腾讯混元团队开源的 HunyuanOCR 是一款轻量级的端到端 OCR 视觉语言模型,其 1B 参数的设计在多个基准测试中达到了先进水平。它支持复杂文档解析、信息提取、视频字幕识别等多种任务。模型已发布在 Huggingface 与 ModelScope,本文将手把手指导您在本地环境完成部署与功能测试。
环境准备与模型下载
官方推荐在 Linux 系统下使用 Python 3.12+、CUDA 12.9 和 PyTorch 2.7.1 进行部署,运行 vLLM 需要至少 20GB 的 GPU 显存。
实际测试环境:
- 操作系统: Ubuntu 24.04.3 Server
- CUDA: 12.8
- 显卡: NVIDIA RTX 2080 Ti (22GB 显存)
- 内存: 32GB
首先,我们通过 ModelScope 下载模型。确保已安装 modelscope 库,并指定一个缓存目录。
pip install modelscope
modelscope download --model Tencent-Hunyuan/HunyuanOCR --cache_dir '/path/to/your/models/'
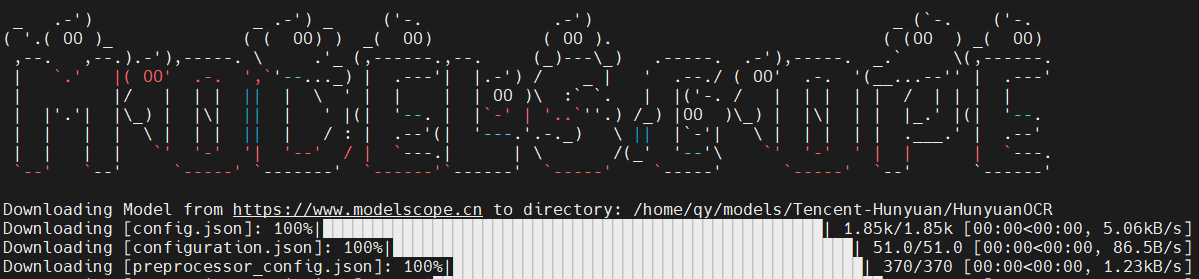
下载过程如图所示:
使用 uv 创建隔离的 Python 环境
为了环境整洁,推荐使用 uv 工具管理 Python 虚拟环境,这对于管理复杂的Python项目依赖非常有效。
# 安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建并激活虚拟环境
uv venv hunyuanocr --python 3.12
source hunyuanocr/bin/activate
激活后,建议配置 PyPI 镜像源以加速后续的包安装。
部署与启动 vLLM 服务
克隆项目源码并安装基础依赖。
git clone https://github.com/Tencent-Hunyuan/HunyuanOCR.git
cd HunyuanOCR
uv pip install -r requirements.txt
接下来安装推理引擎 vllm。需要注意依赖版本问题,直接安装 nightly 版本可能导致 aiohttp 编译失败。
# 先安装稳定版 aiohttp
uv pip install -U “aiohttp<4”
# 再安装 vllm
uv pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly
如果您的 CUDA 驱动版本(如 12.8)低于模型要求的 CUDA 运行时版本(12.9),需要安装 cuda-compat 包来提供兼容性支持。
完成上述步骤后,即可启动 vLLM 服务。以下命令将模型加载到 GPU,并在 6688 端口启动一个兼容 OpenAI API 格式的服务。
vllm serve \
/path/to/your/models/Tencent-Hunyuan/HunyuanOCR \
--served-model-name HunyuanOCR \
--host 0.0.0.0 \
--port 6688 \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--gpu-memory-utilization 0.9
参数说明:
--no-enable-prefix-caching:禁用前缀缓存,有助于提升 OCR 任务性能。--gpu-memory-utilization 0.9:设置 GPU 显存利用率,需根据实际显存调整。
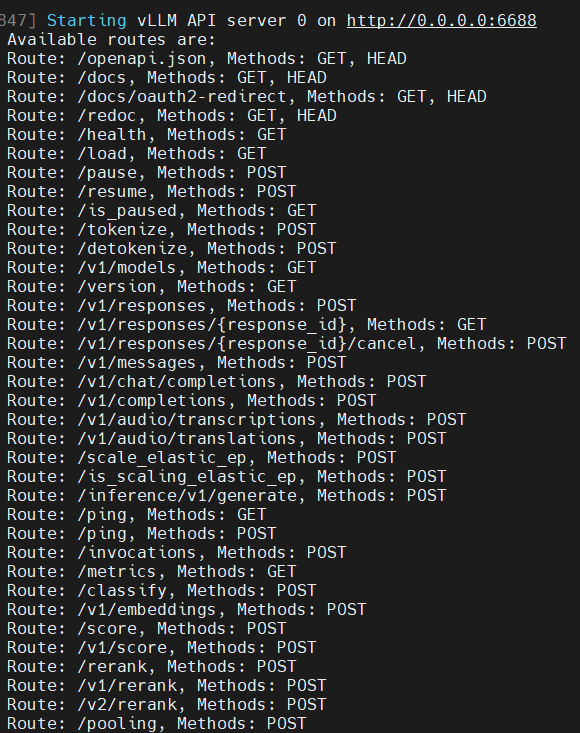
服务成功启动后,终端会显示如下信息:
客户端接入与功能测试
服务端通过 vLLM 部署后,提供了标准的 OpenAI API 接口,可以使用任何兼容的客户端进行调用。
使用 Cherry Studio 快速测试
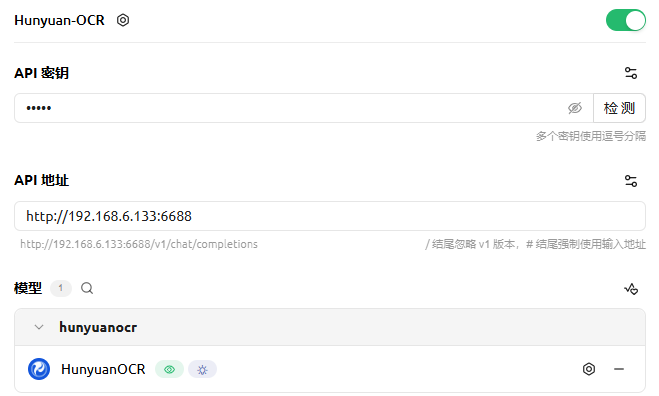
您可以配置 API 地址和模型名称(留空即可)进行连接。
官方提供了针对不同任务的推荐提示词,例如对于通用文字提取,直接使用“提取图中的文字”即可获得良好效果。
文字提取示例:
上传一张包含文字的图片,并输入提示词“提取图中的文字”,模型能够准确地返回识别结果。

信息抽取示例:
对于结构化的票据或文档,HunyuanOCR 能够有效提取关键字段信息。

通过 Python 代码调用
对于自动化测试或集成到现有系统中,通过代码调用更为稳定。以下是基本的调用示例,您可以在项目的 HunyuanOCR-vllm 目录下找到更完整的测试脚本。
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:6688/v1"
)
response = client.chat.completions.create(
model="HunyuanOCR",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "提取图中的文字"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,/9j/4AAQ..."}},
]
}
],
max_tokens=1024
)
print(response.choices[0].message.content)
项目文件结构清晰,方便用户查找和使用各类工具脚本。
总结
通过以上步骤,我们成功在本地完成了腾讯 HunyuanOCR 1B 模型的部署与基础功能验证。这款轻量级模型在保持高精度的同时,降低了对硬件资源的需求,其端到端的架构和强大的多场景解析能力,为人工智能领域的文档处理和信息提取应用提供了新的选择。整个部署过程涉及环境配置、依赖解决和服务运维,是学习现代AI模型服务化部署的一次良好实践。
 发表于 2025-12-16 00:26:39
|
查看: 286|
回复: 0
发表于 2025-12-16 00:26:39
|
查看: 286|
回复: 0
