在构建大规模直播服务时,单台服务器往往无法满足海量用户并发与跨地域访问的需求。主流的单线程异步流媒体服务(如Nginx-rtmp或SRS)虽然性能优异,但单个进程仅能利用单核CPU。为了充分发挥多核服务器的性能并实现横向扩展,构建一个高效的直播集群势在必行。
直播集群的核心架构
本文将以SRS为例,深入剖析RTMP直播集群的搭建。SRS提供了一套清晰实用的集群方案,主要定义了两种角色:
-
边缘服务器 (Edge RTMP Server)
- 功能:直接面向终端用户,处理用户的RTMP推流和拉流请求。
- 上行:将接收到的推流转推至中心服务器。
- 下行:当本地无目标流时,向中心服务器发起回源拉流。
-
中心服务器 (Origin RTMP Server)
- 功能:作为流媒体的源站,不直接服务终端用户。
- 职责:接收来自边缘服务器的转推流,并响应边缘服务器的回源拉流请求。

通过这两种角色的组合,可以灵活构建机房内多进程集群、跨服务器集群乃至多地域部署的构建应对高并发的系统架构。
集群工作流程详解
下图展示了一个典型的多地域集群工作流程:
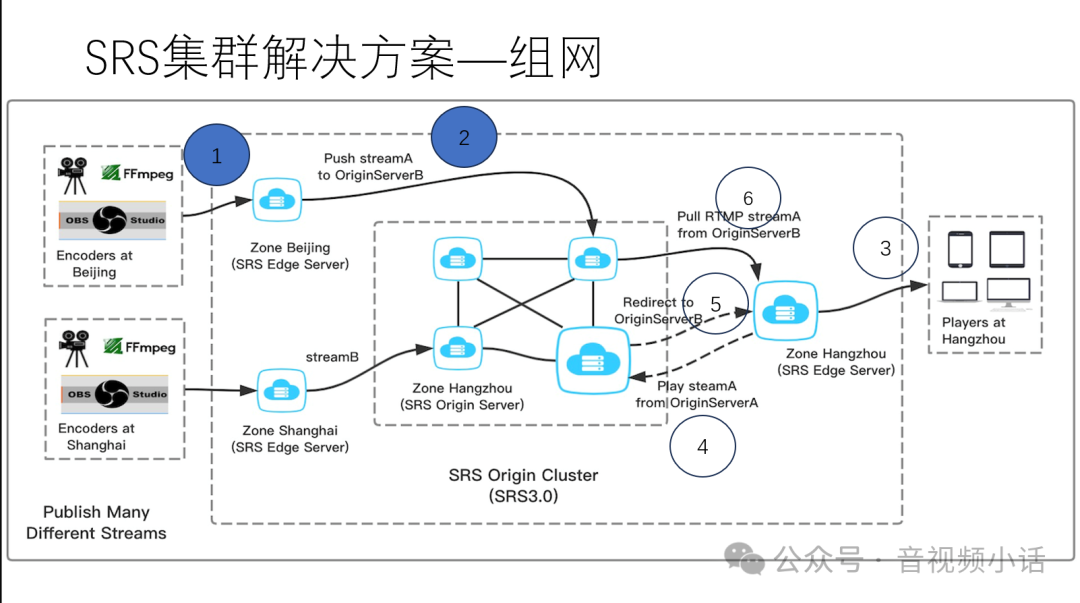
假设我们拥有北京、上海、杭州三个边缘节点,以及一个包含多台机器的中心源站集群。
推流流程(以Stream A为例):
- 北京用户将流
Stream A 推送到北京边缘服务器。
- 北京边缘服务器立即将
Stream A 转推至中心源站集群中的某台服务器(例如 OriginServerB)。
拉流流程:
- 杭州用户向杭州边缘服务器发起对
Stream A 的拉流请求。
- 杭州边缘服务器本地若无此流,则向中心源站发起回源拉流请求。
- 假设请求先到达
OriginServerA,它发现本机没有 Stream A,便会通过集群协作接口(Coworker HTTP API)查询该流实际所在的服务器地址。
- 查询得知
Stream A 在 OriginServerB 上,OriginServerA 会向杭州边缘服务器返回一个RTMP 302重定向响应。
- 杭州边缘服务器根据重定向地址,直接连接到
OriginServerB 成功拉取到 Stream A,并分发给用户。
至此,系统自动完成了从推流到跨地域拉流的全过程,对用户完全透明。
SRS集群配置实践
SRS的集群配置逻辑清晰。以下是一个简单的配置示例:
其核心逻辑是:所有推流由边缘服务器转推到中心服务器集群;用户从边缘服务器拉流,若边缘服务器没有缓存,则自动向配置的中心服务器列表进行回源拉取。若被询问的中心服务器没有该流,则通过 coworkers 机制查询到流所在的正确服务器,并通过302跳转完成拉流。
这套方案无需二次开发,具备简单、易用、高效的特点。
默认方案的局限性与优化
然而,默认的边缘服务器架构在特定场景下存在局限性。
问题:重复回源
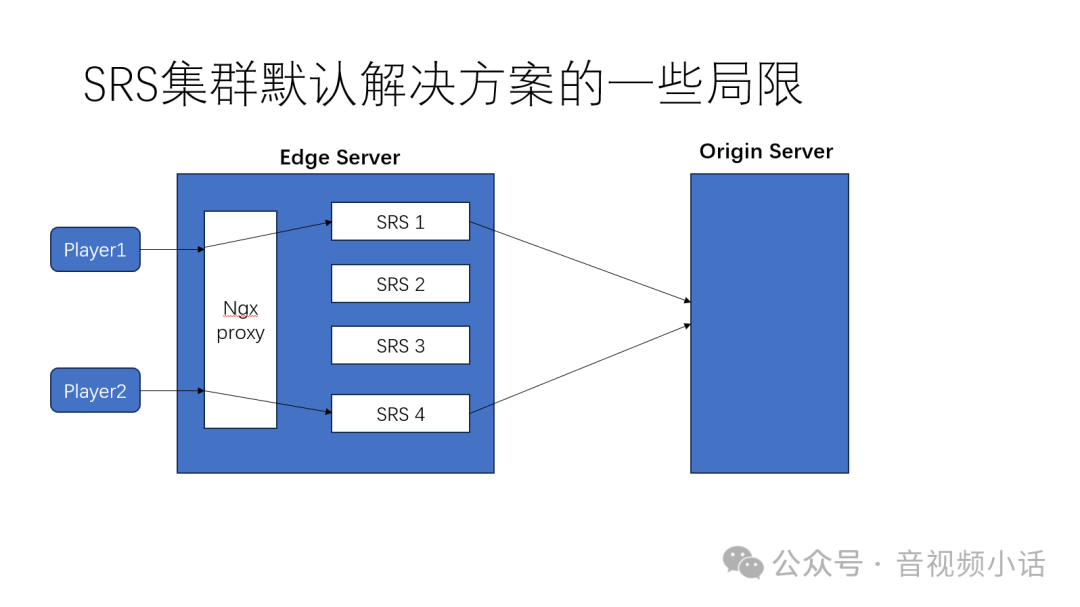
当一台边缘服务器上启动多个SRS实例(例如通过利用Nginx进行TCP负载均衡接入用户)时,不同实例上的用户请求同一路流,可能会导致每个实例都独立向中心服务器回源,造成带宽浪费和源站压力。
解决方案:本地源站
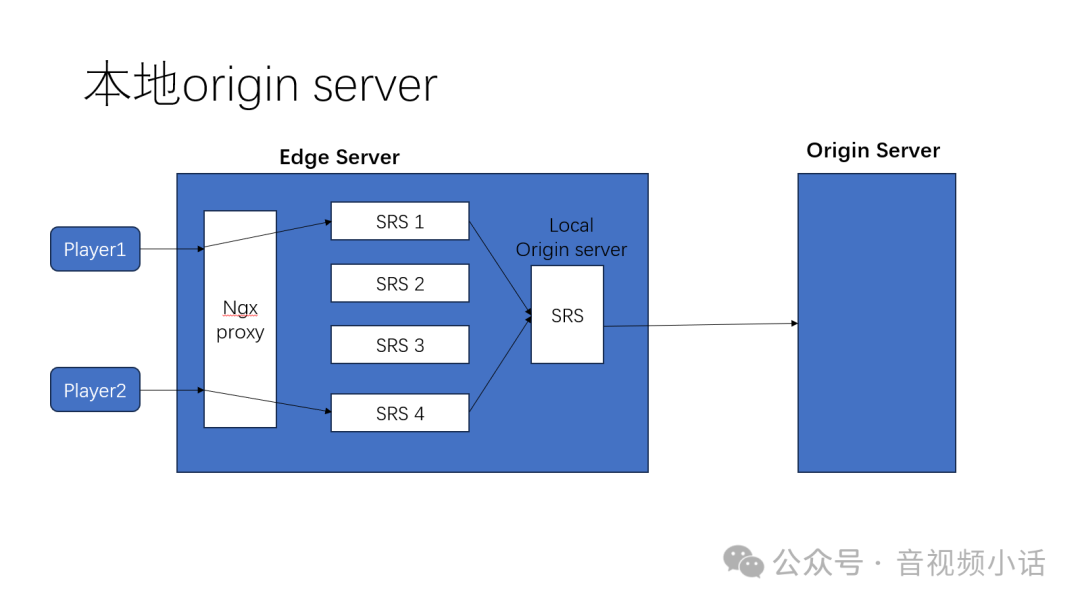
在边缘服务器内部署一个配置为origin模式的SRS实例。将该服务器上所有SRS边缘实例的origin指向这个本地源站实例。这样,所有推流汇聚到本地源站,所有回源请求也由它统一处理,完美避免了重复回源。
大规模集群管理
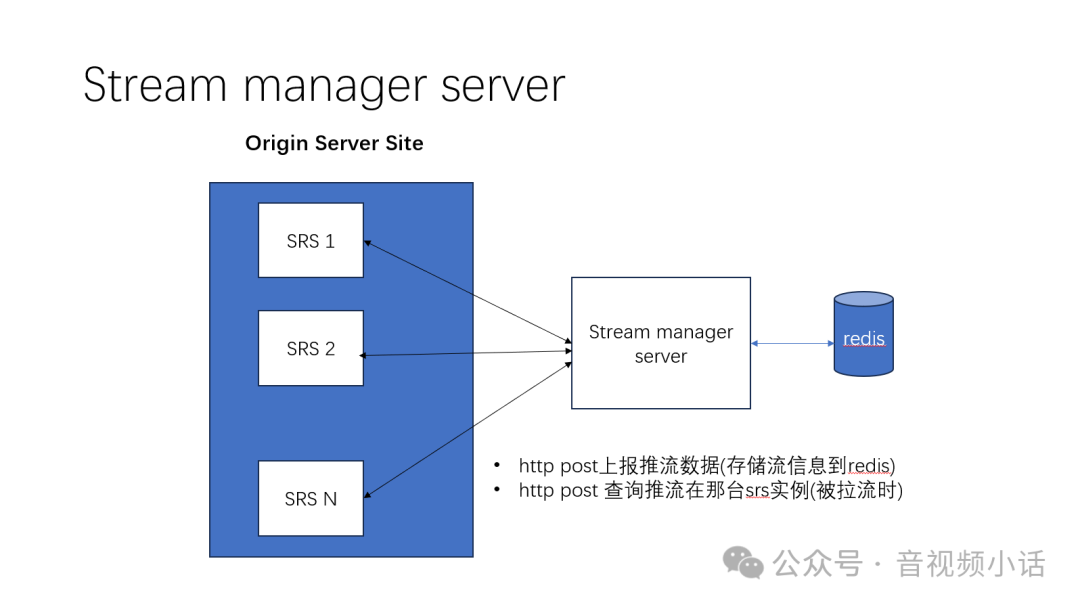
当中心源站实例数量非常庞大时,原生的coworkers列表查询效率会降低。此时可以引入一个流管理服务 (Stream Manager Server)。
这个服务可以用Python、Go、Java等语言开发,核心功能包括:
- 流信息上报:边缘服务器推流时,通过HTTP POST将流信息(如流名称、所在服务器IP端口)上报至管理服务,服务将其存储于高效的键值数据库(如借助Redis进行状态管理)。
- 流信息查询:当中心服务器需要查询流位置时,向该管理服务发起HTTP查询,服务返回流所在的确切服务器地址。
通过引入这个轻量级的中心化流管理组件,可以极大地提升超大规模集群的流调度效率和可管理性。 |  发表于 2025-12-15 04:32:17
|
查看: 220|
回复: 0
发表于 2025-12-15 04:32:17
|
查看: 220|
回复: 0
