你的 Kubernetes Pod 全年无休地运行着。但一个扎心的事实是:大部分业务 API 在一周内超过 70% 的时间都处于闲置状态。

以金融服务环境中的一个典型交易 API 为例。市场交易时间为周一至周五,上午 9 点到下午 6 点。每周的实际使用时间为 45 小时。然而,你却在为 168 小时的计算容量付费。
这意味着每周纯粹浪费了 123 个小时。
这不是一个假设场景。这是我在受监管的金融环境中大规模管理财资和风险管理解决方案时观察到的现实。
传统的 Kubernetes 成本模型已然失效
当你部署一个标准的 Kubernetes Deployment 时,你需要定义一个最小副本数 (replicas)。无论这些副本是在处理请求还是处于闲置状态,它们都会持续运行,消耗计算资源并产生费用。
apiVersion: apps/v1
kind: Deployment
metadata:
name: trading-api
spec:
replicas: 3 # Always running
template:
spec:
containers:
- name: api
image: trading-api:v1
resources:
requests:
memory: "256Mi"
cpu: "250m"
在我们将单体应用“平移” (lift-and-shift) 到 Kubernetes 的时代,这种模型是合理的。但对于拥有数十个微服务的现代云原生架构而言,这种成本结构与实际使用模式并不匹配。
Knative 登场:为你的 Kubernetes 带来厂商中立的 Serverless

Knative最近获得了CNCF 的毕业 (Graduation) 状态(2025 年 9 月),加入了久经考验的云原生项目精英行列。Knative 的变革性不仅在于技术本身,更在于它所赋能的经济模型。
Knative 直接在你现有的 Kubernetes 基础设施上提供无服务器 (Serverless) 能力。没有专有平台,没有厂商锁定,也没有神秘的定价模型。你的集群,你做主。
两大核心组件
- Knative Serving:根据流量将 HTTP 工作负载从零自动扩展到 N,然后再缩容回零。这正是成本优化的魔力所在。
- Knative Eventing:基于 CloudEvents 的事件处理,用于构建事件驱动架构。虽然功能强大,但本文我将重点关注 Serving,因为这是直接体现业务价值的地方。
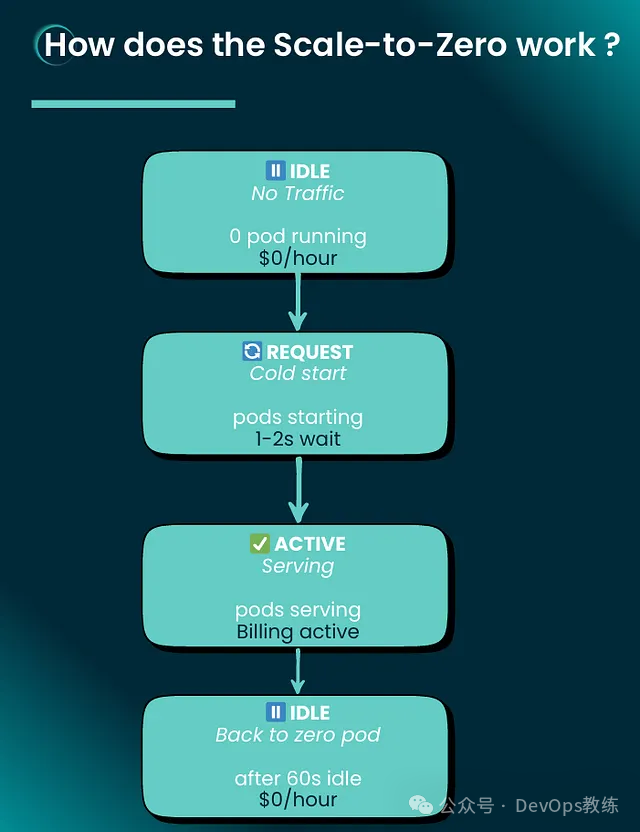
“缩容至零” (Scale-to-Zero) 的实际工作原理
“缩容至零” 机制遵循一个简单而有效的生命周期:
- 闲置状态 (IDLE State): 无流量 → 运行中的 Pod 为零 → $0/小时
- 请求到达 (REQUEST Arrives): 启动冷启动 (Cold start) → Pod 启动中 → 等待 1–2 秒
- 活跃状态 (ACTIVE State): 处理请求 → Pod 运行中 → 计费激活
- 返回闲置 (BACK TO IDLE): 60 秒无流量后 → 缩容回零 → $0/小时
这是一个 Knative Service 的示例:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: trading-api
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/scale-down-delay: "60s"
spec:
containers:
- image: trading-api:v1
resources:
requests:
memory: "256Mi"
cpu: "250m"
就是这么简单。Knative 会处理剩下的一切:路由、自动扩缩容 (auto-scaling)、版本管理以及平滑缩减。
真实世界的交易 API 示例
让我通过一个基于生产环境金融服务工作负载的场景,来展示它的实际效果。
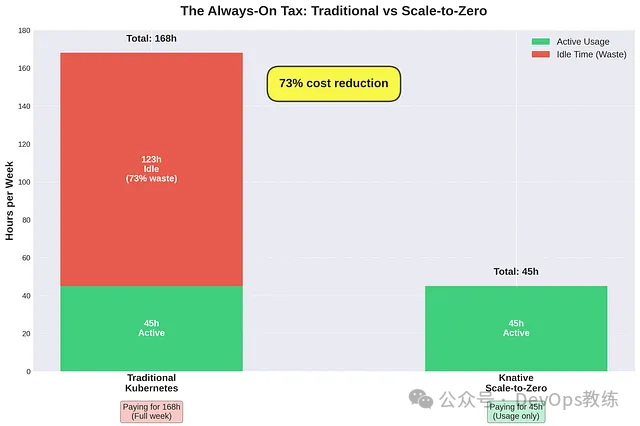
传统的 Kubernetes 部署:
- 3 个副本 24/7 全天候运行
- 每周计费 168 小时
- 整周的计算成本
使用 Knative 缩减到零 (Scale-to-Zero):
- 仅在交易时段 (每周 45 小时) 活跃
- 每周计费 45 小时
- 通过消除空闲时间,成本降低 73%
计算过程很简单:每个服务每周可以减少 123 小时的空闲计算时间。这就是为“以防万一”的容量付费与为实际使用付费之间的区别。
对于运行数十个微服务的组织来说,这种成本削减的效果会迅速累积。关键在于识别出哪些服务具有可预测的空闲期,从而适合应用“缩减到零”的策略。
何时应该(以及不应该)使用 Knative
Knative 非常适合以下场景:
✅ HTTP API:REST API、webhook、API 网关
✅ 事件驱动函数:处理来自队列或流的事件
✅ 请求/响应型工作负载:同步处理模式
✅ 存在空闲期的服务:开发环境、批处理器、定时任务
✅ 批处理:ETL 作业、报告生成、数据处理流水线
Knative 不适用于以下场景:
❌ 数据库:需要持久连接、始终在线的有状态服务
❌ 消息队列:基于连接的持久化服务
❌ WebSocket:长连接与“缩减到零”模型冲突
❌ 超低延迟要求:如果无法容忍 1-2 秒的冷启动 (cold start) 时间
冷启动的考量至关重要。在金融服务领域,对于后台操作、批处理任务和大多数内部 API 来说,1-2 秒的初始延迟是完全可以接受的。但对于高频交易系统呢?还是坚持使用传统的部署方式吧。
计算你可能节省的成本
以下是我在评估是否采用 Knative 时使用的公式:
传统成本:
服务数量 × 副本数 × 168 小时/周 × 每小时成本
Knative 成本:
服务数量 × 副本数 × 实际使用小时数 × 每小时成本
节省百分比:
((168 – 实际使用小时数) / 168) × 100
交易 API 的例子清楚地证明了这一点:45 小时的使用时长对比 168 小时的计费时长,意味着消除了 73% 的浪费。你实际节省的成本将取决于你的具体使用模式以及能够从缩容至零 (scale-to-zero) 中受益的服务数量。
治理与安全:企业现实
在受监管的金融服务环境中,你不能在没有适当治理的情况下就直接部署无服务器 (serverless) 工作负载。正因如此,将 Knative 与 Kyverno 这样的策略即代码 (policy-as-code) 框架相结合就变得至关重要。
以下是一个 Kyverno 策略,它为 Knative 服务 (Knative Services) 强制执行了安全最佳实践:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: knative-security-requirements
spec:
validationFailureAction: enforce
rules:
- name: require-resource-limits
match:
resources:
kinds:
- Service
namespaces:
- production
validate:
message: "Knative Services must define resource limits"
pattern:
spec:
template:
spec:
containers:
- resources:
limits:
memory: "?*"
cpu: "?*"
- name: enforce-minimum-scale
match:
resources:
kinds:
- Service
namespaces:
- production
validate:
message: "Production services must maintain minimum 1 replica"
pattern:
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/min-scale: ">=1"
该策略确保生产环境的 Knative 服务至少保留一个副本 (replica),从而消除了关键服务的冷启动 (cold starts) 问题,同时又能受益于自动扩缩容 (auto-scaling) 的优势。
厂商中立性:战略优势
在实践中,厂商中立性 (vendor neutrality) 的实际含义如下:
- 可在任何 Kubernetes 上运行:
- Azure AKS
- AWS EKS
- Google GKE
- Red Hat OpenShift
- 本地部署的 Kubernetes 发行版
- 随处可用的统一 API:你的 Knative 服务清单 (manifests) 是可移植的。没有特定于云的语法,也没有专有的扩展。
- 没有专有定价:你只需为你已在使用的底层计算资源付费。没有额外的无服务器税,没有按请求收费,也没有意外账单。
在企业环境中,多云 (multi-cloud) 战略是风险管理 (risk management) 的要求,因此这一点至关重要。
入门指南:实践路径
你可以通过以下步骤在 Minikube 中快速体验 Knative Serving。
# Start Minikube with sufficient resources
minikube start --cpus=4 --memory=8192 --kubernetes-version=v1.28.0
# Install Knative Serving CRDs
kubectl apply -f https://github.com/knative/serving/releases/latest/download/serving-crds.yaml
# Install Knative Serving core components
kubectl apply -f https://github.com/knative/serving/releases/latest/download/serving-core.yaml
# Install Kourier as networking layer
kubectl apply -f https://github.com/knative/net-kourier/releases/latest/download/kourier.yaml
# Configure Knative to use Kourier
kubectl patch configmap/config-network \
--namespace knative-serving \
--type merge \
--patch '{"data":{"ingress-class":"kourier.ingress.networking.knative.dev"}}'
# IMPORTANT: Start minikube tunnel for Kourier (run in separate terminal)
# This creates a route to services with type LoadBalancer
minikube tunnel
# Verify Knative is ready
kubectl get pods -n knative-serving
# Deploy your first Knative service
kubectl apply -f - <<EOF
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello
spec:
template:
spec:
containers:
- image: gcr.io/knative-samples/helloworld-go
env:
- name: TARGET
value: "Knative"
EOF
# Get the service URL
kubectl get ksvc hello
# Test the service (in another terminal, with minikube tunnel running)
curl $(kubectl get ksvc hello -o jsonpath='{.status.url}')
重要说明:
- 保持
minikube tunnel 在一个单独的终端中运行——这是 Kourier 正常工作所必需的。
- 第一次请求会花费 1-2 秒(冷启动)。
- 使用以下命令观察 Pod 的扩容过程:
kubectl get pods -w。
- 在 60 秒无活动后,Pod 将缩容至零。
FinOps 视角
参与云原生环境 FinOps 实践 的人员,会认为 Knative 代表了我们实现成本优化 (cost optimization) 方法上的一次根本性转变。
传统的 FinOps 专注于规模优化 (rightsizing)、承诺使用折扣和消除浪费。这些措施固然重要,但都属于增量式改进。Knative 通过在工作负载级别将计费与使用量直接挂钩,实现了结构性的成本优化。
随着组织越来越多地采用 AI 和 ML 工作负载,这一点尤为重要。模型训练、批量推理和模型服务等任务都是 Knative 的理想应用场景:它们资源需求波动大、资源消耗密集,并且经常处于空闲状态。
结论:商业价值显而易见
如果你的 Kubernetes 工作负载存在大量空闲时间(大多数组织都是如此),Knative 提供了一条直接有效的路径,可以在不更改应用程序代码或牺牲控制权的前提下,实现可观的成本削减。
你需要问自己的关键问题是:
- 你的服务中有多大比例存在可预测的空闲时段?
- 你的应用程序能否容忍首次请求时 1-2 秒的冷启动 (cold start)?
- 你是否为无服务器工作负载制定了适当的治理策略?
如果你对这些问题的回答是肯定的,那么 Knative 就值得你认真评估。这项技术已经成熟,成本节约效果显著,并且其供应商中立性保障了你的战略灵活性。
 发表于 2025-12-24 00:26:01
|
查看: 323|
回复: 0
发表于 2025-12-24 00:26:01
|
查看: 323|
回复: 0
