在数字化转型的浪潮中,数据仓库与数据中台是两个常被提及的核心概念。许多从业者疑惑:它们究竟有何区别与联系?为何数据仓库的设计中,“分层”被视为一条金科玉律?本文将深入剖析数据仓库的核心分层思想,并对比业界主流模型与实战优化方案。
一、数据中台与数据仓库:平台与地基的关系
要理解二者的关系,首先需明确它们的定义与核心职能:
- 数据中台:是一个承载“理、采、存、管、用”全流程的一体化数据能力平台。其核心目标是让数据能力实现服务化与可复用,提升整体数据驱动业务的效率。
- 数据仓库:是中台体系中专门负责 “存” 的核心数据存储与组织架构,是数据经过治理和加工后的规范化存储基地。
它们协同工作的流程可以概括为:业务数据经过中台的梳理(理)与采集(采)后,流入数据仓库进行标准化存储;再通过中台的调度与管理(管),最终以API、报表等服务形式(用)支撑上层业务应用。
简而言之,数据中台负责操作和治理数据,而数据仓库负责以最优的结构存储数据。一个强大的大数据平台离不开两者紧密配合。
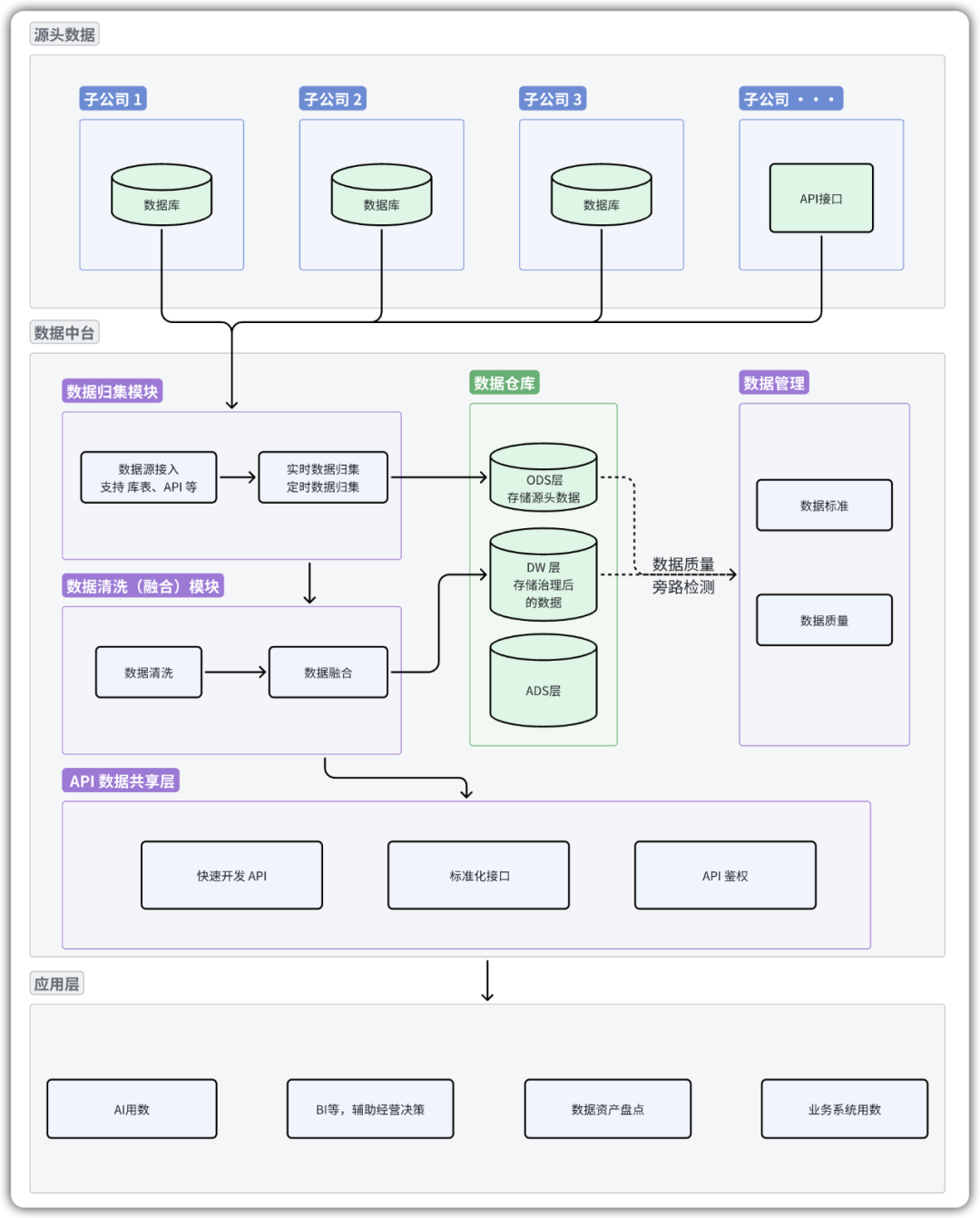 图1:数据中台作为平台,集成数据仓库作为存储核心,协同完成从数据源到数据服务的数据价值链。
图1:数据中台作为平台,集成数据仓库作为存储核心,协同完成从数据源到数据服务的数据价值链。
二、数据仓库分层的必要性与核心价值
如果将未经处理的原数据、半成品加工数据和最终应用数据混杂存放在一起,会导致数据管理混乱、定位困难、查询性能低下等一系列问题。分层设计正是为了解决这些痛点,其核心价值体现在:
- 结构清晰,简化复杂性:像搭建积木一样,通过ODS、DWD、DWS等层次划分,将复杂的数据处理流程分解为职责单一的模块,实现“复杂问题简单化”。
- 数据复用,避免重复开发:在中间层沉淀公共数据模型、指标和宽表,供多个上层应用调用,极大提升开发效率,避免“重复造轮子”。
- 任务解耦,便于运维:复杂的ETL任务被拆分为多个步骤,分布在不同的层次。当某层任务出错时,可以独立重跑,而不影响整体流程,提升了系统的可维护性。
- 空间换时间,加速查询:通过预处理和预先汇总,将计算压力下沉,使得面向最终应用(如BI报表、AI模型、数据大屏)的查询能够获得极快的响应速度。
- 支持水平扩展:现代数据仓库多基于分布式架构(如Hadoop、Spark),分层设计能更好地利用其弹性扩容能力,从容应对数据量的增长。
三、业界主流的数据仓库分层思想
3.1 两大经典方法论
在数据仓库发展史上,形成了两种影响深远的设计思想:
- Inmon范式(自顶向下):主张首先建立企业级统一的数据仓库(EDW),强调数据的整合与一致性,然后再从EDW中衍生出面向部门的数据集市。
- Kimball范式(自底向上):主张首先围绕具体的业务过程(如销售、库存)快速建立数据集市,然后通过一致性维度将这些数据集市联系起来,最终形成企业级的视图。
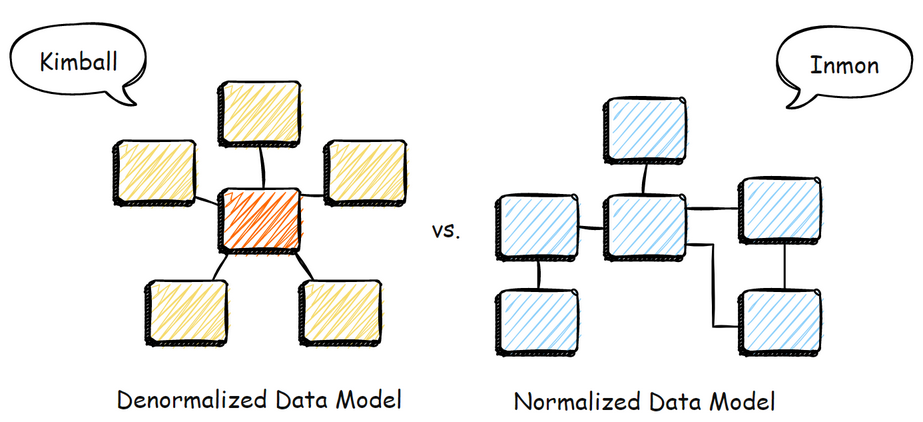 图2:Inmon的规范化模型与Kimball的维度模型对比,代表了两种不同的设计哲学。
图2:Inmon的规范化模型与Kimball的维度模型对比,代表了两种不同的设计哲学。
可以这样比喻:Inmon像先建造一个庞大的中央标准化仓库,再向各分公司配送;Kimball则像先为各分公司开设专业门店,但使用统一的商品编码和会员体系,最终连锁成大型超市。现代数据平台通常融合了两种思想。
3.2 当前共识:经典五层模型
融合经典思想,互联网和大型科技公司普遍采用以下五层结构:
- ODS(贴源层): Operational Data Store。直接镜像源业务系统数据,保持原始面貌,仅做必要的格式转换。主要作用是隔离源系统压力,并提供数据回溯能力。
- DWD(明细层): Data Warehouse Detail。在ODS层基础上,进行数据清洗、标准化、去重、业务维度退化等操作,形成干净、一致、颗粒度最细的业务明细数据。
- DWS(服务层): Data Warehouse Service。基于DWD层数据,按主题域进行轻度汇总,生成可复用的公共指标和宽表,直接服务于常见的分析需求。
- ADS(应用层): Application Data Store。面向具体的业务场景、产品或报表进行深度加工,数据模型高度定制化,是数据产出的最后一步。
- DIM(公共维度层): Dimension。统一管理时间、地区、产品等公共维度信息,确保各层数据计算中维度定义的一致性。
数据流向: ODS → DWD → DWS → ADS,DIM层贯穿始终提供维度支持。这种架构高内聚、低耦合,但对数据建模和团队技术要求较高。
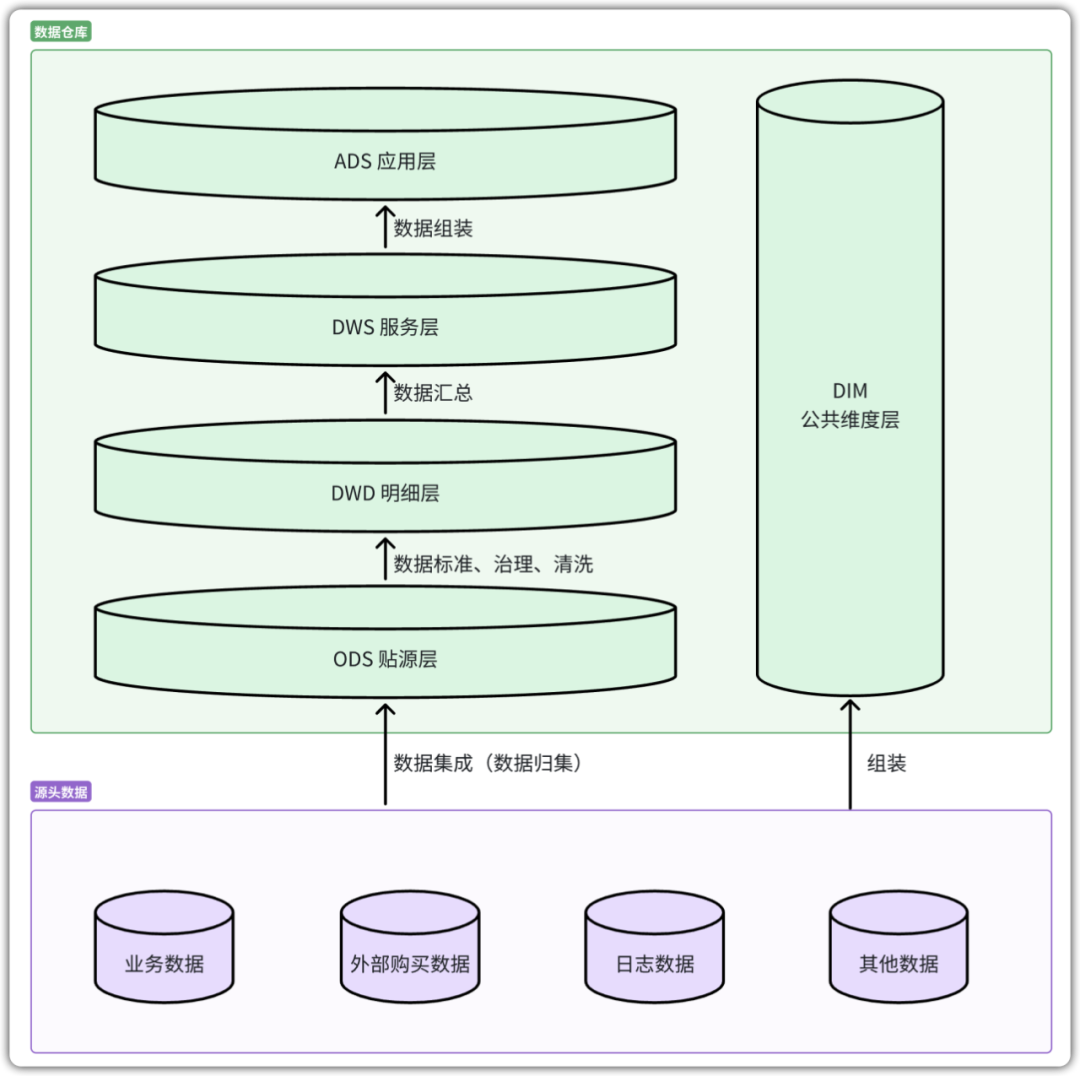 图3:经典的五层数据仓库架构,清晰地展示了数据从原始到应用的流转与分层加工过程。
图3:经典的五层数据仓库架构,清晰地展示了数据从原始到应用的流转与分层加工过程。
四、实战优化:龙石数据的五层模型实践
上述经典模型理论完备,但在中小型团队或要求快速落地的场景中,实施门槛较高。龙石数据基于大量项目实践,提出了一套更注重实战、易用性的分层模型:SRC → ODS → DW → ADS → DS。
4.1 设计思路:聚焦“好管”与“好用”
- 强化头尾,映射流程:在头部增加 SRC(来源层),明确对应数据治理的“理”与“采”的源头;在尾部增加 DS(共享层),明确对应数据服务的“用”的出口。这让数据血缘和使用关系一目了然。
- 合并中间,降低门槛:将经典的DWD(明细)和DWS(汇总)层合并为统一的 DW(治理层)。这降低了对团队成员精通复杂Kimball维度建模的要求,使其能更快速地投入生产。
- 工具固化,保障规范:将维度(DIM)管理、数据标准、质量检核等规范,内嵌到数据中台的工具模块中(如数据标准管理、可视化ETL),而非完全依赖人工在ETL脚本中实现,确保了简化架构的同时不牺牲数据质量。这种将规范工具化的思路,与优秀的Java后端框架设计思想有异曲同工之妙。
- 适配多样:该模型兼容多种底层数据库,无论是Doris、StarRocks等分析型数据库,还是PostgreSQL、MySQL等传统关系型数据库,乃至达梦、人大金仓等信创数据库,都能良好适配。
4.2 龙石五层模型详解
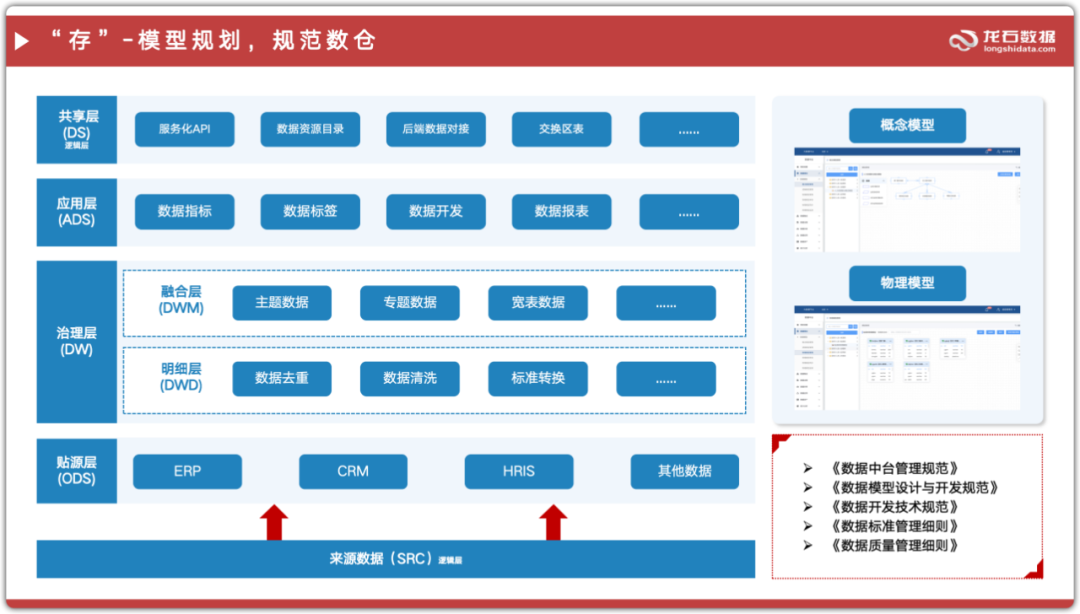 图4:龙石数据提出的实战五层模型,强调源头映射与服务出口。
图4:龙石数据提出的实战五层模型,强调源头映射与服务出口。
- 第0层:SRC(来源层):逻辑层,不存储实际数据。用于梳理和登记数据资产目录,如“CRM系统-客户表”,是数据治理的起点。
- 第1层:ODS(贴源层):物理层,将源系统数据近乎原样同步至此,仅做轻度格式处理,实现业务解耦与数据备份。
- 第2层:DW(治理层):核心物理层。在此完成主要的数据清洗、标准化、关联和轻度汇总,产出高质量、可复用的核心数据资产。
- 第3层:ADS(应用层):物理层。面向具体应用场景(如领导驾驶舱、精准营销报表)进行深度加工,模型灵活多变,快速响应业务需求。
- 第4层:DS(共享层):逻辑层。将ADS层的数据封装成标准API或发布到数据资源目录,供前端业务系统或分析人员直接调用,实现“数据即服务”。
 图5:在数据中台中进行数据源(SRC层)接入与管理的界面示例。
图5:在数据中台中进行数据源(SRC层)接入与管理的界面示例。
总结
数据中台是赋能数据的“操作系统”,而数据仓库是其内部精心设计的“文件系统”。分层架构是构建高效、清晰、可扩展数据仓库的基石。从经典的Inmon、Kimball理论,到通用的五层模型,再到龙石数据优化的实战五层模型(SRC/ODS/DW/ADS/DS),其演进方向始终是:在保证数据规范与质量的前提下,不断降低实施复杂度,提升数据交付与使用的效率。
随着数据湖、湖仓一体等新理念的发展,数据存储与处理架构仍在持续演进,但分层管理所体现的“解耦、复用、规范”的核心思想,始终是构建稳健数据体系的根本。 |  发表于 2025-12-14 07:41:50
|
查看: 256|
回复: 0
发表于 2025-12-14 07:41:50
|
查看: 256|
回复: 0
