当Kubernetes集群出现故障时,真正的挑战往往不在于问题本身,而在于缺乏清晰的排查思路。面对Pod启动失败、服务无法访问或节点失联等情况,盲目查看日志往往事倍功半。
事实上,Kubernetes的故障具有高度的结构性。掌握一套系统化的“黄金排查路径”,能够帮助你从现象表象快速定位到问题层级,并最终找到根本原因。本文将为你梳理一套可复用的Kubernetes故障诊断思维模型。
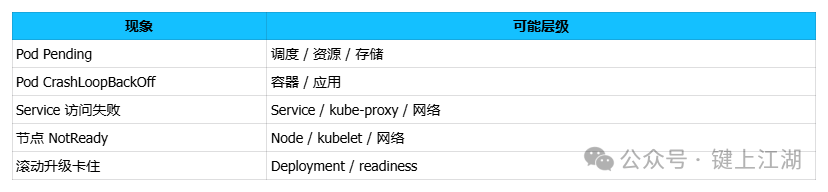
1. 定位问题层级:从现象出发,而非日志
排查的第一步不是执行 kubectl logs,而是根据现象快速确定问题发生的层级。
常见的故障现象可以归纳为以下几类,先确定层级能节省大量时间:
2. 第二步:检查资源状态与事件(Describe > Logs)
在Kubernetes中,资源事件(Event)通常比容器日志更具指导性,它能直接反映调度器、控制器等系统组件的决策结果。
核心命令顺序
kubectl get pod -o wide
kubectl describe pod <pod-name>
执行 describe 命令后,重点关注以下三部分:
✅ Pod状态 (Status)
Pending:等待调度Running:运行中CrashLoopBackOff:容器启动后反复崩溃ImagePullBackOff:镜像拉取失败
✅ 事件 (Events) - 最关键
Events区域常直接揭示根本原因,例如:
FailedScheduling:调度失败Insufficient cpu/memory:资源不足FailedMount:存储卷挂载失败Readiness probe failed:就绪探针失败
✅ 节点绑定情况
- Pod被调度到了哪个Node
- 该Node的状态是否为
Ready
- 是否因Taint(污点)或Affinity(亲和性)规则而未调度
据统计,约80%的常见问题在 describe 阶段就能发现端倪。掌握高效的运维技巧对于快速解读这些信息至关重要。
3. Pod处于Pending状态:排查调度失败原因
Pod状态为 Pending 并不意味着Pod本身有问题,而是调度器(Scheduler)未能为其找到合适的节点。
请按顺序排查以下方面:
① 集群资源是否不足
查看Events中是否有 Insufficient cpu 或 Insufficient memory 提示。
② Taints(污点)与Tolerations(容忍度)
事件中可能出现类似 node(s) had taint {xxx:NoSchedule} 的提示,说明Pod无法容忍目标节点的污点。
③ NodeSelector / NodeAffinity(节点选择器/亲和性)
检查Pod的配置:
- 是否指定了不存在的节点标签?
- 强制的亲和性规则是否无法满足?
④ PVC(持久卷声明)与存储
事件提示 pod has unbound immediate PersistentVolumeClaims 表示Pod等待的存储卷尚未就绪。
核心要点:Pending 是调度层面的问题,通常与应用程序代码无关。
4. CrashLoopBackOff:容器级启动故障
CrashLoopBackOff 状态的含义很明确:容器能够启动,但很快自行退出,此过程循环发生。
排查顺序如下:
① 首先查看容器日志
kubectl logs <pod-name>
# 查看上次崩溃的容器日志
kubectl logs <pod-name> --previous
② 常见根因
- 容器启动命令(command)错误
- 应用配置文件缺失或格式错误
- 必需的环境变量未设置或错误
- 容器内端口被占用
- 应用程序本身启动时发生 panic 或 exit(1)
③ 检查存活探针(Liveness Probe)配置
这也是一个非常常见的原因:
livenessProbe 配置过于严格或检测路径错误- 应用程序尚未完成初始化就被探针判定为失败,导致容器被重启
- 误将本应作为
readinessProbe(就绪探针)的配置用于livenessProbe
核心要点:CrashLoopBackOff 绝大多数情况下是应用程序的启动或配置问题,而非K8s集群本身的问题。
5. Service无法访问:分段排查网络流量
Service访问失败,需要按照流量路径分段排查,而不是笼统地怀疑“网络有问题”。
经典流量路径与排查点
客户端 → Service(虚拟IP) → Endpoints(端点列表) → Pod IP → 容器端口
必查命令
kubectl get svc <service-name>
kubectl get endpoints <service-name>
kubectl describe svc <service-name>
常见错误
- Selector不匹配:Service的
selector 与后端Pod的 labels 不匹配,导致Endpoints列表为空。
- Pod未就绪:Pod的
readinessProbe 失败,导致其未被加入Service的Endpoints。
- 端口映射错误:Service中定义的
targetPort 与容器实际监听的端口不一致。
- kube-proxy异常:节点上的
kube-proxy 组件异常,未能正确配置iptables或IPVS规则。
核心要点:遇到Service访问失败,首先检查对应的Endpoints是否存在且不为空。理解云原生网络模型是解决此类问题的基础。
6. Node状态为NotReady:系统级故障
Node NotReady 是一个高优先级的集群级告警,意味着该节点已脱离集群控制。
常见原因
① Kubelet异常
kubelet 进程崩溃kubelet 无法连接到 API Server(证书过期、网络不通、配置错误)
② 网络问题
- CNI(容器网络接口)插件异常,导致Pod网络中断
- 节点与API Server之间的网络通信故障
③ 节点资源压力
- 磁盘空间已满 (
DiskPressure)
- 内存不足 (
MemoryPressure)
④ 系统时间不同步
- NTP服务异常导致节点与Master节点时间偏差过大,可能使证书失效。
排查命令:kubectl describe node <node-name>
核心要点:当Node NotReady 时,应首先修复节点本身的问题,而不是去排查其上的Pod。
7. 滚动更新卡住:探针配置是关键
Deployment的滚动更新过程卡住,通常不是Kubernetes的bug,而是应用或配置设计问题。
常见原因
- 就绪探针失败:新版本Pod的
readinessProbe 永远无法通过,导致其一直处于“未就绪”状态。
- 启动速度慢:新Pod启动缓慢,而
maxUnavailable 被设置为0(不允许不可用),更新过程会一直等待。
- 旧Pod不敢删除:由于新Pod无法就绪,控制器不会删除旧Pod,更新过程停滞。
监控命令:kubectl rollout status deployment/<deployment-name>
核心要点:滚动更新是否顺畅,几乎完全取决于 readinessProbe 是否能真实、及时地反映应用的业务就绪状态。
8. 故障排查黄金路径总结
你可以遵循以下可背诵的排查顺序:
现象 → 确定层级 → 检查状态 → 分析事件 → 审查约束(配置) → 查看日志 → 定位根因
更简化的步骤是:
- 定性:问题是出在Pod、Node还是Service/Network?
- 观态:相关资源的状态(Status)是什么?
- 寻迹:
describe 命令中的 Events 揭示了什么?
- 归因:问题是调度问题、容器问题,还是网络问题?
- 深挖:最后,才通过日志深入分析应用内部行为。
9. 结语:让故障排查有迹可循
Kubernetes的设计哲学之一就是让分布式系统的状态可观测、问题可定位、行为可解释。它提供了丰富的工具和API来暴露这些信息。
只要你坚持:
- 不跳过诊断步骤
- 不凭直觉盲目操作
- 不一上来就执行“重启大法”
你会发现,绝大多数Kubernetes故障都有一条清晰的排查路径。结合像 Prometheus 这样的监控工具建立更完善的可观测性体系,将使你的运维工作更加主动和高效。
 发表于 2025-12-24 00:23:07
|
查看: 175|
回复: 0
发表于 2025-12-24 00:23:07
|
查看: 175|
回复: 0
