
如何让AI智能体在复杂的连续任务中保持上下文感知?关键在于为其构建像人类一样持久、连贯的记忆系统。记忆机制是大语言模型(LLM)智能体实现个性化与上下文一致交互的基石。本文将深入探讨Agent记忆的核心概念,并重点解析在LangGraph框架下如何实现短期会话记忆与长期知识记忆的存储、管理与检索。我们还将通过一个引入MCP协议的实战案例,手把手带你构建一个融合中断机制与长短期记忆的真实多智能体(Multi-Agent)系统。
记忆机制核心概念
Agent Memory是什么?

上图中(来源于Mem0[1]),左侧是无记忆的Agent,右侧是有记忆的Agent。后者能基于用户过往信息(如素食主义、不喜欢乳制品)给出更合理的响应(推荐不含乳制品的素食菜单),而前者的回答则显得不够智能。
简单来说,Memory是赋予Agent记忆能力的技术与架构,使其能够记住过去的交互、学到的知识、执行过的任务及未来的计划。这是将LLM转变为能够执行复杂长期任务的真正“智能体”的核心所在。
记忆的分类与工作机制
与人类类似,Agent的记忆通常被划分为短期记忆和长期记忆。短期记忆关注微观任务的即时表现,而长期记忆则作为持久知识库,决定了Agent在宏观时间尺度上的智能深度与个性化水平。两者协同工作,才能使Agent表现出连贯性和上下文感知能力。
一个有效的记忆系统通常包含以下步骤:
- 记忆存储:设计策略来存储重要的交互信息。
- 记忆更新:随着交互不断更新记忆内容,如用户偏好、最新情况。
- 记忆检索:根据当前需求,从记忆中检索相关信息以生成更智能的回复。
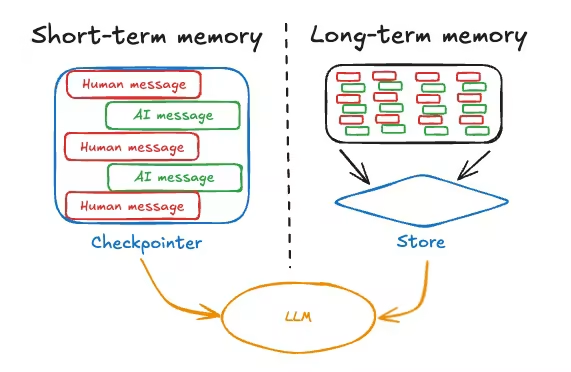
LangGraph中的记忆管理系统
LangGraph作为一个面向多智能体协作与状态管理的框架,设计了巧妙的双轨记忆系统:
- 短期记忆:通过
Checkpointer实现,针对单个对话线程,保障对话的连续性。
- 长期记忆:通过
Store实现,可跨对话线程共享,作为持久知识库。
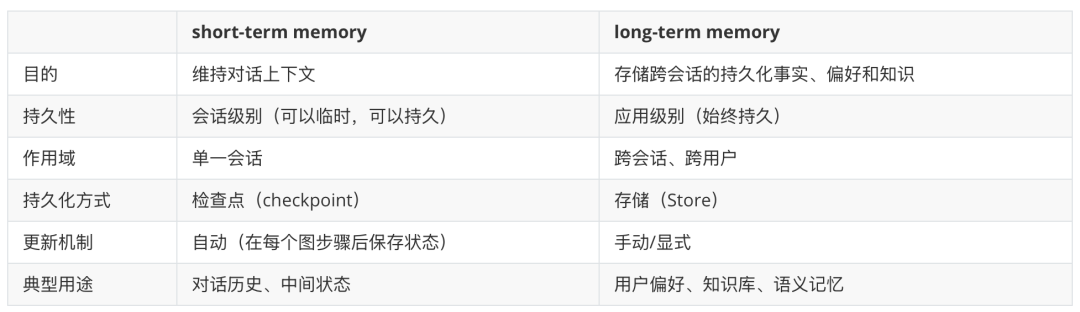
两者核心区别如下:
架构基础:Checkpointer、Thread与Store
- Checkpointer:内置的持久化层,在每个执行步骤(super-step)保存图状态的检查点,是实现记忆、人工干预等功能的基础。
- Thread:管理独立对话的线程概念,通过唯一的
thread_id来区分和激活不同对话。
- Store:一个暴露给图节点和工具的键值数据库,用于在多个线程间长期保留信息,数据通过
namespace(如(“memories”, user_id))进行组织隔离。
短期记忆实现详解
1. 内存临时存储 (InMemorySaver)
适用于开发和测试,将状态存储在内存字典中。
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.prebuilt import create_react_agent
checkpointer = InMemorySaver()
agent = create_react_agent(model=model, tools=[], checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
# 第一次交互
agent.invoke({"messages": [{"role": "user", "content": "你好,我叫ada!"}]}, config)
# 第二次交互,相同thread_id,Agent记得名字
agent.invoke({"messages": [{"role": "user", "content": "你还记得我叫什么吗?"}]}, config)
注意:InMemorySaver的数据在程序终止后会丢失。
2. 数据库持久化存储
生产环境需使用数据库(如PostgreSQL)持久化记忆。
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 初次使用需设置
graph = builder.compile(checkpointer=checkpointer)
配置数据库后,记忆在应用重启后依然存在。LangGraph会在数据库中创建checkpoints(状态快照)和checkpoint_writes(消息内容)等表来管理数据。
3. 子图中的记忆
- 记忆继承(默认):子图继承父图检查点,共享对话状态。
- 记忆隔离:编译子图时设置
checkpointer=True,使子图拥有独立内存空间。
4. 工具与记忆的交互
- 读取状态:在工具函数签名中使用
Annotated[CustomState, InjectedState]注入当前状态。
- 写入状态:工具返回
Command(update={...})对象,直接修改智能体的短期记忆。
长期记忆实现详解
长期记忆通过Store管理,支持跨线程的信息保留和检索。
1. 内存存储 (InMemoryStore)
from langgraph.store.memory import InMemoryStore
from langgraph.config import get_store
store = InMemoryStore()
store.put(("users",), "user_123", {"name": "ada", "language": "中文"})
def get_user_info(config: RunnableConfig) -> str:
store = get_store() # 获取上下文中的store
user_info = store.get(("users",), "user_123")
return str(user_info.value) if user_info else "Unknown user"
2. 数据库持久化存储
生产环境使用如PostgresStore。
from langgraph.store.postgres import PostgresStore
with PostgresStore.from_conn_string(DB_URI) as store:
store.setup()
def call_model(state, config, *, store: BaseStore):
# 读取记忆
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = store.search(namespace, query=state["messages"][-1].content)
# 写入记忆
if "记住" in last_message.content.lower():
store.put(namespace, str(uuid.uuid4()), {"data": "用户名字是ada"})
此例中,首次对话(线程3)将用户名字存入Store,第二次对话(新线程4)通过store.search成功检索,展示了跨线程的长期记忆能力。
3. 语义搜索
Store支持语义搜索,可结合Embedding服务实现基于概念的模糊检索,这实质上是一套RAG流程。
# 1. 创建自定义Embedding类(继承自langchain.embeddings.base.Embeddings)连接自部署服务
# 2. 配置Store时传入index
from langgraph.store.memory import InMemoryStore
custom_embeddings = SelfAPIEmbeddings() # 您的自定义类
store = InMemoryStore(index={"embed": custom_embeddings, "dims": 2560})
# 3. 进行语义查询
store.put(("user_123", "memories"), "1", {"text": "我喜欢吃披萨"})
items = store.search(("user_123", "memories"), query="我肚子饿了", limit=1)
# 能检索到“披萨”相关记忆,尽管查询词中没有“披萨”
短期记忆管理策略
为避免对话历史超出模型上下文窗口,需对短期记忆进行管理。
1. 修剪消息 (trim_messages)
在调用LLM前,根据token限制裁剪消息列表。
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
def call_model(state: MessagesState):
messages = trim_messages(
state["messages"],
strategy="last", # 保留最后的消息
max_tokens=128,
include_system=True
)
response = model.invoke(messages)
return {"messages": [response]}
此方法仅裁剪传入模型的历史,完整历史仍保留在状态中。
2. 删除消息
使用RemoveMessage从图状态中永久删除特定消息。
from langchain_core.messages import RemoveMessage
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
使用RemoveMessage(id=REMOVE_ALL_MESSAGES)可清空所有消息。
3. 总结消息
调用LLM对历史对话进行摘要,以保留关键信息的同时减少消息数量。可使用langmem库的SummarizationNode简化实现。
pip install -U langmem
from langmem.short_term import SummarizationNode
summarization_node = SummarizationNode(
model=summarization_model,
max_tokens=256,
max_tokens_before_summary=256,
)
# 在图中加入总结节点,或通过pre_model_hook集成到agent
实战:基于MCP协议构建带记忆的多智能体系统
本节将构建一个集成中断机制与长短期记忆的Multi-Agent系统,模拟旅游信息查询与酒店预订管理场景。
系统架构:
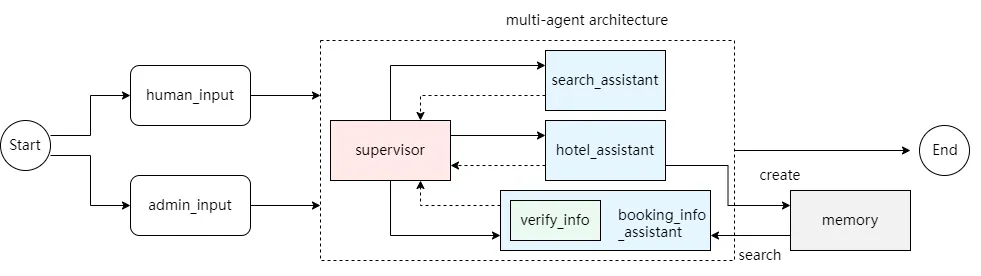
包含三个子智能体:search_assistant(信息查询)、hotel_assistant(酒店预订)、booking_info_assistant(预订查询,带权限中断验证),由一个Supervisor进行协调。
步骤详解
1. 环境与模型准备
pip install langchain-mcp-adapters
BASE_URL=""
TOKEN=""
MODEL_NAME=""
from langchain.chat_models import init_chat_model
model = init_chat_model(model=MODEL_NAME, model_provider="openai", base_url=BASE_URL, api_key=TOKEN)
2. 初始化记忆
from langgraph.store.memory import InMemoryStore
from langgraph.checkpoint.memory import InMemorySaver
store = InMemoryStore()
checkpointer = InMemorySaver()
3. 配置工具与助手
- 搜索助手:集成MCP搜索工具。
from langchain_mcp_adapters.client import MultiServerMCPClient
search_client = MultiServerMCPClient({...})
search_tools = await search_client.get_tools()
search_agent = create_react_agent(model, search_tools, name="search_assistant")
- 酒店预订助手:定义数据结构并存储至长期记忆。
from typing_extensions import TypedDict
class UserInfo(TypedDict):
user_id: str; hotel_name: str; date: str; num_guests: int
def book_hotel(user_info: UserInfo, config: RunnableConfig):
user_id = config["configurable"].get("user_id")
namespace = ("user_bookings",)
user_bookings = store.get(namespace, user_id) or []
user_bookings.append(user_info)
store.put(namespace, user_id, user_bookings) # 存入长期记忆
return f"成功预订..."
book_hotel_agent = create_react_agent(model, tools=[book_hotel], store=store, name="hotel_assistant")
- 查询助手(带中断验证):在查询前中断流程验证管理员权限。
from langgraph.types import interrupt, Command
def authentication_and_query_node(state: SubgraphState, config: RunnableConfig):
admin_input = interrupt("请输入管理员id,如需退出查询,请输入exit") # 中断执行
if admin_input == "admin_123":
result = query_booking_from_store(config) # 验证成功后查询
else:
result = f"没有权限查询..."
return {"messages": [AIMessage(content=result)]}
# 构建子图
query_workflow = StateGraph(SubgraphState)
query_workflow.add_node("auth_and_query", authentication_and_query_node)
booking_query_subgraph = query_workflow.compile(checkpointer=checkpointer, store=store)
booking_query_subgraph.name = "booking_info_assistant"
4. 构建Supervisor工作流
from langgraph_supervisor import create_supervisor
workflow = create_supervisor(
[search_agent, book_hotel_agent, booking_query_subgraph],
model=model,
prompt="您是团队主管,负责管理三个助手...",
)
supervisor = workflow.compile(checkpointer=checkpointer, store=store)
系统运行演示
场景1:连续查询(短期记忆)
config = {"configurable": {"thread_id": "1", "user_id": "user_123"}}
# 第一次:查询北京火锅店
await supervisor.astream({"messages": [("user", "北京最出名的老北京火锅是哪家?")]}, config)
# 第二次:基于上次回答追问
await supervisor.astream({"messages": [("user", "那第一个推荐的火锅店附近有哪些酒店呀")]}, config)
# Supervisor能记住上文提到的“第一个推荐的火锅店”
场景2:酒店预订(写入长期记忆)
await supervisor.astream(
{"messages": [("user", "帮我预定北京王府井希尔顿酒店,日期:2025-11-13到14,人数1")]},
config
)
# hotel_assistant被调用,预订信息存入Store
场景3:管理员查询(中断与长期记忆检索)
config = {"configurable": {"thread_id": "2", "user_id": "user_123"}} # 新线程
# 首次运行触发中断
interrupt_input = None
async for chunk in supervisor.astream({"messages": [("user", "查询用户预定酒店信息")]}, config):
if key == "__interrupt__":
break
# 模拟输入正确管理员ID恢复执行
interrupt_input = Command(resume="admin_123")
async for chunk in supervisor.astream(interrupt_input, config):
...
# booking_info_assistant验证权限后,从Store中查询到长期记忆并返回结果
总结与展望
本文详细介绍了基于LangGraph框架构建AI智能体记忆系统的完整方案,涵盖了短期会话记忆与长期知识记忆的管理策略与实现细节,并通过实战展示了其在复杂Multi-Agent系统中的应用。
未来的改进方向可以聚焦于:
- 更智能的记忆管理:让Agent能自主决定记忆的存储、更新、遗忘与检索优先级。
- 记忆驱动的架构优化:根据应用场景(如个体记忆、团队记忆、全局记忆)选择更合适的Multi-Agent架构(如分层架构),而非单一Supervisor。
通过有效的记忆管理,AI智能体将能更好地理解上下文、学习用户偏好,从而在长期互动中提供更连贯、更个性化的服务。
参考文献
[1] Chhikara P, Khant D, Aryan S, et al. Mem0: Building production-ready ai agents with scalable long-term memory[J]. arXiv preprint arXiv:2504.19413, 2025.
[2] Langchain Docs
 发表于 2025-12-23 23:30:44
|
查看: 325|
回复: 0
发表于 2025-12-23 23:30:44
|
查看: 325|
回复: 0
