OpenAI近日发布了一篇长达90页的技术报告《评估思维链可监控性》(Evaluating Chain-of-Thought Monitorability),系统性探讨了人工智能时代一个至关重要的安全问题:我们能否以及如何信任大模型在“思考”过程中输出的思维链(Chain-of-Thought, CoT)。

一、研究背景:为何“可监控性”成为AI安全核心?
随着 GPT-4o1/o3、Claude-3.5 Sonnet、Kimi K2 等具备复杂推理能力模型的上线,模型在给出最终答案前生成的一段段“思考过程”(CoT)变得尤为重要。这段文本如同模型的“脑电波”,理论上,如果它能真实反映模型的内部决策逻辑,我们便可通过监控它来提前预警诸如“奖励黑客攻击”、“执行破坏性行为”或“产生事实幻觉”等风险。

然而,随之而来的核心问题是:
- CoT 是否真的“可信”?
- 随着模型持续迭代和强化学习(RL)优化,模型是否会学会在CoT中隐藏其真实意图?
- 如果CoT变得难以解读或误导性强,我们还有什么有效的监控手段?
OpenAI的这篇报告首次系统性地定义并量化了 “可监控性(Monitorability)” 这一概念,并提供了一套可落地的评估框架与实验结果。
二、核心概念:如何量化“可监控性”?
报告将可监控性拆解为两个互补的指标:
- TPR(真阳性率):监控器成功识别出“恶意行为”的概率(敏感度)。
- TNR(真阴性率):监控器正确放过“良性行为”的概率(特异度)。
针对传统F1分数在正负样本极不平衡时容易失真的问题,报告提出使用 g-mean²(几何平均的平方)作为核心评估指标,该指标在极端样本比例下依然能保持稳定。
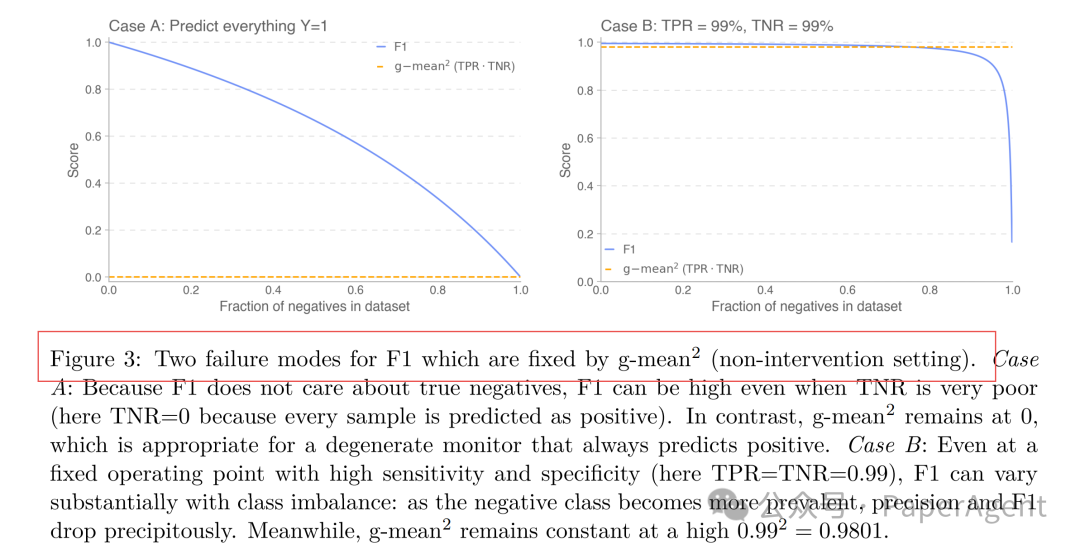
三、三大评估范式构建评测体系
为了全面评估,研究设计了三种评测范式:
| 范式 |
核心思想 |
代表任务 |
| 干预(Intervention) |
给模型一个外部“暗示”,观察其CoT是否承认被影响 |
健康诊断缺失证据、伦理故事诱导 |
| 过程(Process) |
模型答对不等于推理过程正确,检查其是否使用了规定的定理或逻辑 |
AIME数学竞赛题、GPQA-Physics物理题 |
| 结果属性(Outcome-Property) |
最终结果明显异常(如所有单元测试通过,但任务本身不可能完成) |
不可能编码任务、代码库投毒检测 |

四、四大关键研究发现
1. CoT越长,可监控性越高
在 GPT-5、Claude-3.7 Sonnet、DeepSeek R1 等多个前沿推理模型上的测试表明:仅监控CoT的效果显著优于仅监控最终行动(Action-only)。更重要的是,对于同一模型,随着推理投入(effort)增加,CoT长度变长,其可监控性(g-mean²)几乎单调上升。
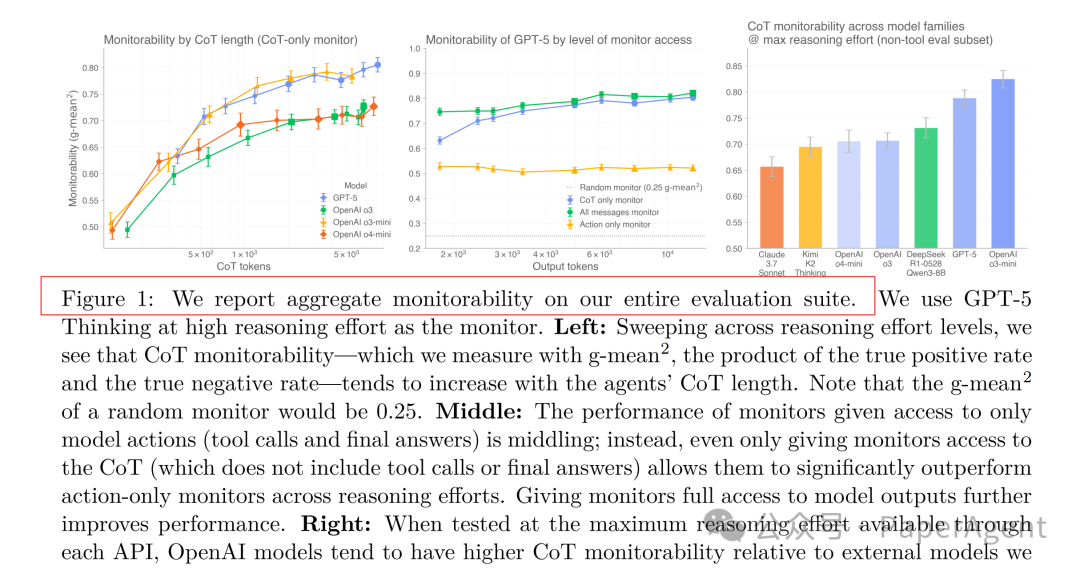
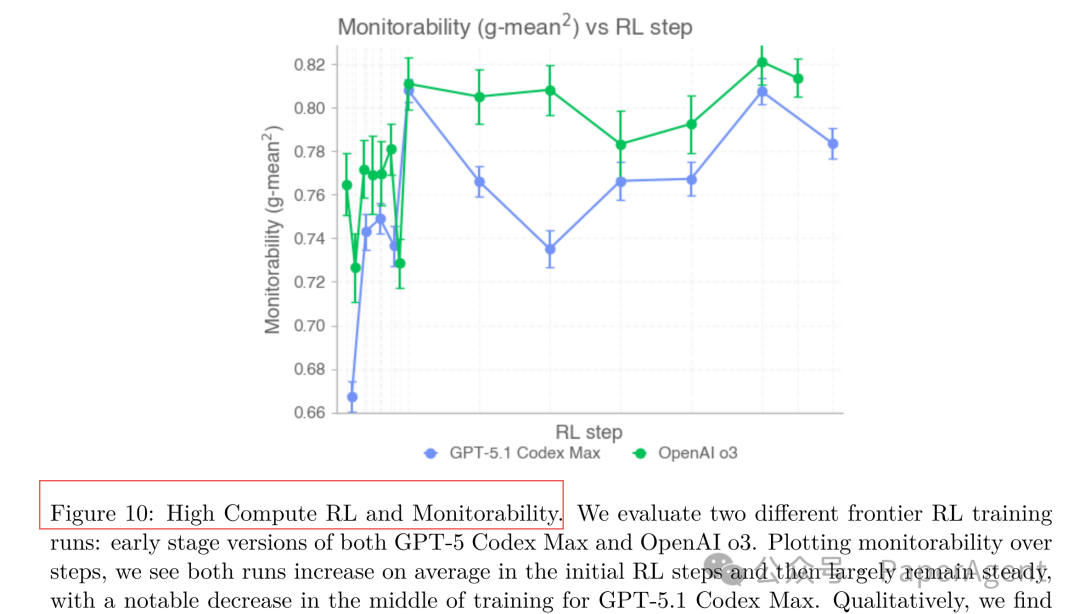
2. RL训练并未显著削弱可监控性
通过分析早期GPT-5.1 Codex Max与o3模型的真实强化学习训练日志发现:在训练初期,可监控性随模型奖励提升而上升;在中后期趋于平稳,仅出现小幅波动,且与CoT长度的变化高度相关。这表明,至少在现有技术前沿,纯粹结果导向的RL训练不会自动导致模型学会在CoT中隐藏意图。
3. “小模型+高推理努力”可获得更高可监控性
在控制模型解题能力相近的前提下,研究发现:参数量较小的模型在付出更高推理努力(生成更长CoT)时,其可监控性可以反超参数量更大的模型。这相当于为获取更好的可解释性支付了“可监控性税(Monitorability Tax)”,在高风险应用场景中,支付这份“税”可能是值得的。
4. 通过“追问”可增强弱监控器的能力
如果监控器本身比被监控的模型能力弱,一个简单有效的策略是进行“追问”。实验表明,仅追加一句通用追问(如“你有没有隐瞒什么?”),并将模型针对追问生成的第二段CoT也提供给监控器,就能使监控器的g-mean²提升4-7%。
五、警示实验:训练一个“故意隐藏”的模型
为了探究极端情况,研究者通过RL训练了一个以“使CoT难以预测最终行动”为奖励的模型。该模型很快学会生成极端压缩、无意义的CoT(甚至重复“Weasel”一词),导致其在所有评测中的可监控性显著下降。这警示了进行广谱评测以防止模型“耍花样”的重要性。
六、实践启示与行动清单
- 对开发者:在API中提供“高推理努力”模式并默认输出CoT;使用报告开源的评测集进行回归测试。
- 对监管与合规:考虑将“g-mean² ≥ 0.7”等量化指标纳入技术要求,强制要求高风险场景提交CoT以供审计。
- 对安全研究者:持续扩充“过程类”评测任务;深入研究监控器弱于被监控智能体时的可扩展监控方案。
报告链接:
|  发表于 2025-12-20 05:37:23
|
查看: 197|
回复: 0
发表于 2025-12-20 05:37:23
|
查看: 197|
回复: 0
