本文旨在探讨一种名为 Trustworthy Generation 的设计模式,其核心目标是提升 RAG(检索增强生成)系统生成内容的信赖度。这里的“信赖度”主要包含两大维度:真实性(即生成内容是否准确、无幻觉、无偏见)与完整度(即是否全面、不遗漏关键信息)。接下来,我们将系统性地分析 RAG 信赖度不足的四大根源,并围绕“可解释、可追溯、可反思、可监管”四个层次,详细阐述相应的解决方案与权衡考量。

一、问题根源:为何RAG会“失信”?
RAG 技术已广泛应用于各类场景,其核心流程不外乎“检索”(Retrieve)与“生成”(Generate)两大动作,本质上是在进行上下文工程的内容补充。尽管我们在知识库中填充的往往是经过梳理的“高质量”信息,但最终由大语言模型(LLM)生成的内容,仍可能因以下几种典型情况而出现信赖度问题:
-
检索错误
- 准确率问题:检索出的信息虽然向量相似度高,但内容相关性弱。这里存在一个常见误区:高向量相似度 ≠ 高内容相关性(high similarity ≠ high relevant)。
- 召回率问题:知识库中实际存在高度相关的内容,却未能被成功检索召回。
-
内容可靠性问题
检索召回的信息虽然是相关的,但其本身可能带有偏见、已经过期,或者不同来源的内容之间存在矛盾与冲突。
-
前置推理错误
这一问题通常源于检索前的查询(Query)扩写或“Step-Back”问题抽象环节出现偏差,导致检索方向错误,进而获取了有偏差的上下文。
-
模型幻觉
在面对复杂问题时,RAG 可能召回大量繁杂内容。LLM 在生成最终答案时,容易“加戏”,即基于不充分的关联或错误理解进行推理,从而产生事实或逻辑上的幻觉。
以上情况基本涵盖了 RAG 实践中的主要痛点。需要明确的是,这些问题无法被“根治”,本文所探讨的 Trustworthy Generation 设计模式,旨在通过一系列技术手段与人机交互的结合,降低问题发生的概率,并提升对问题出现的感知能力,从而系统性提高 RAG 系统的整体信赖度。
对于希望深入探讨 AI 可信性与模型优化策略的开发者,欢迎在 云栈社区 的人工智能板块交流更多想法。

二、解决方案:构建可信RAG的四层框架
解决方案围绕建立信赖度的四个递进层次展开,可以通俗地理解为:
- “解决不了的事情要明确说出来”:不强行生成,这是建立信赖的第一步。
- “说话要有依据”:为生成内容中的关键信息附上可追溯的出处。
- “深思熟虑,为自己的言论负责”:在检索过程中引入反思与递进机制,并对结果进行质量把关。
- “建防护、受监管”:构建面向信赖度提升的工程化技术链路,并融入人机交互的监督机制。
下面,我们将深入几个关键技术模块。
模块一:信息关联度识别
我们在工程链路中使用 RAG,本质是为当前查询补充关联信息。因此,如果一个 RAG 模块能够做到:a. 只返回有关联的信息,且 b. 在没有检索到足够关联信息时,明确告知不返回,就能极大提升用户对其的信赖感。
当前的主要问题在于 RAG 经常返回“相似但不相关”的信息。提升对“相关性”的识别能力是关键,主要有三种实践思路:
- 相似度阈值(Threshold)设置:RAG 检索基于向量相似度排序并返回 top-K 个结果,但常缺乏底线阈值。可以为相似度设定一个阈值,低于该值的结果不予召回(此阈值需根据具体场景调优)。有研究表明,当信息不相关时,向量相似度会陡然下降,可以利用这一趋势进行截断。
- 问题类型分类:在 RAG 调用前,先对用户问题进行分类。如果问题不在当前知识库覆盖的范围内,则不触发 RAG。
- 领域关键词识别:仅当检测到查询中包含特定领域关键词或术语时,才触发 RAG 调用,这是一种非常严格的限制策略。
模块二:引用出处说明
第二种提升信赖度的方式是,像学术论文一样,为 RAG 生成的内容明确标识出其引用的知识片段。实现方式主要有三种:
1. 信息直接来源引用
即直接指出内容来源于哪个知识文档或分块(Chunk)。以下是一个相关的 Prompt 示例:
template = """Answer the question based on the following sources, using in-line citations like in scientific papers.
SOURCES:
{sources}
QUESTION: {question}
INSTRUCTIONS:
1. Use information only from the provided sources
2. Provide an answer with in-line citations using brackets, e.g., "Einstein developed the theory of relativity [1]"
3. Use the source ID in brackets [1], [2], etc., corresponding to the source number
4. Cite ALL facts with their source IDs
5. If multiple sources support a fact, you can include multiple citations [1][2]
6. If the information isn't in the sources, say "I don't have enough information to answer this question"
7. Include a "References" section at the end listing all the sources you cited
Your answer should be comprehensive, accurate, and include citations for all factual claims.
"""

2. 有判断的引用来源说明
先判断某段内容是否需要通过引用来增强可信度。这个判断可能基于应用领域以及该事实对整体答案的重要性。例如,在句子“王二生于1990年3月3日,出生在一农民家庭,于2015年被评为全国劳模”中,出生信息可能无需引用,但所获荣誉则需要明确出处。这通常需要针对特定领域微调一个小型判断模型。
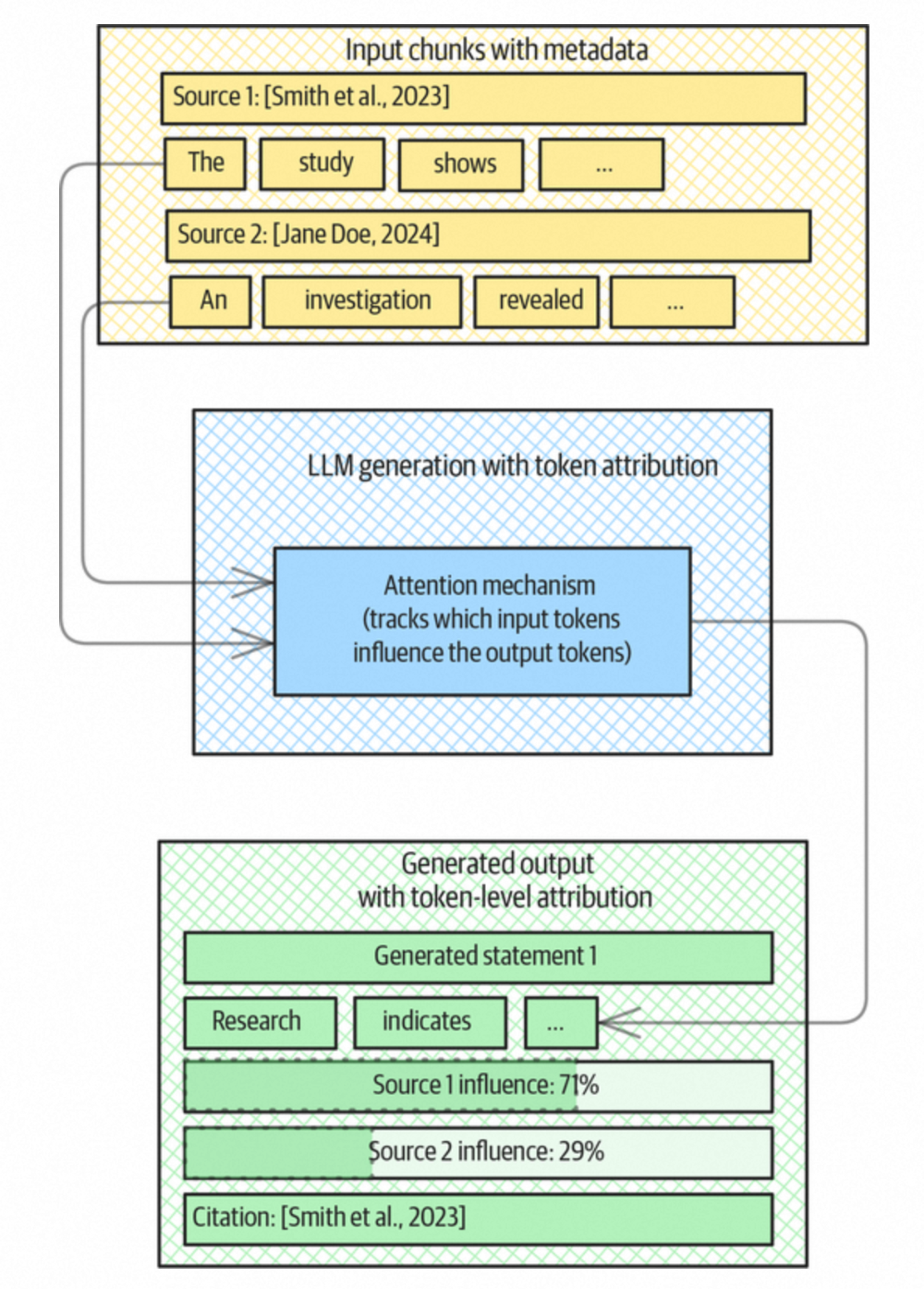
3. 基于Token级别的关联说明
在回答复杂问题时,可能会召回多个文档,最终答案的每个段落可能是综合多个文档内容生成的。这仍可能导致逻辑编排错误或事实混淆。Token 级别的关联说明旨在追溯输出中每个 token 受哪些输入 token 影响,目前尚无成熟的现成库,其概念如下图所示:
模块三:自我批判与反思
我们在设计和使用 RAG 时,通常默认知识库内容是“正确”且“高质量”的。然而,知识库内容是否足够正确、是否比模型自身参数知识更优质,并非一个固定结论,而是因时因事而异的。因此,批判性地看待检索结果并在过程中引入反思,对提升 RAG 信赖度至关重要。
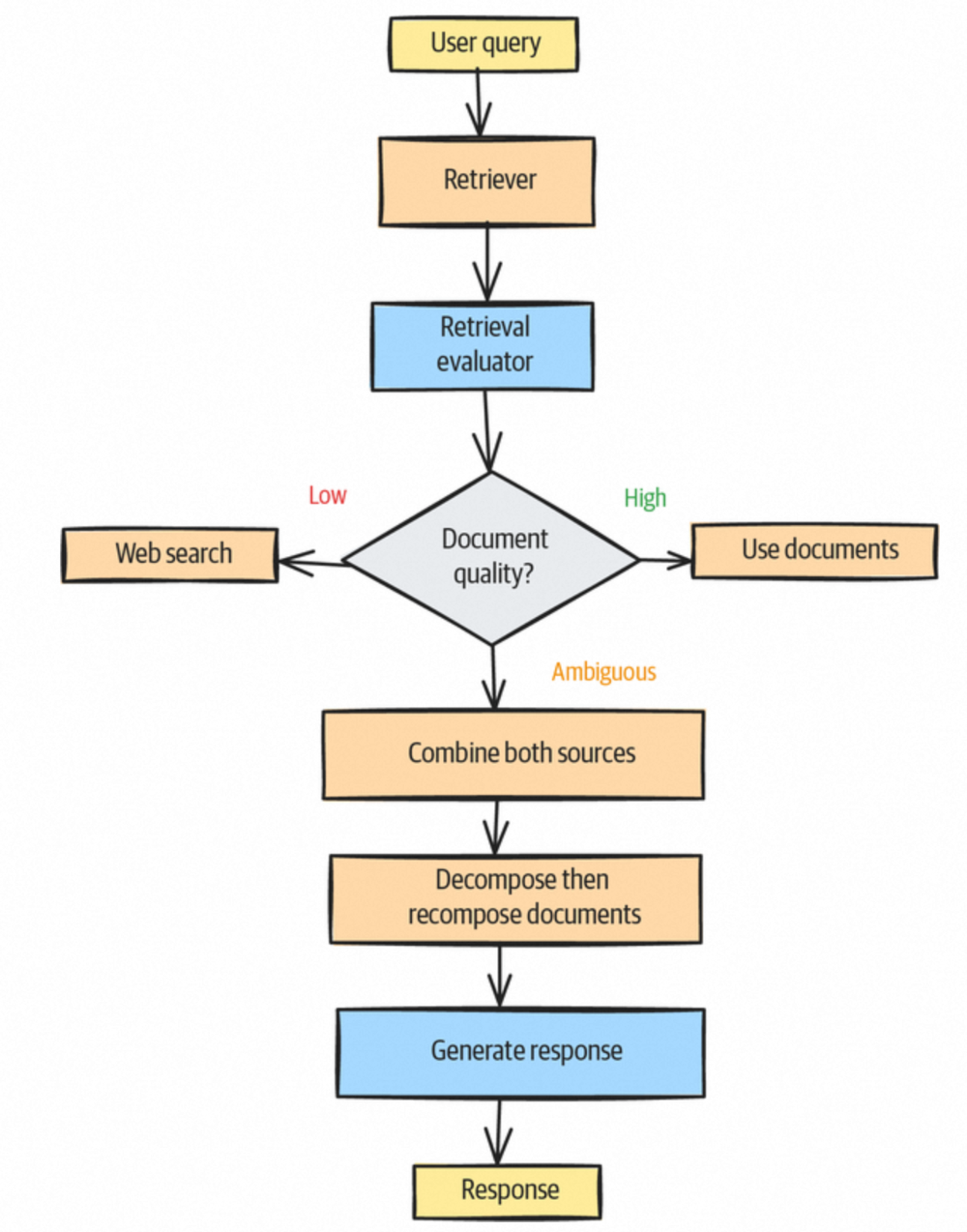
- CRAG(校正性检索增强生成)
CRAG 主要解决两个问题:1) 评估检索文档的质量(正确性),过滤低质量文档或通过其他知识库/网络搜索进行补充;2) 评估检索文档的关联性,裁剪掉与查询不相关的部分。其流程示意如下:
以下是 LangChain 中基于 LLM 的文档相关性打分实现示例:
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
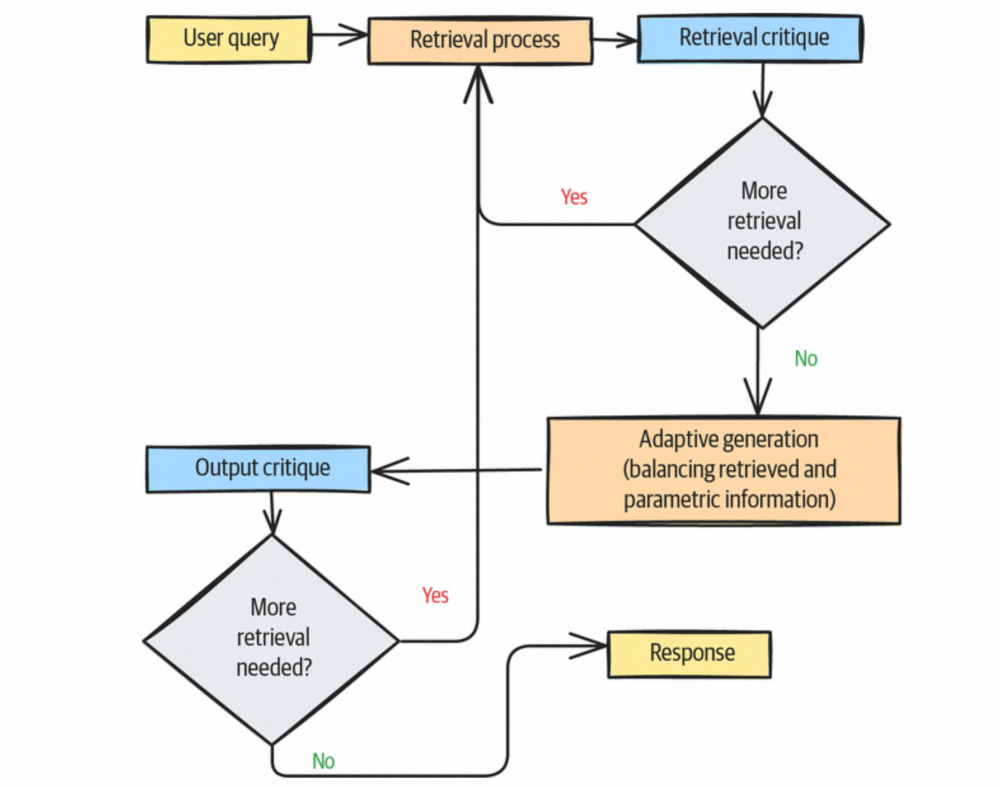
- Self-RAG(自反思检索增强生成)
Self-RAG 主要具备三个职能:1) 评估检索文档的相关性与质量,进行过滤;2) 判断是否需要基于当前结果进行进一步检索(类似于智能体化 RAG 的思路);3) 评估文档内容,判断是否直接调用底层 LLM 的知识来替代部分文档内容,以利用基础模型快速发展的红利。其流程示意如下:
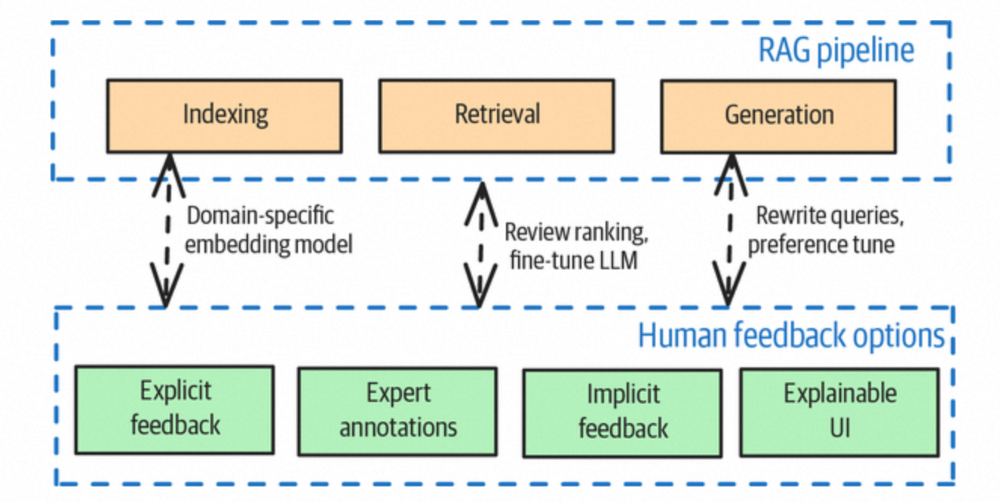
模块四:工程防护与人机监管

三、权衡与考量
上述提升 RAG 信赖度的方案,大多会增加系统架构的复杂性以及模型调用次数,从而影响整体性能与成本。因此,是否采用、采用哪些手段,需要结合实际业务需求进行谨慎权衡。
局限性
- 阈值动态性:RAG 检索极度依赖向量相似度计算。上文提到的相似度阈值,在实际中可能难以直观确定,需要结合评测不断调整。并且,该阈值会随着知识库内容和领域的扩展而变化,需要定期检测与调整。
- 误过滤风险:本模式中涉及对检索内容的打分、质量判断等操作,这些判断本身并非百分之百准确。如果过滤策略过于严格,可能会误杀掉有用信息,反而影响最终结果的完整性。
替代方案
如果经过权衡后决定不采用上述复杂模式,以下三种相对轻量的方式也值得考虑:
- 双知识库交叉验证:为 RAG 系统增设一个独立维护的知识库,每次查询同时检索两个库,并对结果进行交叉验证,以提升信息的可靠性。
- 增强过程透明性:向用户展示检索到的信息概述,以及模型得出结论的思考链(Chain-of-Thought),通过增加解释性来间接提升信赖度。
- 带置信分的引用标注:在提供引用来源的同时,为每个引用附上一个“置信分”,让用户自行判断特定信息的可靠程度,并决定后续行为的依赖程度。

参考资料
探索复杂系统架构与 设计模式 的更多实践,能够帮助我们更好地构建稳定、可靠的技术方案。
 发表于 2026-2-10 02:32:24
|
查看: 233|
回复: 0
发表于 2026-2-10 02:32:24
|
查看: 233|
回复: 0
