昨天的开源社区异常热闹,两家头部国产 AI 公司同台“秀肌肉”。
Kimi 发布了 K2.5,视觉编程能力显著提升,能够通过截图或录屏直接复刻网页和 App,并引入了一种核心的自主体智能蜂群范式,据称比单一智能体的执行速度快了4.5倍。
而 DeepSeek 则拿出了更底层的硬核技术,开源了 DeepSeek-OCR-2,其最激进之处在于,完全摒弃了传统的 CLIP 视觉编码器,转而使用一个 LLM 架构来“看图”。
如果说 Kimi K2.5 将“界面理解到代码生成”推向了实用化,那么 DeepSeek-OCR-2 则在挑战一个更根本的问题:AI 能否像人类一样拥有逻辑地“阅读”文档?
答案是肯定的,并且这次的做法截然不同。
项目背景:从“扫视”到“阅读”
传统基于 CLIP 的模型擅长“全局感知”,比如快速识别“这是一张猫的图片”,但其处理视觉信息的顺序是固定的(通常是从左上到右下的光栅扫描)。这导致它们在处理具有复杂逻辑排版的文档(如多栏文章、嵌套表格)时,容易产生语序混乱。
CLIP 的方式更像 一眼扫过,抓住整体语义。
而真正的文档OCR需要的是 像人一样,按照语义逻辑逐块阅读。
因此,DeepSeek-OCR-2 做出了一个大胆的改变:将视觉编码器换成了 Qwen2-0.5B。

这意味着,它用一个 擅长因果推理的小型语言模型,替代了 擅长全局匹配的视觉模型。这好比以前是让“广角相机”去读文章,现在则请来了一位“阅读理解专家”。这种让语言模型跨界学习视觉理解的思路,在人工智能领域显得相当新颖。
核心创新:Visual Causal Flow(视觉因果流)
DeepSeek-OCR-2 的核心创新被称为 Visual Causal Flow(视觉因果流)。
听起来很学术,但用大白话解释就是:AI 不再机械地按固定路径“扫描”图像,而是先理解内容布局,动态规划出一条最符合人类阅读逻辑的路径,实现真正的「智能阅读」。
具体实现分为两步:
- 第一步(全局感知):模型通过双向注意力机制快速“瞥”一眼全图,初步识别出标题、段落、图片、表格等区域的位置。
- 第二步(路径规划):模型生成一组特殊的“因果流 Token”,就像为阅读过程绘制一张导航图,规划出一条从最重要信息开始、符合语义关联的阅读序列。
最终效果:即使是报纸那种复杂的“迷宫式”多栏排版,模型也能按照正确的、符合人类习惯的顺序将文字内容提取和还原出来。
Qwen2-0.5B 作为语言模型,天生擅长处理序列数据和因果关系。DeepSeek 的实践证明了,让 LLM 跨界担任视觉编码器,能更有效地捕捉图像中的 逻辑结构,而不仅仅是像素模式。
快速上手体验与部署
想要快速体验模型效果,HuggingFace 上已经有不少现成的 Demo。
Demo 01:https://huggingface.co/spaces/merterbak/DeepSeek-OCR-Demo

Demo 02:https://huggingface.co/spaces/prithivMLmods/DeepSeek-OCR-2-Demo

如果想进行本地部署或集成到自己的服务中,可以参考以下步骤。这体现了开源实战的魅力,让开发者能深入探究。
① 克隆项目
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git
② 安装依赖
首先下载 vLLM 预编译包:https://github.com/vllm-project/vllm/releases/tag/v0.8.5
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
③ 使用 vLLM 进行推理
cd DeepSeek-OCR2-master/DeepSeek-OCR2-vllm
# 处理单张图像(流式输出)
python run_dpsk_ocr2_image.py
# 处理 PDF 文档(并行处理)
python run_dpsk_ocr2_pdf.py
# 批量评估(OmniDocBench v1.5 基准测试)
python run_dpsk_ocr2_eval_batch.py
或者使用 Transformers 库推理
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR-2'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = “<image>\nFree OCR. ”
prompt = “<image>\n<|grounding|>Convert the document to markdown. ”
image_file = ‘your_image.jpg’
output_path = ‘your/output/dir’
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 768, crop_mode=True, save_results = True)
性能与效率:质变与量变的平衡
尽管架构发生了根本性变化,DeepSeek-OCR-2 在效率上却做到了“加质不加价”,甚至更优。
由于其具备逻辑理解能力,它无需像传统模型那样生成海量的图像块Token来覆盖每一个角落。它知道重点在哪里,并按逻辑顺序处理。

- 对比某些模型:仅需约100个视觉Token就能达到对方256个Token的效果。
- 在处理复杂文档时,不到800个视觉Token的精度就能超越其他模型使用7000个Token的结果。
这直接带来了两大优势:推理速度极快,且生成的无意义重复内容(废话)极少。
吞吐量数据同样惊人:
- 速度:单张 A100 显卡每天可处理约 20万页 文档。
- 吞吐:峰值达到 2500 tokens/s。
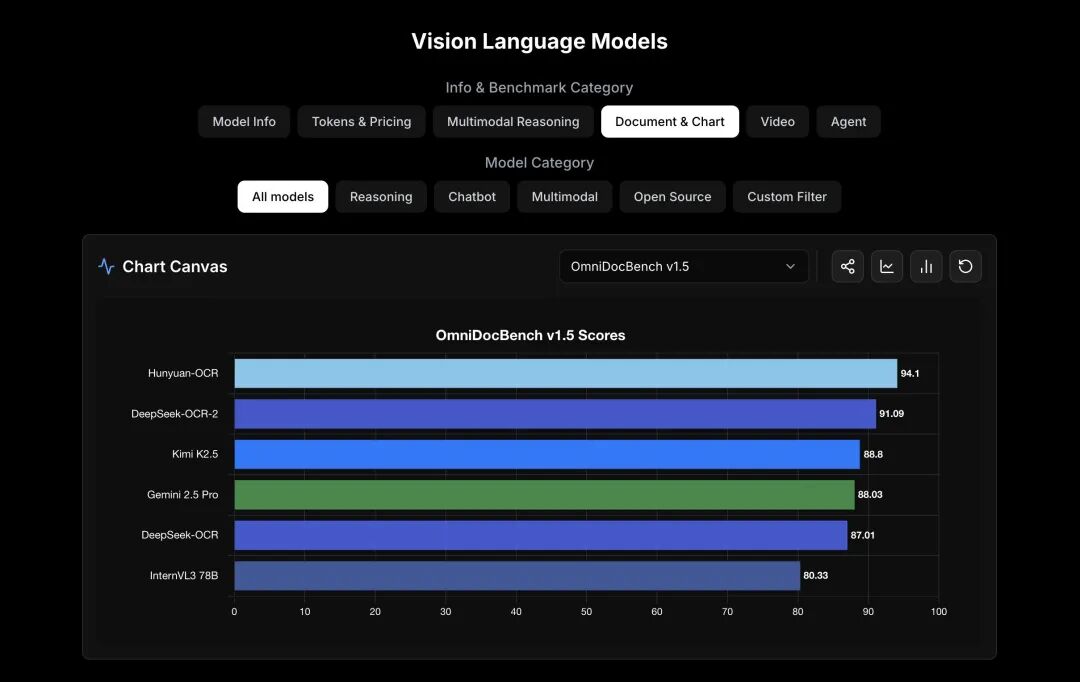
在权威的 OmniDocBench v1.5 基准测试中,其表现如下:
- 综合得分:91.09%
- 相比上一代 DeepSeek-OCR 提升:+3.73%
- 阅读顺序识别能力:显著增强
视觉编码器从 CLIP ViT(300M参数)换为 Qwen2-0.5B(500M参数),仅增加了200M参数,却换来了性能的质的飞跃。最关键的是,模型总参数量仍控制在 3B 级别,保持了轻量级特性,对部署非常友好。
总结与展望
DeepSeek-OCR-2 的这次开源,为多模态领域,特别是文档理解方向,指明了一条新路径:视觉理解不一定非得依赖传统的视觉Transformer(ViT),经过恰当设计的语言模型本身就可能成为更优秀的视觉编码器。
这不仅仅是OCR技术的一次升级,更是对多模态模型架构可能性的一次重要验证。DeepSeek 再次展现了其强大的工程实现能力和前沿的探索精神。
目前,该项目已在 GitHub 上完全开源。无论你是有海量文档处理需求的企业开发者,还是对智能 & 数据 & 云前沿技术充满好奇的研究者,都值得去深入了解甚至亲自尝试这个“更像人类”的OCR工具。不妨去点个Star,跑个Demo,感受一下视觉因果流带来的不同。
项目资源链接:
技术社区的发展离不开这样的硬核分享与碰撞,欢迎在云栈社区继续探讨相关技术细节与应用实践。


 发表于 2026-1-31 08:55:07
|
查看: 248|
回复: 0
发表于 2026-1-31 08:55:07
|
查看: 248|
回复: 0
