DeepSeek V4 正式版 7 月中旬上线,高峰时段 API 价格翻倍——这不是涨价,而是 AI 算力第一次系统性引入电力行业百年经验。
你交电费时可能没注意过,白天和半夜电价并不一样。工业用电的峰谷差价尤其明显:高峰贵,低谷便宜。这个机制叫“峰谷定价”,电力行业用了一百多年,目的是用价格信号引导用户错峰用电,避免大家在同一时间挤垮电网。现在,这套逻辑被首次系统性引入大模型 API。
先说事实
DeepSeek 宣布 V4 正式版 7 月中旬上线,正式版 API 将引入峰谷机制:每天 9:00—12:00、14:00—18:00 为高峰时段,价格是平时的 2 倍;其他时段维持现价。
与此同时,V4-Pro 此前已永久降价至原定价的四分之一。把两件事放一起算:V4-Pro 输出价格目前每百万 tokens 6 元,未降价前是 24 元。高峰翻倍后 12 元——仍只有原价的一半。V4-Flash 更便宜:输入每百万 tokens 1 元(缓存未命中),输出 2 元。按 DeepSeek 官方文档换算,1 个中文字符约 0.6 个 token,100 万字中文大约 60 万 tokens,输入成本不到 1 块钱。高峰翻倍后也就 2 块出头。
这不是涨价,而是在用价格杠杆调节需求。
行业里有没有人这么干过
问题来了:峰谷定价在大模型 API 领域是 DeepSeek 独创,还是已有先例?我们扫一遍主流厂商。
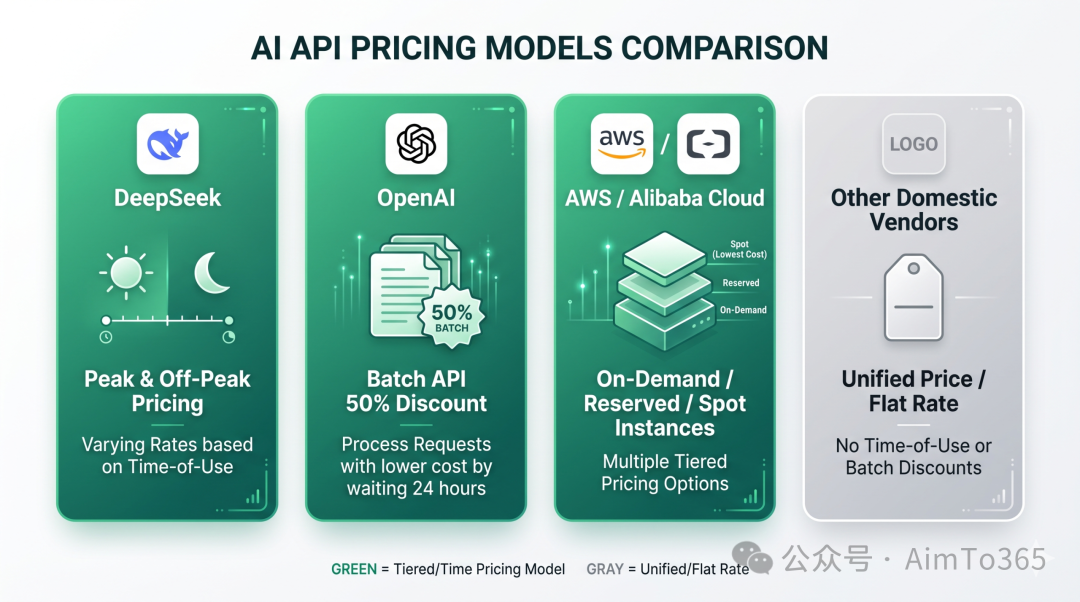
OpenAI 的 API 定价是统一价,不分时段。但它曾在 2024 年 6 月推出 Batch API——异步批量处理接口,价格打五折。逻辑类似:你愿意等(最长 24 小时返回结果),就付一半的钱。本质是用时间换价格,和峰谷定价一脉相承,只是切分维度不同——Batch 按“实时/异步”切,峰谷按“时间段”切。
Anthropic(Claude 系列)、Google(Gemini 系列)的 API 都是统一价,没有分时定价。国内厂商如通义千问、智谱 GLM、百度文心、月之暗面 Kimi,目前也都是统一价,没有一家引入峰谷定价。
但把视角从大模型 API 拉到云计算,情况就不同了。AWS 有三种定价模式:按需实例(最贵,随时用)、预留实例(便宜,但要锁定 1~3 年合约)、竞价实例(最便宜,可能被随时回收)。阿里云也有类似竞价实例,价格通常仅为按需实例的 10%~30%。云厂商早就用价格杠杆调节算力供需了——只不过调节的是 GPU 虚拟机,不是大模型 API 调用。
所以准确的说法是:峰谷定价在云计算行业是成熟实践,在大模型 API 领域是第一次。DeepSeek 是第一个吃螃蟹的国内厂商。
为什么是 DeepSeek 先走这一步
为什么不是 OpenAI 先做?
一个可能的解释是承载模型推理的算力结构不同。OpenAI 背靠微软 Azure 的全球数据中心,GPU 集群规模庞大且分布在不同时区——美洲、欧洲、亚洲的流量可以互相填谷。当美国进入工作时间高峰,亚洲刚好进入低谷。全球分布的算力天然有错峰效果,不太需要用价格信号调节。
DeepSeek 的算力集中在国内,国内用户的工作时间高度一致——9 点到 18 点集中调用,其他时间几乎空白。没有跨时区的流量均衡,GPU 夜间闲置问题更突出。因此,峰谷定价对 DeepSeek 的边际收益比 OpenAI 大得多。
还有一个旁证:DeepSeek 同时开源了模型,任何人都可以自己部署,但官方 API 仍有大量用户。这说明它的算力规模和价格已到临界点——用户量够大、调用量够集中,才需要也才值得用价格信号管理供需。小公司不需要峰谷定价,因为算力要么闲置,要么满载,调节空间有限。
算力基础设施化的信号
过去几年,“算力是继水、电、气、路、网之后的又一大新型基础设施”反复出现在宣传和行业讨论中。国家“东数西算”工程、各地智算中心建设、算力调度平台——都在把算力当作公共基础设施来规划。
但基础设施不只是建起来就行。所有基础设施都要经历一个关键转变:从“稀缺资源”的定价逻辑(有多少卖多少),转向“公共服务”的定价逻辑(用价格信号调节供需平衡)。
电力行业走过这条路。发电厂建设成本固定,但用电需求波动剧烈。按峰值建电厂,低谷产能闲置;按平均需求建,峰值拉闸限电。峰谷定价的精髓是:不增加总产能,通过价格信号让部分需求主动转移,在不扩建电厂的情况下提升整体利用率。中国工业用电的峰谷价格比一般在 3:1 到 4:1 之间——高峰电价是低谷的三到四倍。
自来水也走过这条路。用水高峰水压不足,低谷时水厂产能闲置。不少城市已实施阶梯水价和峰谷水价。
宽带同样走过这条路。早期按流量计费,后来包月不限量但分速率档次,本质是用价格分层管理带宽供需。
DeepSeek 的峰谷定价,2 倍高峰溢价——放在电力行业不算高(电力是 3~4 倍),但对大模型 API 来说是从 0 到 1 的突破。它标志着 AI 算力的定价逻辑开始从“卖模型”转向“运营基础设施”。
云计算行业走完了这条路——AWS 从最初的按需计费,演化出预留、竞价、储蓄计划等多种定价模式。大模型 API 现在站在云计算十年前走过的那条路口。
生图生视频会不会也峰谷定价
很多创作者关心这个问题。
先看算力消耗差异。文本生成模型(如 DeepSeek V4)的推理主要是矩阵运算,GPU 占用时间短——生成上千字只需几秒。但图像生成模型(如 Stable Diffusion)需要多步迭代去噪,生成一张图 GPU 要跑十几到几十秒。视频生成更夸张:生成一段 10 秒视频,GPU 可能要跑好几分钟。
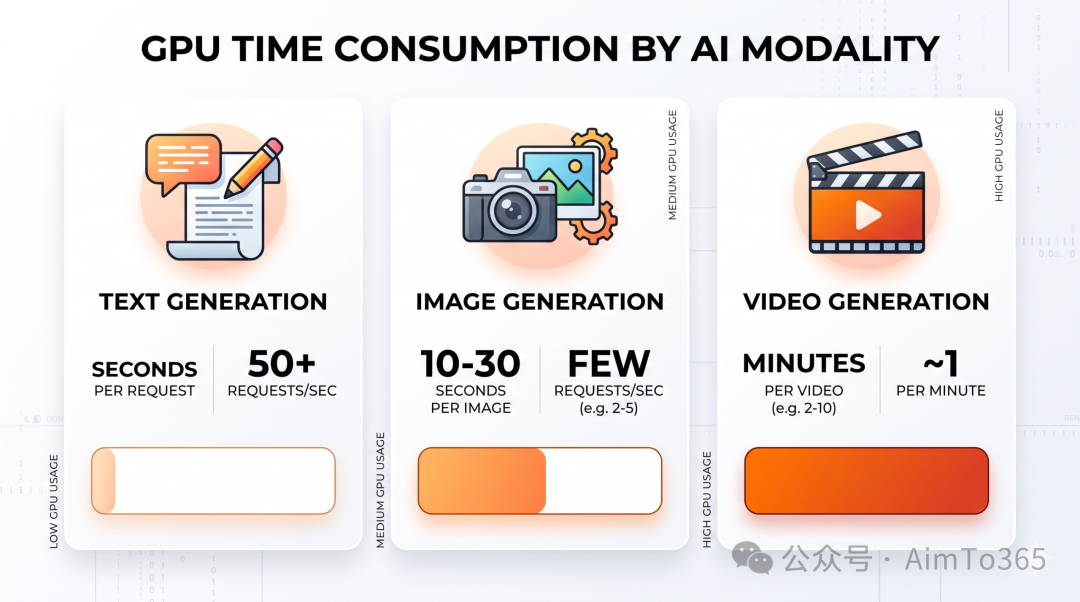
这意味着:同样一块 GPU,文本推理一秒能处理几十个请求,图像生成一秒只能处理几个,视频生成可能一分钟才完成一个。图像和视频模型的 GPU 占用时间是文本模型的几十倍甚至上百倍。
供需矛盾因此更尖锐。白天用户扎堆生成图片和视频,GPU 排队时间更长;夜间用户少,GPU 大量闲置。从供需结构看,图像和视频模型比文本模型更需要峰谷定价。
目前主流图像和视频生成平台大多采用按次计费或订阅制,不分时段。Midjourney 按月订阅,不区别高峰低谷;可灵(快手)按次或按点数计费,也没有分时定价;即梦(字节跳动)同样按次计费。
但瓶颈已经出现:高峰时段生成视频经常排队几分钟到几十分钟,有时甚至提示“服务器繁忙,请稍后再试”。这就是算力供不应求的信号——只不过当前是以排队而非价格来分配有限的算力。
电力行业的经验告诉我们:用排队分配资源效率最低——排队的人浪费了时间,资源的利用率也没有最大化(有人中途放弃,GPU 空转)。用价格分配效率更高——愿意付高价的走高峰,不急的等低谷,GPU 全天满载。
所以,图像和视频模型的峰谷定价,不是会不会的问题,而是什么时候的问题。当某家厂商的生图/生视频 API 调用量大到高峰排队成为常态,它就会像 DeepSeek 一样引入分时定价。目前还没到那个临界点——大多数厂商的图像/视频生成调用量远不如文本模型大,GPU 要么闲置,要么满载,调节空间有限。
但方向是清楚的。随着 AI 生成内容渗透到设计、营销、影视制作等日常工作流,调用量上来只是时间问题。
用户怎么规划算力使用
如果峰谷定价成为趋势,作为日常使用 AI 算力的用户——不管是开发者、企业还是内容创作者——怎么合理规划?
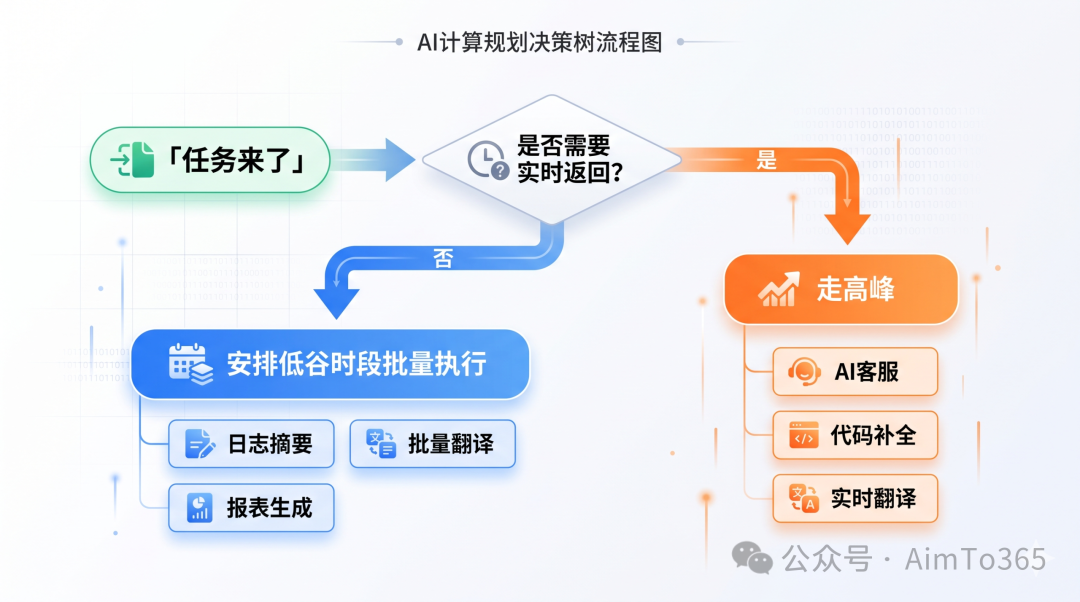
第一步:分清实时任务和批量任务。
- 实时任务:用户在等结果的,必须高峰跑。比如 AI 客服对话、代码补全、实时翻译、交互式问答——这些延迟敏感,不能错峰。
- 批量任务:不需要实时返回的,挪到低谷。比如日志摘要、知识库向量化、报表生成、批量翻译、代码审查、数据清洗——这些可以等几小时甚至过夜。
第二步:量化成本。
以 DeepSeek V4-Flash 为例。假设一个企业每天处理 100 万字的中文文本(约 60 万 tokens),输入成本 0.6 元,输出成本假设也是 60 万 tokens 约 1.2 元,合计 1.8 元。高峰翻倍后 3.6 元。一个月 22 个工作日,高峰额外成本约 40 元——对 Flash 这个量级影响很小。
但 V4-Pro 就不同了。同样 60 万 tokens,Pro 输入 1.8 元,输出 3.6 元,合计 5.4 元。高峰翻倍后 10.8 元。一个月多出约 119 元。如果调用量再放大 100 倍——每天 6000 万 tokens——高峰额外成本每月约 1.2 万元。这时候错峰的收益就相当明显了。
第三步:建立调度意识。
目前主流的 API 调用框架还没有内置“低谷优先”的调度能力。开发者需要自己写调度逻辑——把批量任务放到晚上 8 点以后的 cron job 里自动执行。不复杂,但需要有人去做。对中小企业来说,最简单的做法是:白天跑交互式服务,晚上跑批处理脚本。一个 cron 表达式就能解决。
第四步:善用缓存。
DeepSeek 的缓存定价值得特别关注。Flash 缓存命中输入 0.02 元,未命中 1 元——差距 50 倍。Pro 更夸张:缓存命中 0.025 元,未命中 3 元——差距 120 倍。高峰翻倍后缓存命中也才 0.04~0.05 元,几乎免费。如果你的应用有大量重复上下文(比如同一个系统提示词、同一份文档反复提问),缓存能省下的钱远比错峰多。
第五步:关注多模态的成本结构。
如果你同时使用文本和图像/视频生成 API,成本结构完全不同。文本 API 按 token 计费,单价低;图像 API 按张计费,单价通常是文本的几十到几百倍;视频 API 按秒计费,更贵。一旦图像/视频 API 引入峰谷定价,错峰收益会比文本大得多——因为单次调用的算力消耗更大,高峰溢价的绝对值更高。
举一个具体场景(假设未来图像生成模型也开始峰谷计价):一个电商团队用 AI 生成产品图。白天设计师调整参数、确认风格,需要实时看效果,走高峰。但晚上批量生成不同尺寸、不同场景的产品图——这些不要求实时,放到低谷跑。如果高峰每张图 0.5 元,低谷 0.25 元,每天批量生成 1000 张,一个月能省下 5000 多元。
一个判断
定价策略比产品发布更能说明一家公司的阶段。
发布新模型说明技术能力到了。调整定价说明运营成熟度到了。从预览版的一口价到正式版的峰谷调节,背后是从“实验室产品”到“公共服务平台”的身份转变。
当 AI API 的定价开始像电费一样分峰谷,说明 AI 算力正在从“稀缺资源”变成“基础设施”。这不是 DeepSeek 算力不够用了——恰恰相反,只有算力规模够大、用户够多、调用量达到一定程度时,峰谷定价才有意义。
7 月中旬正式上线后的实际效果有待观察。高峰时段 7 小时覆盖了工作日 88% 的时间,真正能错峰的窗口不算宽。而且大部分中小企业目前还没有错峰意识,工具链也不完善。但方向是清楚的。
更重要的问题是:当文本、图像、视频模型的 API 都开始分峰谷,算力的使用方式会从“来了就调”变成“像用电一样规划”。这一天不会太远。
云栈社区此前在讨论算力基础设施化时,也多次提到过类似趋势。比如在人工智能专区,不少用户就探讨过 API 调用成本优化与调度策略,无论是 LangChain 的批处理实践,还是 RAG 应用的缓存设计,都能看出工程师们对“按需调度算力”的强烈需求。峰谷定价的落地,或许恰好为这些讨论提供了一个落地的支点。
 发表于 4 小时前
|
查看: 4|
回复: 0
发表于 4 小时前
|
查看: 4|
回复: 0
