在Linux内核的网络子系统中,sk_buff(常简写为skb)扮演着绝对核心的角色。每一个流经系统的网络数据包,无论其承载的是HTTP请求、视频流还是DNS查询,都会被封装在这个统一的数据结构中。理解sk_buff的设计与运作机制,是深入掌握Linux网络栈性能与行为的钥匙。
想象一个高效的物流系统,sk_buff就像是标准化的集装箱。它规定了统一的“包装规格”,内部货物(应用数据)被层层封装上“面单”(各层协议头部),并在“分拣中心”(内核协议栈)中根据面单信息被快速处理与转运,最终抵达目的地。
设计哲学与核心概念
sk_buff的设计深刻体现了Linux内核追求高效与灵活的理念:
- 统一封装:贯穿以太网、IP、TCP/UDP直至应用层的所有协议,都使用同一数据结构进行处理。
- 零拷贝导向:通过精巧的指针操作,在不同协议层间传递时避免不必要的数据内存复制。
- 分层解耦:各层只关心和处理属于自己的协议头与数据部分,通过调整指针“视窗”实现。
- 共享与计数:支持引用计数,允许单个数据缓冲区被多个
sk_buff描述符共享,提升内存利用率。
其核心在于三组关键指针,它们共同定义了一个“可滑动的数据视窗”:
struct sk_buff {
/* 缓冲区边界指针 */
unsigned char *head; // 分配的内存块起始地址
unsigned char *data; // 当前协议层有效数据的起始地址
unsigned char *tail; // 当前协议层有效数据的结束地址
unsigned char *end; // 分配的内存块结束地址
/* 数据包信息 */
unsigned int len; // 数据包总长度 (data区长度 + 分片数据长度)
unsigned int data_len; // 分片数据长度 (存在于非线性区域)
__u16 protocol; // 上层协议标识 (如ETH_P_IP)
// ... 更多字段
};
你可以将head和end理解为望远镜的固定筒身边界,而data和tail则是你当前通过目镜看到的画面范围。在不同协议层,我们只需滑动(调整)data/tail指针,就能观察或处理数据包的不同部分,无需搬动整个“望远镜”。
数据结构深度解析
一个完整的sk_buff结构包含管理网络数据包所需的各种元信息(基于Linux 5.x内核精简):
struct sk_buff {
/* 链表管理 */
struct sk_buff *next;
struct sk_buff *prev;
/* 所属Socket与网络设备 */
union {
struct sock *sk;
int ip_defrag_offset;
};
struct net_device *dev;
/* “可滑动视窗”指针 */
unsigned char *head;
unsigned char *data;
unsigned char *tail;
unsigned char *end;
/* 长度信息 */
unsigned int len;
unsigned int data_len;
unsigned int mac_len;
unsigned int hdr_len;
/* 各层头部偏移指针 */
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
/* 各协议层私有数据区(控制缓冲区) */
char cb[48];
/* 引用计数与内存信息 */
refcount_t users;
unsigned int truesize;
/* 校验和与硬件卸载 */
__u32 ip_summed;
__u32 csum;
// ... 其他重要字段
};
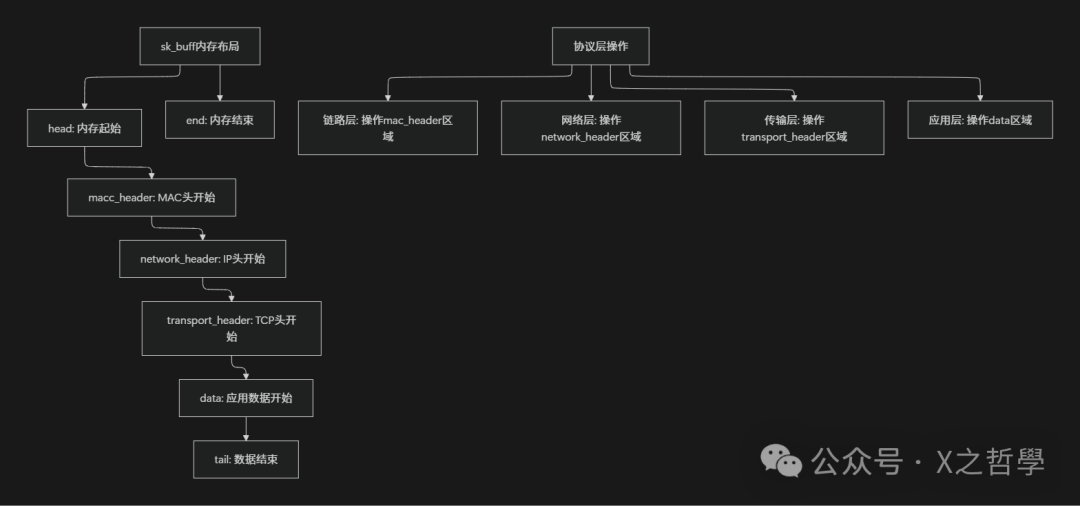
各层头部指针(如transport_header)记录了对应协议头在data区域内的偏移量。内核提供了skb_push()(在data前添加头部,data上移)和skb_pull()(从data剥离头部,data下移)等函数来动态调整这个“视窗”,以适应TCP/IP协议栈层层封装与解封装的过程。
生命周期全景
一个sk_buff的生命周期清晰反映了数据包在内核中的旅程。
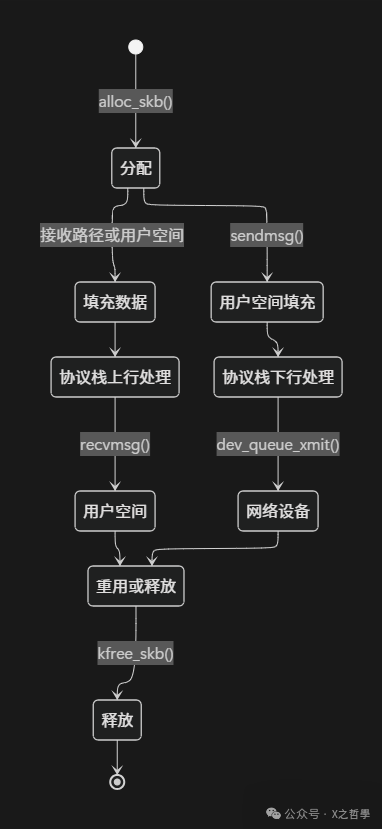
阶段一:创建与分配
通常由网卡驱动(接收路径)或套接字层(发送路径)调用分配函数。
// 典型分配流程
struct sk_buff *skb = alloc_skb(total_size, GFP_ATOMIC);
if (skb) {
skb_reserve(skb, headroom); // 预留链路层头部空间
skb_put(skb, data_len); // 扩展data/tail指针,准备数据区
// ... 填充数据
}
分配后,内存布局如下:
head end
| |
v v
+--------------------------------------------+
| headroom | data area | tailroom|
+--------------------------------------------+
^ ^
| |
data tail
阶段二与三:协议栈处理
- 接收路径(上行):数据从网卡进入,
data指针初始指向链路层头部。每向上经过一层(如IP层、TCP层),就调用skb_pull()剥离该层头部,data指针下移,并将当前层的头部偏移记录在network_header、transport_header等字段中。
- 发送路径(下行):过程相反。应用数据通过
skb_put()放入,在经过每一层时调用skb_push()在data前添加协议头,data指针上移。
阶段四:释放与重用
sk_buff采用引用计数管理生命周期。
skb_get(skb); // 增加引用计数 (users++)
kfree_skb(skb); // 减少引用计数,当 users 为 0 时真正释放内存
// skb_clone 复制描述符,共享底层数据缓冲区
struct sk_buff *new_skb = skb_clone(skb, GFP_ATOMIC);
高级特性与优化机制
1. 非线性缓冲区 (Non-linear SKB)
为处理大块数据(如TCP大报文分片)而设计,避免内存拷贝。数据可以分散在多个page页面中,通过skb_shared_info结构管理。
struct skb_shared_info {
unsigned short nr_frags; // 页面分片数量
skb_frag_t frags[MAX_SKB_FRAGS]; // 分片数组
};
typedef struct skb_frag_struct {
struct page *page; // 指向物理页面
__u32 page_offset;
__u32 size;
} skb_frag_t;
2. 控制缓冲区 (Control Buffer)
cb[48]字节区域是各协议层的“私有储物柜”,用于存储仅在本层有效的控制信息,例如TCP层的序列号、确认号等。这避免了为这些信息单独分配内存,提升了访问效率。
3. 校验和卸载
现代网卡支持硬件计算校验和。内核通过设置skb->ip_summed标志(如CHECKSUM_PARTIAL)并告知网卡校验和起始位置(csum_start)与偏移(csum_offset),将计算任务卸载到硬件,大幅降低CPU负载。
实战:构建一个TCP SYN数据包
以下代码展示了如何手动构建一个完整的TCP SYN数据包skb:
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/tcp.h>
struct sk_buff *build_tcp_syn_skb(struct net_device *dev,
__be32 saddr, __be32 daddr,
__be16 sport, __be16 dport) {
struct sk_buff *skb;
struct iphdr *iph;
struct tcphdr *tcph;
int hdr_len = sizeof(struct iphdr) + sizeof(struct tcphdr);
// 1. 分配skb,并预留链路层头空间
skb = alloc_skb(LL_RESERVED_SPACE(dev) + hdr_len, GFP_ATOMIC);
skb_reserve(skb, LL_RESERVED_SPACE(dev));
// 2. 构建IP头部
skb_put(skb, sizeof(struct iphdr));
iph = ip_hdr(skb);
iph->version = 4;
iph->ihl = 5;
iph->tot_len = htons(hdr_len);
iph->ttl = 64;
iph->protocol = IPPROTO_TCP;
iph->saddr = saddr;
iph->daddr = daddr;
// ... 设置其他IP字段
iph->check = 0; // 先置零,后计算
// 3. 构建TCP头部
skb_put(skb, sizeof(struct tcphdr));
tcph = tcp_hdr(skb);
tcph->source = sport;
tcph->dest = dport;
tcph->seq = htonl(123456);
tcph->syn = 1;
tcph->window = htons(65535);
tcph->check = 0; // 临时置零
// 4. 设置协议层指针与设备
skb->protocol = htons(ETH_P_IP);
skb->dev = dev;
skb_reset_network_header(skb); // 设置L3头偏移
skb_set_transport_header(skb, sizeof(struct iphdr)); // 设置L4头偏移
// 5. 计算校验和
iph->check = ip_fast_csum((unsigned char *)iph, iph->ihl);
// TCP校验和通常由后续流程或网卡硬件计算
return skb;
}
调试与性能调优
调试工具
性能优化实践
- SKB池化:在已知会频繁分配/释放的场景(如高频转发的网关),预分配并复用
sk_buff对象池,避免直接内存分配器的开销。
- 智能预留头空间:根据数据包可能经过的协议栈路径(如是否要经过VLAN、隧道封装),一次性预留足够的头部空间,避免中途因空间不足而重新分配和拷贝。
- 批量操作:在驱动层或特定转发路径,尝试批量分配和处理多个
skb,以提高缓存命中率和效率。
设计思想总结与对比
sk_buff是Linux内核网络栈高度成功的抽象。其核心优势在于:
- 统一的抽象层:用一个结构贯穿整个网络栈,极大简化了各层间的交互。
- 极致的性能设计:从指针操作实现零拷贝,到支持非线性缓冲区整合大页内存,再到完善的硬件卸载接口。
- 优雅的内存管理:引用计数、控制缓冲区、分片机制等,在功能、性能与内存效率间取得了平衡。
对比经典的BSD mbuf,sk_buff更倾向于“单一缓冲区+分片描述”模型,而mbuf是纯粹的链式结构。sk_buff通过指针调整头部的方式,通常比mbuf添加新节点的方式在本地操作上更高效。
演进与未来
新技术正在影响sk_buff的传统角色:
- eBPF:允许用户态程序安全地注入代码到内核,直接读取和修改
sk_buff中的数据与元数据,实现灵活的流量控制、监控和策略。
- XDP (eXpress Data Path):在网卡驱动层最早的点处理数据包,性能极高(纳秒级)。在XDP路径中,数据包甚至可以被处理或丢弃,而无需分配完整的
sk_buff对象,这对DDoS防御等场景至关重要。
总结
sk_buff不仅是Linux网络的数据载体,更是其高效网络能力的基石。它的设计处处体现着对性能的苛求与对复杂性的精妙管理。无论是进行内核网络开发、性能调优还是网络问题排查,深入理解sk_buff都是不可或缺的一课。它如同一个设计精良的标准化集装箱系统,使得Linux内核这座“超级物流中心”能够高效、可靠地处理全球互联网的海量数据洪流。
 发表于 2025-12-20 01:55:03
|
查看: 263|
回复: 0
发表于 2025-12-20 01:55:03
|
查看: 263|
回复: 0
