近年来,基于扩散模型的视频生成技术取得了显著进展,大幅提升了视频编辑的真实感与可控性。然而,实现纯文本驱动的视频对象添加与移除任务,仍然面临着巨大挑战。这不仅需要精准地根据文字描述定位目标对象,还必须同时保持背景的连续性、时序的一致性以及语义的准确匹配。现有的大多数方法在推理时仍需依赖用户提供的对象掩码或参考帧来确定编辑区域,这一要求不仅提高了使用门槛,也限制了模型在真实应用场景中的实用性与泛化能力。
为攻克上述难题,研究团队提出了 LoVoRA(Learnable Object-aware Localization for Video Object Removal and Addition)—— 一个真正意义上仅需文本驱动、无需任何掩码或参考帧的视频对象移除与添加框架。LoVoRA能够仅凭文本提示精准定位视频中需要编辑的区域,并执行时序一致、背景自然的编辑操作,无需任何人工辅助控制信号。大量实验与用户评测表明,LoVoRA在编辑质量、背景一致性和时序稳定性等多项指标上均超越了现有的基线方法。
数据集构建
现有的基于指令的视频编辑数据集,如InsViE、Ditto等,在文本引导的视频操作上已具备一定能力,但仍存在一些局限:空间与时间分辨率较低;因逐帧生成导致背景不一致;以及对对象添加与移除场景的覆盖有限。为了克服这些问题,并为提出的框架奠定基础,我们构建了一个专门用于视频中对象级添加与擦除的高质量数据集。
我们的数据集构建在高保真图像编辑数据集NHR-Edit之上,并通过一个多级流水线合成为时间上一致的视频编辑序列。与之前的工作相比,我们的数据集具有更好的背景一致性、准确的对象级时空掩码,以及语义上更为鲁棒的文本指令。同时,它提供了密集的运动掩码监督,这使得LoVoRA中的目标感知编辑定位模块能够进行有效的训练与评估。
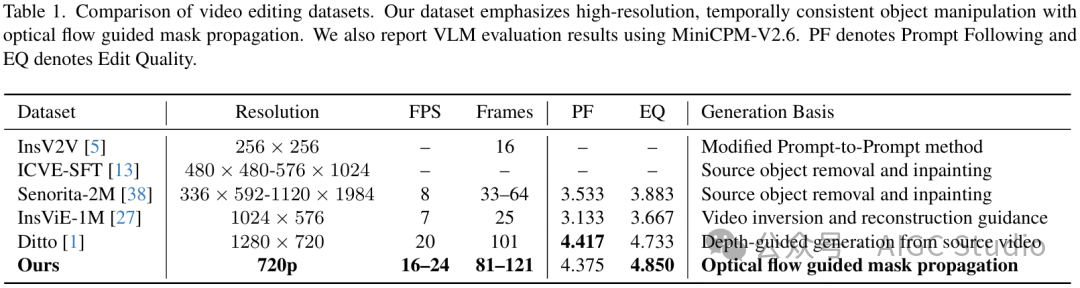
其构建流程始于一组高质量的图像编辑三元组(源图像、目标图像、编辑指令),并通过统一的多阶段合成流水线将其转化为具有时空监督的视频编辑对:
- 视频生成:使用基于文本的图像到视频生成器(Wan2.2),在保持场景布局与背景一致性的前提下,将单帧源图像扩展为时序连贯的源视频。场景描述文本由InternVL3模型提取,以确保初步的文本与视觉语义对齐。
- 对象定位:针对编辑指令,在源图像或目标图像的首帧上进行对象定位。通过Grounding-DINO获取目标边界框,并调用SAM2提取高质量的二值分割掩码,经过形态学平滑后得到初始掩码。
- 时序掩码传播:为了将该静态掩码扩展至整个视频序列,我们采用GMFlow估计源视频的稠密光流,并对掩码进行反向光流拼接与传播。同时引入双向流一致性检测以处理遮挡与位移误差,最终得到平滑且与运动相符的时序掩码序列。
- 视频填充编辑:基于得到的掩码序列、源视频以及文本指令,使用VACE模型进行视频内填充,生成编辑后的目标视频。这一步既保证了被编辑区域(对象移除或插入)的语义变化,又维护了背景与运动的全局一致性。
为确保语义与质量的稳定性,整个流水线还通过InternVL3自动生成并校验文本指令,并对生成的样本应用面积与运动幅度阈值筛选,以剔除信号较弱的样本。最终构建的数据集为每一对视频编辑样本提供了完整的信息:时序掩码、像素级光流以及语义对齐的指令文本。这些密集的时空与语义监督,为训练LoVoRA的可学习定位与编辑模块提供了关键支持。
模型概览
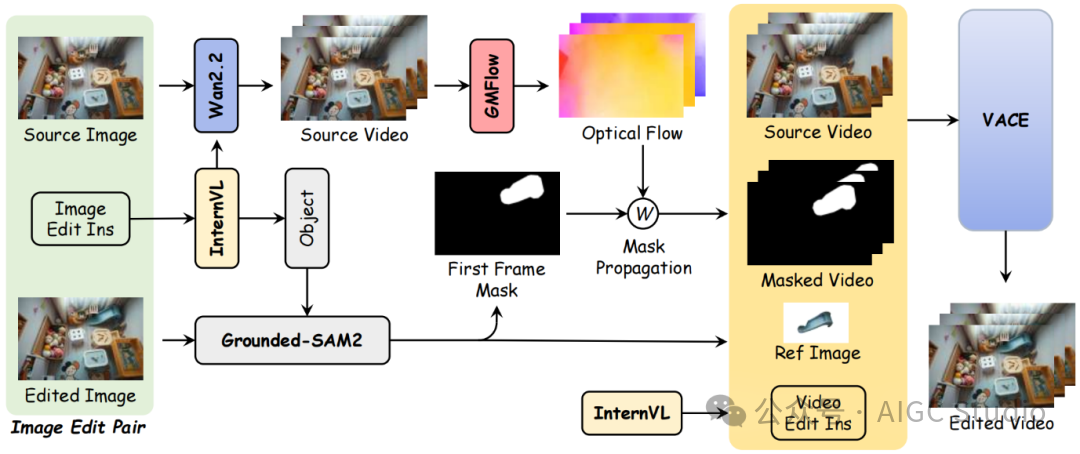
LoVoRA的核心思想是,在一个统一的端到端框架中,仅通过文本指令即可完成视频中对象的移除与添加,而无需依赖任何推理阶段的掩码、参考帧或人工控制信号。为实现这一目标,模型构建了一个基于时空VAE与3D DiT的视频编辑架构。
模型首先将输入视频编码到潜空间,并通过通道拼接的方式同时接收原视频的潜变量与噪声潜变量。随后,由3D DiT模块在文本驱动的跨模态引导下,逐步对潜空间进行结构化重建,从而生成与语义一致、运动自然的编辑后视频。这一架构能够同时建模空间细节、时间一致性与文本语义,使LoVoRA能够在复杂场景中有效保持背景结构和时序连贯性。
然而,仅依靠文本指令还不足以让模型可靠地判断“应该在哪里编辑”。为此,我们进一步提出了一个轻量级的可学习对象定位机制——扩散掩码预测器(Diffusion Mask Predictor, DMP)。该模块从DiT的中间特征中学习预测一个随时间变化的软掩码,用于指示哪些区域与当前编辑指令最相关。通过在训练过程中结合数据集中提供的时序掩码监督,DMP逐渐学会了将模型的编辑能力聚焦于目标对象上,从而在推理阶段无需任何显式掩码即可实现自动定位。这一机制有效避免了传统方法中常见的过度编辑或漏编辑问题,显著提升了空间精度与时序稳定性。
在基础架构与可学习定位机制的协同作用下,LoVoRA实现了真正意义上的纯文本驱动、完全免掩码的视频对象编辑。基础架构保证了整体视频的自然性与一致性,而DMP使模型能够精准理解文本语义并聚焦于关键区域,从而在对象移除与添加两类任务中,都能生成高质量、语义一致且时序稳定的视频结果。
实验与分析
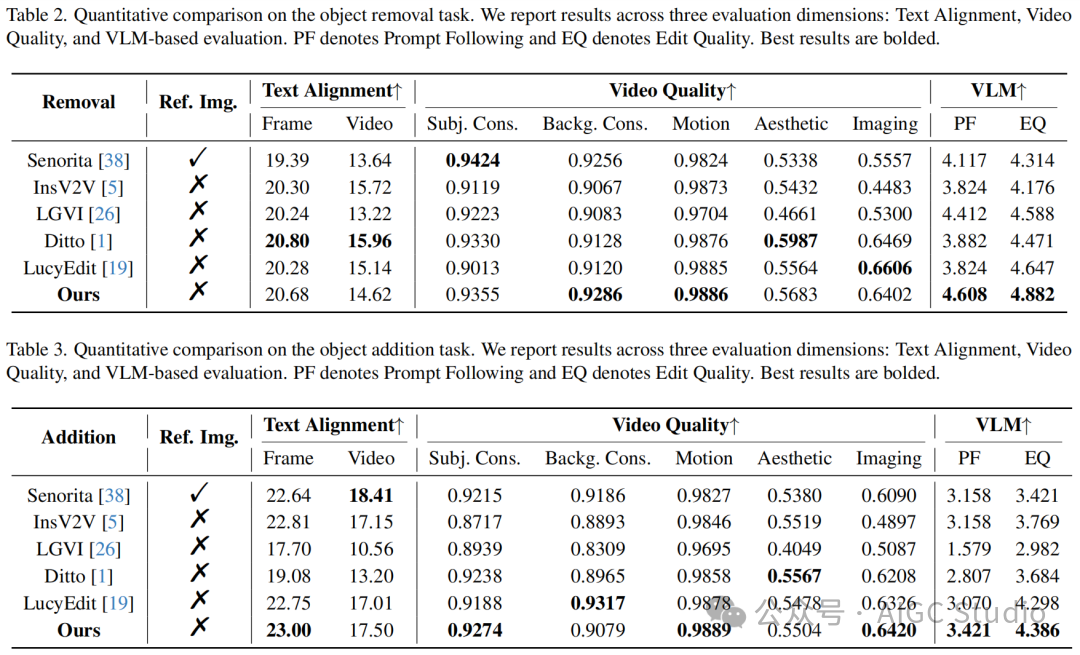
定量分析:在DAVIS与LoVoRA-Bench的综合测试中,LoVoRA在文本对齐度、视频质量与VLM评估(包括指令跟随与编辑质量)等关键指标上全面领先于主流视频编辑方法。无论是在对象移除还是对象添加任务中,LoVoRA都在大多数指标上取得了最佳或次优的结果,体现了其在语义一致性、对象级操作精度、背景稳定性与运动连续性方面的显著优势。
与Ditto等注重外观增强但容易牺牲局部准确性的模型不同,LoVoRA在保持整体画面美观的同时,显著提升了编辑的可控性。而与依赖参考帧的Senorita等方法相比,LoVoRA在无任何辅助输入的条件下仍然展现出高度竞争力,证明了其可学习定位机制的有效性。总体而言,各项定量指标验证了LoVoRA在文本理解、定位精度与编辑质量上的综合优异表现。
定性分析:从可视化结果中可以直观观察到LoVoRA在复杂场景下对对象的精准定位与自然编辑能力。
- 对于移除任务:LoVoRA能够干净地擦除目标对象,几乎不留残影或造成结构性破坏,同时完整地保留原有的纹理、光照与背景几何。
- 对于添加任务:插入的对象在颜色、光影、透视关系与运动轨迹上都能与环境无缝融合,即便在存在遮挡或快速运动等困难场景中也保持了良好的稳定性。
相比之下,多种基线方法常出现模糊边界、背景扭曲、时序跳变或编辑区域偏移等问题。LoVoRA在这些方面均有明显改善,展现出更高的真实感与一致性。

结语
LoVoRA展示了一种面向未来的视频编辑范式:无需任何手工标注的掩码,仅凭一句自然语言指令,即可驱动对象级别的、准确自然且时序一致的视频修改。结合我们新构建的高质量数据集与创新的可学习对象定位策略,LoVoRA在语义理解、空间精度与时间稳定性上均取得了领先表现,全面超越了现有的指令式视频编辑模型。我们的研究表明,让模型在训练阶段学习“隐式定位”是实现通用、高可控、可扩展视频编辑的有效途径,这为后续开发面向开放世界的智能视频编辑与创作工具奠定了坚实基础。
 发表于 2025-12-16 01:48:17
|
查看: 204|
回复: 0
发表于 2025-12-16 01:48:17
|
查看: 204|
回复: 0
