本文通过 AI Agent 技术实现数据库异常的自动发现、智能分析与快速修复,将故障处理时间从数小时缩短到分钟级,异常误报率显著降低。

背景:传统运维的三大核心痛点
随着业务规模快速增长,大型企业的数据库规模通常达到数十万实例、千万级库表,涵盖MySQL、PostgreSQL、MongoDB、ClickHouse、Redis、Milvus等多种类型。日常运维中,常见的故障点分布广泛:
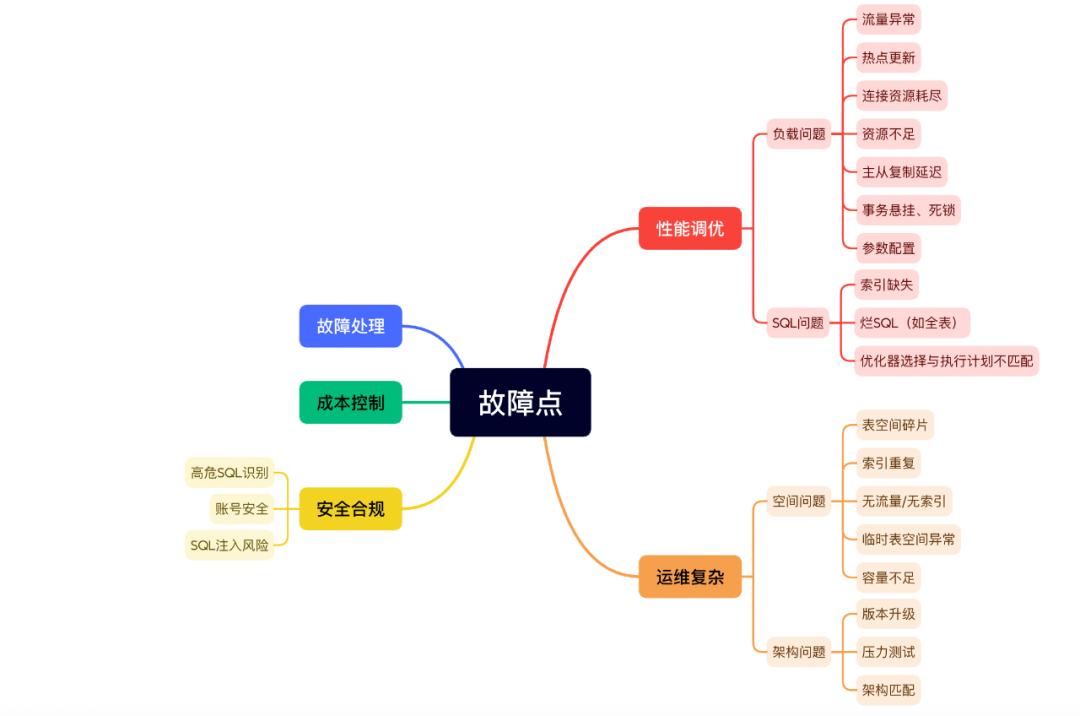
图1:数据库常见故障点
分析运维数据可以发现:
- 约80%的故障处理时间消耗在问题分析与根因定位环节。
- 平均故障处理时长(MTTR)可达195分钟,其中约70%为性能调优类问题。
传统依赖人工经验的诊断模式面临三大核心挑战:


AI智能诊断的三大核心优势
基于 AI Agent 构建的智能诊断系统,相比传统方式展现出三大核心优势。
1. 多模态融合诊断
- 传统方式:孤立检查单项指标,依赖人工经验进行关联分析。
- AI方式:可同时处理数百个性能指标,自动挖掘隐式关联关系,融合五种数据模态:
- 指标时序数据(来自Prometheus/Grafana等监控系统)
- 文本日志(错误日志、慢查询日志)
- 配置信息(如
my.cnf)
- SQL文本(查询语句、执行计划)
- 拓扑结构(主从关系、分片信息)
实战案例:数据库突然变慢
- 指标:QPS下降50%
- 日志:出现大量
Lock wait timeout 错误
- SQL:某
UPDATE语句执行时间从10ms激增至5s
- 配置:
innodb_lock_wait_timeout 参数设置为50s(过长)
- 拓扑:发现
UPDATE操作被错误路由到只读从库执行
AI诊断逻辑:应用错误路由至从库 → 从库只读导致写操作阻塞 → 连接池耗尽 → 整体QPS下降。
价值:将此类复杂问题的排查时间从数小时缩短至分钟级。
2. 动态自适应诊断
- 传统方式:依赖固定阈值告警,无法区分“正常业务高峰”与“异常高负载”。
- AI方式:
- 自动识别业务模式:区分工作日/周末、业务高峰期/低峰期。
- 综合异常评分:基于多维度指标计算异常程度分数。
- 迁移学习:将在A数据库积累的诊断经验,迁移应用于架构相似但业务不同的B数据库。
实战案例:CPU使用率升高
- 传统告警:CPU使用率达到85%即触发告警(可能仅是正常业务高峰)。
- AI判断:CPU 85% + 查询模式异常 + 连接数突增 + 与历史同期对比异常 → 综合评分0.92(高度异常)→ 精准告警。
价值:使异常误报率降低60-80%。
3. 预测性诊断
- 传统流程:问题发生 → 用户投诉 → DBA介入分析 → 解决(业务已受影响)。
- AI能力:
- 时序预测:预测未来1-24小时的性能趋势。
- 故障预测:提前预警磁盘空间、容量瓶颈。
- 性能退化预警:提前发现索引效率下降等问题。
实战案例:磁盘空间预警
AI模型输入:磁盘空间增长率(呈指数趋势)、表大小增长率、历史数据清理周期。
AI输出:“预计3天后磁盘将写满,建议立即执行数据归档操作”。
价值:实现从被动“救火”到主动“防火”的转变,将故障处置节点从“已发生”提前至“即将发生”。

技术架构:统一平台+知识库+AI Agent
3.1 整体架构
- 多数据库类型支持:覆盖OLTP、文档型、分析型、键值型及向量数据库等。
- 多模数据管理平台:
- OneMeta:将各类数据库统一为“可理解、可治理、可查询”的数据资产。
- OneOps:提供DBaaS(数据库即服务)体验的运维控制平台。
- AI驱动核心:构建融合专家经验的数据库知识库,并驱动 AI Agent 执行诊断。
- AI应用场景:开发提效、智能诊断、运维自治等。
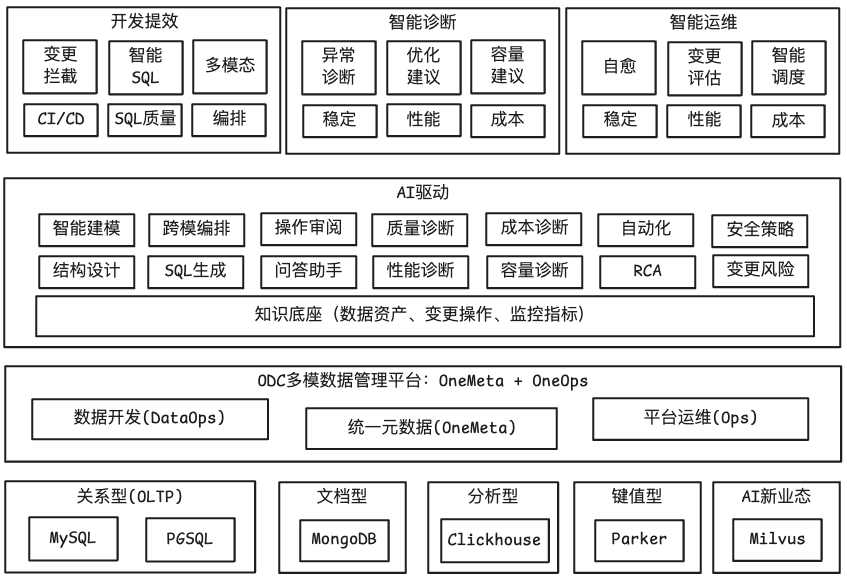
图2:AI智能诊断系统整体架构
其中,多模数据管理平台ODC已稳定投入使用。下文将重点剖析智能诊断模块的实现。
3.2 智能诊断核心组件
- OneMetrics:统一监控指标输入与异常监测
- 运行日志:慢日志、错误日志、审计日志。
- 性能指标:CPU、内存、IO、连接数等。
- 操作日志:扩缩容、主从切换、参数修改历史。
- 诊断自治服务:专家经验 + AI Agent
- 异常识别:自动识别CPU飙高、慢日志激增等场景。
- 异常分析:结合AAS分析与AI Agent智能诊断。
- 异常定位:基于RAG的检索增强生成技术。
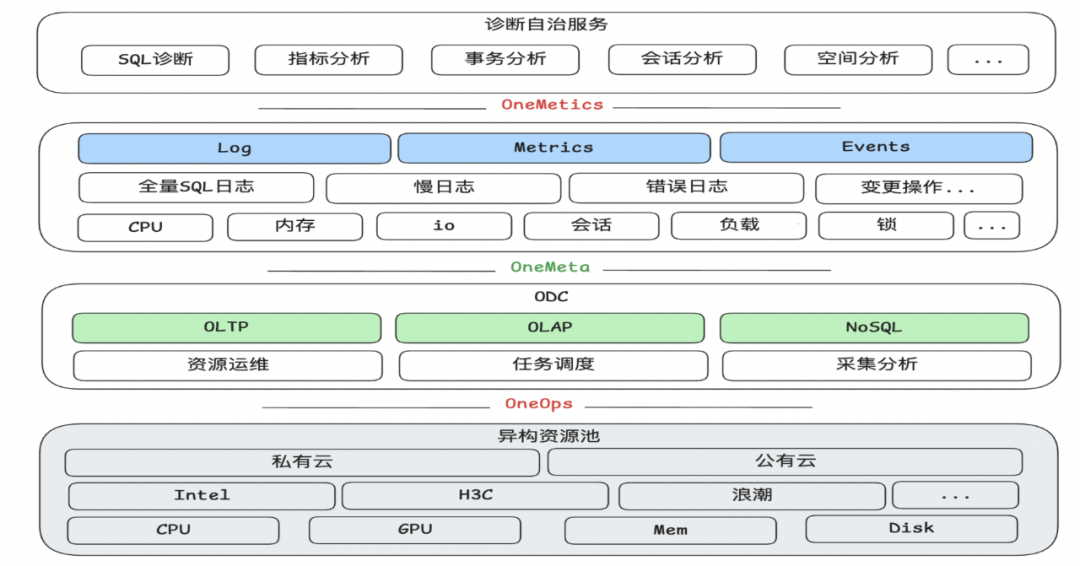
图3:诊断自治服务流程

核心技术:专家经验与RAG增强的AI融合
4.1 诊断演进路径
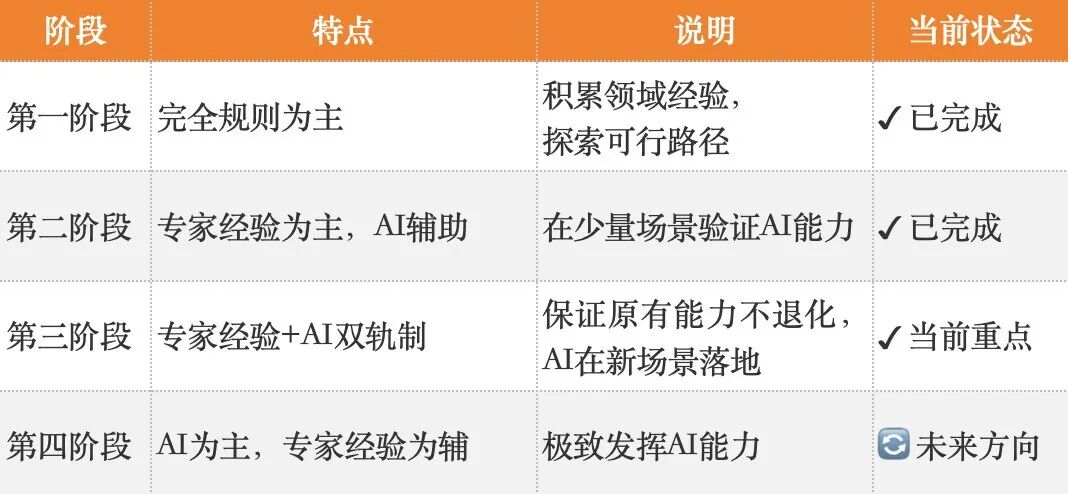
4.2 诊断流程:识别 → 分析 → 定位
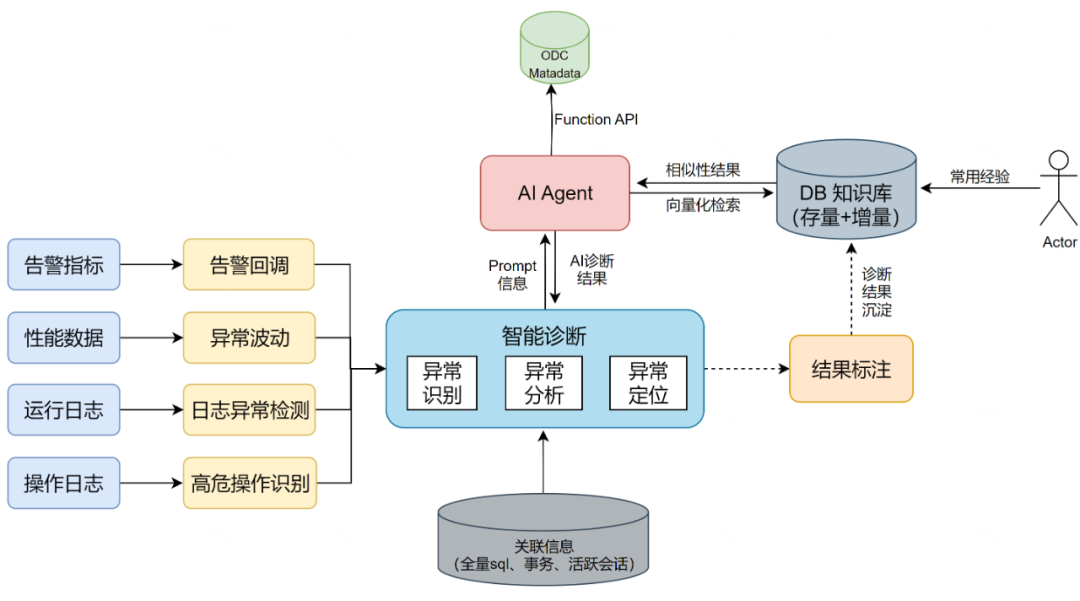
图4:智能诊断方案
4.2.1 异常识别
依赖实时数据采集与监测,自动识别预设异常场景,如:CPU/内存异常、慢日志/错误日志激增、主从切换、整库整表删除等。
4.2.2 异常分析
- 专家经验部分:以AAS(平均活跃会话数) 为关键切入点。
- AAS趋势直接反映数据库实例负载变化。
- 优先处理AAS计数高的会话状态,可快速初步定位根因。
- AI Agent部分:将异常信息、各类日志、AAS数据、监控指标等整合为结构化Prompt,交由AI Agent执行预设诊断流程,并输出分析结果。
4.2.3 异常定位
技术方案:基于RAG(检索增强生成)。
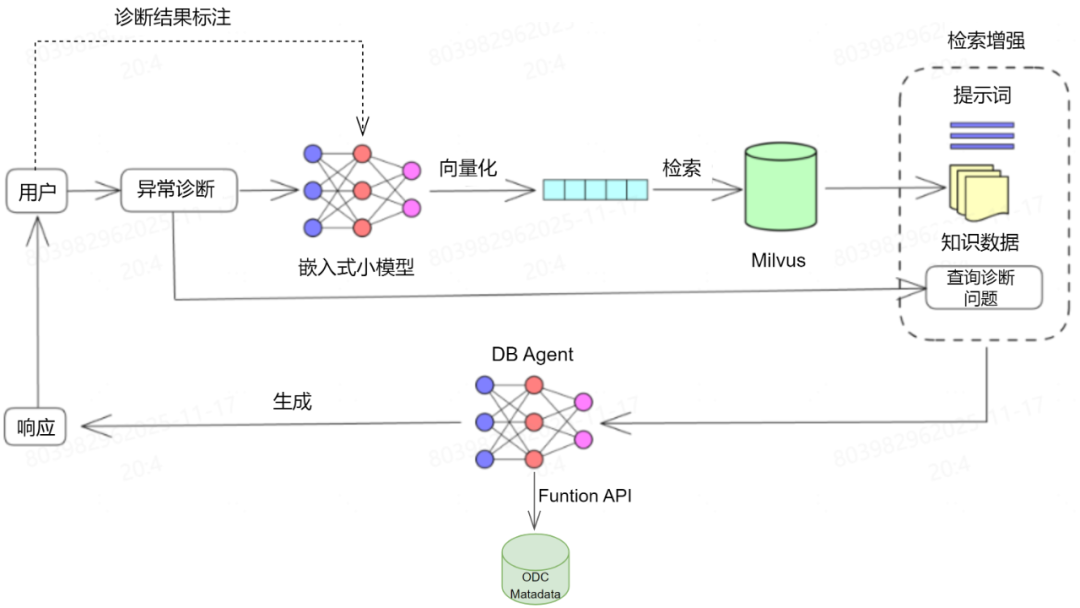
图5:基于RAG的异常定位技术架构
RAG方案优势:
✅ 结合通用知识库与人工标注结果,减少“AI幻觉”。
✅ 融入企业私有业务知识,提升场景化诊断准确性。
✅ 通过调用OneMeta API获取实时元数据,增强诊断依据。
反馈闭环:
用户对诊断结果进行评价(采纳/否决)后,系统将对应的Prompt与标注结果输入模型,用于更新和优化知识库,实现效果持续提升。
4.3 结果评估:双重保障机制
- AI评估:使用专用小模型对DB Agent的输出进行初步评估。
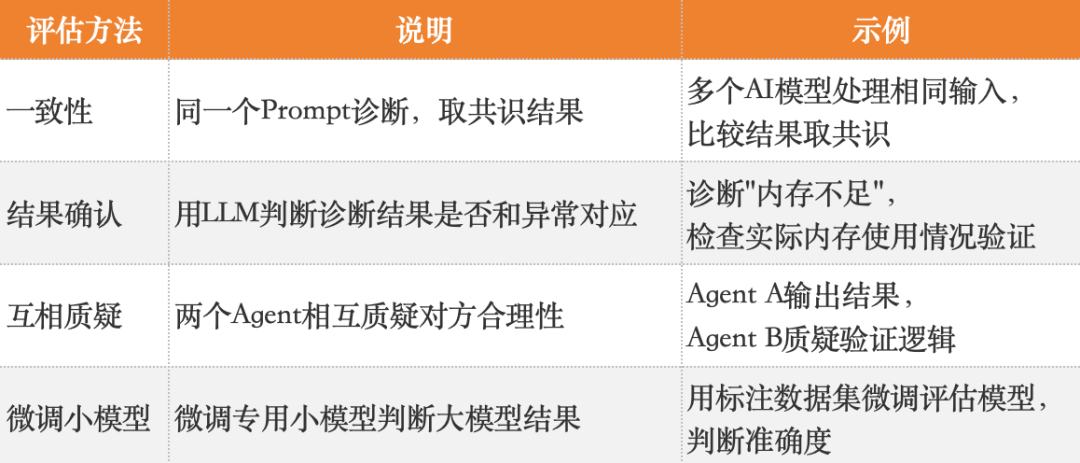
- 人工评估:
- 用户评估:一线运维人员对诊断结果的准确性和可行性进行评估。
- 专家评估:资深DBA对结果的安全性、相关性进行复核。
- 知识库更新:剔除劣质案例(Bad Case),存入优质案例,持续迭代优化。
重要性:尽管评估成本较高,但这是提升 数据库 AI Agent准确率、确保基础组件稳定性的关键环节。

实战案例:CPU飙高智能诊断全流程
5.1 异常监测
在性能诊断界面,系统发现某数据库实例CPU使用率在21:03-21:13期间突然飙升至85%,自动触发智能诊断流程。
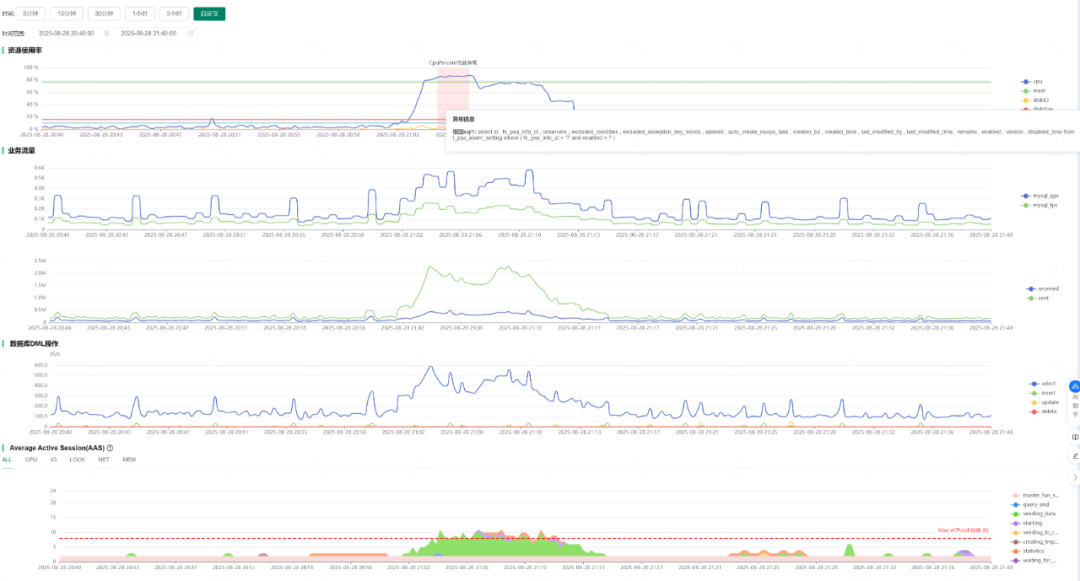
图6:CPU使用率异常监测界面
5.2 根因分析与定位
通过AAS分析发现:
Sending_data 状态的会话负载最大。- AAS数量变化趋势与CPU飙高时间段完全吻合。
- 业务发送数据量与MySQL TPS同时增多,相互佐证。
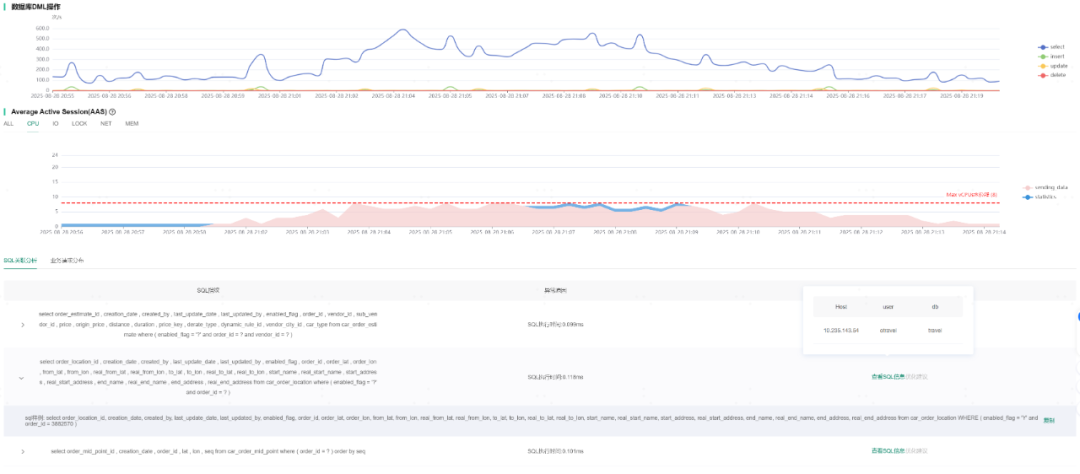
图7:AAS分析图
AI推断:CPU飙高原因为数据库查询时 Sending_data 数据量过大。通过SQL指纹关联分析,精准定位到导致问题的具体SQL语句。
5.3 优化建议
AI提供具体的索引优化建议与SQL改写方案,并支持一键跳转至ODC数据变更界面执行。
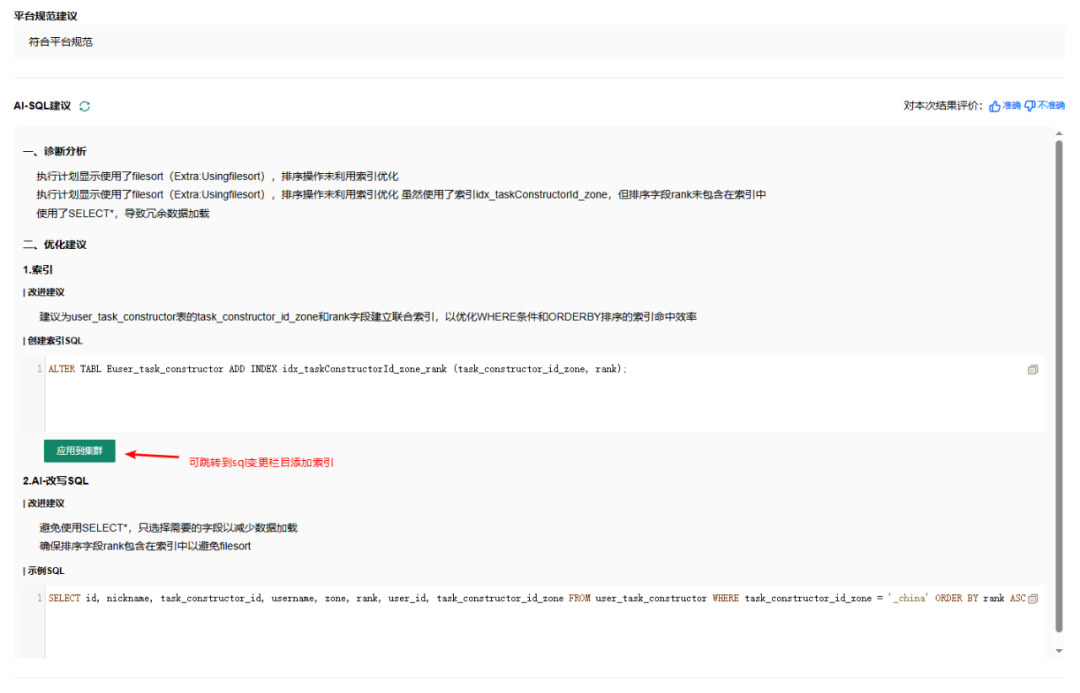
图8:SQL优化建议界面

核心价值与未来展望
1. 核心成果
- 异常发现及时性:从被动响应升级为主动预测。
- 根因诊断高效性:平均处理时间从数小时缩短至分钟级。
- 异常告警准确性:误报率降低60-80%。
2. 技术亮点
- 多模态融合:有效关联指标、日志、配置、SQL、拓扑等多源数据。
- RAG增强生成:结合知识库与专家经验,大幅提升诊断准确性。
- 双轨制保障:“专家经验规则库 + AI推理”双引擎,保障系统稳定性。
- 反馈闭环:通过用户与专家评估,实现模型与知识库的持续优化。
3. 未来方向
- 持续优化AI模型,进一步提升诊断准确率与覆盖场景。
- 扩展支持更多类型的 数据库 与数据源。
- 增强预测性诊断能力,更早发现潜在风险。
- 探索并完善自动化修复(Auto-Remediation)能力。

总结
基于AI Agent的数据库智能诊断系统,实现了资源监控与SQL操作的智能关联,能够精准锁定异常根因并提供优化方案,形成了“异常发现-诊断-修复-优化”的完整闭环。
需要注意的是,AI的诊断结果并非百分百准确,在部分关键或复杂场景中仍需人为审核与决策。DB Agent的建设是一条需要持续投入、不断迭代优化的漫长道路,其最终目标是成为 数据库运维 工程师高效、可靠的智能助手。 |  发表于 2025-12-18 00:29:54
|
查看: 180|
回复: 0
发表于 2025-12-18 00:29:54
|
查看: 180|
回复: 0
