大型视频扩散和流模型在高质量视频生成中取得了显著的成功,但由于其低效的多步采样过程,它们在实时交互应用中的应用仍然受到限制。越来越多的研究已经探索了扩散蒸馏将长去噪轨迹压缩到少量推理步骤中。然而,大多数现有方法将扩散网络视为一个整体映射,忽略了大型视频扩散主干中固有的层次结构和语义进展。
为此,NVIDIA 和纽约大学研究团队联合提出了一种将视频扩散模型蒸馏为高效少步生成器的新框架——过渡匹配蒸馏(Transition Matching Distillation, TMD):将扩散模型的多步去噪轨迹与一个少步的概率转移过程相匹配,其中每一步转移均由一个轻量级的条件概率流建模。
对前沿 Wan2.1 T2V 模型进行蒸馏的实验表明,TMD 在平衡生成速度与视频质量之间提供了细粒度的灵活性。TMD 能够超越现有的蒸馏技术,在相当甚至更低的计算预算下实现更优的视觉保真度和提示词遵循度。

方法
TMD 通过紧凑的少步概率转移过程来近似原模型的多步去噪过程,如图 1 所示:其中每一步转移捕捉视频样本在跨度较大的噪声级别间的分布演化,使学生模型能够采用与教师模型分布匹配的大步长转移。
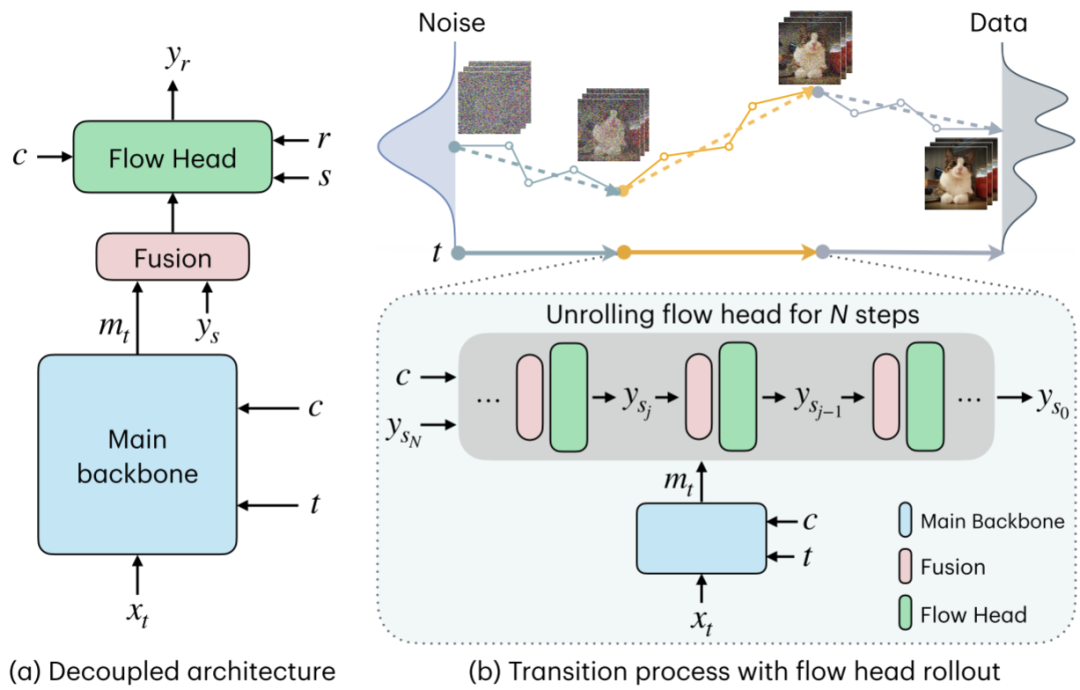
图 1 TMD 方法概述。(a) TMD 学生模型的解耦架构:主干网络以噪声样本 x_t 、时间步 t 及文本条件 c 作为输入,输出主干特征 m_t;通过一个简单的融合层,流预测头以 m_t 和 c 为条件,从噪声程度更高的 y_s(s ≥ r)预测噪声程度较低的目标 y_r。(b) 顶部:转移过程通过少量转移步骤将噪声映射至数据。底部:在每一步中,流预测头的推演计算在蒸馏与采样过程中均会执行。为简化图示,流预测头的时间步输入 s 与 r 已省略。
解耦架构
该方法遵循过渡匹配通用形式。与 TM 不同之处在于,其目标是通过蒸馏后学生模型的大步长过渡,来近似模拟教师模型的多个小步去噪过程。为高效预测每个过渡步 y_s -> y_r 中的目标变量 y_r,将预训练的教师架构解耦为两部分:
- 主干网络:作为特征提取器
- 轻量级流预测头:基于提取的特征迭代预测
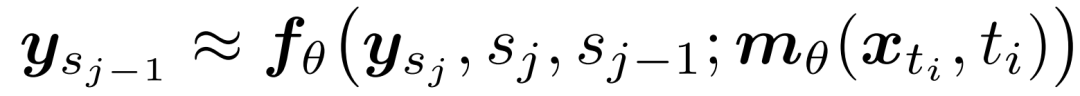
阶段一:过渡匹配预训练
基于上述解耦架构,可在蒸馏前将流预测头转换为用于迭代优化的流映射。与 TM 方法类似,可直接采用流匹配损失训练流预测头,以逼近内部流的速度场。然而理论上,这仍需要大量内部步骤才能逼近目标 ys{j-1}。因此,可利用均值流方法实现少步流预测头。
过渡匹配均值流(TM-MF):在高层设计上,该预训练算法采用均值流目标函数,并以主干特征 m 为条件。具体而言,通过平均速度对条件内部流映射进行参数化:
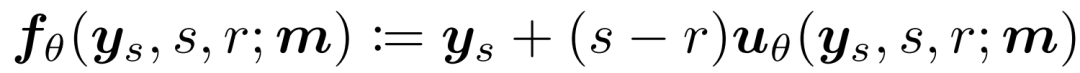
核心假设是流预测头的输出应尽可能接近预训练教师模型的输出。由于教师模型预测的是外部流的速度 v(x, t) ,为使之一致,流预测头应转而预测 u_θ。根据内部速度的定义,可得:
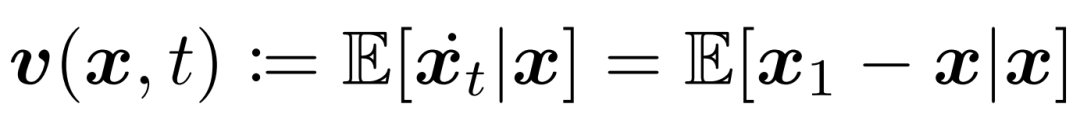
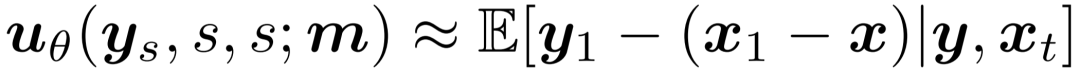
因此,将平均速度参数化为:
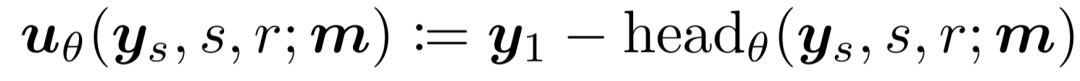
遵循原始均值流框架,采用部分批次流匹配、无分类器指导(以一定概率丢弃文本条件)及自适应损失归一化,以提升训练性能与稳定性。采用 JVP 的有限差分近似,使算法对底层架构和训练技术保持不可知性。
阶段二:流预测头引导的蒸馏
DMD2-v:DMD2 最初是为蒸馏图像扩散模型而提出的,因此其设计选择在视频领域可能并非最优。改进视频版 DMD2(称为DMD2-v)的三个关键因素构成了 TMD 训练的默认设置:
- GAN判别器架构:在 GAN 判别器中使用 Conv3D 层优于其他架构,这表明局部化的时空特征对于 GAN 损失至关重要;
- 知识蒸馏预热:KD 预热能提升一步蒸馏的性能,但在多步生成中,它往往会引入粗粒度伪影,且难以通过后续的 DMD2 训练修正。因此,我们仅在 DMD2-v 的一步蒸馏中应用 KD 预热;
- 时间步偏移:当为外部转移步采样时间步,或在 VSD 损失中为生成样本添加噪声时,会发现对均匀采样的 t 应用偏移函数 φ(t) = t + α(其中 α ~ N(0, σ²))能够提升性能并防止模式崩溃。
流预测头推演:在蒸馏过程中,内部流计算图被展开,所形成的结构在每个转移 y_s_j -> ys{j-1} 处被视为一个样本生成器 g_θ。基于流预测头目标 u_θ,展开后的学生模型输出可表示为:
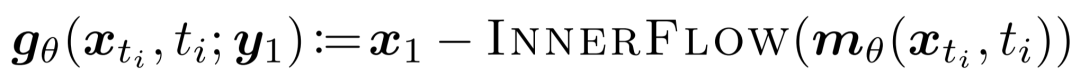
将 DMD2-v 中VSD 损失应用于上述展开的学生模型输出,梯度可自然贯穿所有 N 个内部流步骤进行反向传播。
评估
在计算效率时,以有效函数评估次数(NFE)作为指标,其定义为生成过程中使用的 DiT 模块总数除以教师模型架构的模块总数 L;对于基线模型,NFE即对应采样步数 M,对于 TMD 模型,其计算方式为:
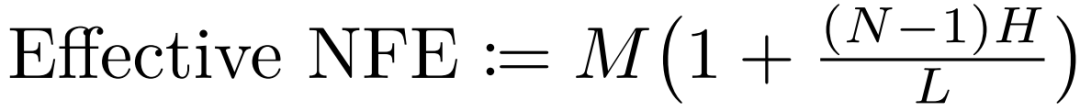
需要说明的是,Wan2.1 1.3B 模型的 L = 30,而 Wan2.1 14B 模型的 L = 40。
表 1:将 Wan2.1 1.3B 蒸馏为少步生成器时,TMD 方法与基线方法的 VBench 结果
(DMD2-v 表示针对视频生成改进的 DMD2 版本。“N2H5”(或“N4H5”)表示包含 2 个(或 4 个)去噪步,且流预测头包含 5 个 DiT 模块。)
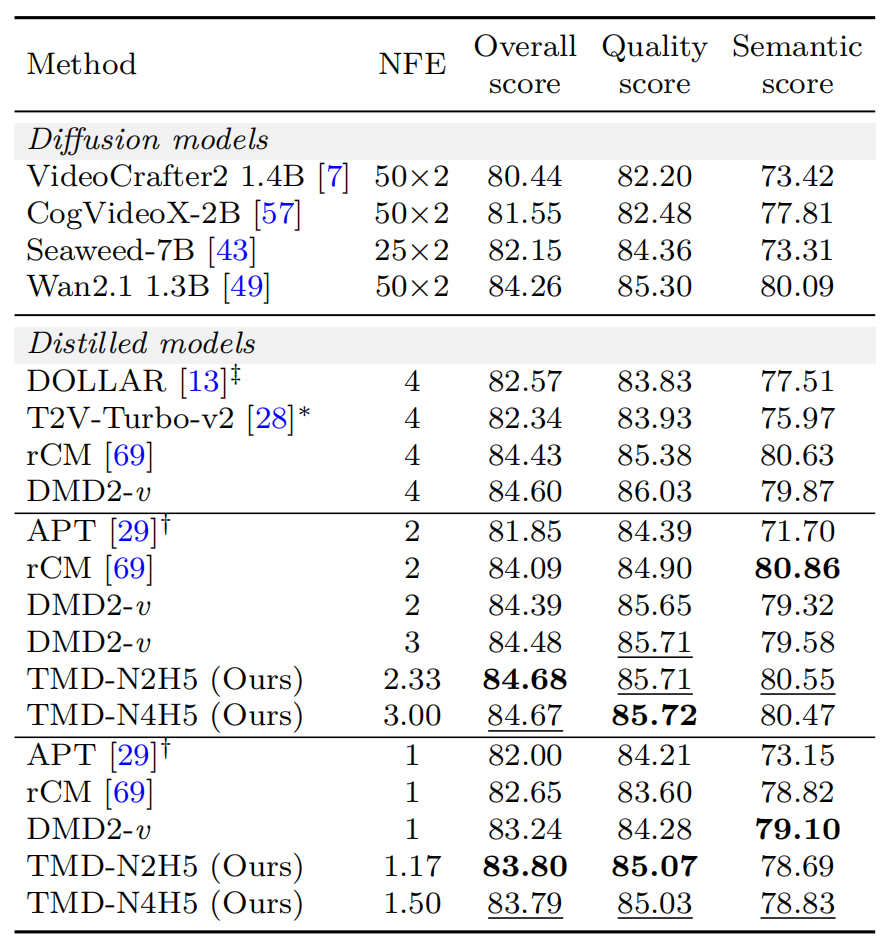
表 1 展示了将 Wan2.1 1.3B 模型蒸馏为少步生成器的 VBench 评测结果,其中蒸馏模型根据学生去噪步数 M 进行分组。当 M = 2 时,有效 NFE 为 2.33 的 TMD-N2H5 模型获得了 84.68 的综合得分,超越了所有其他蒸馏模型,包括NFE=4的最强基线 rCM。当 M = 1 时,NFE 为 1.17 的 TMD-N2H5 模型同样以 83.80 的综合得分优于所有其他一步蒸馏方法,缩小了与两步蒸馏模型之间的差距。通过 TMD 方法,可以凭借非整数 NFE 实现对质量-效率权衡的更精细控制。
表 2:将 Wan2.1 14B 蒸馏为少步生成器时,TMD 方法与基线方法的 VBench 结果
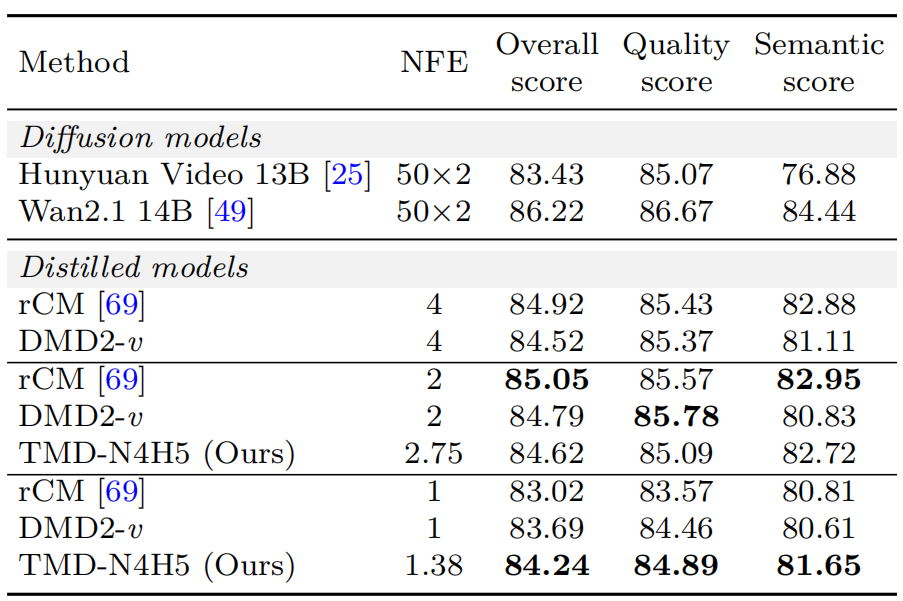
表 2 展示了蒸馏 Wan2.1 14B 参数模型的 VBench 结果。当 M = 2 时,NFE为2.75 的 TMD-N4H5 模型未超越两步基线(尽管其优于四步DMD-v)。当 M = 1 时,NFE 为 1.38 的 TMD-N4H5 模型以 84.24 的综合得分显著优于所有其他一步蒸馏方法,相较一步 rCM 提升 1.22 分,而仅增加了极少的推理成本。
图 2:视觉对比。针对 Wan2.1 14B 模型的示例提示词,对比展示了 TMD 与 DMD2-v 生成结果中的三帧画面。

图 2 表明,TMD 方法提升了提示词遵循度,支持了数值上的改进。此外,TMD 消除了原一步 DMD2-v 所需的、计算代价高昂的知识蒸馏预热阶段。
用户偏好研究:研究进行了一项双盲二选一迫选用户偏好调查,比较了在蒸馏Wan2.1 14B 参数模型时,TMD-N4H5与DMD2-v 在两种设置下的表现:(1)M = 2(两步生成);(2)M = 1(一步生成)。从 VBench 中随机抽取 60 个具有挑战性的提示词,并为每个提示词和模型使用不同随机种子生成 5 个视频。对于每个提示词,评估者会并排观看来自本模型与基线的视频(顺序与种子随机),并基于两个独立标准进行成对比较:视觉质量与提示对齐度。
图 3:用户偏好研究结果。对比展示了一阶段(M = 1)与二阶段(M = 2)蒸馏设定下,TMD-N4H5(本方法)与 DMD2-v 的比较结果。
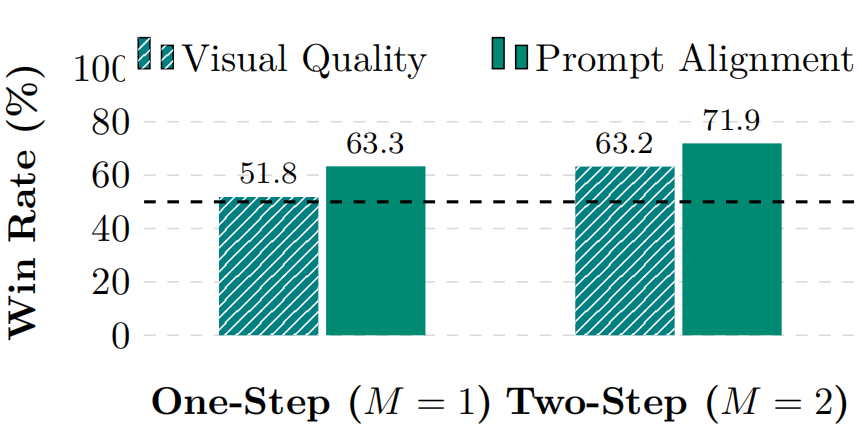
如图 3 所示,在一步和两步生成设置下,用户一致更偏好 TMD 而非 DMD2-v 。在提示对齐度方面的优势更为显著,这与图 2 的定性结果相呼应,并凸显了迭代式流预测头优化在显著提升提示遵循能力中的作用。
这项由 NVIDIA 提出的 TMD 框架,为人工智能领域的视频生成模型加速提供了一种高效且灵活的蒸馏新思路,在深度学习模型优化方向上具有重要意义。更多前沿技术动态与深度解析,欢迎持续关注云栈社区。
 发表于 2026-1-27 07:23:43
|
查看: 201|
回复: 0
发表于 2026-1-27 07:23:43
|
查看: 201|
回复: 0
