在数据库应用中,SQL执行效率是决定系统整体性能的关键因素。应用程序与数据库的交互通常涉及大量结构相似或重复的查询。为了有效应对这一挑战,Prepared Statement(预编译语句)机制被广泛应用。本文将首先介绍SQL在数据库中的通用执行流程,然后重点解析Oracle、DB2及MySQL这三大传统数据库中Prepare处理机制的异同及其关键参数控制。
1、数据库中SQL执行的核心过程
一条SQL语句在数据库内的执行,通常需要经历解析、优化与执行三大阶段。以查询语句为例,其完整生命周期包含以下环节:
- 查询解析:将文本格式的SQL语句转换为数据库内部可识别的结构。此过程包括词法分析、语法分析和语义分析。
- 查询优化:基于规则(RBO)和代价(CBO)对查询逻辑进行优化,并生成最优的执行计划。
- 查询执行:依据生成的执行计划,访问存储引擎获取数据。
- 结果返回:将处理后的数据返回给客户端。
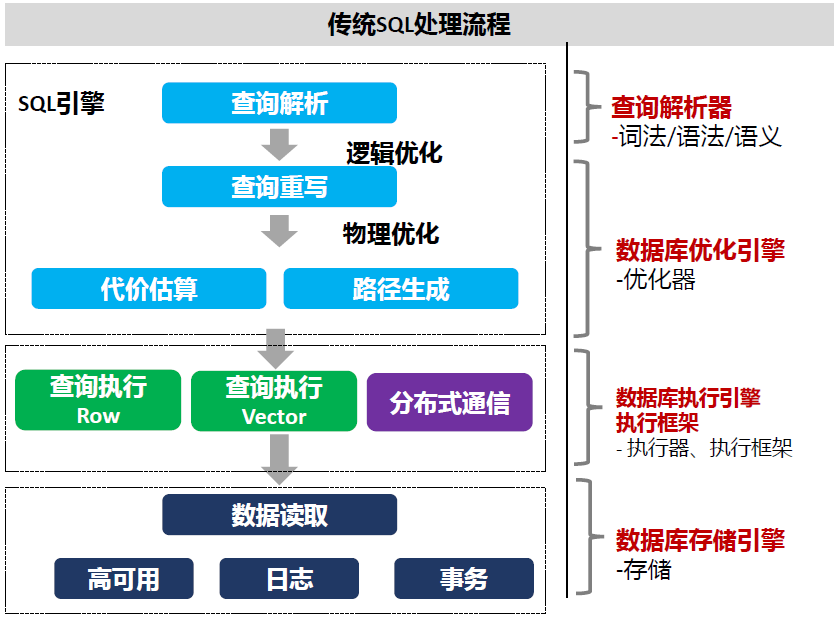
其中,SQL解析是一个将文本“翻译”为内核逻辑的关键步骤,具体包含:
- 词法解析:拆分SQL字符串,识别关键词、标识符、常量等。
- 语法解析:检查单词序列是否符合SQL语法规范。
- 语义分析:在语法正确的基础上,进行上下文相关的审查,如校验表名、列名是否存在,用户是否有操作权限,并消除语义二义性。
显而易见,如果每条SQL语句都需重复经历完整的解析和优化过程,将产生巨大的开销。为此,Prepare(预编译)机制被引入以提升效率。
1.1 Prepare过程的核心思想
Prepare操作的核心在于将SQL的解析/优化与执行相分离。它预先对SQL语句模板进行处理,生成一个中间形式或执行计划,后续只需传入变化的参数即可快速执行。该过程通常包括:
- 语法与语义解析:验证SQL语句的正确性及对象权限。
- 查询优化:为SQL模板生成一个或多个候选执行路径。
- 生成执行计划:优化器基于统计信息选择最优路径,生成具体的执行计划。
预编译完成后,数据库会返回一个语句句柄。应用程序后续通过该句柄,仅需绑定不同的参数值即可反复执行,从而跳过了重复的解析和优化开销,极大提升了性能。此外,Prepare机制能自动对输入参数进行转义,是防范SQL注入攻击的有效手段。
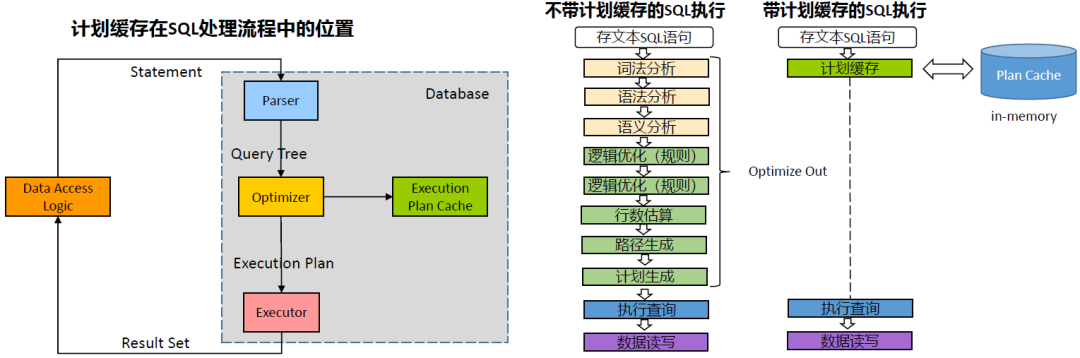
1.2 执行计划缓存
执行计划缓存是构建在Prepare机制之上的进一步优化。当一条SQL首次经过硬解析生成执行计划后,该计划会被存入特定的内存区域(即执行计划缓存)。当后续接收到相同SQL时,数据库会尝试从缓存中直接复用现有计划,这个过程称为“软解析”,避免了昂贵的硬解析成本。
2、主流数据库的Prepare实现机制对比
2.1 Oracle数据库的实现机制
Oracle通过共享池(Shared Pool) 中的库缓存(Library Cache)实现全局执行计划共享。其SQL处理分为硬解析(Hard Parse)和软解析(Soft Parse)。
- 硬解析:对全新SQL进行完整解析、优化并生成执行计划,结果缓存于库缓存。
- 软解析:当SQL进入时,Oracle计算其哈希值并在库缓存中查找。若找到完全匹配的SQL文本与执行计划,则直接复用,跳过大部分优化步骤。
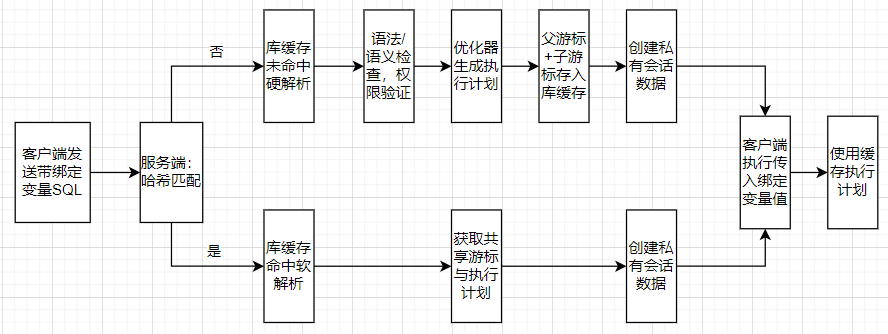
关键参数配置:
Oracle的缓存管理高度自动化,核心参数包括:
SHARED_POOL_SIZE:控制共享池大小,影响库缓存容量。通常由Oracle自动管理(AMM/ASMM),采用LRU算法淘汰旧计划。CURSOR_SHARING:用于处理字面值替换,对于未使用绑定变量的遗留应用,设置为FORCE可减少硬解析。SESSION_CACHED_CURSORS:控制会话级游标缓存数量,用于在会话内部快速重用游标,减少对库缓存闩锁的争用。
总的来说,应用使用Oracle时,通常无需关心Prepare缓存的详细配置,由服务端动态管理。
2.2 DB2数据库的实现机制
DB2通过包缓存(Package Cache) 实现执行计划的全局共享。其Prepare过程同样区分缓存命中(软编译)与未命中(硬编译)。

静态SQL与动态SQL:
- 动态SQL:即常见的JDBC PrepareStatement,执行计划在运行时生成并缓存于包缓存。
- 静态SQL:程序预编译时(
PREP或BIND阶段)即完成解析优化,执行计划持久化存储在系统编目表中,运行时直接调用。
关键参数配置:
PCKCACHESZ:控制包缓存的内存大小,通常设置为AUTOMATIC,由DB2内存自动调节器管理。
与Oracle类似,DB2服务端的缓存管理对应用透明。
2.3 MySQL数据库的实现机制
MySQL的Prepare机制有显著不同:其预处理语句缓存默认是会话级别的,无法在不同连接间共享。每个连接维护自己的预处理语句缓存。
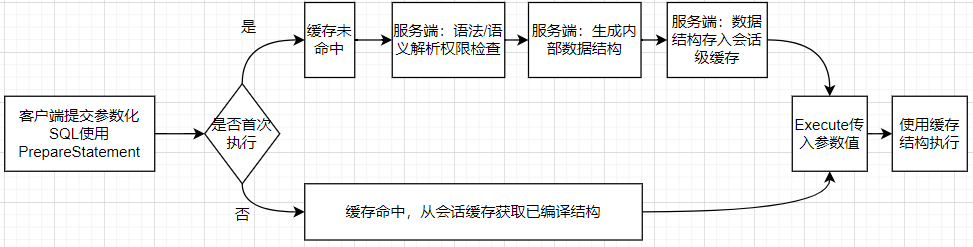
关键配置(主要在客户端/连接层):
对于使用JDBC连接MySQL的应用,以下参数至关重要:
useServerPrepStmts=true:启用真正的服务端预编译(默认false,为客户端模拟)。cachePrepStmts=true:启用客户端驱动对PreparedStatement句柄的缓存。prepStmtCacheSize:设置每个连接缓存的预处理语句数量(默认25)。prepStmtCacheSqlLimit:设置可被缓存的SQL语句最大长度(默认256字节)。
服务端参数:
max_prepared_stmt_count:控制整个MySQL实例同时存在的预处理语句总数上限(默认~16万)。需警惕连接数过多或缓存设置过大导致超出此限制。
因此,对于MySQL,应用层(特别是JDBC连接配置)的调优至关重要,不合理的配置可能导致缓存失效或触及服务器限制。
3、总结
数据库执行SQL通常需经历解析、优化、执行三阶段。Prepare机制通过分离解析与执行来提升性能。
- Oracle与DB2:默认提供全局共享的执行计划缓存(库缓存/包缓存),由数据库服务器自动管理内存,对应用透明。
- MySQL:默认提供会话级别的预处理缓存,且需显式开启。性能优化重心在客户端驱动配置(如JDBC参数),配置不当易引发缓存未命中或服务器资源超限。
了解这些底层机制与差异,有助于在不同数据库环境下进行更有针对性的性能调优。
参考资料:
- 知乎:数据库Prepare机制详解
|  发表于 2025-12-23 19:48:27
|
查看: 258|
回复: 0
发表于 2025-12-23 19:48:27
|
查看: 258|
回复: 0
