先问一个扎心的问题:当你给 ChatGPT、Cursor 或 Claude Code 发送了一个复杂的 Prompt 之后,接下来的 30 秒到 1 分钟里,你在干什么?
我观察过很多开发者,90% 的人是这样的:双手离开键盘,甚至抱在胸前,眼睛死死盯着屏幕上那个闪烁的光标,看着文字一个字一个字地蹦出来。心里默默念叨:“快点,再快点……”
在计算机科学里,这叫什么?这叫 I/O 阻塞(Blocking I/O)。
在这个场景里,AI 是那个慢速的 I/O 设备(就像早期的磁带机或机械硬盘),而你——拥有几十亿神经元、算力无法估量的 人类大脑(CPU),却因为等待这个 I/O 响应,被迫挂起(WAIT),处于完全闲置的状态。
这不仅仅是时间的浪费,这是算力的极大浪费。很多开发者抱怨:“AI 有时候太慢了,打断了我的思路。” 但事实的真相可能是:不是 AI 慢,而是你的“调度算法”还停留在单核时代。
职场新分层:单核工作者 vs. 多核工作者
随着 AI 能力的普及,代码生成的质量差距正在缩小。未来的竞争壁垒,将从“你会写什么 Prompt”转移到 “你如何管理与 AI 的并发交互”。
这导致了两种工作模式的分化,我们可以通过下面这张“大脑CPU”调度时序图来直观对比:
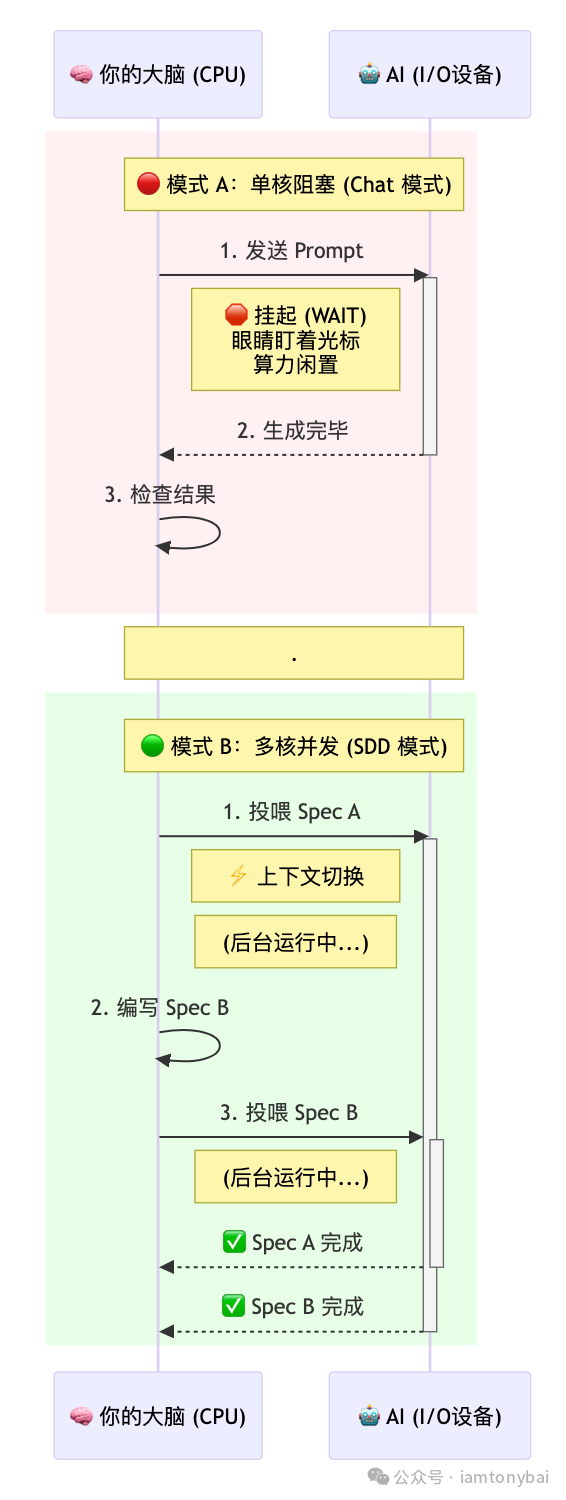
🔴 模式 A:单核工作者(同步阻塞)
- 特征:就像单核 CPU 跑单线程程序。发完指令后,必须盯着屏幕等结果,算力被强行挂起(Wait)。
- 痛点:图中红色的区域就是被浪费的生命。只要 AI 稍微卡顿,你的工作流就被切断了。
🟢 模式 B:多核工作者(异步并发)
- 特征:就像现代操作系统的分时调度(Time-sharing)。人脑作为 OS Scheduler,维护着多个任务的状态。
- 优势:图中绿色的区域显示,当 AI 在后台“搬砖”时,你的大脑立刻切换(Switch)到下一个任务(编写 Spec B)。
- 收益:在 AI 响应延迟短期内无法消除的前提下,模式 B 的产出效率是模式 A 的 2 倍甚至更多。
第一性原理:如何优化大脑的“调度算法”?
既然“多核模式”效率极高,为什么 99% 的人做不到呢?核心难点在于 “上下文切换(Context Switching)”的成本。
做过底层开发的都知道,CPU 在切换线程时,必须执行一个昂贵的操作:Save Context(保存现场)和Restore Context(恢复现场)。
人脑也是一样,甚至更弱。 根据认知心理学的“米勒定律”,人类的工作记忆(Working Memory,相当于 CPU 的 L1 Cache)容量极小,只有 7±2 个单位。
当你从“编写 Go 后端”切换到“调试 Vue 前端”时,你的 L1 Cache 会瞬间被清空。等你切回来时,你需要重新阅读代码、重新回忆变量名——这个过程就是 “冷启动”,极度消耗能量。
所以,要实现高效的“人脑并发调度”,我们不能靠死记硬背,必须利用 第一性原理 优化我们的交互协议。
上下文卸载 (Context Offloading)
计算机如何解决内存不足的问题?虚拟内存(Swap)。 把不用的数据换出到硬盘里。
我们要模仿这个机制。不要试图在脑子里维持与 AI 的对话状态。 凡是发给 AI 的任务,必须是一个 “全量的、自包含的数据包”。在这个数据包里,包含了 AI 完成任务所需的所有背景、约束和目标。
一旦发送出去,你的大脑应当能 彻底遗忘(Forget) 这个任务,清空 L1 Cache 去处理下一个线程,直到收到“完成”的中断信号。
无状态交互 (Stateless Interaction)
目前的“Chat 模式”是典型的 有状态(Stateful) 交互。你必须记得上一句说了什么,下一句才能接得上。这是并发的天敌。
高效的调度算法要求我们采用 无状态(Stateless) 交互。每一次与 AI 的交互,都应该是一次独立的 API 调用。我不关心你记不记得上下文,我会在这一次指令中把上下文重新传给你。
我们可以用一张系统架构图来理解这种“大脑调度优化”:

结论很明显: 要让大脑 CPU 不阻塞,关键不在于你思考得有多快,而在于你是否拥有一个 “外部存储(External RAM)” 机制。你需要一种介质,能够帮你 低成本地固化上下文,让你敢于放手(Fire),也方便你随时捡起(Resume)。
那么,在软件工程领域,这种“固化上下文的介质”叫什么呢?
落地实战:Spec 就是你的“外部存储”
答案就是 Spec(规范说明书)。而这种全新的开发范式,我们称之为 SDD (Spec-Driven Development,规范驱动开发)。
为什么“聊天(Chat)”是并发的天敌?
目前主流的“Chat-based Coding”本质上是 同步且有状态 的。你输入:“把这个函数改一下。” AI 问:“改成啥样?” 你回:“像上次那个一样。”
这就完了。 你的大脑被迫挂载了海量的历史上下文,你必须在线,必须记得“上次”是指哪次。一旦去回个邮件,回来你就断片了。
SDD 如何实现“异步并发”?
在 SDD 工作流中(特别是配合像 Claude Code、Gemini Cli 这样的新一代 CLI 编码智能体工具),交互模式发生了质变:
- Context Offloading(上下文固化): 你不再在对话框里碎碎念,而是打开一个 Markdown 文件(Spec),把接口定义、业务逻辑、边界条件、甚至测试用例全部写下来。写完的那一刻,你的大脑内存就释放了。
- Stateless Execution(无状态执行): 你将这个 Spec 文件投喂给 AI。对于 AI 来说,这是一个全量的、自包含的原子任务。它不需要知道你昨天说了什么,它只需要根据这份文档执行。
- Fire and Forget(即发即忘): 指令发出后,你不需要盯着光标。AI 在后台读文档、写代码、跑测试。你可以立刻切换到下一个 Spec 的编写中。
让我们看下这张 SDD 并发工作流时序图:
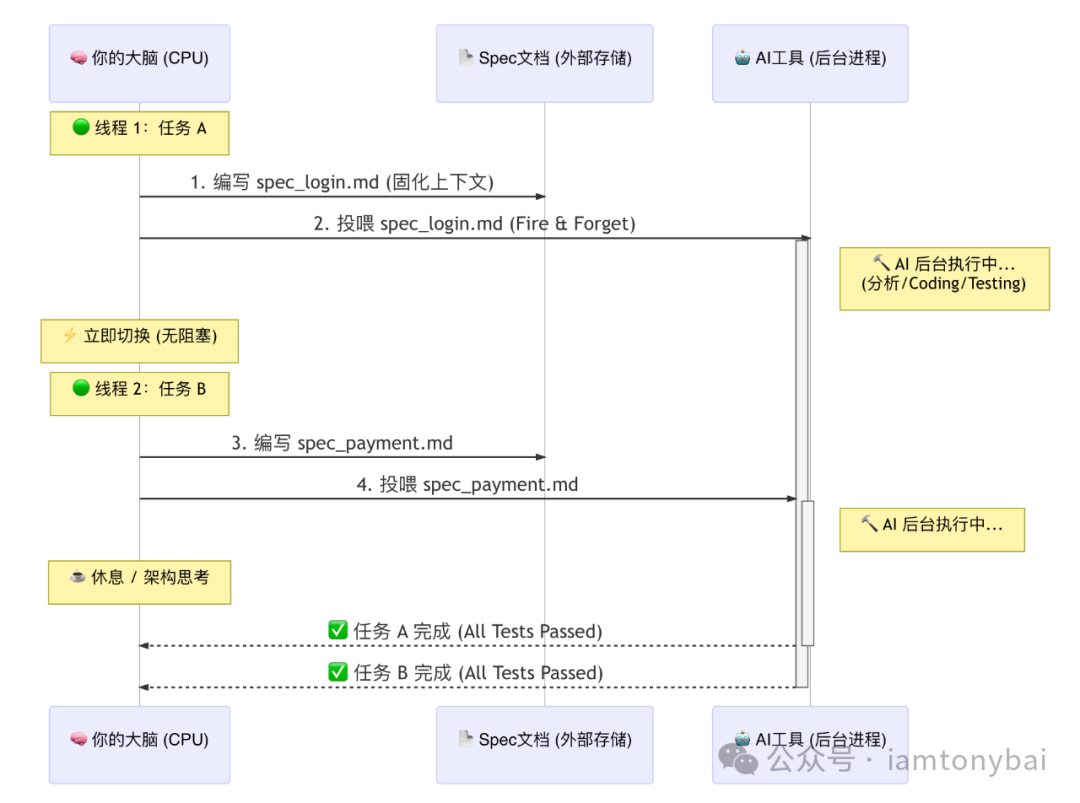
Spec,就是你发给后台进程的“异步数据包”。它让你的大脑从“内存条”变成了高效的“调度器”。
写在最后:工具与范式,决定了你的并发量
除了思维的升级,你必须掌握一套支持“异步并发”的开发工具链。如果你还在用浏览器里的聊天窗口写代码,你依然很难摆脱“I/O 阻塞”。真正的解法,是构建一套 基于 Claude Code/Gemini Cli… 的 SDD 工作流。
这不仅是工具的改变,更是软件工程的回归—— 从“堆砖头(Coding)”回归到“画图纸(Architecting)”。
- 你可以只做定义者:你的核心工作不再是纠结 for 循环怎么写,而是编写清晰、严谨的 Spec。
- 让 AI 做实现者:AI 成为你的异步协程。它在后台自动完成实现、修复、测试的闭环。
这才是多核工作者的终极形态:你负责定义世界(Spec),AI 负责构建世界(Code)。 掌握 现代前端框架与工程化 思维,能帮助你更好地进行这种顶层设计。别再盯着光标发呆了。写好 Spec,剩下的交给 AI。
 发表于 2025-12-15 07:54:12
|
查看: 291|
回复: 0
发表于 2025-12-15 07:54:12
|
查看: 291|
回复: 0
