在电商推广领域,一个精准的自动出价策略是决定广告投放效果的关键。近年来,生成式模型因其卓越的数据挖掘和序列建模能力,在自动出价任务中崭露头角。然而,一个普遍的挑战是:现有的生成式出价模型大多只是在模仿数据集中的历史投放轨迹,缺乏根据模型自身表现主动探索和优化出价动作的能力。
针对这一问题,淘天集团淘工厂&淘特算法团队提出了一种新颖的模型——基于Q值引导的生成式出价模型 Q-Regularized Generative Auto-Bidding (QGA)。该模型巧妙地借鉴了强化学习中Actor-Critic框架的思想,通过构建能够评估动作价值的Critic网络,并采用Q值正则化方法改进生成式模型的出价轨迹,从而赋予了模型更强的自主寻优能力。目前,该模型已成功上线应用,在推广消耗、ROI和GMV等多个核心指标上均实现了显著提升。相关研究成果已被国际顶级会议 KDD 2026 收录。
论文及代码地址: https://github.com/M2C-Tech/QGA
1. 背景
自动出价任务的目标,是在满足商家预算和成本约束的前提下,最大化所获推广流量的总价值。这是一个典型的多约束优化问题(Multi-constrained Bidding, MCB),其数学形式如下:
$$
\max \sum_{i=1}^{N} y_i q_i \\\\
s.t. \sum_{i=1}^{N} y_i b_i \le B \\\\
\frac{\sum_{i=1}^{N} y_i b_i}{\sum_{i=1}^{N} y_i q_i} \le C
$$
其中:
- $y_i \in \\{0,1\\}$ 表示是否成功竞得第 $i$ 个流量。
- $q_i$ 表示该流量的质量。
- $b_i$ 表示对该流量的出价。
- $B$ 为单品推广总预算。
- $C$ 为单品目标成本。
- $N$ 为一定时间内的总流量数。
理论上,该问题存在解析最优解,其形式与流量质量 $q_i$ 以及两个约束参数 $\\lambda_1$ 和 $\\lambda_2$ 相关:
$$
b_i^* = q_i (\frac{1}{\lambda_1 + \lambda_2 q_i})
$$
然而,将理论应用于实际系统时,会遇到两大难点:
- 流量分布变化剧烈:推广投放是一个多方实时竞争的环境,流量分布动态变化,准确预估 $q_i$ 的难度很高。
- 求解计算成本高昂:直接求解大规模线性规划问题,其计算开销在实时系统中难以承受。
因此,在实践中,自动出价通常被建模为一个序列决策问题。出价模型需要在整个推广周期内,根据实时变化的流量和竞价状态,动态调整出价策略以优化最终效果。早期的解决方案(如PID控制器)虽易于实现,但难以适应复杂多变的环境。随后的强化学习方法将出价过程建模为马尔可夫决策过程,但在捕捉长期依赖关系方面存在局限。生成式出价模型通过直接建模优化目标与推广投放序列之间的相关性,有效克服了传统强化学习的问题。
尽管如此,当前的生成式出价模型仍存在瓶颈。它们主要采用监督学习(类似模拟学习)的方式,目标是拟合历史数据集中的动作。这导致模型只是在“模仿”历史轨迹,缺乏突破既有模式、探索更优出价动作的能力,从而使得出价策略单一,性能存在明显的天花板。
为了解决上述问题,团队提出了QGA模型,其核心思想是为生成式出价模型注入强化学习的自主寻优能力,从而突破性能瓶颈。
2. 基于Q值正则的生成式出价模型 QGA
我们借鉴了大语言模型训练中引入“批评家模型”(Critic Model)进行对齐的思路,在生成式出价框架中引入了一个能够对动作质量进行评估的打分模型。通过类似强化学习的交互式训练,使生成式模型能够根据Critic的反馈,不断向更优的出价动作方向探索。QGA的主要贡献包括:
- 动作正则化引导:在生成式出价任务中引入强化学习的Actor-Critic框架。通过一个评估动作价值的Critic网络,以动作价值正则项的方式,引导生成式模型生成更高价值的出价动作。
- 基于动作价值和双重探索机制缓解OOD问题:设计了独特的双重探索机制,有效提升了模型对未见动作空间的探索能力,缓解了分布外(OOD)问题。
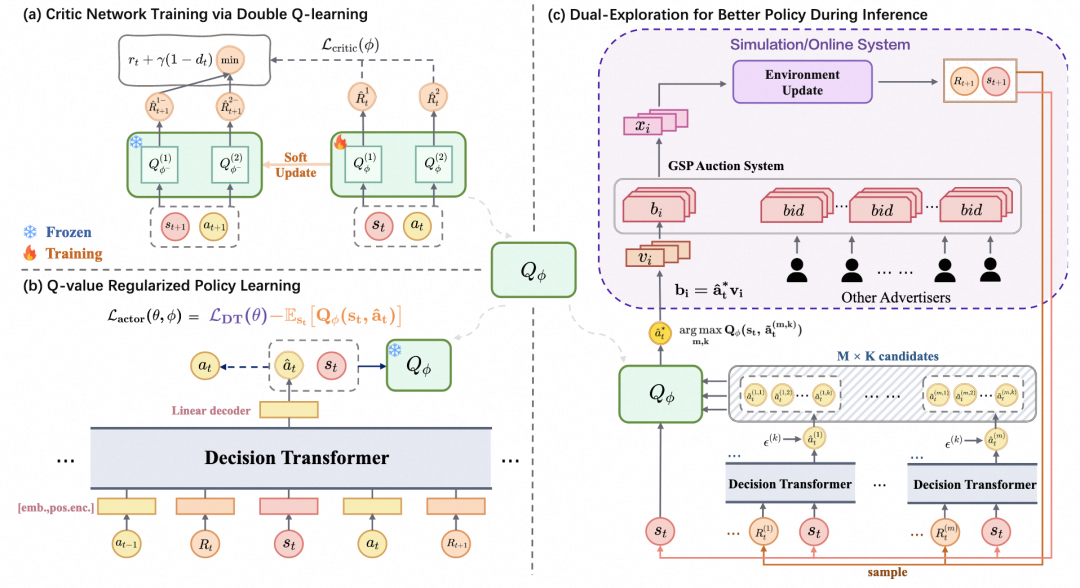
图1:QGA算法的整体框架
在QGA中,我们将负责产出出价动作的决策变换器(Decision Transformer, DT)视为动作生成器(Actor)。为了克服传统基于DT的模型因使用动作的均方误差(MSE)损失进行训练而导致的“纯粹模仿”问题,我们构建了一个基于双Q网络的批评家网络(Critic)。Critic的核心作用是对Actor生成的动作进行“打分”,评估该动作对未来整个推广序列回报的潜在影响。
具体而言,Critic输出的是在给定推广状态 $s_t$ 下,执行出价动作 $a_t$ 所能获得的动作价值 $Q_{\phi}(s_t, a_t)$。这里的 $Q$ 值定义为从当前时刻到推广周期结束的折扣期望累积回报。QGA采用Actor与Critic交替训练的方式,通过在Actor的训练损失中加入Q值正则项,激励Actor生成Critic认为价值更高的动作,从而达到提升整体出价效果的目的。
2.1 基于双Q网络的动作价值打分器(Critic)
我们的Critic模型采用双Q网络结构,包含两个独立的Q网络,分别记为 $Q_{\phi}^{(1)}$ 和 $Q_{\phi}^{(2)}$。每个网络以状态-动作对 $(s_t, a_t)$ 作为输入,输出对应的动作价值估计。
为了提高训练稳定性,每个主Q网络都配备了一个对应的目标网络,即 $Q_{\phi‘}^{(1)}$ 和 $Q_{\phi’}^{(2)}$。目标网络的参数通过对主网络参数进行指数移动平均(EMA)来缓慢更新:
$$
\phi' \leftarrow \tau \phi + (1 - \tau) \phi'
$$
其中 $\tau$ 是一个较小的正数(如 0.005)。这种“软更新”机制有助于稳定训练过程。双Q网络结构在计算TD目标时,使用一个网络选择动作,另一个网络评估价值,有效缓解了强化学习中因“自举”导致的Q值过度估计问题。
最终,Critic的损失函数是两个Q网络时间差分误差(TD Error)的平方和:
$$
L_{critic}(\phi) = \mathbb{E}_{(s_t, a_t, r_t, s_{t+1}) \sim D} [(r_t + \gamma (1-d_t) \min_{j=1,2} Q_{\phi'}^{(j)}(s_{t+1}, a_{t+1}) - Q_{\phi}^{(1)}(s_t, a_t))^2 + (r_t + \gamma (1-d_t) \min_{j=1,2} Q_{\phi'}^{(j)}(s_{t+1}, a_{t+1}) - Q_{\phi}^{(2)}(s_t, a_t))^2]
$$
2.2 动作Q值正则化引导的动作生成器(Actor)
本方法中的Actor采用决策变换器(DT) 结构。其训练目标不仅包括对历史动作的模仿,还引入了来自Critic的引导信号。最终的Actor损失函数如下:
$$
L_{actor}(\theta, \phi) = L_{DT}(\theta) - \alpha \mathbb{E}_{s_t \sim D}[Q_{\phi}(s_t, \hat{a}_t)]
$$
其中:
- $L_{DT}(\theta)$ 是DT模型预测动作 $\hat{a}_t$ 与真实历史动作 $a_t$ 之间的MSE损失。
- $Q_{\phi}(s_t, \hat{a}_t)$ 是Critic网络对DT生成的动作 $\hat{a}_t$ 的评分。
- $\alpha$ 是一个大于零的正则化系数,用于控制探索与模仿的权衡。
通过最小化该损失,模型被鼓励在模仿历史数据的同时,生成Critic认为价值更高的动作。
2.3 基于动作和RTG的双重探索机制
尽管Q值正则化鼓励DT在离线数据集中选择高价值动作,但最终策略仍可能局限于历史行为空间,倾向于重复已知的高价值动作,缺乏主动探索新策略的能力。为此,团队提出了双重探索机制,通过在推理阶段引入扰动,打破模型对历史轨迹的依赖,探索多样化的动作路径。
-
多目标回报条件生成(Multi-RTG):在每一步决策时,模型不只为单一的剩余回报目标(Return-To-Go, RTG)生成动作。相反,它会采样 $M$ 个不同的RTG目标 $\\{R_t^{(1)}, ..., R_t^{(m)}, ..., R_t^{(M)}\\}$,针对每个目标生成一个基础候选动作 $\\{a_t^{(1)}, ..., a_t^{(m)}, ..., a_t^{(M)}\\}$。这相当于让模型“思考”在不同剩余预算或目标下可能采取的策略,从而覆盖更广的策略空间。
-
动作扰动与多样性探索:对于上述 $M$ 个基础候选动作中的每一个 $a_t^{(m)}$,进一步叠加 $K$ 组小幅度的高斯随机噪声扰动 $\\epsilon^{(m,k)}$,从而生成一个扩展的候选动作集 $\\{a_t^{(m,k)} = a_t^{(m)} + \epsilon^{(m,k)} \\}_{k=1}^{K}$。这个过程类似于有经验的运营人员手动微调出价:“试试提高5毛或降低3毛会怎样?”,在安全范围内进行小步探索,显著丰富了候选策略的多样性。
-
Q值评估与最优决策筛选:最后,利用训练好的Critic网络对所有 $M \times K$ 个候选动作 $a_t^{(m,k)}$ 进行价值评估,并选择Q值最高的动作作为最终输出:
$$
a_t^* = \arg \max_{m, k} Q_{\phi}(s_t, a_t^{(m,k)})
$$
这套机制确保了模型在推理时能够主动探索,而非简单地复制历史行为。
3. 实验
3.1 公开基准测试
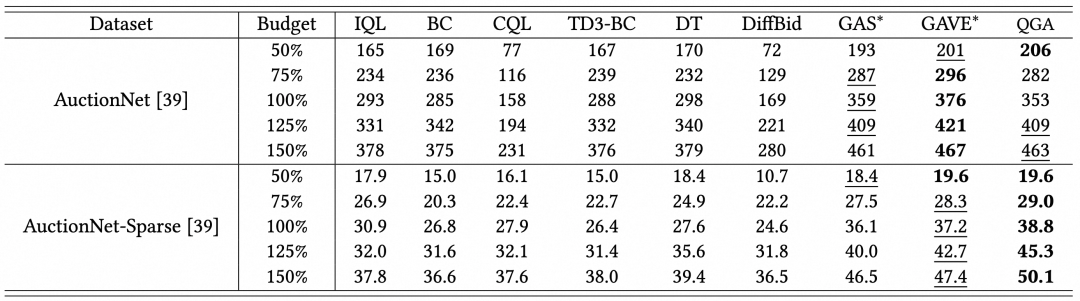
我们在阿里妈妈开源的推广出价数据集 AuctionNet 上进行了测试。如表所示,QGA模型相比现有的强化学习方法和生成式模型,在多个预算设定下均取得了持续且显著的性能提升。
3.2 Critic网络性能分析
Critic网络不仅引导Actor训练,还在推理阶段的双重探索机制中负责评估候选动作。我们使用以下指标监控其训练状态和性能:
- Critic Loss:训练损失,值越小表明Q网络预测与真实奖励越接近。
- Q_data:在整个数据集样本上计算的平均Q值,用于监控Q值估计的数值稳定性。
- Q_delta:相邻训练步之间Q值的变化量,用于监控网络参数更新的速度。
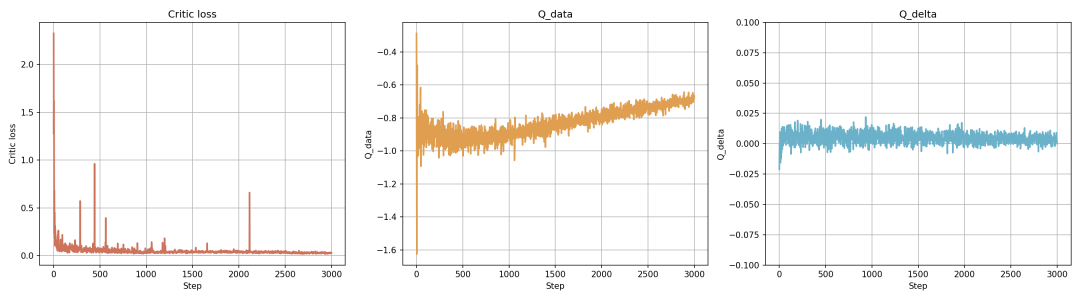
从图中可以看出:Critic Loss随训练步数增加而下降并趋于收敛;Q_data在初期波动后趋于平稳;Q_delta虽有小幅波动但始终围绕零轴。这些指标表明Critic网络的训练过程平稳、可靠,为Actor的引导和推理时的评估提供了坚实基础。
3.3 出价探索能力分析
我们评估了不同模型的平均绝对百分比误差(MAPE) 和性能得分(Score)。MAPE反映了模型模仿历史行为的能力(越低模仿越好),Score则衡量所学策略的实际优劣(越高策略越好)。
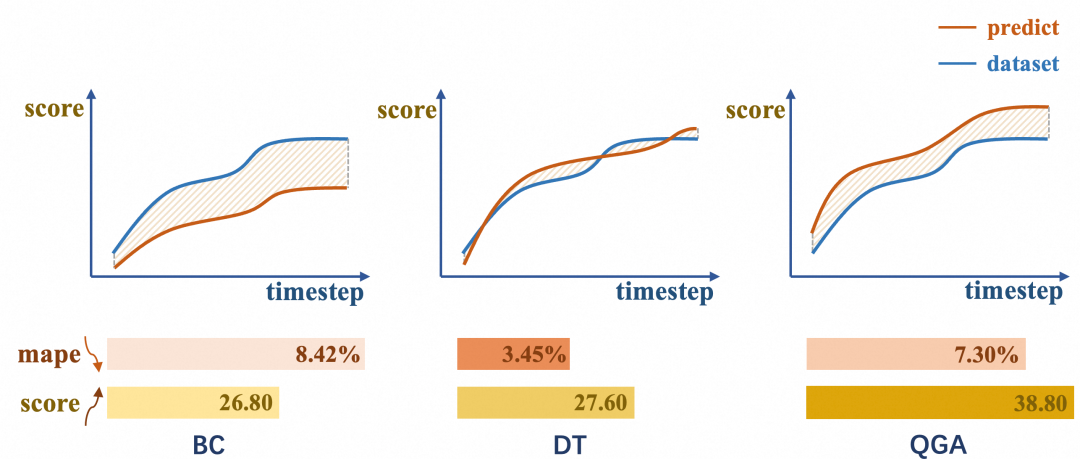
实验结果显示:
- 行为克隆(BC)方法MAPE最高、Score最低,说明其难以有效学习策略分布。
- DT模型MAPE最低,但Score仅中等,表明纯粹模仿无法获得最优策略。
- QGA模型以适中的MAPE取得了最高的Score。这说明它在有效模仿历史策略的基础上,通过引入探索机制,成功发现了更优的出价策略,验证了双重探索机制的有效性。
3.4 出价模型效果分析
我们进一步分析了不同模型随着投放时间步累积获得的流量价值。
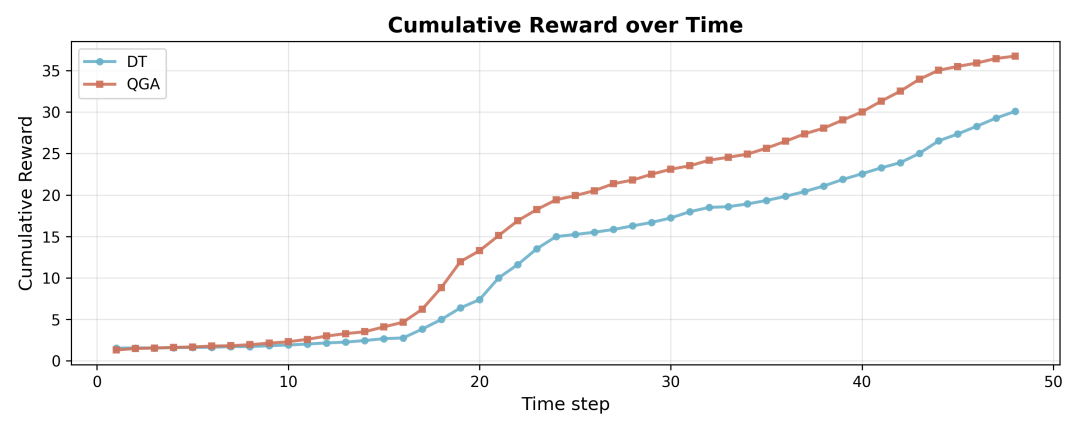
如图所示,QGA方法从第20步左右开始,累计收益便明显超越传统生成式出价模型DT,并且随着时间推移,优势持续扩大。在整个投放周期内,QGA的收益曲线不仅更高,而且增长更平滑稳健。这说明QGA并非仅在特定时刻表现优异,而是在整个周期内都能稳定发挥更优性能,展现出强大的泛化能力和对市场变化的适应性。
4. 总结与展望
通过在生成式出价模型中引入强化学习的“大脑”,QGA模型在线上取得了显著收益。这一探索也为我们带来了新的思考与挑战:
- 实时链路升级:更复杂的模型对线上推理链路的实时性和稳定性提出了更高要求。
- 端到端 vs. 两阶段出价:当前我们采用端到端方式直接生成出价动作序列。另一种思路是两阶段生成式出价:先用生成式模型规划理想的推广状态轨迹,再用轻量级模型预估出价来逼近该轨迹。这种“规划”与“执行”异步分离的架构可能更具灵活性。
- 轨迹突变适应性:线上推广环境充满突变,传统方法常依赖经验调参。对于生成式出价模型,如何利用智能体的记忆与反思能力,对线上突变轨迹进行实时纠正,从而提升模型的适应性和鲁棒性,是一个值得深入探索的方向。
对电商广告算法和生成式强化学习融合应用感兴趣的朋友,可以关注云栈社区的智能与数据板块,获取更多前沿技术解读与实践分享。我们始终相信,技术的进化源于持续的探索与开放的交流。
 发表于 2026-3-19 05:59:56
|
查看: 243|
回复: 0
发表于 2026-3-19 05:59:56
|
查看: 243|
回复: 0
