本文对NVIDIA数据中心GPU进行全面技术解析与对比,涵盖CPU+GPU超级芯片、传统加速卡及先进互连架构。内容涉及Ampere、Hopper、Ada Lovelace等所有主流产品线,并重点分析多实例GPU、NVLink/NVSwitch及NVL72等关键技术。
1. NVIDIA数据中心GPU架构演进
NVIDIA GPU历经多次架构迭代,每一代都针对多样化的数据中心负载进行优化。以下是主要架构的演进里程碑:
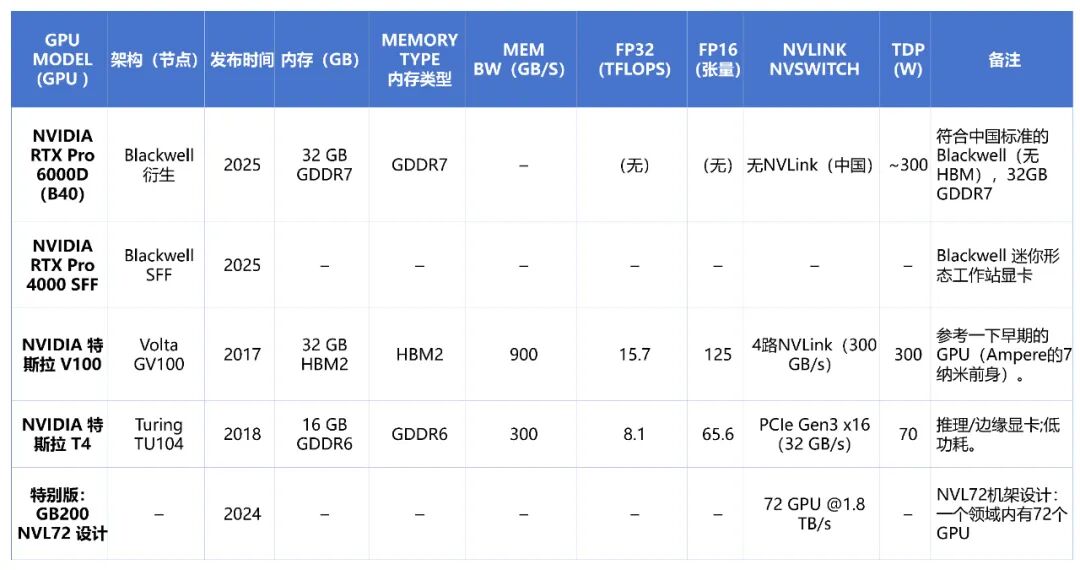
- Volta: 2018年推出,代表产品为Tesla V100。它首次引入了Tensor Core用于混合精度计算,并支持NVLink 2.0互联,FP16计算性能达到112 TFLOPS。
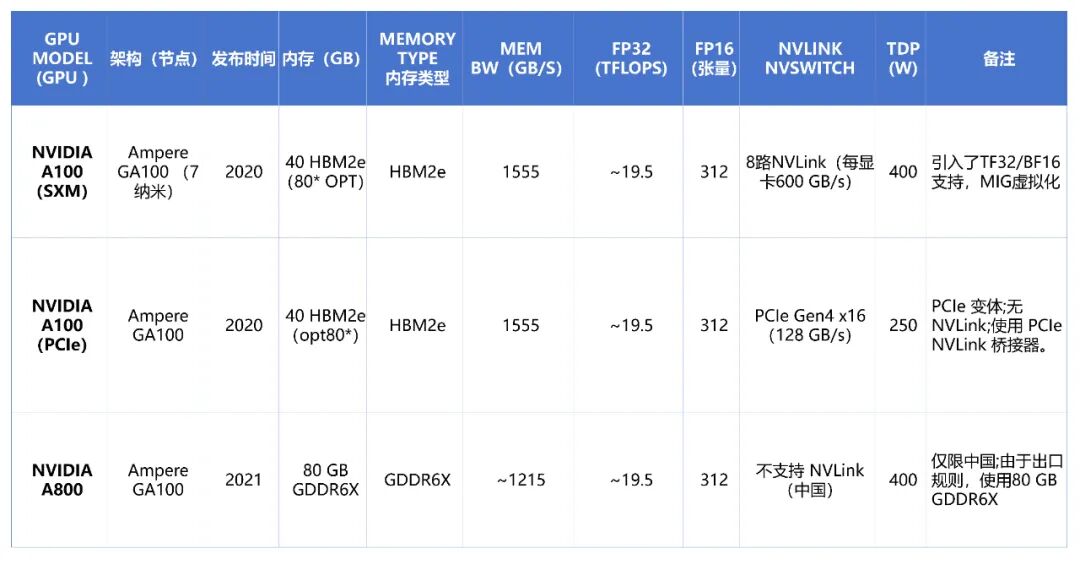
- Ampere: 2020年发布的第八代架构,代表产品A100基于7nm工艺,集成了约540亿晶体管。其关键创新包括第三代Tensor Core、对TF32与BFLOAT16数据格式的支持,以及多实例GPU虚拟化技术。A100 SXM模块的FP16矩阵运算性能达到约312 TFLOPS,并通过NVLink 3.0实现了每GPU 600 GB/s的高速互联。
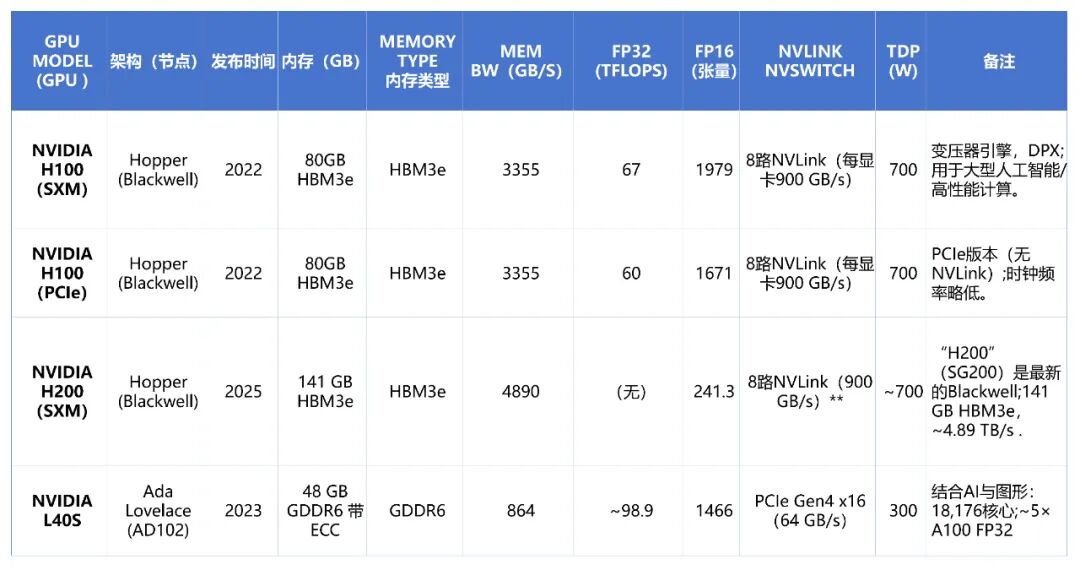
- Hopper: 2022年发布的第九代架构,代表产品H100基于4nm工艺。它引入了Transformer引擎以加速FP8/FP16混合精度下的LLM训练,并将HBM内存升级至HBM3e。H100 SXM的FP16性能高达1,979 TFLOPS,NVLink 4.0带宽也提升至每GPU 900 GB/s。后续的H200则进一步将HBM3e容量提升至141GB,带宽接近4.89 TB/s。
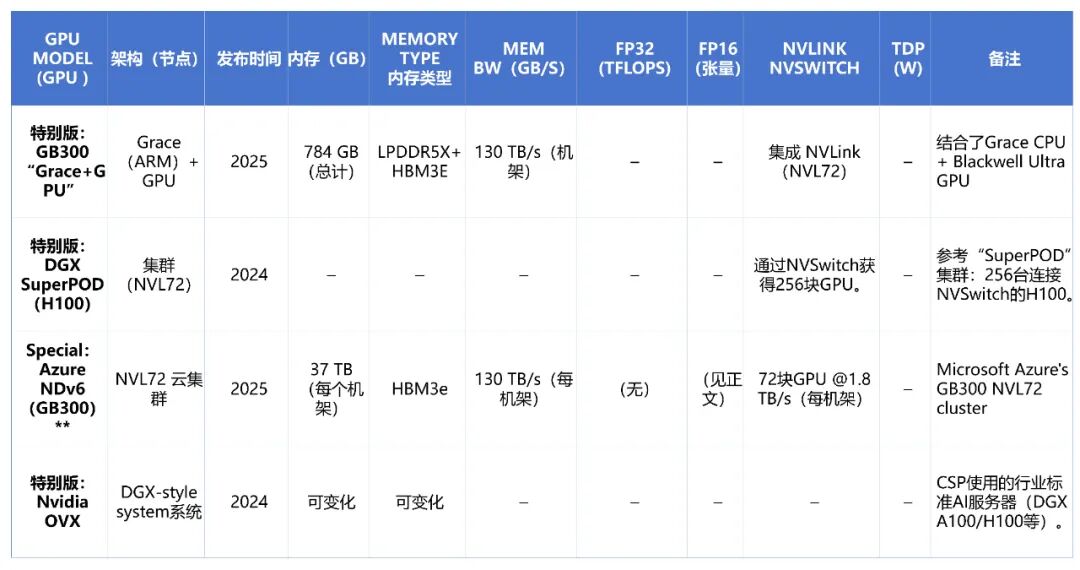
- Grace超级芯片: 2022至2025年间,NVIDIA将GPU与基于ARM架构的CPU融合,形成超级芯片。例如GB300集成了72核Grace CPU与Blackwell Ultra GPU,宣称AI算力可达20 PFLOPS,并通过统一内存架构实现CPU与GPU的高效协同,专为大规模AI与HPC应用场景设计。
- Ada Lovelace: 2023年面向数据中心发布的架构,代表产品L40S。它采用与消费级RTX 4090同源的AD102核心,拥有18,176个CUDA核心和48GB GDDR6 ECC显存,在图形渲染和AI推理工作负载中表现突出,官方称其FP32吞吐量可达A100的5倍。
2. NVIDIA数据中心GPU规格详情
下表汇总了当前主流NVIDIA数据中心GPU的关键规格参数对比:

3. NVIDIA数据中心GPU的详细特性
内存与计算
NVIDIA数据中心GPU具备大容量、高带宽的板载内存,以支持庞大的模型与数据集。
- A100 80GB 版本采用HBM2e,带宽为1.555 TB/s。
- H100 升级至HBM3e,带宽达到约3.355 TB/s。
- H200 则进一步将HBM3e容量推至141GB,带宽高达约4.89 TB/s。
- 相比之下,L40S 等注重成本效益的型号使用GDDR6显存,带宽为864 GB/s。这反映了在极致带宽与成本功耗之间的设计权衡。
计算性能方面,架构代际提升显著:
- A100 SXM可提供约19.5 TFLOPS的FP64/FP32性能。
- H100 SXM的FP32性能提升至67 TFLOPS,FP16性能更是高达1,979 TFLOPS。
- L40S凭借更多的CUDA核心,在特定推理与图形任务中展现出强大竞争力。
多GPU互连:NVLink、NVSwitch与NVL72
高性能GPU互连是释放多卡算力的关键。NVIDIA的解决方案远超PCIe标准:
- NVLink: 提供GPU间的高速直连。Hopper架构的H100在NVLink 4.0上实现了每GPU 900 GB/s的双向带宽。
- NVSwitch: 用于构建全网状互联,允许多个GPU(如8个或16个)在一个节点内像单一总线一样通信,这对紧密耦合的训练任务至关重要。
- NVL72: Blackwell架构引入的革命性设计,将单个NVLink域的GPU数量扩展至72个,每GPU链路速度提升至1.8 TB/s。这种Scale-Up设计能将超大规模AI模型的训练与推理效率提升数倍至数十倍,是构建万卡级AI集群的基础。
多实例GPU与虚拟化
为提高大型GPU在云环境中的利用率,从Ampere架构开始引入了多实例GPU技术。例如,一块A100或H100 GPU可以被硬件划分为最多7个独立的实例,每个实例拥有隔离的内存、缓存和计算单元,从而安全地服务于多个用户或任务。而L40S等专注于图形的GPU则不支持MIG。
内存架构与能效
先进的内存架构是支撑算力的另一基石。采用HBM2e/HBM3e的GPU通过NVLink可以实现多卡内存的统一寻址,形成一个聚合的、高速的共享内存池。在Grace超级芯片中,CPU与GPU更通过统一内存地址空间实现了更深层次的融合。
随着算力密度剧增,散热与供电成为系统设计核心。NVL72机柜的热设计功耗高达120kW,推动了直接液冷等先进散热技术的普及。整个数据中心的基础设施,从机架、电源到冷却系统,都需要围绕高密度GPU集群进行全新设计,这体现了现代AI算力基础设施的系统工程复杂性。

|  发表于 2025-12-15 05:06:14
|
查看: 558|
回复: 0
发表于 2025-12-15 05:06:14
|
查看: 558|
回复: 0
