

近期,美国政府批准NVIDIA向中国部分经许可的客户销售H200芯片(需缴纳25%的销售收入分成),这一消息引发了广泛讨论,被视为美国对华AI芯片出口管制政策的部分松动。此举将对国产芯片产生何种影响?本文将从H200芯片的技术特点出发进行深入分析。
H200是NVIDIA基于Hopper架构打造的一款高性能GPU。Hopper架构于2022年正式推出,虽然在绝对性能上不及后续的Blackwell、Rubin等架构产品,但其凭借成熟的技术方案与稳定的规模化交付能力,已成为当前人工智能算力商业化落地中最广泛应用的核心方案之一,也是各大算力厂商的主力部署选择。

基于Hopper架构的产品线主要包括H100、H200、H800和H20四款核心型号。其中,H800与H20是面向中国大陆市场推出的定制版(业界俗称“特供版”或“阉割版”),受出口管制政策限制,这两款芯片在算力性能、互联带宽等核心指标上均低于H100、H200等国际标准版产品。
H800/H100:面向训练场景的对比
H800与H100的定位都是训练卡。以SXM款式进行对比,两者主要参数差异如下:
- 高精度计算能力:H800的FP64算力被大幅削减,仅为1 TFLOPs。
- 互联带宽:H800的NVLink带宽不足H100的一半,这对大模型进行大规模分布式训练时的通信效率构成了显著制约。
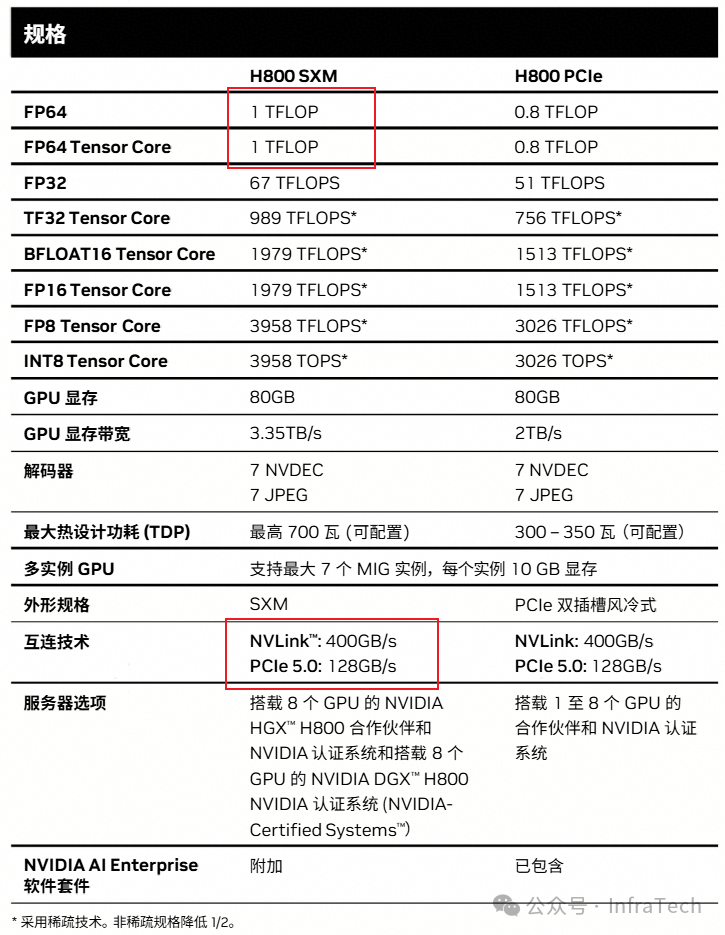
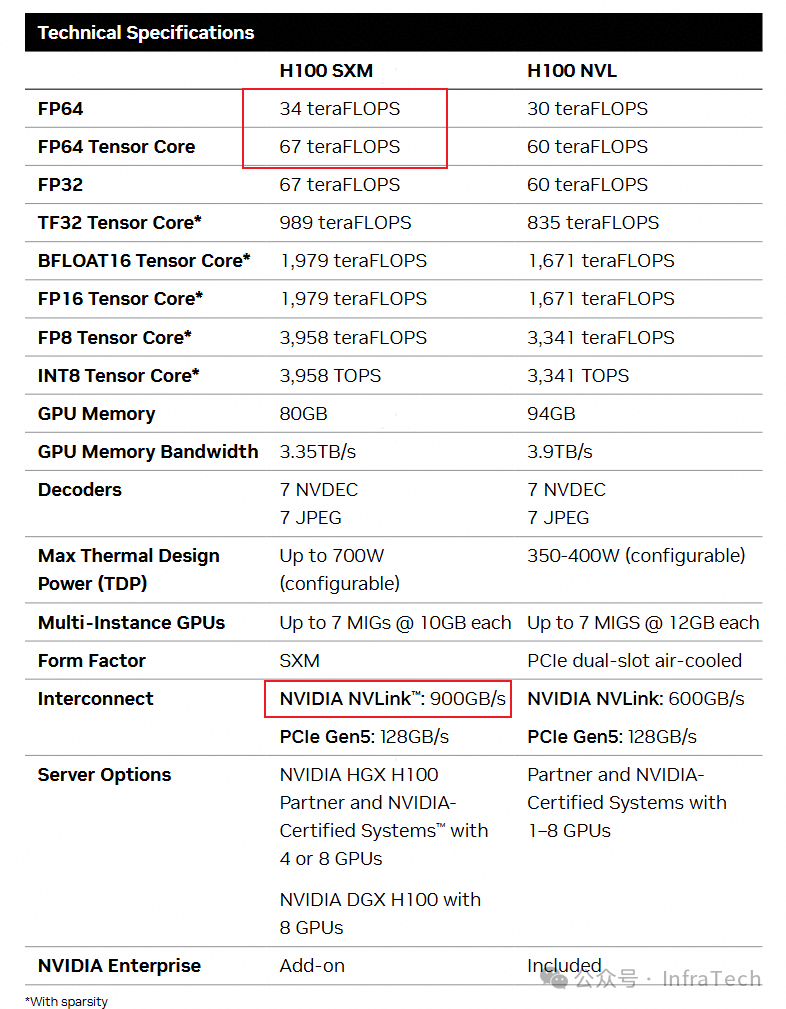
从H800与H100的对比可以看出,美国的出口管制策略旨在限制中国大陆在高性能计算(HPC)研究以及人工智能大模型训练领域的发展能力。
H20/H200:面向推理场景的对比
H20与H200则更侧重于推理场景。与H200相比,H20在算力和显存容量方面均被大幅削减,尤其是FP16/BF16算力受到严格限制,这直接影响了其运行大模型时的推理性能。
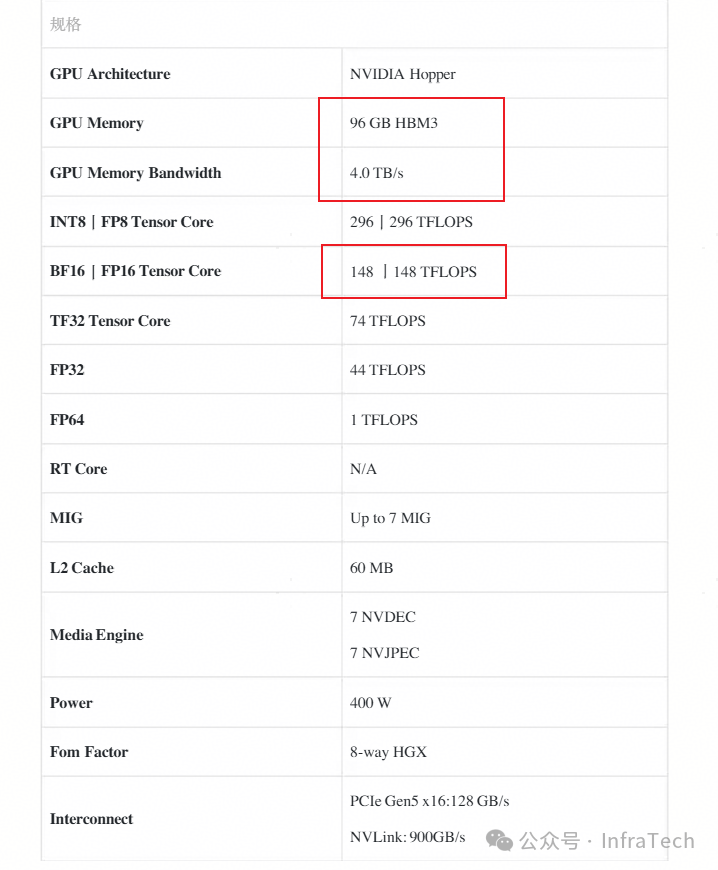
尽管H20的整体性能远逊于H200,但与部分国产芯片相比,其在显存容量与带宽方面仍保有一定优势,能够满足国内市场的部分基础需求。然而,目前H20的性价比已落后于快速迭代的国产芯片,加之其本身存在的潜在安全漏洞问题,使其在中国大陆的市场空间日益收窄。
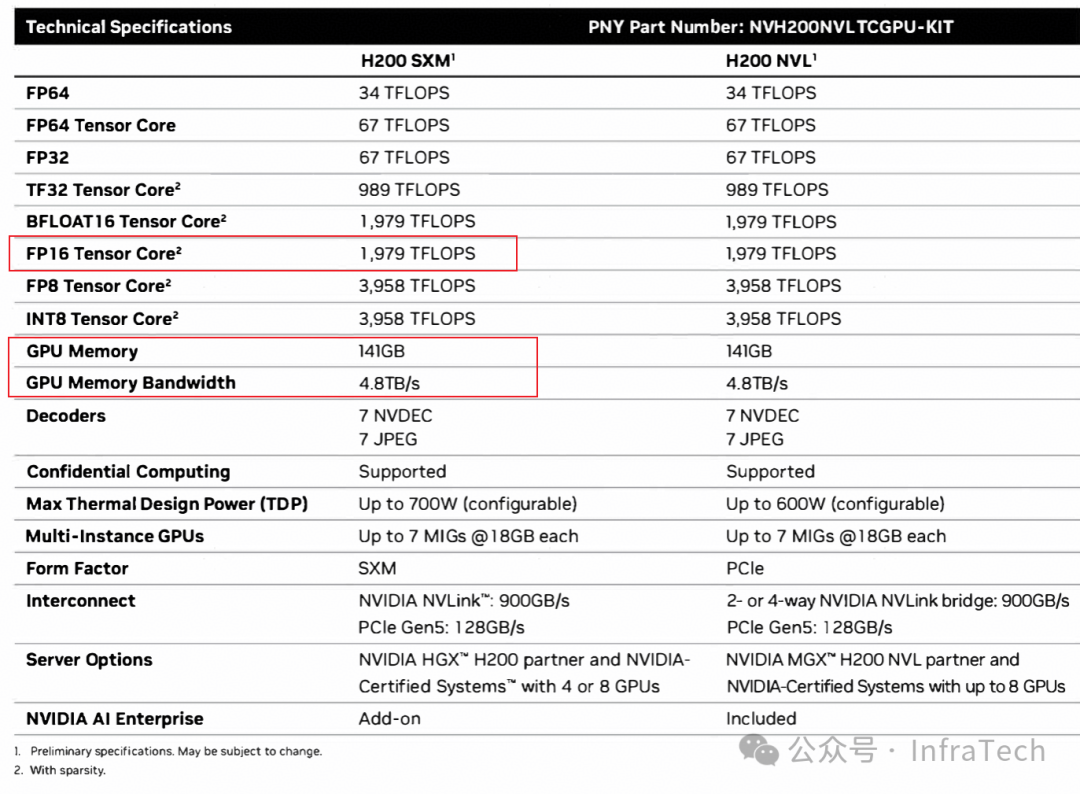
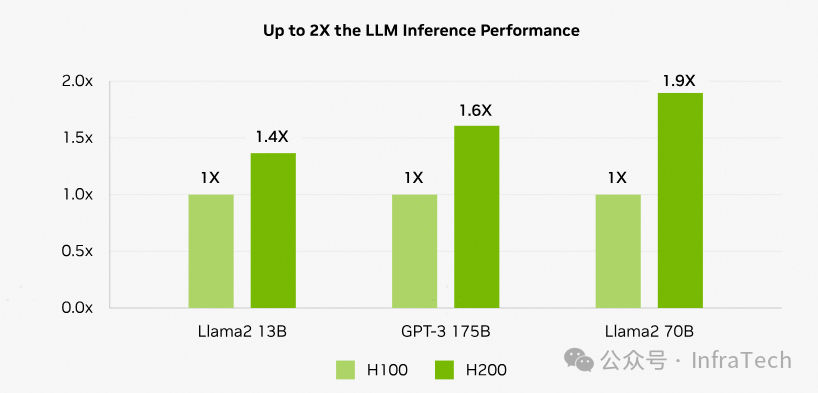
NVIDIA在推出H200时,其主要的性能参照系是H100而非H20。H200的核心改进点集中在显存子系统上,包括显存容量与显存带宽的大幅提升,其次在NVLink互联技术上也有相应优化。

显存性能的提升对于大模型推理任务的效果尤为明显,官方测试数据显示了显著的性能增益:
H200与国产旗舰芯片华为910C的横向对比
当前国产芯片正处在多元化发展的关键阶段。若综合考虑规模化量产能力与供应链稳定性等因素,现阶段具备与H200同台竞技实力的国产芯片,主要指向华为的Ascend 910C。下面我们从多个维度对二者进行详细比较。
1. 单芯片性能对比
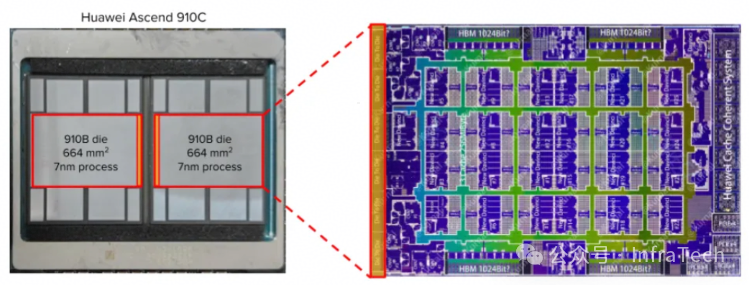
仅从芯片本身的纸面参数来看,910C处于相对劣势。其核心指标与H200(以GB200为参照)对比如下:
- BF16算力:910C约为780~800 TFLOPS,低于H200的989 TFLOPS。
- 显存容量:910C为128GB HBM,低于H200的141GB。
- HBM带宽:910C为3.2TB/s,低于H200的4.8TB/s。

需要指出的是,910C是一款由两颗910B Die通过先进封装技术拼接而成的芯片。这种设计在性能上并非简单的“1+1=2”,例如其128GB HBM由两个64GB堆栈组成,在进行跨Die数据传输时,速度远低于Die内部传输。相比之下,H200的141GB HBM为单体设计,不存在此类问题。
2. 单服务器节点对比
910C的标准服务器配置通常为8张NPU卡。根据已知信息,可以推算出其单节点的算力与内部带宽概况:
- 算力:BF16算力约为 800 TFLOPS * 8。
- 节点内带宽:采用448G以太网互联,带宽约为784 GB/s。
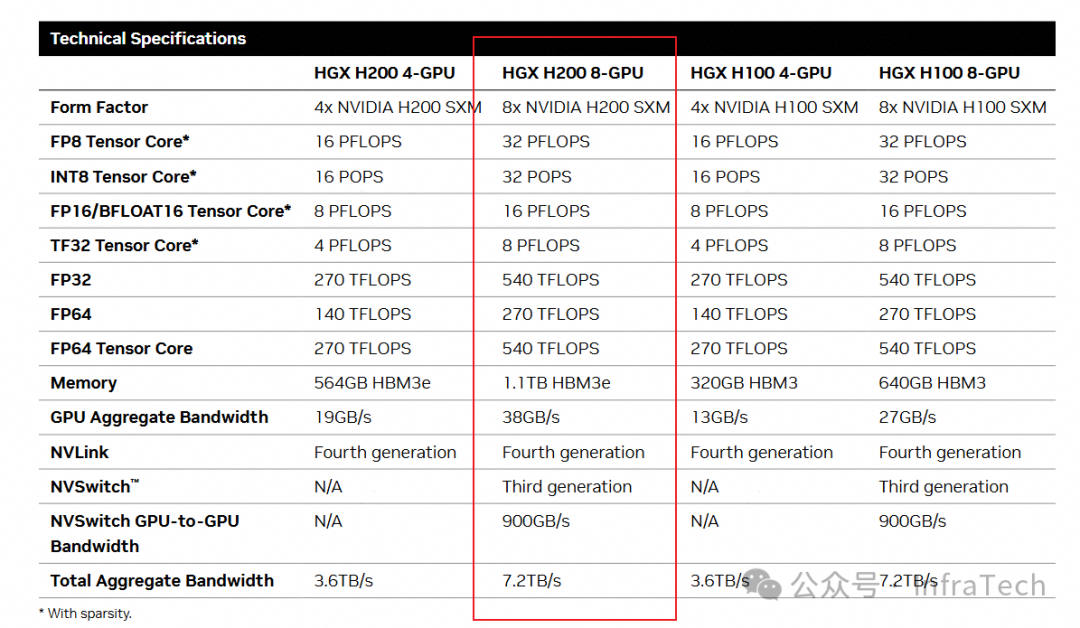
与之对比,8卡配置的HGX H200服务器在单节点性能上表现更为强劲,具体参数对比如下图所示:
3. 大规模集群(超节点)对比
构建GPU大集群面临的核心挑战之一是节点间网络通信。在超节点方案上,华为与NVIDIA选择了不同的技术路径:华为采用光互联方案,而NVIDIA则主要采用铜缆互联。
铜缆与光缆各有优劣。随着传输距离增加,铜缆的信号衰减速度远大于光缆,但光传输的初期成本更高。NVIDIA出于成本考量,在现阶段大规模部署中仍以铜缆为主;华为作为ICT领域的巨头,在光通信技术方面积累深厚、产业链成熟,这使得光互联成为了910C构建超大规模集群时的独特优势。
下图对比了由910C组成的CloudMatrix 384超节点与NVIDIA的B200 NVL72的参数。凭借在通信层面的优势,华为超节点在总算力吞吐性能上实现了对NVL72的超越,达到其近2倍的水平。
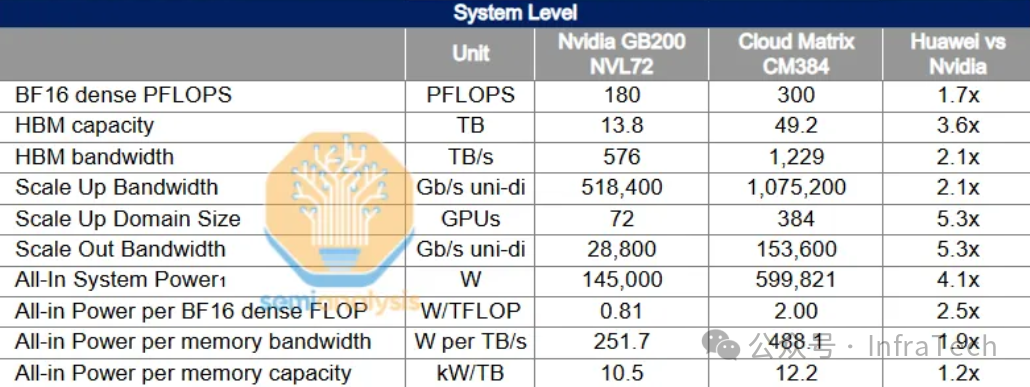
若从性能功耗比的角度审视,华为超节点的优势似乎并不突出。但对此需要辩证看待:首先,当前的功耗数据多为理论推测,实际运行功耗可能存在变数;其次,若将超节点部署在中国大陆电力资源丰富、电价较低的区域,其最终的整体运营成本未必高于NVL72方案。
总结与展望
- 在小规模部署场景下,H200凭借其在推理场景下显著的性能优势、相对成熟的CUDA软件生态以及可能具备的价格竞争力,确实难逢对手。尽管H200的产品定位侧重于推理,但其用于模型训练任务也完全能够胜任。
- 在超大规模集群应用层面,即使是比H200领先一代的NVIDIA B200(NVL72配置),在算力吞吐量上也未能超越华为的910C超节点方案。
单纯从技术维度分析,H200的重新进入中国市场,势必会对国产芯片市场产生一定冲击,但这种冲击的力度可能是有限的、结构性的。当前,国产AI芯片正处在快速迭代、新品频出的高速发展阶段,未来的市场格局仍存在诸多变数,值得持续关注。
参考资料:
- 美允许英伟达向中国出售H200芯片
- NVIDIA H100 Tensor Core GPU Architecture
- NVIDIA H20 GPU Datasheet
- 相关安全漏洞通报
- Deploying NVIDIA H200
- NVIDIA H200 产品页面
- Huawei AI CloudMatrix 384 Analysis
 发表于 2025-12-16 03:09:21
|
查看: 394|
回复: 0
发表于 2025-12-16 03:09:21
|
查看: 394|
回复: 0
