Diffusion Transformers (DiTs) 在生成高质量图像方面展现出强大的能力。然而,随着模型规模的增大,其不断增长的内存占用和推理延迟给实际部署带来了重大挑战。近期在大语言模型领域的研究表明,基于旋转的技术能够平滑异常值并实现4比特量化,但这类方法通常会产生显著的额外开销,且难以处理DiT中存在的行方向异常值。
为应对上述挑战,清华大学与华为的研究团队提出了一种名为 ConvRot 的分组旋转量化方法。该方法利用正则Hadamard变换同时抑制行方向和列方向的异常值,并将计算复杂度从平方级降低至线性级。在此基础上,团队设计了一个即插即用的模块ConvLinear4bit,集成了旋转、量化、通用矩阵乘法和反量化操作,能够在无需重新训练的情况下实现W4A4推理,并保持图像质量。在 FLUX.1-dev 模型上的实验表明,ConvRot 在保持图像保真度的同时,实现了 2.26倍的推理加速,并减少了 4.05倍的内存占用。该研究是首次将基于旋转的量化方法应用于 Diffusion Transformers,以实现即插即用的低比特推理。

方法详解
1. 基于等效变换的量化原理
给定一个激活向量 x∈Rⁿ,一个均匀的 b-bit 量化器定义为:
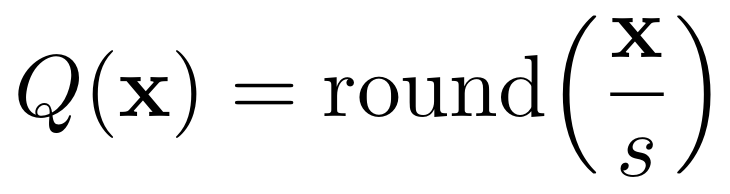
其中,s 是一个缩放因子。x 中幅值较大的异常值会增大 s,从而降低大多数元素的有效分辨率,使得低位量化变得困难。
基于变换的量化方法在量化之前应用一个正交或对角变换 T(⋅) 来重新分配激活值的幅值,同时保持计算结果不变。对于一个线性层 Y = XWᵀ,这种不变性表示为:
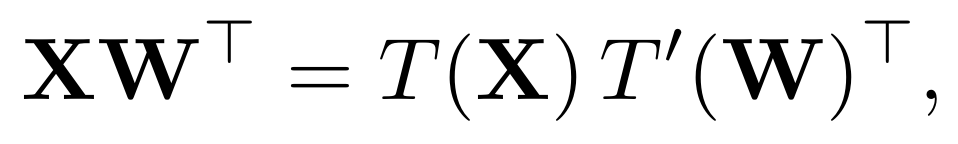
其中,T′(⋅) 是对应于权重的变换。如图 2 所示,不同的 T(⋅) 选择对应于不同的异常值重新分配策略。核心挑战在于设计一种变换 T(⋅),能够在最小计算开销的前提下抑制异常值的幅值,从而实现更小的缩放因子 s 和低位量化下更高的有效精度。
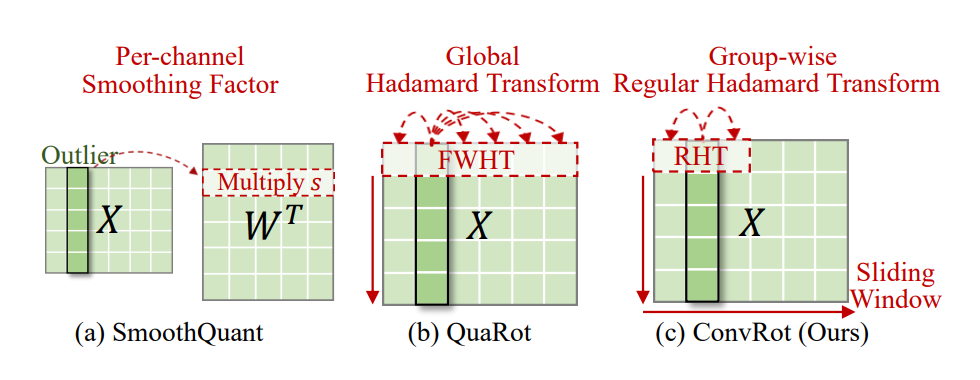
图2:不同变换如何重新分配异常值的示意图。(a) SmoothQuant:每通道对角变换。(b) QuaRot:全局Hadamard变换。(c) ConvRot:分组正则Hadamard变换,在滑动窗口内进行局部平滑处理。
2. ConvRot:分组正则Hadamard旋转
在矩阵乘法中插入Hadamard变换可理解为在不改变输出分布的情况下对输入或权重空间进行旋转。基于这一思想,研究团队提出了 ConvRot,它采用分组正则Hadamard变换,来控制旋转的作用范围,同时提升计算效率和异常值处理能力。
现有方法(如QuaRot)通常采用阶数为 K 的全局Hadamard变换,会产生 O(K²) 的平方级计算复杂度,对于大规模人工智能模型难以承受。
研究团队发现:通过将特征维度划分为大小为 N₀ 的块,并在每个块内应用正则Hadamard变换,既能将计算成本降至 O(K),又能将异常值的重分配局部化。
给定一个标准线性层 Y = XWᵀ,将输入矩阵和权重矩阵按列划分为大小为 N₀ 的块。对于每个块,插入一个正则Hadamard旋转。通过执行分组RHT,能够显著降低计算复杂度,同时保留有效的异常值抑制能力。等价性保证了这种局部旋转不会改变整体的线性变换;它仅在每个块内部重新分配信息,从而对激活分布提供更精细的控制。
表1展示了在不同旋转类型和分组大小 N₀ 下的异常值幅度(定义为 max∣XH∣)。
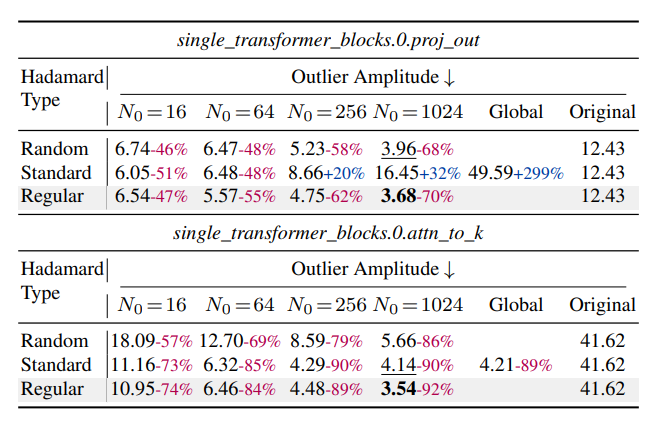
表1: 不同Transformer层在Hadamard变换后的异常值幅度对比。
研究团队通过矩阵乘法实现ConvRot,这减少了额外内存移动,并能充分利用现代GPU上高度优化的矩阵乘法流水线。分组大小为 N₀ 的旋转操作可表示为对输入激活值执行类卷积操作,这种特性促使团队将其命名为ConvRot。
3. ConvLinear4bit:即插即用模块
基于ConvRot方法,研究团队进一步开发了 ConvLinear4bit 模块。如图4所示,该模块可直接替换原有线性层,实现即插即用的4比特推理。ConvLinear4bit 将 ConvRot、量化、4比特矩阵乘法以及反量化过程集成至单一计算层中。
对于ConvRot,通过基于reshape的矩阵乘法实现分组Hadamard旋转,从而最大限度地减少额外内存移动。量化、4比特矩阵乘法与反量化操作沿用了优化的设计方案,并利用高度优化的CUDA内核充分发挥 GPU 上 int4 Tensor Core 的计算优势,这类底层算法优化对于提升推理效率至关重要。
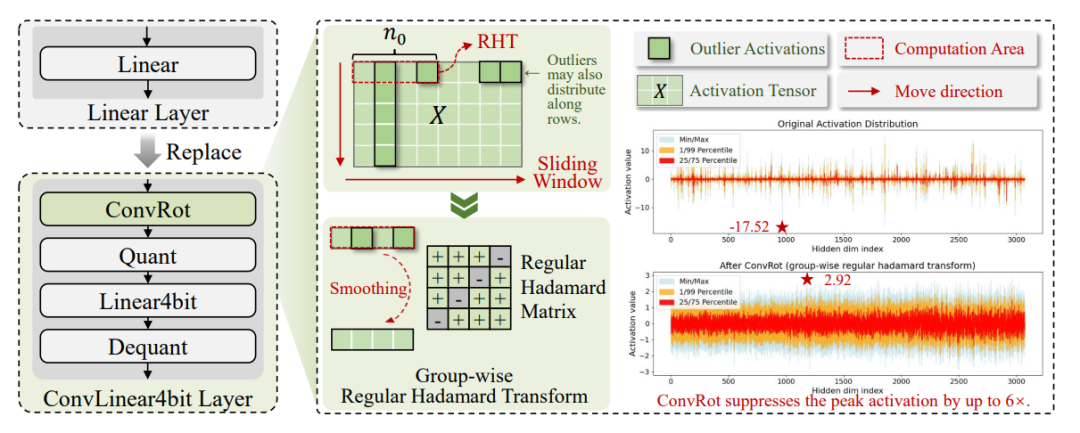
图4:左:ConvLinear4bit 作为线性层的即插即用替代模块。右:ConvRot 在激活张量的非重叠滑动窗口上应用RHT。
总之,ConvRot 提供了一种灵活机制,可通过调整参与异常值重分配的通道数量,在计算开销与平滑效果之间进行权衡。基于矩阵乘法的实现方式能高效利用现代 GPU 的计算流水线,而 ConvLinear4bit 则为大规模扩散模型提供了实用、即插即用的 W4A4 量化方案,在不牺牲图像质量的前提下,显著降低了内存占用并加速了推理过程。
实验评估
研究团队在 FLUX.1-dev 和 FLUX.1-Schnell 模型上对比了 ConvRot、SVDQuant 以及 BF16 基线。如表2所示,团队从相似性(LPIPS、PSNR)和生成质量(FID、IR)两个维度进行评估。
与 BF16 基线相比,ConvRot 显著降低了内存占用和延迟,同时仅引入微小的图像质量损失。各项指标表明,这种质量下降主要源于全 INT4 推理下模型表征能力的减弱,而非由行向异常值导致。尽管如此,ConvRot 在当前所有 INT4 方法中仍取得了SOTA水平的视觉质量。
为提升图像质量,研究团队采用了混合精度策略:经验性地选取 20% 的网络层以 INT8 精度执行,其余层保持 INT4。该配置有效恢复了图像的细粒度细节和感知质量,性能接近采用 16 位 LoRA 分支的 SVDQuant。
如表2所示,ConvRot 在内存效率、延迟和图像保真度之间取得了优异的平衡。
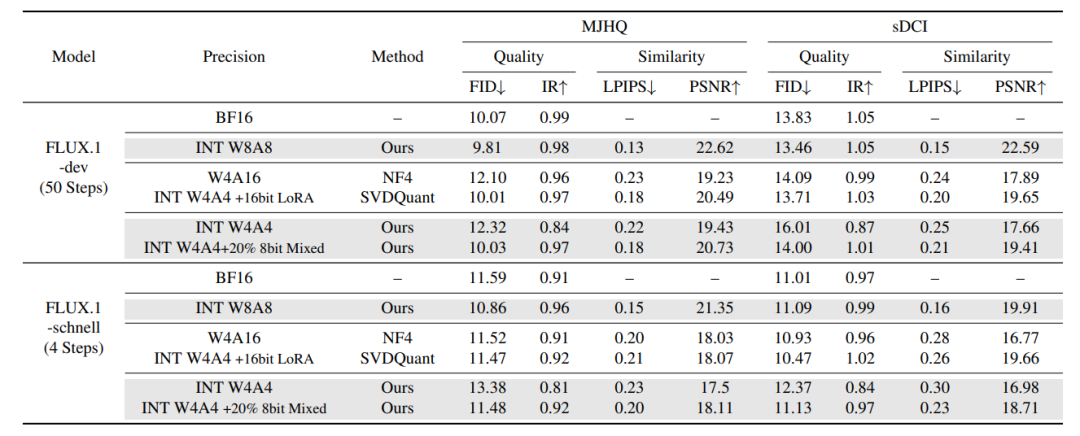
表2. 不同量化方法的端到端性能对比。LPIPS 和 FID 越低、PSNR 和 IR 越高,表示性能越好。
图6进一步说明,相比于全 INT4 推理,引入少量 INT8 层能够显著增强生成图像的纹理锐度和全局一致性。

图6:混合精度推理对图像生成质量的定性影响。
在单张 NVIDIA 4090 GPU 上对 FLUX.1-dev 模型(50 步)的测试结果(表3)进一步证实了其效率:
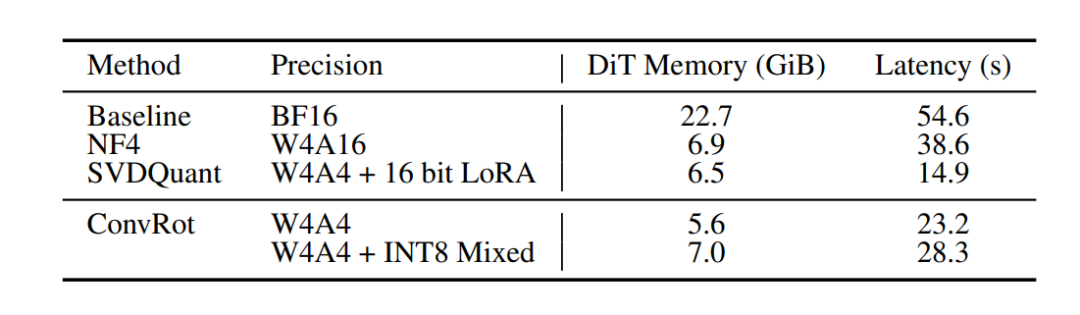
表3:DiT 模型的内存占用与推理延迟对比。
大量实验表明,ConvRot 能够稳定抑制异常值,在保持高保真图像生成的同时,节省了 4.05 倍内存,并实现了 2.26 倍的推理加速。
 发表于 2025-12-14 21:56:42
|
查看: 328|
回复: 0
发表于 2025-12-14 21:56:42
|
查看: 328|
回复: 0
