1. Redis集群连接池与通用对象连接池源码解析
在高并发系统中,高效、稳定地使用Redis是保障性能的关键。理解连接池的工作原理,特别是与Redis集群的交互方式,是进行架构设计与优化的基础。
1.1 Spring的RedisConnectionFactory与JedisConnectionFactory
在Spring Boot项目中,我们通常通过RedisConnectionFactory来配置Redis连接。JedisConnectionFactory是其一个常用实现,负责创建和管理底层的Jedis连接。
@Data
@Configuration
@ConditionalOnClass(RedisConnectionFactory.class)
public class RedisConfig {
...
@Bean
@ConditionalOnClass(RedisConnectionFactory.class)
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setDefaultSerializer(new StringRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
...
}
RedisConnectionFactory接口定义了获取不同类型Redis连接的方法:
public interface RedisConnectionFactory extends PersistenceExceptionTranslator {
RedisConnection getConnection();
RedisClusterConnection getClusterConnection();
RedisSentinelConnection getSentinelConnection();
}
JedisConnectionFactory在获取连接时,会判断是否使用连接池,并从池中获取或直接创建新的Jedis对象。
public class JedisConnectionFactory implements InitializingBean, DisposableBean, RedisConnectionFactory {
private @Nullable Pool<Jedis> pool;
...
public RedisConnection getConnection() {
if (isRedisClusterAware()) {
return getClusterConnection();
}
Jedis jedis = fetchJedisConnector();
JedisConnection connection = (getUsePool() ?
new JedisConnection(jedis, pool, getDatabase(), getClientName())
: new JedisConnection(jedis, null, getDatabase(), getClientName()));
connection.setConvertPipelineAndTxResults(convertPipelineAndTxResults);
return postProcessConnection(connection);
}
protected Jedis fetchJedisConnector() {
try {
if (getUsePool() && pool != null) {
// 从连接池中获取资源
return pool.getResource();
}
Jedis jedis = createJedis();
jedis.connect();
potentiallySetClientName(jedis);
return jedis;
} catch (Exception ex) {
throw new RedisConnectionFailureException("Cannot get Jedis connection", ex);
}
}
...
}
1.2 Jedis的Pool对象:基于Apache Commons通用对象池
Jedis中的Pool类是其连接池的抽象,其内部依赖于Apache Commons Pool库的GenericObjectPool。
public abstract class Pool<T> implements Closeable {
// internalPool就是Apache Commons的通用对象池
protected GenericObjectPool<T> internalPool;
public T getResource() {
try {
return internalPool.borrowObject();
} catch (NoSuchElementException nse) {
...
}
}
}
// 以ShardedJedisPool为例,它用于连接由多个Redis节点组成的集群(客户端分片)
public class ShardedJedisPool extends Pool<ShardedJedis> {
...
@Override
public ShardedJedis getResource() {
ShardedJedis jedis = super.getResource();
jedis.setDataSource(this);
return jedis;
}
...
}
1.3 Apache Commons通用对象池的borrowObject()方法
GenericObjectPool.borrowObject()方法是获取对象的核心。它会优先从空闲队列中获取对象,如果队列为空,则调用factory.makeObject()创建新对象。
public class GenericObjectPool<T> extends BaseGenericObjectPool<T> implements ObjectPool<T>, GenericObjectPoolMXBean, UsageTracking<T> {
// 存放空闲对象的队列
private final LinkedBlockingDeque<PooledObject<T>> idleObjects;
...
public T borrowObject(final long borrowMaxWaitMillis) throws Exception {
assertOpen();
...
PooledObject<T> p = null;
final boolean blockWhenExhausted = getBlockWhenExhausted();
boolean create;
final long waitTime = System.currentTimeMillis();
while (p == null) {
create = false;
// 从空闲队列中获取对象
p = idleObjects.pollFirst();
if (p == null) {
// 队列为空,创建新对象
p = create();
if (p != null) {
create = true;
}
}
...
}
updateStatsBorrow(p, System.currentTimeMillis() - waitTime);
return p.getObject();
}
private PooledObject<T> create() throws Exception {
...
final PooledObject<T> p;
try {
// 调用Factory的makeObject()方法创建对象
p = factory.makeObject();
if (getTestOnCreate() && !factory.validateObject(p)) {
createCount.decrementAndGet();
return null;
}
} catch (final Throwable e) {
createCount.decrementAndGet();
throw e;
} finally {
synchronized (makeObjectCountLock) {
makeObjectCount--;
makeObjectCountLock.notifyAll();
}
}
...
return p;
}
}
1.4 ShardedJedisFactory创建连接对象
在ShardedJedisPool中,创建连接对象的工厂是ShardedJedisFactory。它的makeObject()方法负责创建一个ShardedJedis分片对象。
public class ShardedJedisPool extends Pool<ShardedJedis> {
...
private static class ShardedJedisFactory implements PooledObjectFactory<ShardedJedis> {
private List<JedisShardInfo> shards;
...
@Override
public PooledObject<ShardedJedis> makeObject() throws Exception {
// 创建ShardedJedis对象
ShardedJedis jedis = new ShardedJedis(shards, algo, keyTagPattern);
return new DefaultPooledObject<ShardedJedis>(jedis);
}
...
}
...
}
1.5 Redis分片对象ShardedJedis的创建
一个ShardedJedis对象代表一个逻辑上的集群连接。它内部通过一致性哈希算法,管理着到各个实际Redis节点的物理连接(Jedis对象)。
public class ShardedJedis extends BinaryShardedJedis implements JedisCommands, Closeable {
public ShardedJedis(List<JedisShardInfo> shards, Hashing algo, Pattern keyTagPattern) {
super(shards, algo, keyTagPattern);
}
...
}
public class BinaryShardedJedis extends Sharded<Jedis, JedisShardInfo> implements BinaryJedisCommands {
public BinaryShardedJedis(List<JedisShardInfo> shards, Hashing algo, Pattern keyTagPattern) {
super(shards, algo, keyTagPattern);
}
...
}
public class Sharded<R, S extends ShardInfo<R>> {
private TreeMap<Long, S> nodes; // 一致性哈希环
private final Map<ShardInfo<R>, R> resources = new LinkedHashMap<ShardInfo<R>, R>(); // 分片与实际连接的映射
public Sharded(List<S> shards, Hashing algo, Pattern tagPattern) {
this.algo = algo;
this.tagPattern = tagPattern;
initialize(shards);
}
private void initialize(List<S> shards) {
nodes = new TreeMap<Long, S>();
// 为每个物理分片创建多个虚拟节点,放入一致性哈希环
for (int i = 0; i != shards.size(); ++i) {
final S shardInfo = shards.get(i);
int N = 160 * shardInfo.getWeight(); // 每个分片默认160个虚拟节点
if (shardInfo.getName() == null) {
for (int n = 0; n < N; n++) {
nodes.put(this.algo.hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
} else {
for (int n = 0; n < N; n++) {
nodes.put(this.algo.hash(shardInfo.getName() + "*" + n), shardInfo);
}
}
// 创建并保存到该分片的实际连接
resources.put(shardInfo, shardInfo.createResource());
}
}
...
}
JedisShardInfo的createResource()方法最终创建了到单个Redis节点的Jedis连接。
public class JedisShardInfo extends ShardInfo<Jedis> {
...
@Override
public Jedis createResource() {
// 封装一个Jedis对象,即到一个Redis节点的连接
return new Jedis(this);
}
...
}
1.6 ShardedJedisPool的初始化过程
ShardedJedisPool的初始化就是将配置和工厂传入,创建底层的GenericObjectPool。
public class ShardedJedisPool extends Pool<ShardedJedis> {
public ShardedJedisPool(final GenericObjectPoolConfig poolConfig, List<JedisShardInfo> shards, Hashing algo, Pattern keyTagPattern) {
super(poolConfig, new ShardedJedisFactory(shards, algo, keyTagPattern));
}
...
}
public abstract class Pool<T> implements Closeable {
protected GenericObjectPool<T> internalPool;
...
public Pool(final GenericObjectPoolConfig poolConfig, PooledObjectFactory<T> factory) {
initPool(poolConfig, factory);
}
public void initPool(final GenericObjectPoolConfig poolConfig, PooledObjectFactory<T> factory) {
if (this.internalPool != null) {
try {
closeInternalPool();
} catch (Exception e) {
}
}
this.internalPool = new GenericObjectPool<>(factory, poolConfig);
}
...
}
1.7 客户端一致性哈希分片
值得注意的是,ShardedJedis实现的是一种客户端分片的集群方案,依赖一致性哈希算法将不同的Key路由到不同的Redis节点。这与Redis官方提供的服务端集群方案Redis Cluster不同。
当执行命令时,例如set(key, value),ShardedJedis会根据Key计算哈希值,从一致性哈希环上找到对应的分片,最终使用该分片对应的Jedis连接执行命令。
public class ShardedJedis extends BinaryShardedJedis implements JedisCommands, Closeable {
...
@Override
public String set(final String key, final String value) {
Jedis j = getShard(key); // 根据key获取对应的分片连接
return j.set(key, value);
}
...
}
public class Sharded<R, S extends ShardInfo<R>> {
...
// 根据key获取连接对象
public R getShard(String key) {
return resources.get(getShardInfo(key));
}
public S getShardInfo(byte[] key) {
// 在一致性哈希环上查找第一个大于等于该key哈希值的虚拟节点
SortedMap<Long, S> tail = nodes.tailMap(algo.hash(key));
if (tail.isEmpty()) {
// 如果没找到,则使用环上的第一个节点(环状结构)
return nodes.get(nodes.firstKey());
}
return tail.get(tail.firstKey());
}
...
}
2. 卖家信息高并发场景与缓存预热逻辑
2.1 缓存预热的必要性
在电商等系统中,查询卖家信息的接口会被C端用户高频访问。如果每次请求都直接查询数据库,会对数据库造成巨大压力。因此,必须对卖家数据进行缓存。
由于卖家数据相对固定、变化频率低,且请求量巨大,不适合采用“查询时加载”(惰性缓存)的方式,因为这会导致缓存穿透和数据库瞬时压力。缓存预热就是在服务对外提供前,主动将全量或热点数据从数据库加载到缓存中,使系统一上线就能承载高并发查询。
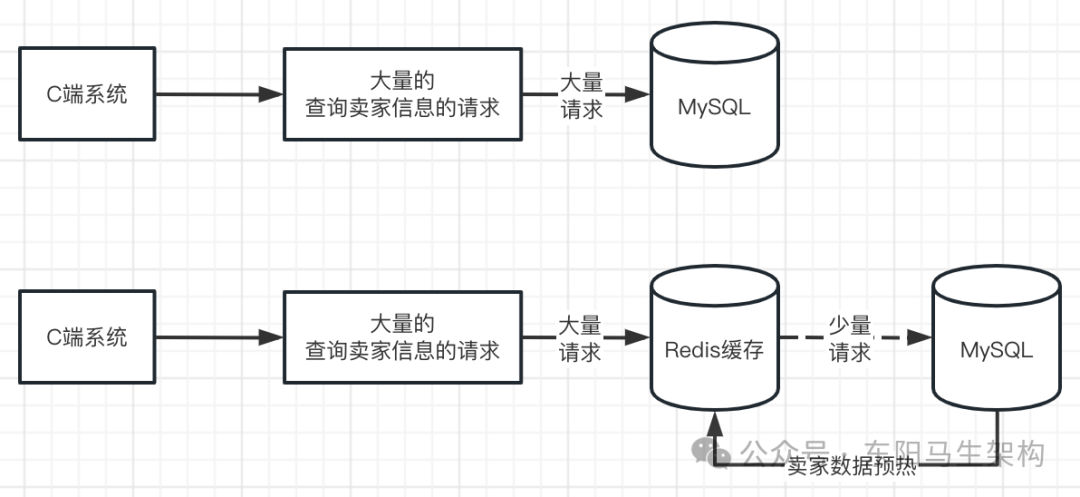
一个典型的卖家信息查询RPC接口实现如下:
@DubboService(version = "1.0.0", interfaceClass = SellerAbilityApi.class, retries = 0)
public class SellerAbilityApiImpl implements SellerAbilityApi {
@Autowired
private SellerInfoService sellerInfoService;
...
@Override
public JsonResult<List<SellerInfoResponse>> getSellerInfo(SellerInfoRequest sellerInfoRequest) {
try {
List<SellerInfoResponse> sellerInfoResponseList = sellerInfoService.querySellerInfoForRPC(sellerInfoRequest);
return JsonResult.buildSuccess(sellerInfoResponseList);
} catch (ProductBizException e) {
log.error("biz error: request={}", JSON.toJSONString(sellerInfoRequest), e);
return JsonResult.buildError(e.getErrorCode(), e.getErrorMsg());
} catch (Exception e) {
log.error("system error: request={}", JSON.toJSONString(sellerInfoRequest), e);
return JsonResult.buildError(e.getMessage());
}
}
...
}
@Service
public class SellerInfoServiceImpl implements SellerInfoService {
@Autowired
private SellerInfoCache sellerInfoCache;
...
@Override
public List<SellerInfoResponse> querySellerInfoForRPC(SellerInfoRequest request) {
checkQuerySellerInfoRequestByRPC(request);
if (CollectionUtils.isEmpty(request.getSellerIdList())) {
// 如果未传sellerIdList,则根据sellerType获取该类型下的所有sellerId
Optional<List<Long>> sellerIdListOps = getSellerIdListBySellerType(request);
if (!sellerIdListOps.isPresent()) {
return Collections.emptyList();
}
request.setSellerIdList(sellerIdListOps.get());
}
// 核心:根据sellerIdList,优先从缓存查询,缓存没有则查库并回填
Optional<List<SellerInfoResponse>> sellerInfoListOps =
sellerInfoCache.listRedisStringDataByCache(
request.getSellerIdList(),
SellerInfoResponse.class,
sellerId -> SellerRedisKeyConstants.SELLER_INFO_LIST + sellerId,
// 缓存未命中时的数据加载函数:根据sellerId从DB查询
sellerId -> sellerRepository.querySellerInfoBySellerId(sellerId)
);
if (!sellerInfoListOps.isPresent()) {
return Collections.emptyList();
}
return filterAccordantSellerInfo(sellerInfoListOps.get(), request);
}
...
}
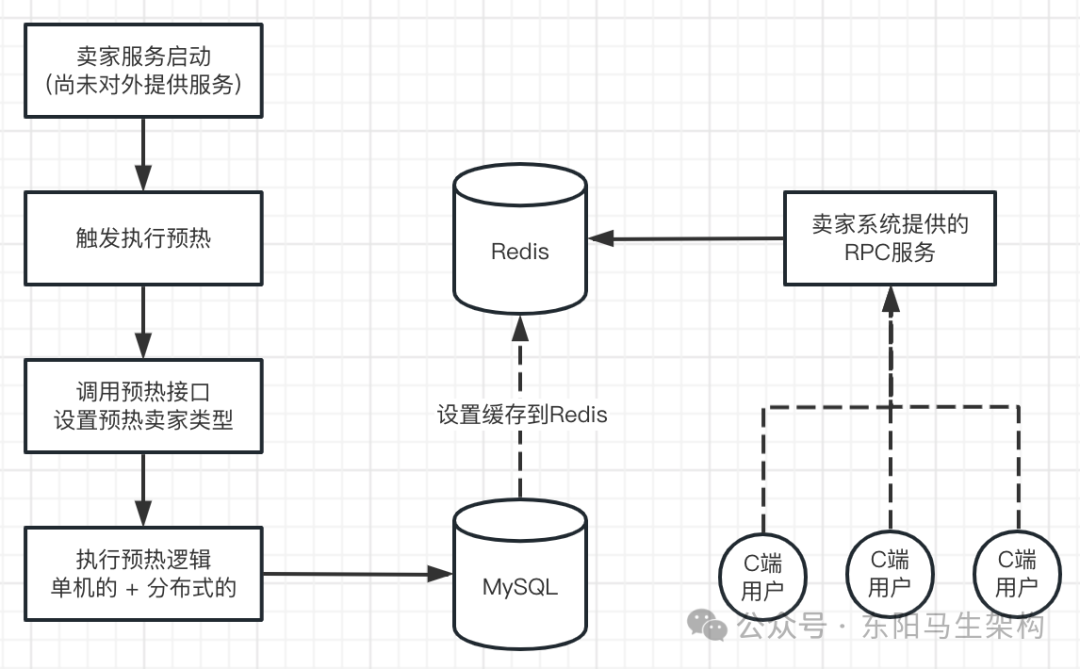
2.2 缓存预热方式:单机与分布式
卖家系统通常提供两种预热方式:
- 单机预热:由卖家系统集群中的某一台机器,独立完成全量卖家数据的查询和缓存写入操作。
- 分布式预热:由一台机器作为生产者,从数据库分页查询数据,并通过消息队列(MQ)将数据分发给集群中的所有机器(消费者)并行写入缓存,显著提升预热速度。
无论哪种方式,目标都是将全量卖家数据加载到Redis缓存中。首次预热后,由于数据可能变更,还需要一个定时任务(例如每5分钟)来对比数据库和缓存的数据差异并更新。
2.3 缓存预热的逻辑
预热的核心业务逻辑并不复杂,关键在于如何在预热过程中保证系统稳定、数据一致,以及如何处理海量数据。其核心流程如下图所示:
3. 卖家信息缓存预热架构设计
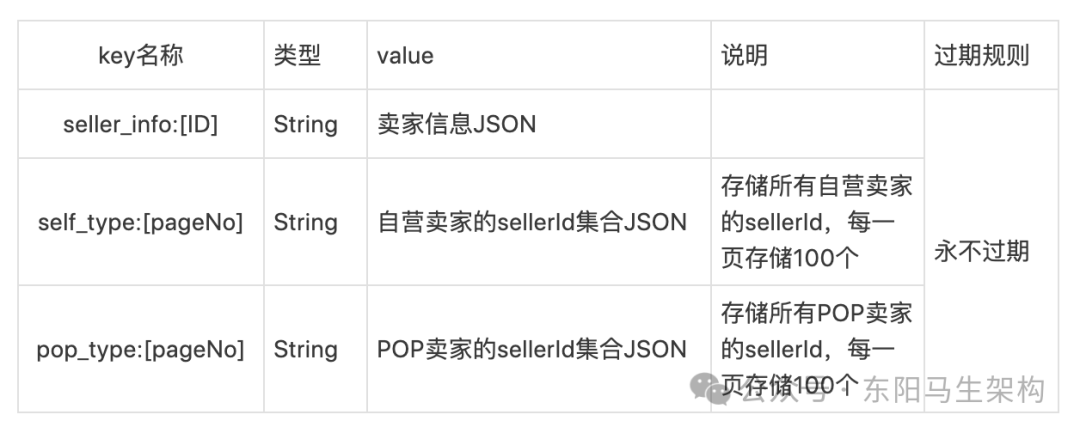
3.1 Redis缓存结构设计
合理的缓存结构是高效访问的基础。卖家信息缓存通常设计为两层结构:
- 卖家详情缓存:Key为
SELLER_INFO_LIST:{sellerId},Value为卖家信息的JSON字符串。用于根据卖家ID快速查询详情。
- 卖家ID列表缓存(按类型分页):Key为
SELLER_TYPE_LIST:{type}:{pageNo},Value为该类型下某页的卖家ID列表JSON。用于支持按卖家类型分页查询的场景。
3.2 单机缓存预热方案设计
单机预热适用于数据量不是特别巨大,或对预热速度要求不极致的场景。其核心步骤是一个典型的生产者-消费者模式在单机内的实现:
- 加分布式锁:确保在集群环境下,同一时间只有一台机器能执行预热操作,避免重复预热。
- 判断强制刷新标志:检查请求参数
forceFlush。如果为0(非强制),则检查Redis中记录的预热状态;若已预热成功,则直接返回,避免无效操作。
- 分页查询数据库:根据卖家类型,使用MyBatis分页插件一页一页地查询卖家数据(例如每页100条)。
- 构建并提交缓存任务:将每页查询出的100条数据,构建成
Map<RedisKey, JSONValue> 的形式。然后将这个Map的写入操作封装成一个任务,提交给一个受控的线程池。
- 线程池与流量控制:线程池使用
Semaphore信号量进行控制,限制同时执行的写入任务数量(例如最多20个),防止任务提交过快导致内存队列堆积或线程耗尽。
- 设置预热状态:所有数据页处理完毕后,在Redis中设置预热状态为“成功”。若过程中出现异常,则设置为“失败”。
- 释放分布式锁:最终释放锁。
3.3 分布式缓存预热方案设计
当卖家数据量极大时,单机预热可能耗时过长。分布式预热利用集群多机算力,大幅缩短预热时间。
生产者(Producer)逻辑:
- 加锁与状态判断:同单机预热步骤1、2,保证操作的原子性与幂等性。
- 分页查询与消息封装:分页查询数据库,但不像单机那样直接写入缓存。而是将每一页的卖家数据列表转换为一个JSON字符串。
- 发送消息到MQ:将封装好的JSON字符串列表(每个字符串代表一页数据),批量发送到指定的消息主题(如
preheat_seller_cache_bucket_topic)。
- 更新状态与释放锁:消息发送成功后,更新预热状态并释放锁。
消费者(Consumer)逻辑:
- 消费消息:集群中的多台机器同时消费MQ中的消息。
- 解析与构建缓存Map:每条消息包含一页(例如100个)卖家数据。消费者解析消息,构建出
Map<卖家详情Key, 卖家详情JSON> 以及该页对应的卖家ID列表。
- 批量写入缓存:使用Redis的
mset命令批量写入卖家详情,使用set命令写入该页的卖家ID列表缓存。
4. 卖家信息单机缓存预热的实现
4.1 实现细节与线程池安全
单机预热的关键在于如何安全、高效地处理海量的数据库查询和缓存写入任务。直接使用无界队列的线程池可能导致内存溢出;而为每个任务创建新线程则可能耗尽线程资源。
此处采用 Semaphore信号量 + 有限线程池 的组合进行流量控制:
Semaphore 控制同时提交的任务数量(如20个),超出则阻塞提交。ThreadPoolExecutor 使用SynchronousQueue,核心线程数为0,最大线程数适当放大(如信号量许可数的2倍)。当任务提交时,如果没有空闲线程,则会创建新线程执行,执行完毕后线程在保活时间后回收。
4.2 实现代码
核心的预热服务类SellerInfoCache包含了主要的逻辑。
@Service("sellerInfoCache")
public class SellerInfoCache {
@Resource
private SellerRepository sellerRepository;
@Resource
private RedisCache redisCache;
@Resource
private RedisLock redisLock; // 分布式锁组件
@Autowired
@Qualifier("preheatCacheThreadPool")
private PreheatCacheThreadPool preheatCacheThreadPool; // 受控的预热线程池
public Boolean preheatSellerCache(SellerInfoCacheRequest cacheRequest) {
try {
// 1. 获取分布式锁,确保集群环境下的操作原子性
redisLock.lock(SELLER_INFO_CACHE_PREHEAT_LOCK);
// 2. 判断强制刷新及预热状态
if (!NumberUtils.INTEGER_ONE.equals(cacheRequest.getForceFlush())) {
if (isPreheated()) {
return true;
}
}
// 3. 根据卖家类型预热数据
if (NumberUtils.INTEGER_ZERO.equals(cacheRequest.getSellerType())) {
preheatSellerInfoToCache(SellerTypeEnum.SELF.getCode());
preheatSellerIdCache(SellerTypeEnum.SELF.getCode());
preheatSellerInfoToCache(SellerTypeEnum.POP.getCode());
preheatSellerIdCache(SellerTypeEnum.POP.getCode());
} else {
preheatSellerInfoToCache(cacheRequest.getSellerType());
preheatSellerIdCache(cacheRequest.getSellerType());
}
// 6. 设置预热成功状态
redisCache.set(SELLER_INFO_CACHE_PREHEAT_SUCCESS, SellerCacheStatusEnum.SUCCESS.getCode().toString(), -1);
return true;
} catch (Exception e) {
// 7. 异常时设置预热失败状态
redisCache.set(SELLER_INFO_CACHE_PREHEAT_SUCCESS, SellerCacheStatusEnum.FAIL.getCode().toString(), -1);
throw new BaseBizException("缓存预热失败,error:{}", JSON.toJSONString(e));
} finally {
// 8. 释放分布式锁
redisLock.unlock(SELLER_INFO_CACHE_PREHEAT_LOCK);
}
}
private Boolean isPreheated() {
Boolean isExist = redisCache.hasKey(SELLER_INFO_CACHE_PREHEAT_SUCCESS);
if (!isExist) {
return false;
}
Integer success = Integer.parseInt(redisCache.get(SELLER_INFO_CACHE_PREHEAT_SUCCESS));
return SellerCacheStatusEnum.SUCCESS.getCode().equals(success);
}
public Boolean preheatSellerInfoToCache(Integer type) {
SellerInfoRequest request = new SellerInfoRequest();
request.setSellerType(type);
Integer pageNum = request.getPageNo();
request.setPageSize(CollectionSize.DEFAULT); // 每页100条
while (true) {
// 4. 分页查询数据库
Optional<List<SellerInfoResponse>> sellerInfoResponses = sellerRepository.querySellerInfo(request);
if (!sellerInfoResponses.isPresent() || CollectionUtils.isEmpty(sellerInfoResponses.get())) {
break;
}
List<SellerInfoResponse> sellerInfoResponseList = sellerInfoResponses.get();
Map<String, String> result = new HashMap<>(sellerInfoResponseList.size());
// 构建缓存数据Map
for (SellerInfoResponse sellerInfoResponse : sellerInfoResponseList) {
Long sellerId = sellerInfoResponse.getSellerId();
result.put(SellerRedisKeyConstants.SELLER_INFO_LIST + sellerId, JSON.toJSONString(sellerInfoConverter.responseToDTO(sellerInfoResponse)));
}
log.info("本批次缓存map:{}", JSON.toJSONString(result));
// 5. 提交缓存写入任务到受控线程池
preheatCacheThreadPool.execute(() -> redisCache.mset(result));
// 查询下一页
request.setPageNo(++pageNum);
}
return true;
}
// ... preheatSellerIdCache 方法类似
}
受控的预热线程池 PreheatCacheThreadPool:
public class PreheatCacheThreadPool {
private final Semaphore semaphore;
private final ThreadPoolExecutor threadPoolExecutor;
public PreheatCacheThreadPool(int permits) {
// 信号量,控制最大并发任务数
semaphore = new Semaphore(permits);
threadPoolExecutor = new ThreadPoolExecutor(
0, // 核心线程数,预热是一次性任务,不需要常驻核心线程
permits * 2, // 最大线程数,设置为信号量许可数的2倍
60,
TimeUnit.SECONDS,
new SynchronousQueue<>() // 直接交接队列,无容量
);
}
public void execute(Runnable task) {
// 获取信号量许可,如果已达最大并发数,则在此阻塞
semaphore.acquireUninterruptibly();
threadPoolExecutor.submit(() -> {
try {
task.run();
} finally {
// 任务执行完毕,释放信号量许可
semaphore.release();
}
});
}
}
5. 卖家信息分布式缓存预热的实现
5.1 生产者:发送预热消息
分布式预热的发起端,负责查询数据并投递到消息队列。
@Service("sellerInfoCache")
public class SellerInfoCache {
// ... 其他依赖
@Autowired
private DefaultProducer defaultProducer; // MQ生产者
public Boolean shardingPreheatSellerCache(SellerInfoCacheRequest request) {
try {
checkPreheatParam(request);
// 1. 获取分布式锁
redisLock.lock(SELLER_INFO_CACHE_PREHEAT_LOCK);
// 2. 判断强制刷新及预热状态
if (!NumberUtils.INTEGER_ONE.equals(request.getForceFlush())) {
if (isPreheated()) {
return true;
}
}
// 3. & 4. 分批次查询出卖家数据,每个String是一页数据的JSON
List<String> sellerInfoList = sellerRepository.querySellerInfoByPage(request.getSellerType());
// 5. 批量发送到MQ
defaultProducer.sendMessages(PREHEAT_SELLER_CACHE_BUCKET_TOPIC, sellerInfoList, "卖家缓存预热消息");
// 6. 设置预热成功状态
redisCache.set(SELLER_INFO_CACHE_PREHEAT_SUCCESS, SellerCacheStatusEnum.SUCCESS.getCode().toString(), -1);
return true;
} catch (Exception e) {
// 7. 异常处理
redisCache.set(SELLER_INFO_CACHE_PREHEAT_SUCCESS, SellerCacheStatusEnum.FAIL.getCode().toString(), -1);
throw new BaseBizException("缓存预热失败,error:{}", JSON.toJSONString(e));
} finally {
// 8. 释放锁
redisLock.unlock(SELLER_INFO_CACHE_PREHEAT_LOCK);
}
}
}
SellerRepository.querySellerInfoByPage 方法会分页查询,并将每一页的100条卖家数据列表封装成一个JSON字符串返回。
5.2 消费者:消费消息并写入缓存
消费者监听MQ主题,并发消费,实现分布式并行写入。
@Component
public class SellerPreheatCacheListener implements MessageListenerConcurrently {
@Autowired
private RedisCache redisCache;
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
try {
for (MessageExt messageExt : list) {
// 1. 解析消息,获取一页数据的JSON字符串
String msg = new String(messageExt.getBody());
List messageList = JsonUtil.json2Object(msg, List.class);
if (CollectionUtils.isEmpty(messageList)) {
throw new BaseBizException(...);
}
Map<String, String> sellerInfoResultMap = new HashMap<>(messageList.size());
List<Long> sellerIdList = new ArrayList<>(messageList.size());
// 2. 遍历该页中的每个卖家数据,构建缓存Map和ID列表
for (Object message : messageList) {
PreheatSellerMessage preheatSellerMessage = JsonUtil.json2Object(message.toString(), PreheatSellerMessage.class);
SellerInfoResponse sellerInfo = preheatSellerMessage.getSellerInfo();
String sellerInfoKey = SellerRedisKeyConstants.SELLER_INFO_LIST + sellerInfo.getSellerId();
sellerInfoResultMap.put(sellerInfoKey, JsonUtil.object2Json(sellerInfo));
sellerIdList.add(sellerInfo.getSellerId());
}
// 获取该页数据的类型和页码
PreheatSellerMessage preheatSellerMessage = JsonUtil.json2Object(messageList.get(0).toString(), PreheatSellerMessage.class);
Integer sellerType = preheatSellerMessage.getSellerInfo().getSellerType();
Integer cachePageNo = preheatSellerMessage.getCachePageNo();
String sellerTypeKey = SellerRedisKeyConstants.SELF_TYPE_LIST + cachePageNo;
if (sellerType.equals(SellerTypeEnum.POP.getCode())) {
sellerTypeKey = SellerRedisKeyConstants.POP_TYPE_LIST + cachePageNo;
}
// 3. 批量写入Redis缓存
redisCache.mset(sellerInfoResultMap); // 批量写入卖家详情
redisCache.set(sellerTypeKey, JsonUtil.object2Json(sellerIdList), -1); // 写入分页ID列表
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
log.error("consume error, 缓存预热消息消费失败", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
}
6. 定时查询DB最新数据更新卖家信息缓存
缓存预热完成后,数据并非一成不变。为了保持缓存与数据库的最终一致性,需要定期同步增量变更。
@Component
public class SellerCacheSyncSchedule {
@Autowired
private RedisCache redisCache;
@Autowired
private SellerRepository sellerRepository;
// 每5分钟执行一次
@XxlJob("cacheSync")
public void cacheSync() {
// 计算5分钟前的时间点
Date beforeTime = getBeforeTime();
// 查询近5分钟内新增或更新的数据
List<SellerInfoDO> sellerInfoList = sellerRepository.querySellerInfoFiveMinute(beforeTime);
// 对比并更新差异数据到缓存
saveDiffSellerInfo(sellerInfoList);
}
private void saveDiffSellerInfo(List<SellerInfoDO> sellerInfoList) {
sellerInfoList.forEach(sellerInfo -> {
Long sellerId = sellerInfo.getSellerId();
String redisKey = SellerRedisKeyConstants.SELLER_INFO_LIST + sellerId;
// 简单策略:如果缓存不存在,则直接插入(适用于新增)。
// 实际生产环境需要对比缓存值与数据库值是否一致,更新有变化的字段。
if (!redisCache.hasKey(redisKey)) {
redisCache.set(redisKey, JsonUtil.object2Json(sellerInfo), -1);
}
// TODO: 如果key存在,则需要比较缓存中的旧值与数据库新值,决定是否更新
});
}
private Date getBeforeTime() {
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.MINUTE, -5);
return calendar.getTime();
}
}
对应的仓库层查询方法:
@Repository
public class SellerRepository {
public List<SellerInfoDO> querySellerInfoFiveMinute(Date beforeTime) {
List<SellerInfoDO> batchList = new ArrayList<>();
int pageNum = 1;
int pageSize = ProductConstants.QUERY_ITEM_MAX_COUNT;
while (true) {
LambdaQueryWrapper<SellerInfoDO> queryWrapper = Wrappers.lambdaQuery();
// 查询创建时间或更新时间在5分钟内的记录
queryWrapper.ge(SellerInfoDO::getCreateTime, beforeTime);
queryWrapper.ge(SellerInfoDO::getUpdateTime, beforeTime);
Page<SellerInfoDO> page = new Page<>(pageNum, pageSize);
Page<SellerInfoDO> pageResult = sellerInfoMapper.selectPage(page, queryWrapper);
if (Objects.isNull(pageResult) || pageResult.getRecords().size() <= 0) {
break;
}
batchList.addAll(pageResult.getRecords());
pageNum++;
}
return batchList;
}
}
7. 高并发架构总结
通过对卖家系统缓存预热方案的深入剖析,我们可以提炼出应对高并发场景的几种常见架构思路:
- 高并发C端系统:核心是保护后端。常用技术组合是 限流 + 过滤 + 实时缓存同步。在入口处进行流量控制,在业务层进行请求过滤(如布隆过滤器),并确保热点数据能实时或近实时地出现在缓存中。
- 高并发卖家/商品等基础数据系统:核心是降低数据库压力,提升读性能。采用 缓存预热 + 定时缓存同步 的组合拳。在服务启动或低峰期主动加载全量/热点数据到缓存,并通过定时任务维护缓存与数据库的差异。
- 高并发库存/秒杀等写多读少系统:核心是抗住瞬时写压力,保证数据准确。常用 缓存分桶 技术。将单一热点Key(如“商品A库存”)拆分成多个子Key(如“商品A库存_bucket1”、“bucket2”),将写请求分散到不同的桶,最后聚合计算。同时结合缓存、数据库、消息队列的最终一致性方案。
理解这些模式及其背后的原理(如本文详细分析的连接池、分布式锁、线程池控制、MQ解耦等),是设计和实现稳定、高效的高并发系统的基石。
 发表于 2025-12-13 15:08:59
|
查看: 174|
回复: 0
发表于 2025-12-13 15:08:59
|
查看: 174|
回复: 0
