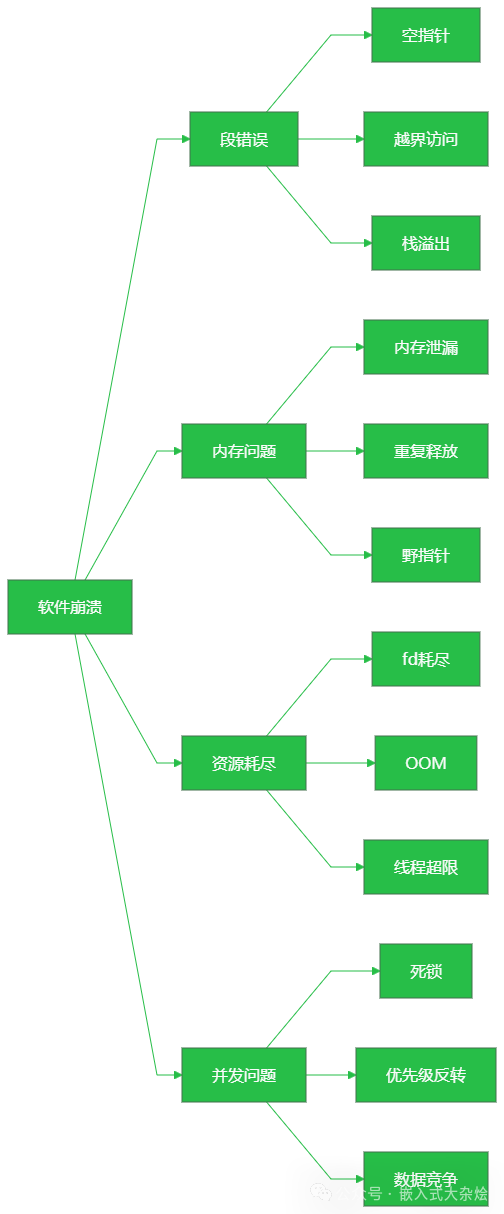
一、崩溃全景图
当嵌入式软件发生崩溃时,在深入代码细节前,建立一个全局的崩溃类型视角至关重要。嵌入式软件的崩溃通常可以归纳为以下四大类:
二、段错误(SIGSEGV)
段错误是内核发出的明确信号,表明程序访问了其无权访问的内存地址。这是在嵌入式开发中最常遇到的崩溃类型之一。
2.1 空指针访问
以下是经典的因访问空指针而导致的崩溃:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int id;
char name[32];
} Device;
Device* find_device(int id) {
// 查找失败,返回NULL
return NULL;
}
int main() {
Device *dev = find_device(100);
// 危险:未检查返回值
printf("Device name: %s\n", dev->name); // SIGSEGV!
return 0;
}
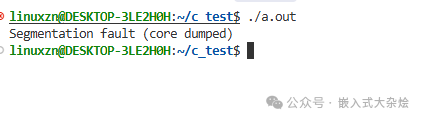
使用dmesg命令查看内核日志,通常会显示segfault at 0,地址0正是访问NULL指针的特征。根本原因在于函数返回NULL后,调用者未进行判空检查便直接解引用。
这在嵌入式系统中极其常见——资源初始化失败、配置文件解析出错或硬件未就绪都可能返回NULL。因此,对于任何可能返回NULL的Linux系统函数调用,都必须谨慎处理,增加必要的防御性检查。
指针在使用前必须进行三重检查:是否已初始化、是否为NULL、是否指向有效的内存区域。
2.2 数组越界访问
缓冲区越界写入:
#include <stdio.h>
#include <string.h>
void parse_command(const char *cmd) {
char buffer[16];
// 危险:未限制拷贝长度
strcpy(buffer, cmd); // 如果cmd超过15字节,栈将被破坏
printf("Command: %s\n", buffer);
}
int main() {
// 构造超长输入
char evil_cmd[64] = "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
parse_command(evil_cmd); // 可能导致崩溃或行为异常
return 0;
}
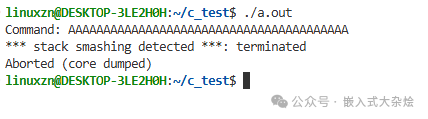
此类问题可能立即引发段错误,也可能在函数返回时才崩溃(因为返回地址被覆盖)。原因在于strcpy函数不会检查目标缓冲区的大小,超长数据直接覆盖了栈上的相邻数据。
嵌入式设备在处理来自网络或串口的外部协议数据时,这类问题尤其危险。安全的做法是使用strncpy或snprintf等替代函数,并始终指定最大拷贝长度。
2.3 栈溢出
无限递归导致的栈空间耗尽:
#include <stdio.h>
void recursive_parse(int depth) {
char local_buffer[1024]; // 每层调用消耗至少1KB栈空间
sprintf(local_buffer, "depth=%d", depth);
recursive_parse(depth + 1); // 无终止条件
}
int main() {
recursive_parse(0); // 很快栈耗尽,引发SIGSEGV
return 0;
}
这会触发段错误,但崩溃地址通常是一个看起来“合理”的值(接近栈底)。由于栈空间有限,无限递归或过深的函数调用链会迅速耗尽所有栈内存。应避免深层递归,考虑用迭代方式重写;对于大型数组,应分配在堆上而非栈上。
三、内存问题
与段错误的“立即崩溃”不同,内存问题往往是“慢性病”——程序可能运行一段时间后才暴露问题。
3.1 内存泄漏
#include <stdlib.h>
#include <string.h>
char* process_message(const char *raw) {
char *buffer = malloc(256);
if (!buffer) return NULL;
// 处理逻辑...
if (strlen(raw) > 200) {
return NULL; // 危险:提前返回,buffer未释放!
}
strcpy(buffer, raw);
return buffer;
}
int main() {
for (int i = 0; i < 100000; i++) {
char *msg = process_message("short message");
// 假设调用者也忘记了free...
}
// 内存持续增长,最终可能触发OOM
return 0;
}
程序会越跑越慢,通过查看/proc/<pid>/status中的VmRSS字段可以发现内存使用量持续增长,最终进程可能被OOM Killer终止。
根本原因在于函数中存在多个返回路径,而某些路径(尤其是错误处理分支)忘记了释放已分配的内存。这类问题在复杂的错误处理逻辑中最容易出现。建议定期使用Valgrind等工具进行内存扫描。
3.2 重复释放(Double Free)
#include <stdlib.h>
int main() {
char *ptr = malloc(100);
free(ptr);
// ... 中间有很多代码 ...
free(ptr); // Double free! 行为未定义
return 0;
}
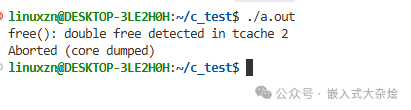
glibc等内存分配器通常能检测到此类错误,并打印double free or corruption等错误信息后中止程序。问题根源在于指针被释放后未及时置为NULL,在复杂的控制流中又被误操作再次释放。
3.3 野指针(Use After Free)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *name = malloc(32);
strcpy(name, "sensor_01");
free(name);
// 危险:内存已释放,但指针仍可访问(暂时)
printf("Name: %s\n", name); // 可能打印乱码,也可能暂时不崩溃
char *other = malloc(32); // 可能分配到刚刚释放的同一块内存
strcpy(other, "XXXXXXXX");
printf("Name: %s\n", name); // 现在打印出了"XXXXXXXX"!数据已被污染
return 0;
}
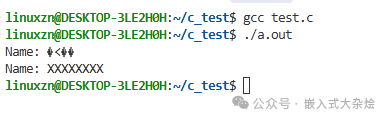
这类问题不一定立即导致崩溃,可能表现为数据错乱、产生随机不可预知的行为,并且极难复现。因为释放后的内存可能被重新分配给其他变量,原指针访问的变成了“别人的数据”。
这是最难调试的内存问题之一,因为崩溃发生的地点与问题产生的源头往往相距甚远。可以借助AddressSanitizer(ASan)等工具来有效检测此类问题。
四、资源耗尽
4.1 文件描述符耗尽
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
void read_config() {
int fd = open("/etc/config.txt", O_RDONLY);
if (fd < 0) return;
char buf[128];
read(fd, buf, sizeof(buf));
// 危险:忘记close(fd)
}
int main() {
for (int i = 0; i < 2000; i++) {
read_config(); // 每次调用泄漏一个文件描述符
}
// 后续所有的open、socket等操作都会失败
int fd = open("/tmp/test", O_RDONLY);
printf("fd = %d\n", fd); // 输出-1,errno=EMFILE
return 0;
}
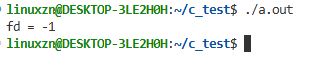
这不会直接导致段错误,但会使所有后续的文件或网络操作开始失败。通过命令ls /proc/<pid>/fd | wc -l可以查看进程打开的文件描述符数量,通常会接近系统限制(ulimit)。原因在于打开文件或网络套接字后,没有在适当的时候关闭。嵌入式设备的文件描述符限制通常较低(默认1024)。
4.2 OOM Killer
#include <stdlib.h>
#include <string.h>
int main() {
while (1) {
char *p = malloc(1024 * 1024); // 每次分配1MB
if (p) memset(p, 0, 1024 * 1024);
// 永不释放
}
return 0;
}
这会触发系统的OOM(内存耗尽)机制,进程被SIGKILL信号杀死。查看dmesg内核日志,会出现Out of memory: Kill process之类的记录。其原理在于Linux的overcommit内存机制允许申请超过物理内存的空间,但当进程实际使用这些内存并触及系统底线时,OOM Killer便会介入,选择一个“合适”的进程终止以回收内存。
五、并发问题
并发问题是隐藏最深、最难调试的缺陷之一。
5.1 死锁
经典的AB-BA顺序死锁:
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
pthread_mutex_t lock_a = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t lock_b = PTHREAD_MUTEX_INITIALIZER;
void* thread1(void *arg) {
pthread_mutex_lock(&lock_a);
usleep(1000); // 增加发生死锁的概率
pthread_mutex_lock(&lock_b); // 等待lock_b
printf("Thread 1 got both locks\n");
pthread_mutex_unlock(&lock_b);
pthread_mutex_unlock(&lock_a);
return NULL;
}
void* thread2(void *arg) {
pthread_mutex_lock(&lock_b);
usleep(1000);
pthread_mutex_lock(&lock_a); // 等待lock_a,死锁!
printf("Thread 2 got both locks\n");
pthread_mutex_unlock(&lock_a);
pthread_mutex_unlock(&lock_b);
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, thread1, NULL);
pthread_create(&t2, NULL, thread2, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL); // 永远不会返回
return 0;
}

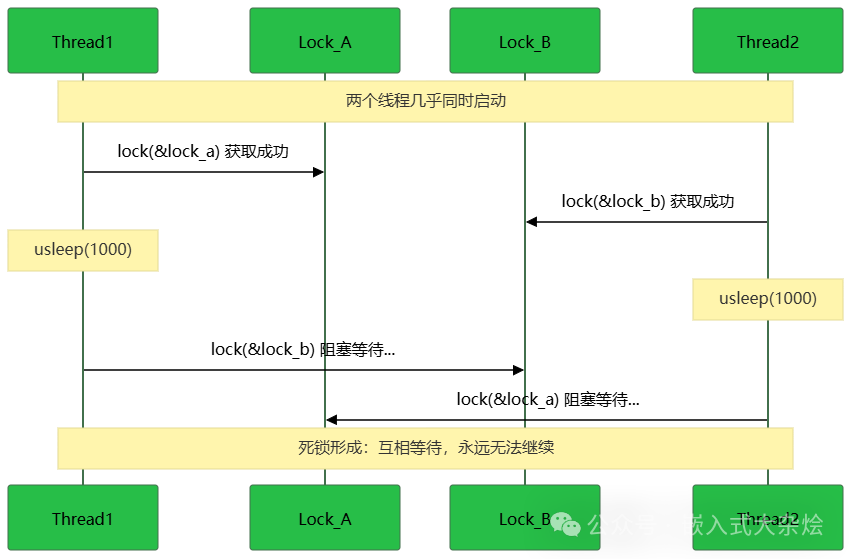
程序会完全卡死,但CPU占用率可能为0。这是经典的AB-BA死锁模式:两个线程以相反的顺序请求两把锁,在特定的执行时序下会相互等待对方释放已持有的锁,从而形成循环等待。
执行时序图:
修复方案:统一加锁顺序
void* thread1(void *arg) {
pthread_mutex_lock(&lock_a); // 先A
pthread_mutex_lock(&lock_b); // 后B
printf("Thread 1 got both locks\n");
pthread_mutex_unlock(&lock_b);
pthread_mutex_unlock(&lock_a);
return NULL;
}
void* thread2(void *arg) {
pthread_mutex_lock(&lock_a); // 先A(与thread1顺序一致)
pthread_mutex_lock(&lock_b); // 后B
printf("Thread 2 got both locks\n");
pthread_mutex_unlock(&lock_b);
pthread_mutex_unlock(&lock_a);
return NULL;
}

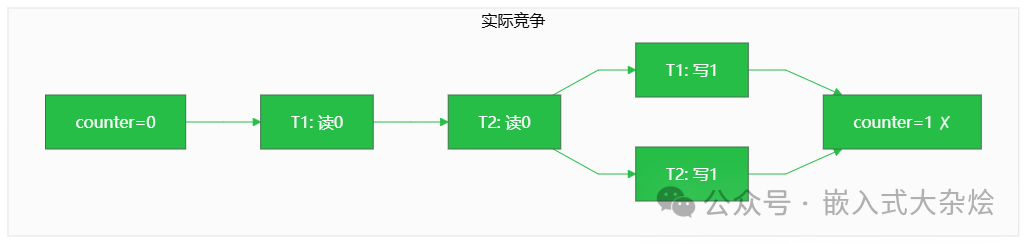
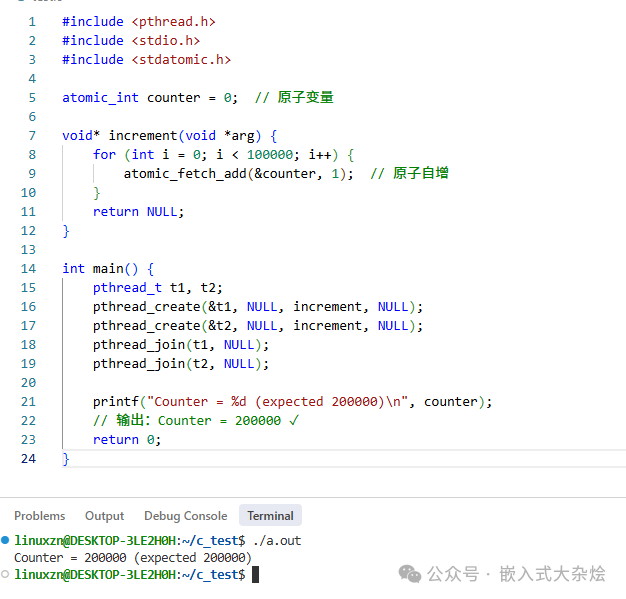
5.2 数据竞争
对共享变量进行无保护访问:
#include <pthread.h>
#include <stdio.h>
int counter = 0; // 共享变量,无锁保护
void* increment(void *arg) {
for (int i = 0; i < 100000; i++) {
counter++; // 非原子操作!
}
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, increment, NULL);
pthread_create(&t2, NULL, increment, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("Counter = %d (expected 200000)\n", counter); // 实际结果远小于200000
return 0;
}
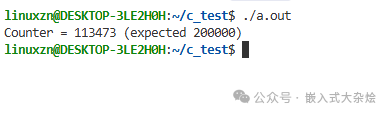
虽然程序可能不会崩溃,但运行结果是错误的。在更复杂的场景下,数据竞争可能导致关键数据结构损坏,进而引发程序崩溃。counter++这个操作在汇编层面是“读取-修改-写回”三个步骤,多线程并发执行时步骤会交织,导致更新丢失。

修复方案对比:
| 方案 |
实现 |
性能 |
适用场景 |
| 互斥锁 |
pthread_mutex_lock/unlock |
较低 |
复杂的临界区代码 |
| 原子操作 |
__atomic_add_fetch |
高 |
简单的计数器增减 |
| 自旋锁 |
pthread_spin_lock |
高(短临界区) |
嵌入式实时场景,等待时间极短 |
总结
上述12种崩溃类型覆盖了嵌入式Linux开发中绝大多数常见问题场景:
| 类型 |
特征 |
首选调试工具 |
| 段错误 |
立即崩溃,dmesg中有地址信息 |
GDB + coredump分析 |
| 内存问题 |
延迟暴露,行为随机难复现 |
Valgrind / AddressSanitizer (ASan) |
| 资源耗尽 |
相关系统调用开始失败 |
监控 /proc 文件系统状态 |
| 并发问题 |
程序卡死或计算结果错误 |
GDB多线程调试,并发分析工具 |
掌握这些典型崩溃场景的特征与调试方法,能极大提升嵌入式系统的问题定位与解决效率。
 发表于 2025-12-14 17:37:13
|
查看: 207|
回复: 0
发表于 2025-12-14 17:37:13
|
查看: 207|
回复: 0
