背景
现有的视频编辑方法普遍面临一个核心矛盾:专家模型虽然精度高,但严重依赖繁琐的人工掩码输入;而统一的免掩码模型虽然便捷,却因缺乏显式的空间线索,导致文本指令与编辑区域映射模糊、定位不准。这一两难困境在多实例编辑场景下尤为突出,迫切需要一种既能保持统一框架便捷性,又能实现专家级编辑精度的全新范式。
方法
2.1 Chain of Frames:从“直接编辑”到“推理后编辑”
受大语言模型中Chain-of-Thought(思维链)推理范式的启发,研究人员提出了VideoCoF——首个将“链式推理”理念引入视频生成与编辑领域的框架。
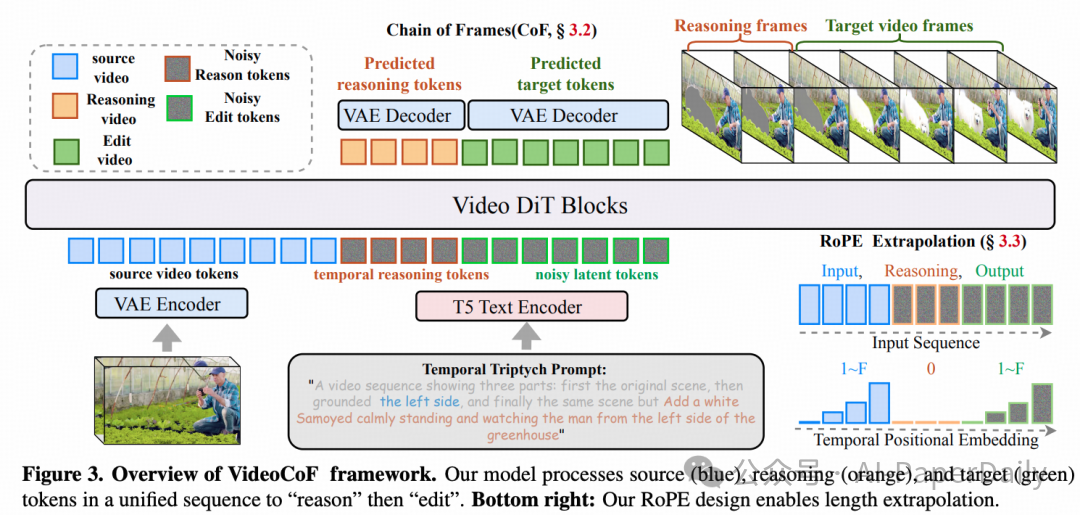
其核心思想是强制视频扩散模型遵循“观察→推理→编辑”的明确流程:先预测出需要编辑的区域,再针对该区域执行具体的编辑操作。这一流程设计,既摆脱了对人工掩码的依赖,又实现了指令与编辑区域的精准对齐。
形式化地,给定源视频、推理视频和目标视频,首先通过VAE编码器将它们编码为潜在表示:
$$
\\mathbf{z}^{src} = \\mathcal{E}(\\mathbf{v}^{src}), \\quad \\mathbf{z}^{inf} = \\mathcal{E}(\\mathbf{v}^{inf}), \\quad \\mathbf{z}^{tgt} = \\mathcal{E}(\\mathbf{v}^{tgt})
$$
其中 \(\mathbf{z}^{src}\) 和 \(\mathbf{z}^{tgt}\) 形状为 \([L, C, H, W]\),\(\mathbf{z}^{inf}\) 形状为 \([N, C, H, W]\)。\(L\) 和 \(N\) 分别表示帧数,\(C, H, W\) 为通道、高度和宽度。关键创新在于时序拼接策略:
$$
\\mathbf{z}^{cat} = [\\mathbf{z}^{src}; \\mathbf{z}^{inf}; \\mathbf{z}^{tgt}]
$$
这种拼接不仅保持了帧序列的连续性,更重要的是在时序上构建了“观察-推理-生成”的因果链。通过将推理过程显式分离,模型学会了如何将抽象的编辑指令映射到视频中的特定空间区域,从而从根本上解决了传统方法中指令与区域关联性弱的难题。
2.2 推理帧机制:灰度渐变高亮设计
推理帧的设计是VideoCoF框架得以运作的核心。研究发现,标准的视频扩散模型对二值掩码(纯黑或纯白像素)的敏感性不足,这源于其生成先验与二值信号在数据分布上存在较大差异。为解决此问题,本文设计了灰度渐变高亮区域作为推理阶段的监督真值,其物理意义可视作“编辑重要性热力图”。

具体训练过程如下:给定时间步 \(t\) 和高斯噪声 \(\epsilon\),仅对推理部分和目标编辑部分添加噪声:
$$
\\mathbf{z}_t^{cat} = [\\mathbf{z}^{src}; \\alpha_t \\mathbf{z}^{inf} + \\sigma_t \\epsilon^{inf}; \\alpha_t \\mathbf{z}^{tgt} + \\sigma_t \\epsilon^{tgt}]
$$
这种渐进式的噪声添加策略,既完整保留了源视频的上下文信息,又确保了模型必须通过观察完整的上下文来预测推理帧。模型的目标是预测速度场 \(\mathbf{v}\),训练损失仅监督推理帧和目标帧部分:
$$
\\mathcal{L} = \\mathbb{E}_{\\mathbf{z}_0^{cat}, \\epsilon, t, c} [\\| \\mathbf{v} - \\hat{\\mathbf{v}}_{\\theta}(\\mathbf{z}_t^{cat}, t, c) \\|^2 ]
$$
其中 \(c\) 为文本条件。
2.3 RoPE对齐:解决索引冲突与长度外推
现有方法在进行时序拼接时通常使用连续索引,这导致模型难以泛化到更长的视频序列。更严重的是,简单的索引重置策略会引发索引冲突,使得推理帧中的伪影“泄露”到生成视频的首帧。
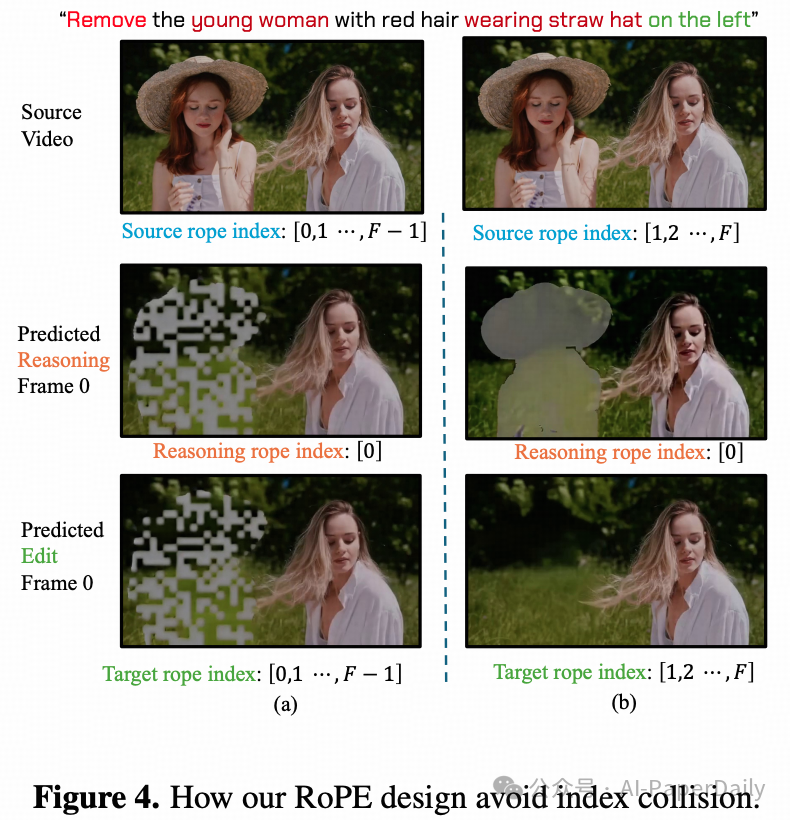
设 \(I{src}\)、\(I{inf}\)、\(I_{tgt}\) 分别为源、推理、目标视频片段的索引集合。当 \(L = N\) 时,共享索引的位置会产生特征混淆。对于简单的重置方案:
$$
I_{src} = \\{0, 1, ..., L-1\\}, \\quad I_{inf} = \\{0, 1, ..., N-1\\}, \\quad I_{tgt} = \\{0, 1, ..., L-1\\}
$$
本文提出了错位分配的RoPE策略:
$$
I_{src} = \\{0, 1, ..., L-1\\}, \\quad I_{inf} = \\{L, L+1, ..., L+N-1\\}, \\quad I_{tgt} = \\{L+N, L+N+1, ..., 2L+N-1\\}
$$
这不仅完全避免了索引冲突,还有效保持了跨片段的运动连贯性。实验表明,该设计使模型能够无需额外训练,即可外推到训练长度4倍(141帧)的视频。
2.4 实例级数据构建:多模态协同管道
为了训练具备复杂空间关系推理能力的模型,本文构建了一个专门的数据生成管道。其中的关键挑战是如何自动生成包含精确空间关系描述(如“左侧的汽车”、“最大的杯子”)的多实例编辑数据。
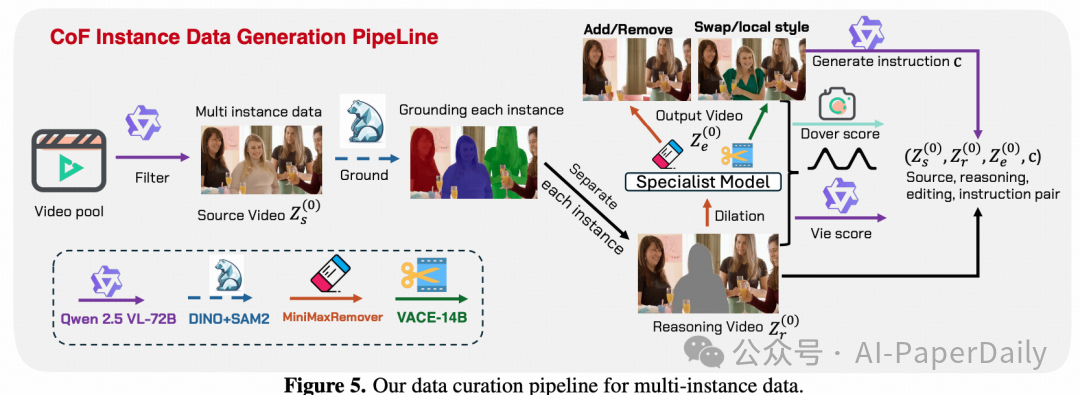
首先,使用Qwen-VL 72B模型扫描Pexels视频库,自动筛选出包含多实例的复杂场景。然后,采用DINO+SAM2的组合进行实例级分割,为视频中的每个对象生成精确的掩码。针对不同的编辑任务,采用不同策略:
- 对象增删:使用MinimaxRemover工具消除特定实例;对于添加任务,则通过逆向过程生成。
- 对象替换/局部风格迁移:利用VACE-14B模型的修复模式,并结合GPT-4o生成的创意提示词进行操作。
数据质量保障:所有生成的视频对都经过双评分过滤机制:
- 美学质量:使用Dover评估生成视频的整体视觉美感。
- 编辑保真度:使用VIE指标衡量编辑操作是否准确遵循了指令,并保持了视频其他部分的一致性。
通过这种多模态协同的自动化管道,从Senõrita 2M数据集中筛选出5万对高质量的视频训练数据。每个样本都包含明确的空间关系标注,从而使模型能够学会进行精准的实例级推理。
实验
在自建的VideoCoF-Bench评测集上,仅使用5万对数据训练的VideoCoF模型显著超越了当前的SOTA方法。在指令遵循率上达到8.97(对比ICVE的7.79),编辑成功率高达76.36%(对比ICVE的57.76%)。
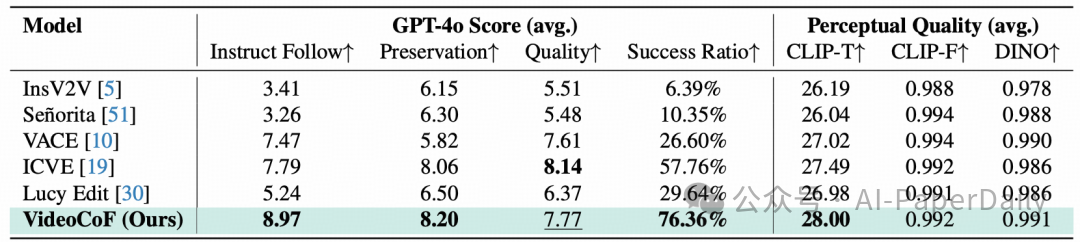
在多实例移除任务中,本文方法的准确率达到了92.3%,而ICVE仅为67.8%。最令人振奋的结果体现在长度外推能力上——在141帧的长视频测试中,得益于RoPE设计,VideoCoF生成的视频保持了画面清晰和运动连贯,而基线方法则出现了严重的模糊和时序错位。这些结果从多个维度验证了“先推理,后编辑”这一范式在精度与泛化性上的双重优势。

论文信息:Unified Video Editing with Temporal Reasoner
 发表于 2025-12-15 09:26:55
|
查看: 233|
回复: 0
发表于 2025-12-15 09:26:55
|
查看: 233|
回复: 0
