环境搭建与框架选择
为了开展基于智能体的强化学习(Agentic RL)实验,首先需要准备合适的计算环境与训练框架。经过评估,本文选择slime作为核心训练框架。
选择slime框架的四大理由
- 架构优雅,易于上手:slime的整体架构与代码设计追求简洁与优雅,对于RL研究者而言非常友好。其轻量化的设计使得研究者能够快速理解核心逻辑,并方便地对特定模块进行定制化修改。
- 社区活跃,文档完善:slime拥有活跃的社区和持续更新的完善文档,为学习和问题排查提供了有力支持。
- 经过生产验证:该框架已被应用于实际的大模型训练项目中(例如智谱GLM模型的训练),证明了其在生产环境中的可靠性与有效性。
- 支持分布式训练:slime原生支持异步RL训练与分布式多卡训练,能够充分释放多GPU硬件的计算潜力。
官方提供了详尽的快速入门指南,可作为重要参考。
快速启动:使用Docker部署
推荐使用Docker快速构建一致的Python与训练环境,避免复杂的本地依赖问题。
1. 拉取最新镜像
首先,从Docker Hub拉取slime官方镜像。
docker pull slimerl/slime:latest
2. 启动容器
启动一个支持GPU的容器,并配置必要的运行参数。
docker run --rm --gpus all --ipc=host --shm-size=16g \
--ulimit memlock=-1 --ulimit stack=67108864 \
-it slimerl/slime:latest /bin/bash
3. 安装slime框架
进入容器后,克隆源码并进行本地安装。
cd /root
git clone https://github.com/THUDM/slime.git
cd slime
pip install -e .
准备数据与模型
数据集下载
可以从Hugging Face等平台下载训练与评估所需的数据集。
# 下载训练数据集 (dapo-math-17k)
hf download --repo-type dataset zhuzilin/dapo-math-17k \
--local-dir /root/dapo-math-17k
# 下载评估数据集 (aime-2024)
hf download --repo-type dataset zhuzilin/aime-2024 \
--local-dir /root/aime-2024
模型权重格式转换
当使用Megatron作为训练后端时,需将Hugging Face格式的模型权重转换为Megatron格式。
Hugging Face 格式 -> Megatron 格式
以Qwen3-4B模型为例,首先加载模型配置文件。
# 查看模型配置
vim scripts/models/qwen3-4b.sh
# 加载配置到环境变量
source scripts/models/qwen3-4b.sh
随后,运行转换脚本。
PYTHONPATH=/root/Megatron-LM python tools/convert_hf_to_torch_dist.py \
${MODEL_ARGS[@]} \
--hf-checkpoint [huggingface模型地址] \
--save [megatron格式保存地址]
Megatron 格式 -> Hugging Face 格式
PYTHONPATH=/root/Megatron-LM python tools/convert_torch_dist_to_hf.py \
--input-dir /path/to/torch_dist_ckpt/iter_xxx/ \
--output-dir [hf格式保存地址] \
--origin-hf-dir [原始huggingface模型地址]
注意:若转换后embedding形状不匹配,可能需要通过 --vocab-size 参数指定词表大小。
训练参数配置详解
slime的训练脚本通过组合多组参数来控制整个流程。以下对关键参数进行解析。
MODEL_ARGS: 模型配置
通过 source 命令从 scripts/models/xxx.sh 加载,定义了Megatron所需的模型结构超参。
CKPT_ARGS: 检查点与路径
CKPT_ARGS=(
# Hugging Face模型路径(用于加载tokenizer等信息)
--hf-checkpoint [huggingface模型地址]
# 参考模型(Reference Model)的Megatron格式检查点
--ref-load [megatron模型地址]
# Actor模型的加载路径。若为空,则从--ref-load加载
--load [actor加载地址]
# 训练过程中模型的保存路径
--save [模型保存地址]
# 模型保存间隔(步数)
--save-interval 20
)
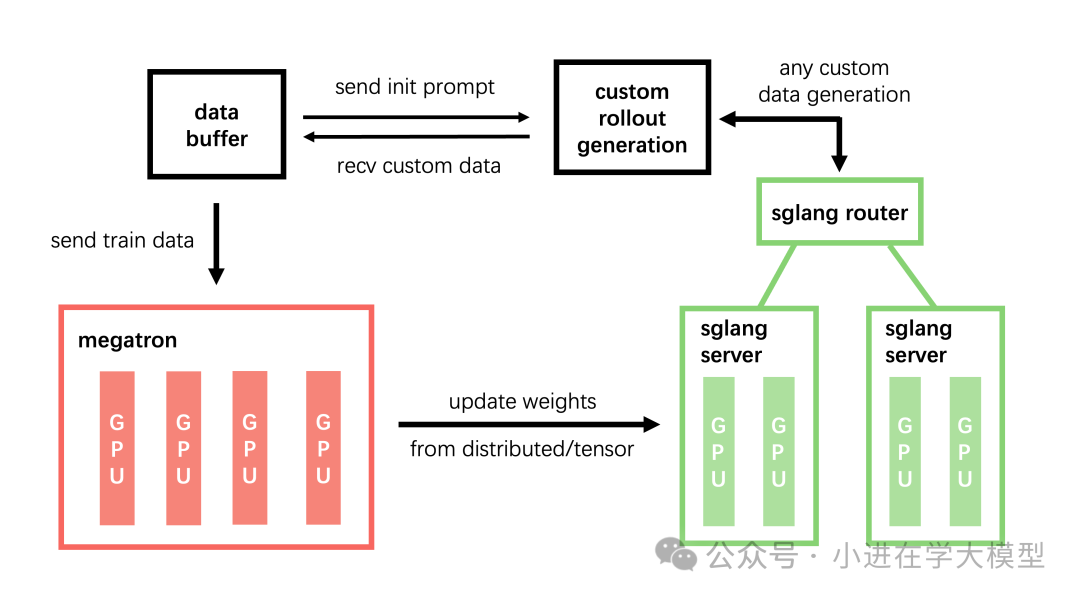
ROLLOUT_ARGS: 数据生成与训练循环
训练是一个“采样(Rollout)→训练(Training)”的闭环。
- 采样阶段:由
--rollout-batch-size(Prompt数量)和 --n-samples-per-prompt(每个Prompt的回复数)决定产出样本总数。
- 训练阶段:由
--global-batch-size(一次参数更新的样本量)和 --num-steps-per-rollout(使用当前采样数据执行的更新次数)决定消耗样本总数。
必须遵守的约束是:产出样本总数 = 消耗样本总数。
ROLLOUT_ARGS=(
# 数据路径与格式
--prompt-data /root/dapo-math-17k/dapo-math-17k.jsonl
--input-key prompt
--label-key label
--apply-chat-template
--rollout-shuffle
# Reward Model配置
--rm-type deepscaler
# 采样与训练循环控制
--num-rollout 3000 # 总循环轮次
--rollout-batch-size 16 # 每轮采样Prompt数
--n-samples-per-prompt 8 # 每个Prompt生成回复数
--num-steps-per-rollout 1 # 每轮采样数据训练的步数
# global-batch-size 会根据上述公式自动计算或校验
# 采样参数
--rollout-max-response-len 8192
--rollout-temperature 0.8
--balance-data # 数据负载均衡,提升训练速度
)
EVAL_ARGS: 评估参数
EVAL_ARGS=(
--eval-interval 5 # 评估间隔(按Rollout轮数)
--eval-prompt-data aime /root/aime-2024/aime-2024.jsonl
--n-samples-per-eval-prompt 16
--eval-max-response-len 16384
--eval-top-p 0.7
)
PERF_ARGS: 性能与并行配置
此部分包含Megatron并行策略与slime的性能优化选项。
GRPO_ARGS: GRPO算法参数
GRPO_ARGS=(
--advantage-estimator grpo
--use-kl-loss # 启用KL散度监控(是否计入损失由系数决定)
--kl-loss-coef 0.00 # 设置为0则KL散度仅监控,不参与损失计算
--kl-loss-type low_var_kl
--entropy-coef 0.00
--eps-clip 0.2
--eps-clip-high 0.28
)
--calculate-per-token-loss:slime默认计算per-sample loss,如需计算per-token loss可开启此选项。
SGLANG_ARGS: 推理服务参数
SGLANG_ARGS=(
--rollout-num-gpus-per-engine 2 # 等同于SGLang的tp_size
)
其他SGLang参数可通过 --sglang- 前缀传递,例如 --sglang-log-level INFO。
训练部署模式:分离与一体
slime支持两种资源调度模式。
1. 训推分离(标准模式)
训练(Actor)和推理(Rollout)使用独立的GPU资源组,通过Ray调度并行运行。
ray job submit ... \
-- python3 train.py \
--actor-num-nodes 1 \
--actor-num-gpus-per-node 4 \
--rollout-num-gpus 4 \ # 推理独占4卡
...(其他参数)
2. 训推一体(Colocated模式)
训练和推理共享同一组GPU,通过添加 --colocate 参数启用,此时会忽略 --rollout-num-gpus。
ray job submit ... \
-- python3 train.py \
--actor-num-nodes 1 \
--actor-num-gpus-per-node 8 \
--colocate \ # 训练与推理共享8卡
...(其他参数)
启动训练
完成所有配置后,在slime项目根目录下执行启动脚本即可开始GRPO训练。
bash scripts/run-qwen3-4B.sh

 发表于 2025-12-16 00:23:56
|
查看: 338|
回复: 0
发表于 2025-12-16 00:23:56
|
查看: 338|
回复: 0
