
越来越相信,互联网从被发明开始,其实从来没有被真正地分成过所谓 Web1、Web2 或 Web3 的不同版本号。一直只有一个互联网,一张网,只是它在不断生长、形变、进化,它会越来越像一个可以新陈代谢能量和信息的“生命之网”( a living web )。
互联网之所以重要,并不只是因为它连接了人,而是因为它持续地承载、暴露、修正并扩展人类的文明本身。未来出现在互联网上的,将不只是文本和图像,而是更复杂的人类经验、心灵感受、行动轨迹、环境信号,以及对自然世界动态现实的长期记录。互联网还会越来越“去中心化”和“去人类中心主义”,它映射的不只是人类社会结构,也会包括生态、能量、物质与时间的结构,它会映射出比“人工智能”更大的“自然智能”。
同时,我也越来越相信,培育“模型”的人本身,对知识、“现实”与人/人文的品味,才是真正的差异。模型并不是中性的,它们继承的是我们选择看见什么、关怀什么、忽略什么,以及我们愿意如何理解世界,和如何定义“我们”。这种品味,决定了模型会走向压缩、收敛和控制,还是走向探索、多样与生态性。
所以从技术结构和哲学价值观上,我不相信智能的终点是单一的“超级大脑或超级个体”。正如生物多样性不是自然的副产品,而是其生存前提,智能的多样性同样重要。不同的人,应该能够接触、帮助塑造,甚至自己创造不同的模型,不同的智能形式应该并存、变异、分化、相互启发,而不是被压缩成唯一的最优解。如果你相信世界和智慧都是展开的,你会相信多样性和行星级的连接。
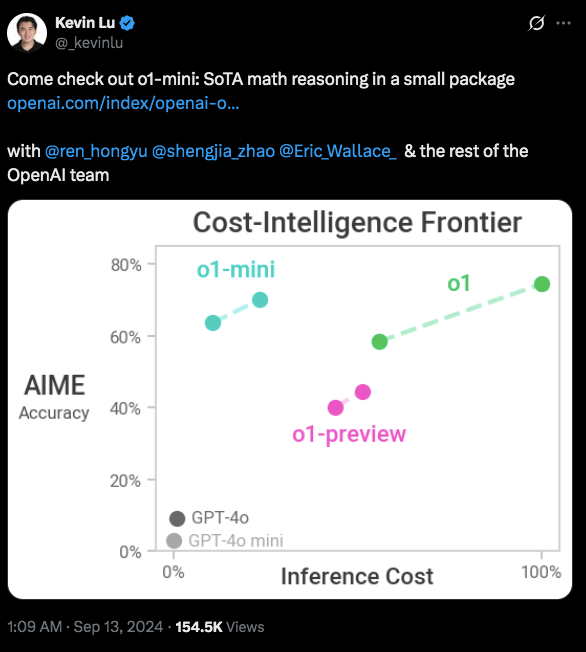
这篇文章来自人工智能研究者 Kevin Lu 的个人博客,他在文章结尾提出的问题非常重要:当前的人工智能还把自己限制在“预测下一个词的范式”和“上一代互联网的环境”中。
“总之,我认为我们距离发现强化学习在系统中真正优雅且高效的对偶形式( dual ) — 如同互联网之于下一个 token 预测那般,仍然遥远。如今我们的强化学习智能体究竟被隐藏了哪些关键信息?但我希望你能怀抱这样的梦想:终有一天,我们将找到方法构建这样的系统,而这将成为真正的突破。”
我猜测这会是一种穿越虚实、人和机器共同探索未知知识的“生态环境”,看起来像是一种游戏( play ),并且它要调动起来更多人/生命贡献自己的智慧,体验和经历,并获得福祉和权益 ( equity )。

尽管人工智能的进步常归功于里程碑式的论文 — 如 Transformer、RNN或扩散模型 — 但这忽略了人工智能的根本瓶颈:数据。然而,拥有优质数据究竟意味着什么?
若我们真正希望推动人工智能发展,与其研究深度学习优化,不如研究互联网。互联网才是真正解锁人工智能模型规模化能力的技术。

受架构创新快速进展( 5年间从 AlexNet 演进至 Transformer )的启发,许多研究者开始寻求更优的架构先验。人们不断押注能否设计出比 Transformer模型 更出色的架构。事实上,自 Transformer 问世以来,确实已有更优架构诞生 — 但为何自 GPT-4 之后,我们很难“感受”到实质性的提升?
范式的转变
算力受限时期:曾几何时,方法效能随算力增长而提升,更高效的算法往往意味着更好。彼时的核心在于尽可能高效地将数据压缩进模型,这类方法不仅取得了更优结果,其表现似乎还能随着规模扩大持续提升。
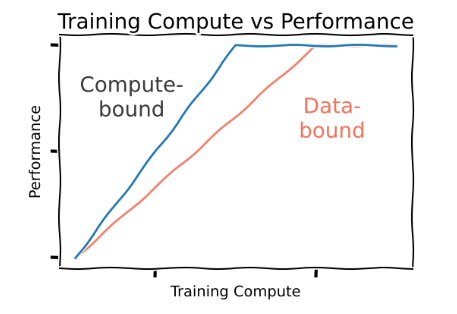
数据受限时期:事实上,研究并非无用武之地。自 Transformer 问世以来,学界已提出更优方法 — 如SSMs 和 Mamba 等 — 但我们并不完全将其视为“免费增益”:在给定训练算力的条件下,训练 Transformer 往往仍能获得更好表现。
但数据瓶颈时代带来了解放:既然所有方法最终表现趋于一致,我们应选择推理阶段最优的方案 — 很可能是某些次二次复杂度注意力变体。这些方法或许很快会重回舞台中央。
研究者应该在做什么?
现在想象一下:我们不再“仅仅”关心推理( 那是“产品”问题 ),而是关心渐近性能( “AGI” )。
显然,继续优化架构已非正解。
纠结如何截断Q函数轨迹更是方向错误。
人工构建新数据集无法规模化。
你提出的新时序高斯探索方法很可能同样难以扩展。
研究社区中的很大一部分人已经收敛到一个原则:我们应该研究新的数据消费方式。目前有两个主流范式:
(1)下一词预测
(2)强化学习(RL)
( 显然,我们在新的范式上并没有取得太大的进展 🙂 )
AI 所做的一切,都是在消费数据
这些里程碑式的工作,提供了新的数据消费路径:
- AlexNet 通过下一词预测消费ImageNet数据
- GPT-2 通过下一词预测消费互联网文本
- “原生多模态”模型 通过下一词预测消费互联网图像与音频
- ChatGPT 通过强化学习消费对话场景中的随机人类偏好反馈
- Deepseek R1 通过强化学习消费狭窄领域内的确定性可验证反馈
就下一词预测而言,互联网是终极解决方案:它为这类序列化方法提供了海量时序关联数据以供学习。
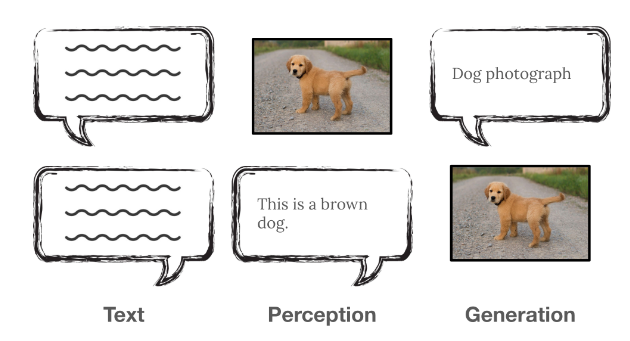
互联网充满以结构化 HTML 形式存在的序列数据,天然适配下一词预测。根据不同的序列编排方式,可以恢复出多种有用的能力。
这并非巧合:这种序列数据是下一词预测的完美养料;互联网与下一词预测技术本就相辅相成。
行星级数据规模
亚历克·拉德福德(Alec Radford )在 2020 年发表过一次颇具预见性的演讲,他指出:尽管当时涌现了各种新方法,但与精心整理更多数据相比,这些方法都显得无足轻重。我们不再寄希望于通过“魔法般”的优化方法实现泛化,转而信奉一个简单原则:如果模型从未接触过某些信息,它自然无法知晓这些知识。
与其通过构建庞大的监督数据集,去手工指定模型应该预测什么……
不如去思考:如何从世界上一切“已经存在的东西”中学习,并对它们进行预测。
你可以这样理解:每当我们构建一个数据集,其实就是把世界上其他一切事物的重要性设为 0,而把数据集中包含的一切事物的重要性设为 1。
可怜的模型啊!它们知道的如此之少,却仍然有如此之多的世界知识,被隐藏在它们之外。
在 GPT-2 之后,世界开始注意到 OpenAI,而时间也证明了它的影响力。
- 低数据:一个显而易见的反事实是:在低数据环境下,Transformer 根本毫无价值,我们认为它们的“架构先验”不如卷积网络或循环网络。因此,在这种情况下,Transformer 的表现应该比卷积网络还差。
- 书籍:一个不那么极端的情况是:如果没有互联网,我们可能会用书籍或教材进行预训练。在所有的人类数据中,通常我们会认为教材代表了人类智慧的巅峰,其作者经过了长期教育,每一个字都倾注了深思熟虑。这本质上体现了“高质量数据应优于海量数据”的理念。
- 教科书:phi 模型在这里展示了小模型中非常出色的性能,但仍然需要 GPT-4( 在互联网数据上预训练 )来进行数据过滤并生成合成数据。和学术界类似,用 SimpleQA 衡量时,phi 模型在世界知识方面也明显弱于同等规模、基于互联网训练的模型。
确实,phi 模型相当不错,但我们尚未看到它们能够达到基于互联网训练模型的同等渐近性能;而且很明显,教材缺乏大量现实世界知识和多语言知识(不过在算力受限的场景下,它们看起来非常强)。
数据的分类
我认为这也与我们之前对强化学习数据的分类存在一个有趣的联系。教科书更像是“可验证奖励”:其中的陈述几乎总是正确的。相比之下,书籍,尤其是创意写作类,往往包含更多关于人类偏好的信息,从而为学生模型注入更强的多样性。
同样地,我们可能不会信任 o3 或 Sonnet 3.7 来替我们写作;我们也可能认为,一个只在高质量数据上训练的模型,缺乏某种创作灵气。直接承接上文,phi 模型在产品—市场匹配上并不理想:当你仅仅需要知识时,更倾向于使用大模型;当你想要一个本地的角色扮演写作模型时,人们通常也不会首选 phi。

互联网之美
归根结底,书籍和教科书只是对互联网上可获得数据的压缩形式,哪怕这种压缩背后有强大的智慧在进行。再往上一层看,互联网是一个极其多样化的模型监督来源,也是人类整体的一个表征。
乍一看,许多研究者可能会觉得,为了在研究上取得突破而转向做产品这件事有些奇怪(甚至是一种干扰)。但我认为这其实非常自然:如果我们关心的是 AGI 能够为人类带来有益的结果,而不是只在真空中表现出“智能”,那么去思考 AGI 以何种“形态”( 产品形态 )存在就是合理的 — 而且我认为,研究( 预训练 )与产品( 互联网 )之间的协同设计本身就非常美。
去中心化与多样性
互联网以一种去中心化的方式运作,任何人都可以以相对民主的方式向其中添加知识:不存在一个唯一的“真理中心”。互联网上呈现着海量丰富的观点、文化模因以及小众语言的表达 — 当我们用大型语言模型对这些数据进行预训练时,最终获得的智能体将能理解极其广阔的知识领域。
这意味着产品( 即互联网 )的守护者在通用人工智能设计中扮演着关键角色!如果我们削弱互联网的多样性,模型在强化学习中可调用的信息熵将大幅衰减;如果我们彻底清除某些数据,等同在通用人工智能中抹去整个亚文化的存在痕迹。
对齐
一项极具启发性的研究表明,要获得对齐的模型,必须在预训练中同时使用对齐与未对齐数据。因为预训练过程会学习区分二者的线性可分方向。若剔除所有未对齐数据,模型将无法深刻理解什么是未对齐行为及其危害性。
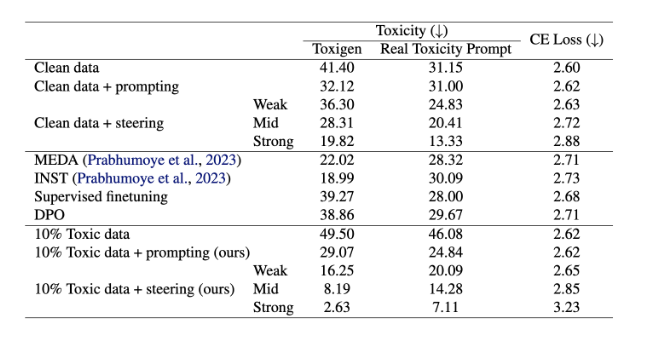
上图为毒性消除实验结果:数值越高( 基于“Toxigen”指标 )代表毒性越强。实验显示,使用10%有毒数据预训练的模型( 10%有毒数据+导向技术 ) 的毒性表现,反而低于用0%有毒数据预训练的模型( 纯净数据+导向技术 steering )。
尤其值得注意的是,上述“有毒”数据来自 4chan — 一个以匿名、几乎不受限制的讨论方式而闻名、同时也充斥着大量有毒内容的网络论坛。尽管这只是一个产品形态与研究之间存在深度耦合的具体案例( 我们需要这种不受限制的讨论,才能训练出真正对齐的研究模型 ),但你其实可以想到更多类似的情形:互联网在设计层面的决策,会在模型训练完成之后,深刻地影响最终的结果。
互联网作为技能进阶课程
互联网的另一个重要属性在于:它包含了难度层级极其丰富的知识谱系。从面向小学生的教育内容,到大学层面的课程,再到前沿科学研究。如果你只用前沿科学论文来训练模型,可以想见其中隐含了大量默认但未明言的背景知识,而模型仅靠阅读论文本身,很可能学不到这些“未写下来的知识”。
这一点之所以重要,是因为可以设想这样一个过程:你拥有一个数据集,用它训练模型,模型学会了这个数据集的内容。然后呢?接下来你可以继续人工策划下一个数据集 —OpenAI最初以每小时2美元雇用知识工作者标注数据,随后提升至博士级工作者,如今其前沿模型已能完成价值约万美元量级的软件工程任务。
但人工构建数据阶梯费时费力:我们曾手动构建 CIFAR、ImageNet 到更大规模 ImageNet 等图像数据集,或是从小学数学、美国数学邀请赛到前沿数学问题集……然而,由于互联网在行星尺度上服务全世界,它自发地包含了一个难度平滑递进的任务课程体系。
强化学习中的课程
当我们迈向强化学习时,课程的重要性变得更加突出:由于奖励是稀疏的,模型必须先理解完成任务所需的子技能,才能哪怕一次获得非零奖励。一旦模型偶然发现了非零奖励,它就可以回溯分析哪些行为是成功的,并尝试复现这些行为 — 强化学习在稀疏奖励下也能展现出惊人的学习能力。
但天下没有免费的午餐:模型仍需平滑的课程梯度才能有效学习。预训练因目标函数密集而容错性更高;为弥补奖励稀疏性,强化学习必须依赖密集的课程设计。

自我博弈机制同样会形成一种课程体系( 在象棋或星际争霸等特定领域内 )。正如强化学习智能体或游戏玩家渴望获胜( 从而探索新策略 ),互联网用户也倾向于贡献新观点( 有时通过获赞或广告收入获得激励 ),这种内在驱动力持续拓展知识边界,并自然形成渐进式学习路径。
苦涩的启示
因此我们必须认识到:人们是自发地使用互联网的,而所有对模型训练有益的特性,都源于互联网作为产品的实际交互过程中涌现的结果。如果我们依赖人工构建 数据集,将不可避免地面临“研究者预设的有用能力”与“用户实际需求的能力”之间的割裂。有用技能的筛选权不应掌握在研究者手中 —互联网用户自会告诉我们答案。
人们真正愿意使用互联网的一个原因是,这项技术对每个用户来说足够廉价,因此能够被广泛采用。如果互联网被高额订阅费所限制,用户就不会大规模地贡献自己的数据。
我认为在关于模型规模化的讨论中,这一点常被忽视:互联网正是实现学习与搜索( 即数据与算力 )规模化的核心机制。若能发现这类简单理念并加以规模化,必将取得突破性成果。
通用人工智能是人类文明的数字映射
因此我认为,除了数学理论之外,我们完全有空间从多维度探讨如何构建通用人工智能:互联网( 及其延伸产物 — 通用人工智能 )可以从哲学、社会科学等多元视角审视。众所周知,大语言模型会固化其训练数据中的偏见。如果用 1900 年代的数据训练模型,它将永久封存那个时代的语言结构与认知局限。我们甚至可以实时观测人类知识与文化的演进轨迹。
通过维基百科条目和 GitHub 代码库,我们可以看到人类智能的协作特性。我们可以模拟合作行为以及人类追求更完美结果的欲望。在在线论坛中,我们可以看到辩论与多样性,人们贡献新颖想法。通过社交媒体,AI 学会了什么是人类认为重要到值得与亲友分享的内容。它观察人类的失误、修正过程,以及持续追求真理的努力。
正如模型 Claude 所言:
人工智能学习的并非我们光鲜的表象,而是我们完整的容颜 — 包括争论、困惑,以及集体意义构建的混乱过程。
核心启示
准确来说,互联网对模型训练的价值体现在:
- 多样性:蕴含模型所需的海量知识
- 它形成了模型学习新技能的自然课程体系
- 用户自驱性:人们愿意使用它,持续贡献数据( 实现产品市场匹配 )
- 经济可行性:技术成本足够低廉,吸引数十亿人使用
互联网是下一 token 预测的对偶存在
强化学习显然是未来方向( 也是实现超人类智能的“必要条件” )。但如前所述,我们缺乏可供强化学习消费的通用数据源。获取高质量奖励信号始终是核心难题:我们必须要么争夺稀缺的高质量对话数据,要么在有限的、可验证的任务中艰难摸索。事实表明,基于他人对话偏好训练出的模型未必符合我的喜好,而在可验证数据上训练的模型,也未必能更好地完成我关心的、那些不可验证的任务。
互联网曾是监督式下一词预测的完美搭档:甚至可以断言,正是以互联网为基石,研究者们才必然地汇聚到下一词预测这条路上。我们可以把互联网看作孕育人工智能的“原始汤”。
因此,我可以说:互联网是下一个 token 预测的对偶存在。
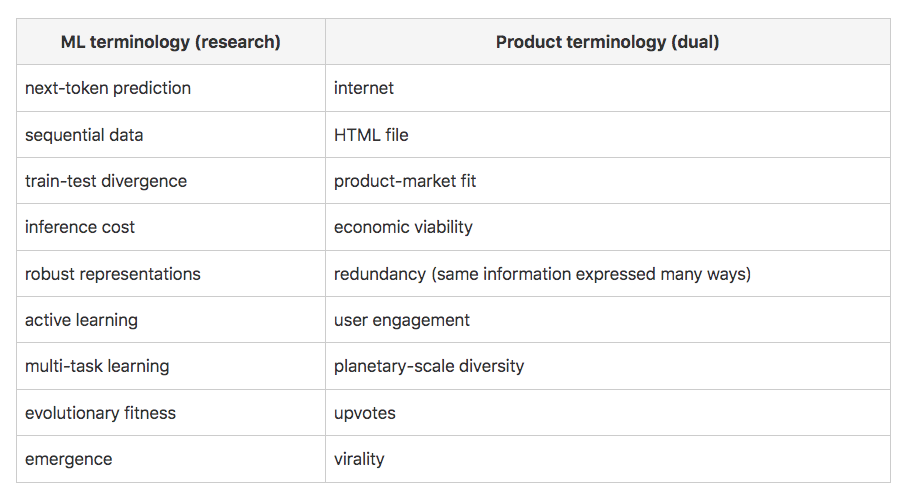
| 机器学习术语(研究领域) |
产品术语(对偶概念) |
| 下一词预测 |
互联网 |
| 序列数据 |
HTML文件 |
| 训练-测试分布差异 |
产品-市场匹配 |
| 推理成本 |
经济可行性 |
| 鲁棒表征 |
冗余性(同一信息以多种方式表达) |
| 主动学习 |
用户参与度 |
| 多任务学习 |
行星级多样性 |
| 进化适应度 |
点赞/支持数 |
| 涌现现象 |
病毒式传播 |
如前所述,尽管研究不断推进,我们目前仍只有两种主要的学习范式。因此,提出新的“产品”构想可能比提出新的核心范式更为可行。这就引出了一个关键问题:强化学习的“对偶存在”是什么?
用强化学习优化困惑度
首先,我注意到已有一些工作尝试将强化学习应用于下一个 token 预测目标,通过困惑度作为奖励信号。这一方向的目标是将强化学习的优势与互联网的多样性相结合,起到桥梁作用。
然而,我认为这种方法有些误导,因为强化学习范式的美妙之处在于它允许我们消费新的数据源( 奖励 ),而不是用来为旧数据建模设定新目标。例如,GAN 曾经是一个新颖且强大的目标,用于从固定数据中获取更多价值,但最终被扩散模型超越,然后又回到下一个 token 预测上。
真正激动人心的方向,应是寻找( 或创造 )可供强化学习消费的新数据源!
强化学习的对偶是什么?
目前存在几种不同的思路,每种都有其局限。这些思路并非“纯粹”的研究构想,而是围绕强化学习构建产品。以下是我的初步推想:
我们需要具备以下特性:多样性、自然课程体系、产品市场匹配、经济可行性。
- 传统奖励:人类偏好反馈:如上所述,这类数据收集困难、个体差异大、噪声极高。如 YouTube 或 TikTok 所示,这类机制往往优化“用户参与度”而非智能水平;“提升参与度能否直接提升智能”仍有待验证。
- 可验证奖励:这类数据局限于狭窄领域,且常难以泛化到其他领域。
应用场景
- 机器人技术:很多人梦想在未来十年构建大规模机器人数据采集流水线和飞轮,从而将智能引入现实世界,这极具吸引力。但正如大量机器人初创公司高失败率所示,这显然很具挑战性。强化学习在这方面面临诸多困难:奖励难以标注、机器人形态多样、存在模拟到现实的差距、环境非稳态等。此外,如自动驾驶汽车所示,这类方案也不一定经济可行。
- 推荐系统:可视为人类偏好机制的延伸,但更具针对性。我们可以使用强化学习为用户推荐产品,并通过用户是否使用或购买来获得反馈。这种方式的局限在于领域较为狭窄;若扩展到更通用的场景,则可能面临奖励信号噪声更大更不稳定的问题。
- AI 研究:我们也可以用强化学习来执行“AI 研究”,训练模型去训练其他模型,以最大化基准测试表现。理论上,这并非狭窄领域,但在实际操作中往往仍有局限。
- 交易:在交易中,我们有一个有趣且大体上难以作弊的指标,但实际操作中你很可能会亏很多钱 —你的强化学习智能体很可能学会“不参与游戏”。
- 计算机操作数据:强化学习本质上是在教模型一个过程,因此我们可以训练模型在计算机上执行动作,正如 Adept 曾尝试的那样。尤其是结合人类数据,可以利用下一个 token 预测与强化学习的组合来实现目标。但同样,这并不容易,而且人们通常不会同意自己的数据被记录。
- 编码:基于历史测试用例的强化学习是可验证的,但生成测试用例则难以验证。
总结思考:假设我们暂时牺牲多样性。你可以在特定产品场景中使用强化学习。这种做法可能有效的理由很多 —但挑战在于如何将其转化为具有多样性的奖励信号,并最终实现突破性的范式变革。
总之,我认为我们距离发现强化学习在系统中真正优雅且高效的对偶形式— 如同互联网之于下一个 token 预测那般,仍然遥远。
如今,我们的强化学习智能体究竟被隐藏了哪些关键信息?
但我希望你能怀抱这样的梦想:终有一天,我们将找到方法构建这样的系统,而这将成为真正的突破。
 发表于 2025-12-20 03:58:57
|
查看: 184|
回复: 0
发表于 2025-12-20 03:58:57
|
查看: 184|
回复: 0
