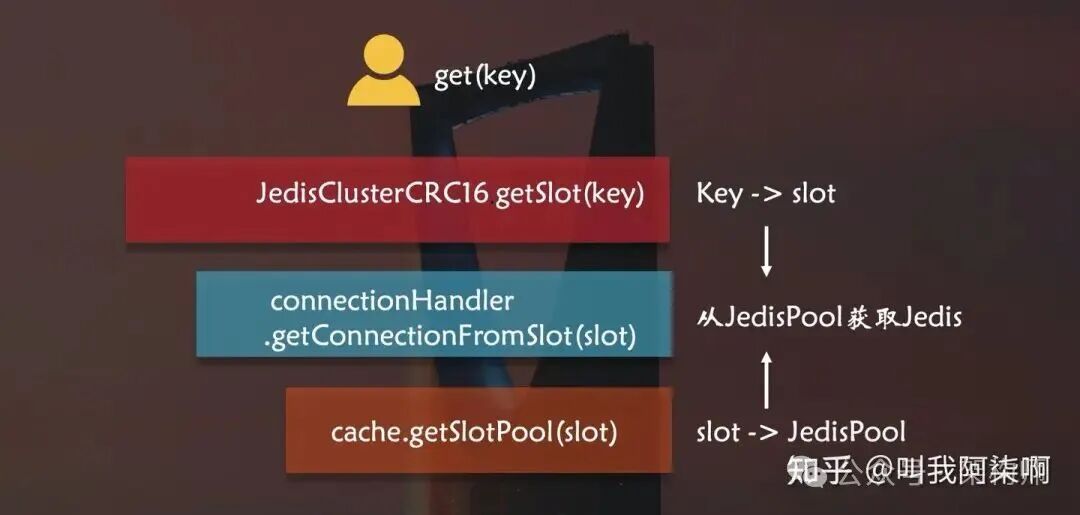
JedisCluster的工作原理:
- 连接管理:
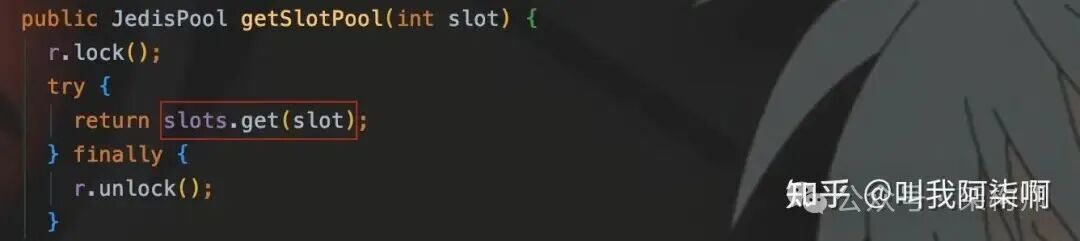
JedisCluster在初始化时,其内部的connectionHandler会为集群中每个Redis节点创建一个JedisPool,并构建一个映射表,将16384个slot与对应的JedisPool关联起来。
-
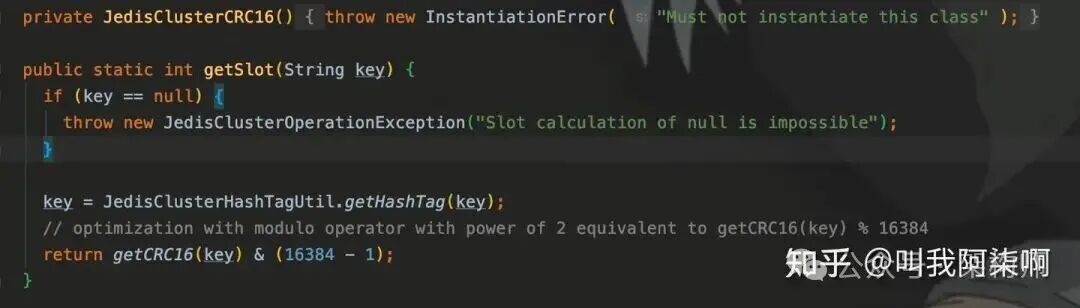
Key路由:每次执行操作前,JedisCluster会通过JedisClusterCRC16.getSlot(key)计算Key所在的slot。
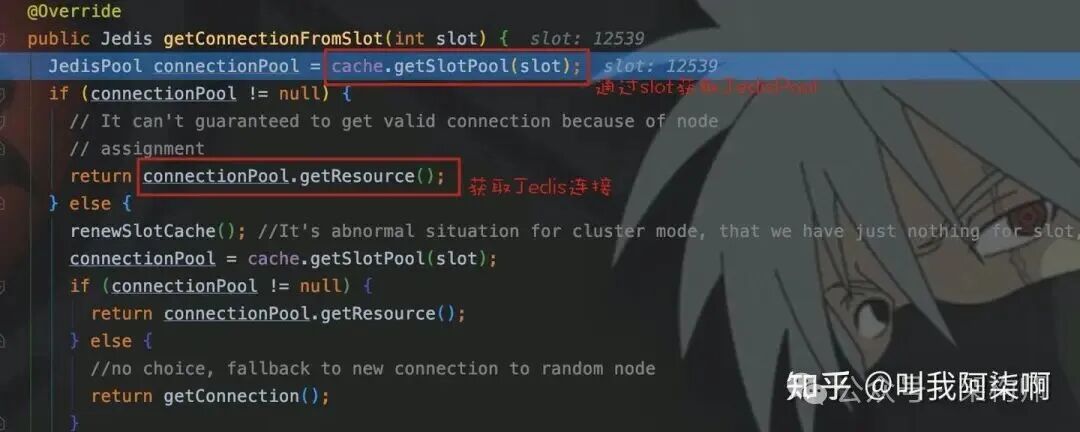
 然后调用
然后调用getConnectionFromSlot(slot),根据slot从映射表中获取对应的JedisPool,进而拿到一个具体的Jedis连接来执行命令。
由于JedisCluster面向的是整个集群,并未向用户暴露底层单个Jedis对象,因此原生的JedisCluster不支持Pipeline操作。在处理每分钟上亿条数据的大数据场景时,与Redis Cluster的交互瓶颈成为了棘手的性能问题。
Redis Cluster的Pipeline替代方案与自定义实现
在从Codis迁移到Redis Cluster的初期,我们尝试了多种方案来缓解交互延迟:
-
Lettuce客户端:另一个流行的Redis客户端,支持异步操作,类似于Pipeline。
RedisURI uri = RedisURI.builder()
.withHost("47.102.xxx.xxx")
.withPassword("1qaz@WSX".toCharArray())
.withPort(10001)
.build();
RedisClusterClient client = RedisClusterClient.create(uri);
StatefulRedisClusterConnection<String, String> connect = client.connect();
RedisAdvancedClusterAsyncCommands<String, String> async = connect.async();
async.set("key1", "v1");
async.set("key2", "v2");
async.flushCommands();
Thread.sleep(1000 * 3);
connect.close();
client.shutdown();
但经实测,其效率提升仍未达到理想状态。Redisson客户端测试结果也不甚理想。
-
自定义JedisCluster Pipeline:最终,我们基于JedisCluster自行实现了一套Pipeline客户端,并在生产环境中取得了显著的性能提升。
实现思路:
关键在于JedisCluster内部用于维护slot-节点映射的cache对象是protected修饰的,这意味着可以被继承访问。
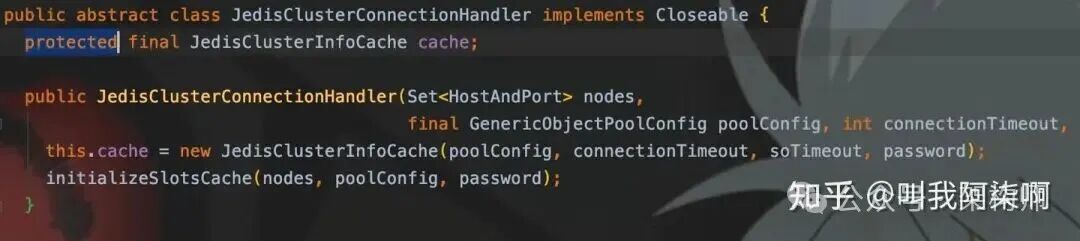 通过子类,我们可以获取到slot与
通过子类,我们可以获取到slot与JedisPool的映射关系(即slots数组)。
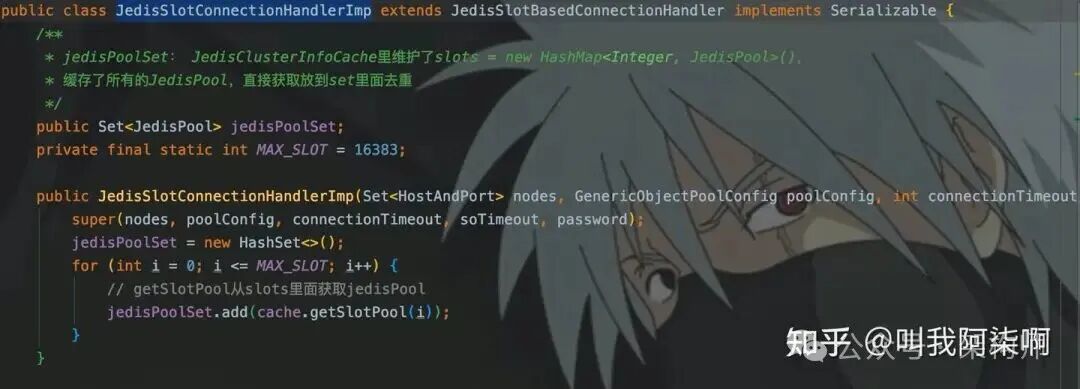 基于此,我们建立了几层映射关系来实现针对每个Redis节点的Pipeline:
基于此,我们建立了几层映射关系来实现针对每个Redis节点的Pipeline:
Map<JedisPool, Jedis>:根据Key计算slot,找到对应的JedisPool,并从中取出(或创建)一个唯一的Jedis连接。确保一个Redis实例只有一个Jedis用于Pipeline。Map<Jedis, Pipeline>:确保每个Jedis实例只开启一个Pipeline,该实例上所有Key的操作都通过这个管道进行。Map<Pipeline, Integer>:记录每个Pipeline中累积的命令数量,当达到预设的批次阈值(如256)时,自动触发sync(),将命令批量发送至Redis。
这一思路的核心是将发往不同Redis节点的命令,分别归集到与各节点对应的Pipeline中,最后统一提交。基于此理论,我们使用Java和Scala开发了适配SparkStreaming的JedisCluster Pipeline组件,有效解决了数据库/中间件交互瓶颈。
总结与展望
以上是笔者在多年大数据开发中积累的关于Redis使用的部分经验。除了连接池、批处理、Pipeline以及针对集群架构的客户端选型与自定义外,Redis的性能优化还有很多维度,例如Hash数据结构中Field与Value的合理设计、内存优化配置等。
近期,陪伴团队七年之久的Codis因无法通过升级修复安全漏洞而正式下线。尽管向Redis Cluster的迁移工作早已启动,此刻也不免感慨技术的迭代与变迁。性能优化之路永无止境,需要根据实际的业务场景与技术架构不断探索与实践。
 发表于 2025-12-13 14:50:29
|
查看: 279|
回复: 0
发表于 2025-12-13 14:50:29
|
查看: 279|
回复: 0
