在应对高并发、高负载的业务挑战时,数据库常常是整个系统的性能瓶颈与风险核心。一次意外的流量洪峰或慢查询连锁反应,极易导致数据库雪崩,进而引发服务大面积不可用。本文将系统性地介绍从根源到外围,多层次防御数据库雪崩的核心策略。
数据库优化与水平扩展:治本之策
要确保系统在高负载下的稳定性,最根本的解决方案在于对数据库进行优化和水平扩展,从源头提升其承载能力。
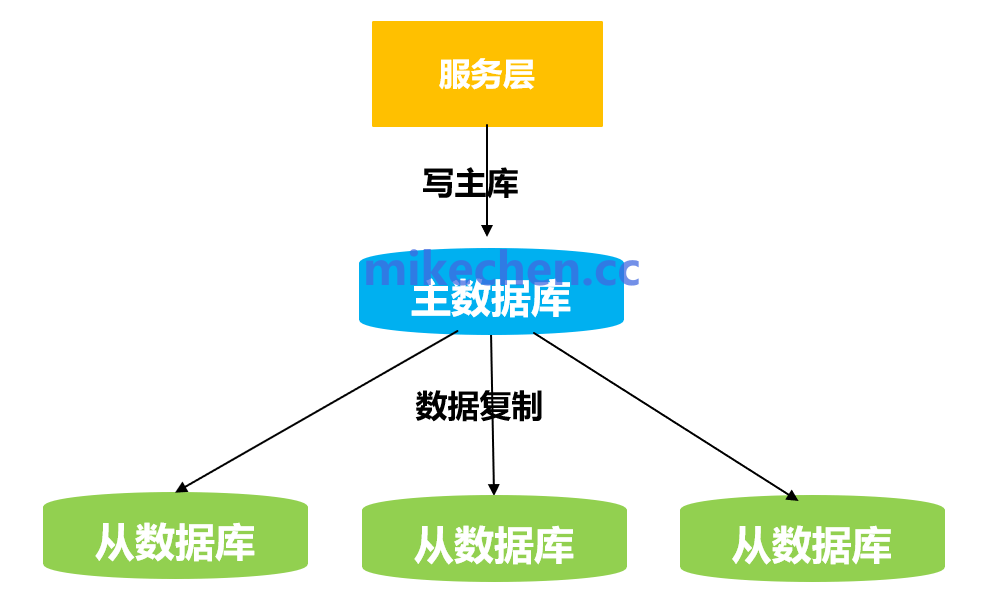
1. 读写分离
多数业务场景中,读请求的比例远高于写请求。通过读写分离,可以将读操作分流到多个只读副本(Read Replicas)上,主库(Master)则专注于处理写操作。这不仅减轻了主库的压力,也提升了系统的整体读吞吐量。
实践建议:通过数据库中间件或代理(如MyCat、ShardingSphere、或云厂商提供的读写分离代理)自动路由读写请求,对应用层透明。
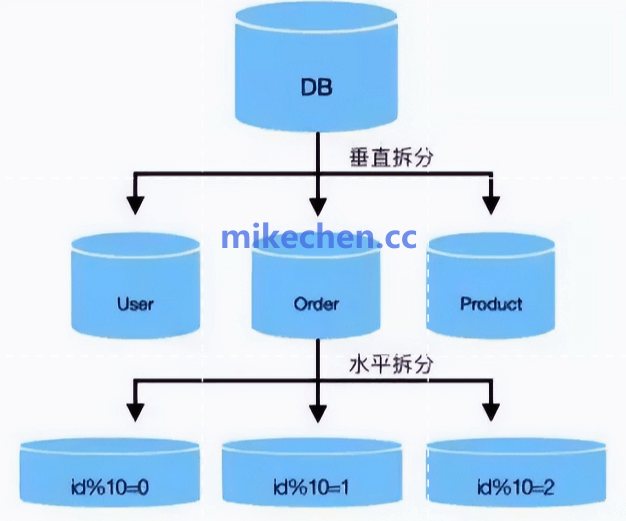
2. 分库分表
当单库单表的数据量和访问量达到极限时,分库分表是分散存储与计算压力的终极方案。
- 垂直分库:按业务模块拆分。例如,将原本庞大的单体数据库拆分为独立的用户库、订单库、商品库。这实现了专库专用,业务间隔离,避免了因一个模块的流量激增或慢查询而拖垮整个数据库。
- 水平分表:将单一业务表的数据按特定规则(如用户ID哈希、时间范围)分布到多个数据库或表中。这能有效解决单表数据量过大导致的索引膨胀、查询性能下降问题。
二级缓存与热点缓存策略:构建快速响应层
在应用与数据库之间引入缓存层,是抵挡读流量冲击最有效的手段之一。常用的数据库/中间件如Redis、Memcached,能将热点数据存储于内存,使绝大多数读请求无需访问数据库。
然而,缓存使用不当会引发缓存雪崩,其典型场景是:大量缓存Key在同一时刻集体失效,导致所有请求瞬间穿透至数据库,击穿连接池,引发系统性崩溃。
防护策略:
- 差异化过期时间:为缓存Key设置基础过期时间加上一个随机偏移值,避免同时失效。
- 热点Key永不过期:对极热点数据,采用逻辑过期或异步刷新策略,而非物理过期。
- 熔断与降级:当检测到大量缓存穿透时,快速启用本地缓存或默认值返回,保护后端数据库。
服务降级与异步化处理:保障核心链路
当系统负载达到临界点时,需要果断采取服务降级策略,暂时关闭或简化非核心功能,以确保核心业务链路的可用性。例如,在流量高峰期间,可以暂时关闭非实时的数据统计、页面渲染中的非关键模块或延迟日志上报。
在微服务架构下,结合Hystrix、Sentinel等组件可以方便地实现服务降级。

异步化处理则是削峰填谷的关键。对于非强一致性的写操作(如记录用户操作日志、发送通知)或耗时较长的任务,应将其投递到消息队列(如Kafka、RocketMQ)或异步任务队列中,由后台Worker逐步消费。这能将数据库的瞬时写入高峰平滑为持续的低流量写入。
限流、熔断与系统自愈:构筑最后防线
在流量入口(网关层)或服务层实施限流(如令牌桶、漏桶算法),严格限制单位时间内到达数据库的请求总量,从源头遏制突发流量。
熔断机制则像电路保险丝。当持续监测到下游服务(如数据库访问)错误率或延迟超过阈值时,熔断器会快速打开,直接拒绝后续请求并返回降级结果,给予下游系统恢复时间。结合合理的超时与重试策略(避免无限制重试),可以防止请求积压。
完善的监控告警体系是系统自愈的前提。必须对数据库连接数、慢查询比例、CPU/IO使用率等关键指标进行实时监控。一旦发现异常趋势,应能自动或手动触发预案,如数据库从节点扩容、服务实例弹性伸缩、或引导用户进入排队系统,从而实现系统的快速云原生自愈能力。
|  发表于 2025-12-16 23:07:52
|
查看: 230|
回复: 0
发表于 2025-12-16 23:07:52
|
查看: 230|
回复: 0
