当前,几乎所有主流的大语言模型都基于2017年Google提出的Transformer架构。以GPT为代表的模型,进一步采用了“预训练+微调”的训练范式,构成了当代生成式AI的基石。本文将从底层原理出发,系统解析大语言模型从架构、训练到部署的全流程核心技术。
大模型的三层产品形态
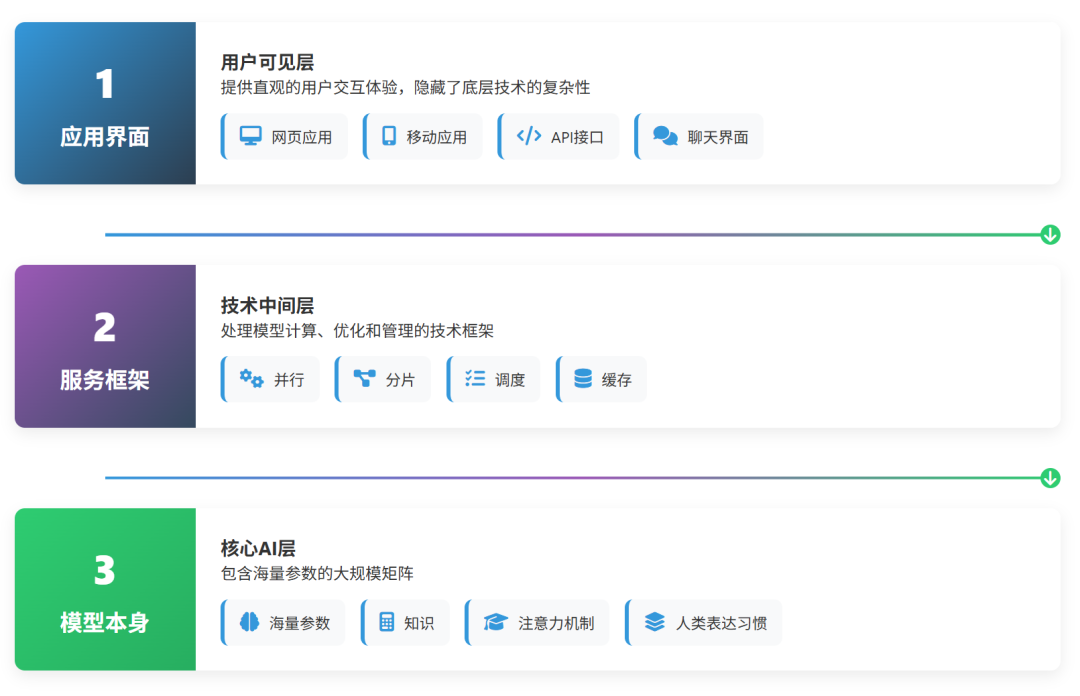
一个完整的大模型产品通常包含以下三个层次:
- 应用界面层:用户可直接交互的部分,如网页应用、移动App或API接口,其作用是提供直观的体验并隐藏底层复杂性。
- 服务框架层:技术中间层,负责处理模型计算、优化与资源管理,涉及并行、分片、调度与缓存等关键技术。
- 模型本体层:由海量参数(训练好的权重矩阵)构成的核心,通过一系列数学计算将输入转化为输出。
如下图所示,用户通常只接触到最上层的应用界面。
从物理本质上讲,模型就是存储在磁盘或内存中的一系列浮点数矩阵。推理时,系统将输入文本转化为数值向量,通过与这些权重矩阵进行线性代数运算(矩阵乘法、激活函数等),最终将结果向量映射回人类可读的文本。
Transformer 架构是大模型的引擎。下图清晰地展示了其数据流动过程,我们可以重点关注输入编码、注意力解析与前馈输出三个核心部分。
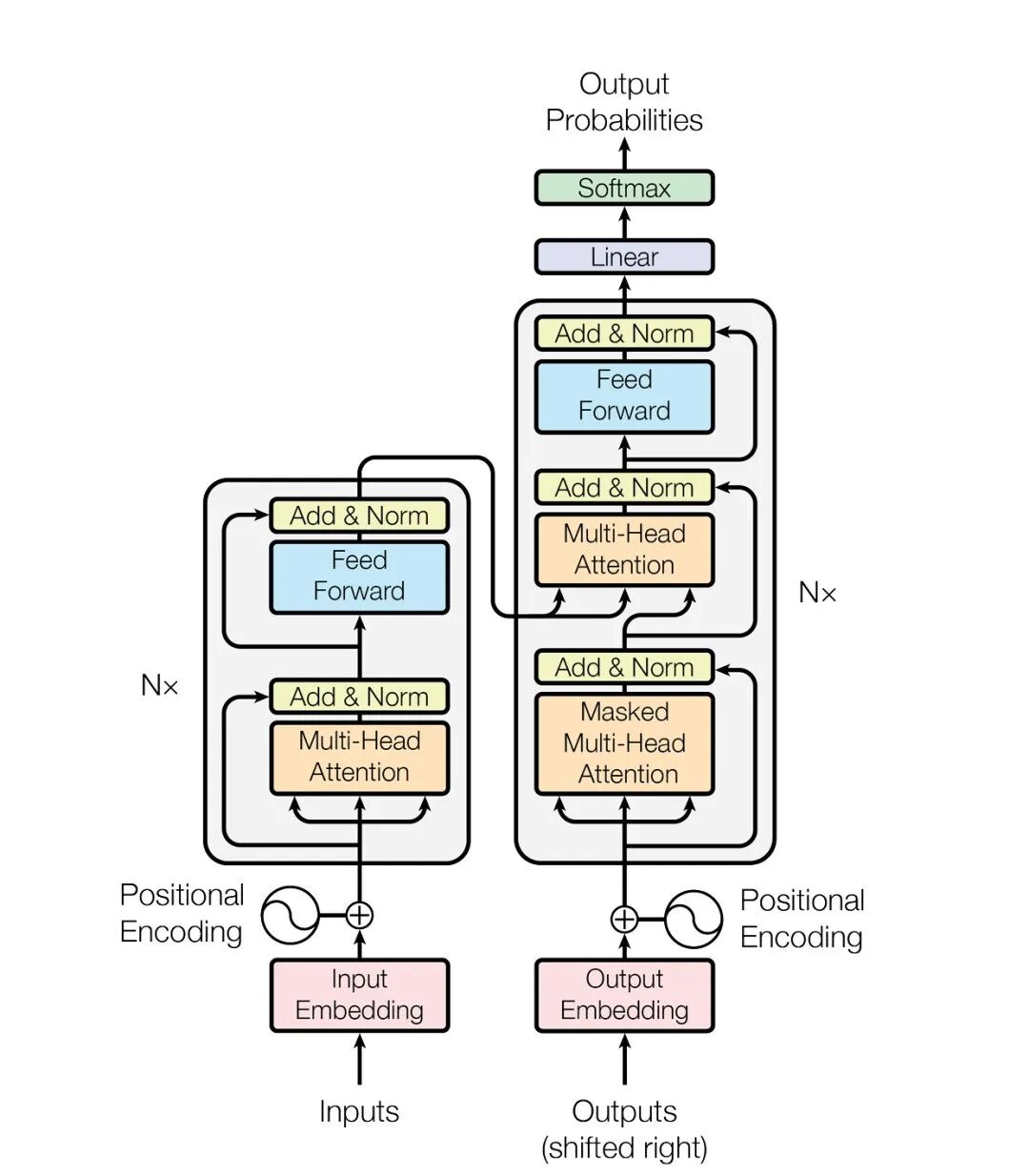
1. 词元输入与嵌入表示
模型处理的基本单位是词元。输入文本会被切分成有序的词元序列(Token Sequence),模型正是依据此顺序来理解语义。这解释了为何计费常以“每百万Token”为单位。
Transformer通过自注意力机制解决了早期RNN/CNN模型难以处理长距离依赖的问题,使其能够同时关注输入序列中的所有词元,上下文窗口因此得以大幅扩展。
在进入模型前,每个词元会被映射为一个高维向量,即词嵌入。在嵌入空间中,语义相近的词其向量距离也更近。例如,在二维可视化中,“摸鱼”、“划水”等词的向量位置可能彼此相邻,而与“美食”、“旅游”等词的向量相距较远。
 (词嵌入低维可视化示意,仅展示聚类趋势)
(词嵌入低维可视化示意,仅展示聚类趋势)
2. 注意力机制与前馈网络
Transformer为每个输入词元生成三个向量:Query(查询)、Key(键)和Value(值)。注意力机制通过计算当前词元的Query与其他所有词元的Key的相似度,得到一组权重,然后对相应的Value进行加权求和,从而汇聚上下文信息。
在实现上,模型常采用多头注意力,即将注意力计算分散到多个“子空间”并行进行,使模型能够同时关注不同类型的信息关联,增强了表达能力与鲁棒性。
经过注意力层聚合上下文后,信息会流入前馈神经网络。FFN对每个位置的特征进行独立的非线性变换,通常会将维度先扩大再缩小,以进行更复杂的特征组合与知识提取,例如理解词汇在不同语境下的微妙含义。
3. 输出生成与参数量估算
经过多层(N层)注意力与FFN模块的堆叠处理,模型最终会为下一个待生成的词元输出一个概率分布。通过线性层和Softmax归一化,模型选择概率最高的词元作为输出,如此循环往复,便生成了连贯的文本。
基于上述架构,我们可以估算大模型的参数量。主要参数来自:
- 注意力部分:Q, K, V, O四个投影矩阵,参数量约为
4 × d_model²。
- 前馈部分:两层矩阵,参数量约为
2 × d_model × d_ff。通常 d_ff = 4 × d_model,因此约为 8 × d_model²。
因此,单层参数约 12 × d_model²。以GPT-3(d_model=12288,层数N=96)为例,主干参数约 12 × 12288² × 96 ≈ 1739亿,加上词表嵌入等参数,即构成其1750亿的总参数量。
大模型的训练流程
训练的目标就是确定前述所有权重矩阵中的数值。现代大语言模型通常遵循一个三阶段的训练流程:
- 预训练:在海量无标注文本上进行自监督学习。核心任务是让模型学习预测被遮掩的词语或下一个词,从而掌握语言的通用规律和世界知识。
- 指令微调:使用高质量的人工标注指令数据对模型进行微调,教导其理解并遵从人类的各种指令,使其回答更符合交互习惯。这一阶段是模型变得“有用”的关键,通常需要精心构建的数据集。
- 人类反馈强化学习:通过人类对模型输出的偏好评分训练一个“奖励模型”,再利用强化学习算法进一步微调模型,使其输出更安全、更无害、更符合人类价值观。
对于个人开发者或小团队,主流的实践方式是使用开源的预训练模型作为基座,然后使用自己的业务数据进行指令微调或领域适配,这是一种高效且可行的模型微调策略。
大模型的部署与推理
将训练好的模型投入实际使用,涉及复杂的工程优化。由于参数规模巨大,部署时需要依赖专业的计算框架(如vLLM、TGI等)来实现高效的推理。工程师需要综合考虑模型并行、张量并行、流水线并行等技术,并在内存、计算与通信开销之间取得平衡,以在有限的硬件资源下实现高吞吐、低延迟的服务。
拓展:AI浪潮下的机遇
大模型技术正驱动各行业智能化升级,也催生了大量相关岗位。无论是专注于模型研发与调优,还是利用Python等工具进行大模型应用开发,掌握其核心原理都至关重要。
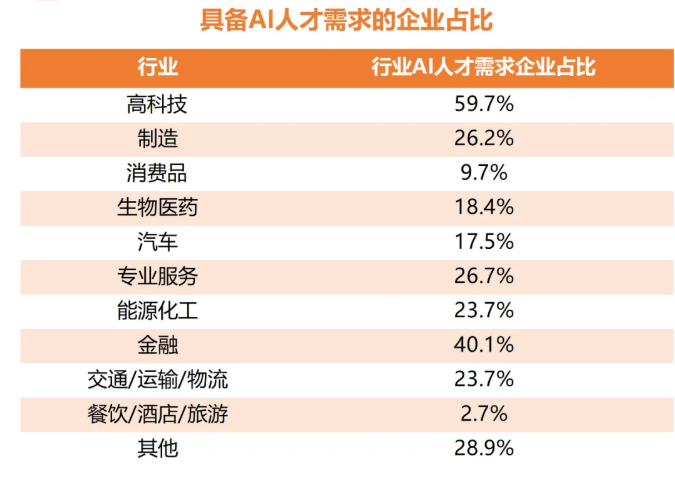
如下图所示,从高科技到金融行业,对AI人才的需求日益旺盛。
理解大模型的原理,不仅能帮助开发者更好地调用和优化模型,更是迈向人工智能更深入领域(如智能体构建、多模态融合)的基石。选择适合自身场景的模型,并深入理解其背后的机制,是在AI时代保持竞争力的关键。
 发表于 2025-12-14 00:12:01
|
查看: 334|
回复: 0
发表于 2025-12-14 00:12:01
|
查看: 334|
回复: 0
